当前位置:网站首页>冒泡排序与快速排序
冒泡排序与快速排序
2022-08-05 03:00:00 【kjl167】
冒泡排序与快速排序
前言:冒泡排序与快速排序都属于交换排序,它们排序的思想是:根据序列中两个记录键值的比较结果来对换这两个记录在序列中的位置,交换排序的特点是:将键值较大的记录向序列的尾部(前部)移动,键值较小的记录向序列的前部(尾部)移动
注意:下文中所有排序都是升序
一、冒泡排序
冒泡排序思想:比较相邻的元素。如果第一个比第二个大,就交换它们。从第一组比较到最后一组相邻元素,此时最后一个元素是最大的元素。除去最后一个元素,将剩下n-1个元素重复上面步骤,直到只剩下一个元素为止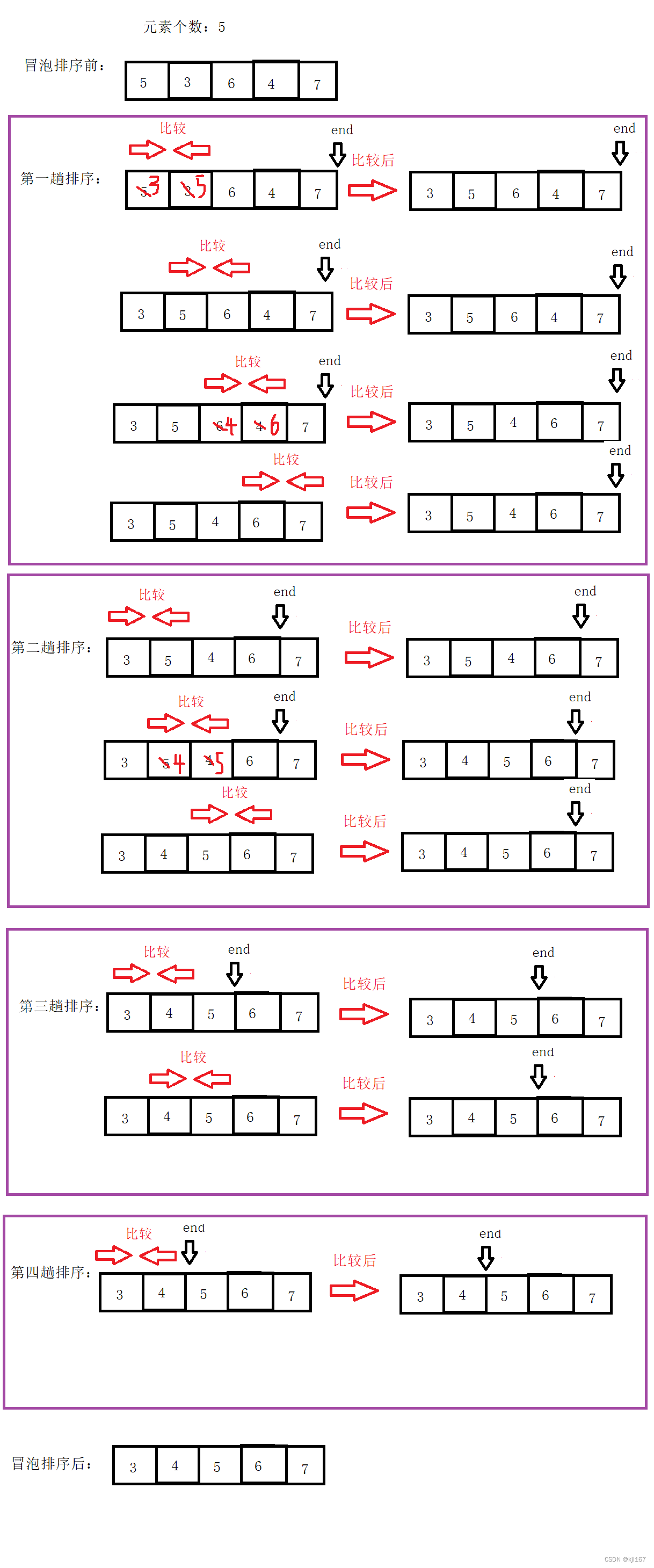
1.1 冒泡排序代码实现
void swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
void BubbleSort(int* arr, int n)
{
assert(arr);
for (int i = 1; i < n; i++) // 排序趟数为:待排序序列元素个数-1
{
for (int j = 0; j < n - i; j++)
{
if (arr[j] > arr[j + 1])
{
swap(&arr[j], &arr[j + 1]);
}
}
}
}
1.2 冒泡排序优化
在上文中冒泡排序的举例图中我们发现,当序列元素个数为n,冒泡排序需排序n-1趟。但在第n-1趟前,序列可能已经排序好了,继续排序没有意义。我们可以设置一个标志位,当某趟排序没有发生过相邻元素交换时,代表序列已经有序,退出循环
void swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
void BubbleSort(int* arr, int n)
{
assert(arr);
for (int i = 1; i < n; i++) // 排序趟数为:待排序序列元素个数-1
{
int flag = 1; // 标志位,当某趟没发生相邻元素交换时,flag为1
for (int j = 0; j < n - i; j++)
{
if (arr[j] > arr[j + 1])
{
swap(&arr[j], &arr[j + 1]);
flag = 0; // 相邻元素交换,flag置0
}
}
if (flag == 1)
break;
}
}
1.3 时间复杂度与空间复杂度
当序列本身有序时,时间复杂度最好:O(N),当序列逆序时,时间复杂度最坏:O(N^2)。冒泡排序只用了常数个辅助变量空间,空间复杂度:O(1)
说明:
●冒泡排序是一个稳定的排序算法
二、快速排序
快速排序思想:选取待排序序列中的某元素作为基准值,按照该基准值将待排序序列分割成两子序列,左子序列中所有元素均小于等于基准值,右子序列中所有元素均大于等于基准值,然后对左右子序列重复该过程,直到所有元素都排列在对应位置上为
止
2.1 选取基准值划分左右子序列方法
选取基准值划分左右子序列方法有多种,下面会演示三种划分方法,只需掌握一种即可
2.1.1 Hoare法
Hoare法是由快速排序发明人查尔斯·霍尔给出方法,Hoare法分为两种方法选取基准值
第一种:选取序列最左边元素做为基准值(key),右指针先走
- 循环开始前,左指针指向基准值,右指针指向序列最右边元素
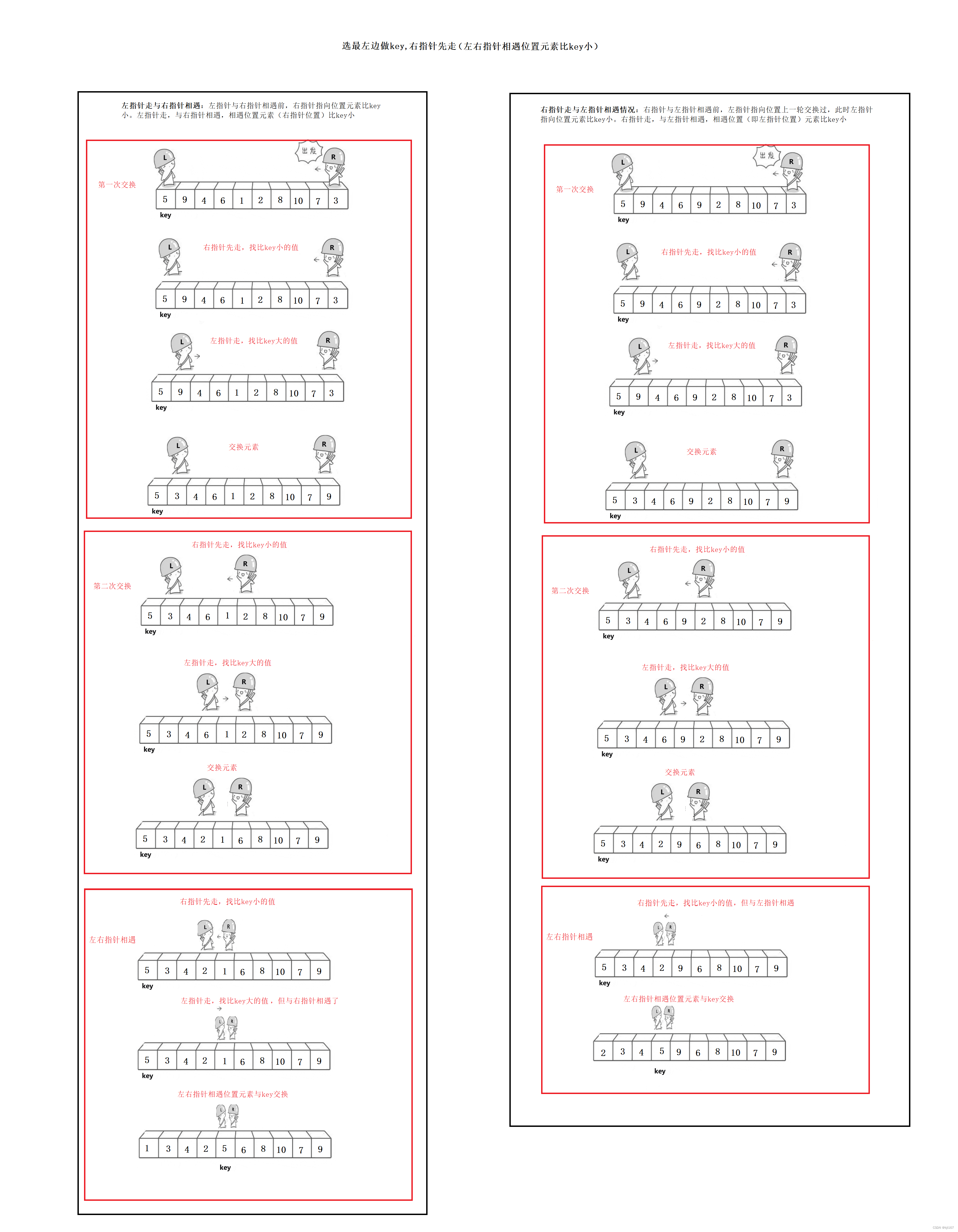
- 循环开始:右指针先走,找到比基准值小的元素停下来,左指针走,找到比基准值大的元素停下来,交换左右指针指向元素值。重复该过程,直到左右指针相遇为止
- 将基准值与左右指针相遇位置元素进行交换
第二种:选取序列最右边元素做为基准值(key),左指针先走
- 循环开始前,左指针指向序列最左边元素,右指针指向基准值
- 循环开始:左指针先走,找到比基准值大的元素停下来,右指针走,找到比基准值小的元素停下来,交换左右指针指向元素值。重复该过程,直到左右指针相遇为止
- 将基准值与左右指针相遇位置元素进行交换
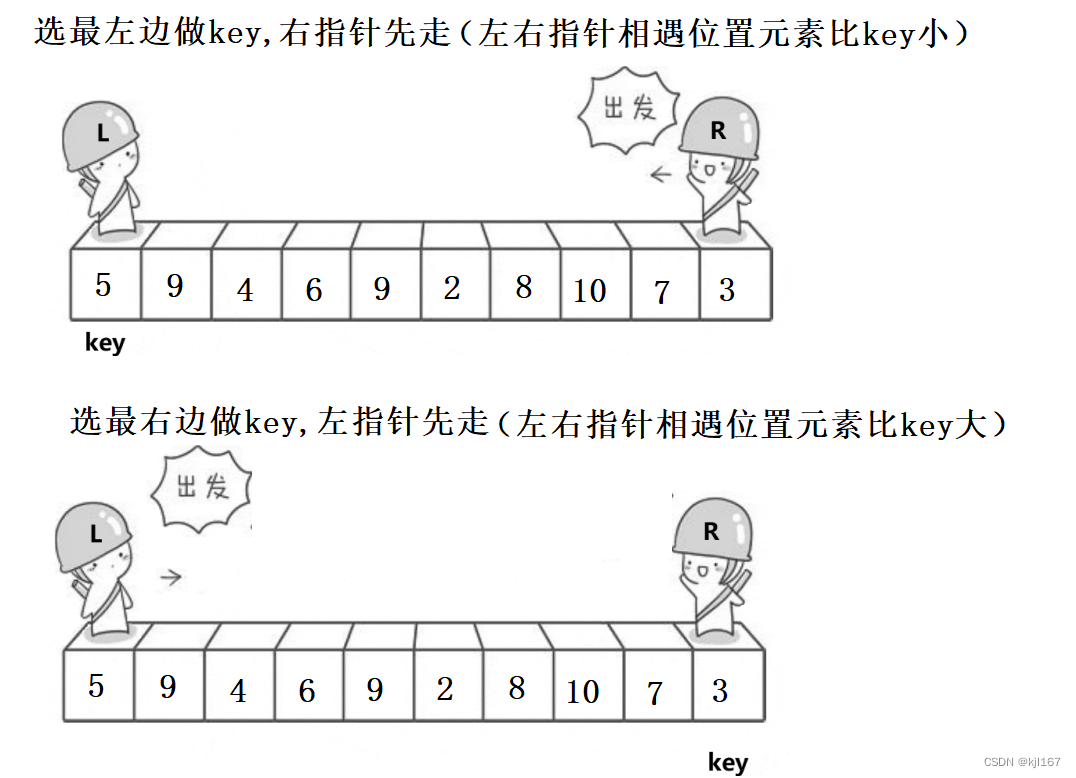
以哪边做key,另一边先走原因:可以保证左右指针相遇位置一定比key小(大),而先走的顺序随意,例如:左边做key,左指针先走,在左右指针相遇前的交换没有区别,最后左右指针相遇位置元素值与key相比不能保证上面条件
下面演示左边做key,右指针先走的两种情况,情况一:左指针走与右指针相遇 ,情况二:右指针走与左指针相遇
void swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
int Partition(int* arr, int left, int right)
{
int key_i = left; // key元素的下标
while (left < right)
{
// 右指针先走,遇到比key小的元素停下
while (left < right && arr[right] >= arr[key_i])
{
right--;
}
// 左指针走,遇到比key大的元素停下
while (left < right && arr[left] <= arr[key_i])
{
left++;
}
// 交换左右指针指向元素
swap(&arr[left], &arr[right]);
}
// 将key位置元素与左右指针相遇位置元素交换,并返回相遇位置元素下标
swap(&arr[key_i], &arr[right]);
return right;
}
2.1.2 挖坑法
挖坑法是Hoare法的变形
- 循环开始前,将序列最左边元素值保存在变量key中,并将该位置做为坑位,左指针指向坑位,右指针指向序列最右边元素
- 循环开始:右指针先走,找到比key小的元素停下来,将该位置元素放到左边的坑位中,并将该位置做为新的坑位。左指针走,找到比key大的元素停下来,将该位置元素放到右边的坑位中,并将该位置做为新的坑位。重复该过程,直到左右指针相遇为止
- 相遇位置一定是坑位,将key值放入坑位中

void swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
int Partition(int* arr, int left, int right)
{
int key = arr[left]; // 存放key的值
int pit = left; // 存放坑位下标
while (left < right)
{
// 右指针找比key小的值并放入坑中
while (left < right && arr[right] >= key)
{
right--;
}
arr[pit] = arr[right];
pit = right;
// 左指针找比key大的值并放入坑中
while (left < right && arr[left] <= key)
{
left++;
}
arr[pit] = arr[left];
pit = left;
}
// 左右指针相遇于坑位中,将key值放入坑中,返回坑位下标
arr[pit] = key;
return pit;
}
2.1.3 前后指针法
- 循环开始前,将序列最左边元素值做为基准值(key),prev指针指向基准值,cur指针指向prev下一个位置
- 循环开始:cur指针找到比基准值小的元素停下,先++prev,然后交换prev与cur指向位置的值,重复该过程,直到cur指向位置越界
- cur越界后,prev与基准位置值交换

void swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
int Partition(int* arr, int left, int right)
{
int key_i = left; // 存放key元素下标
int prev = left;
int cur = prev + 1;
while (cur <= right)
{
while (cur <= right && arr[cur] >= arr[key_i])
{
++cur;
}
if (cur <= right) // 当cur未越界,先++prev,然后交换prev与cur位置值
{
swap(&arr[cur], &arr[++prev]);
cur++; // 防止序列逆序情况下,cur一直不动,prev越界访问并交换,例如序列: 9、8、7、6、5
}
}
swap(&arr[prev], &arr[key_i]);
return prev;
}
我们发现cur指向元素大于等于基准值情况还是小于基准值情况下都需要cur++。只有cur指向元素小于基准值才需要++prev,并交换prev与cur指向位置值,如果++prev后prev等于cur,此时为原地交换没有必要。因此可以对上面代码进行优化
void swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
int Partition(int* arr, int left, int right)
{
int key_i = left; // 存放基准值元素下标
int prev = left;
int cur = prev + 1;
while (cur <= right)
{
if (arr[cur] < arr[key_i] && ++prev != cur)
swap(&arr[prev], &arr[cur]);
cur++;
}
swap(&arr[prev], &arr[key_i]);
return prev;
}
2.2 快速排序
使用 2.1 中任一方法选取基准值并将待排序序列分为左右两个子序列,只需对左右子序列重复该过程,达到整个序列有序
void swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
void QuickSort(int* arr, int left,int right)
{
assert(arr);
if (left >= right) // 序列元素个数小于等于1,已经有序,不需要排序
{
return;
}
int key_i = Partition(arr, left, right);
// 左子序列下标范围: [left,key_i-1] key_i 右子序列下标范围: [key_i+1,right]
QuickSort(arr, left, key_i - 1);
QuickSort(arr, key_i+1, right);
}
2.3 快速排序测试
#include <stdio.h>
#include <assert.h>
void PrintArray(const int* arr, int n)
{
assert(arr);
for (int i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
void swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
// 前后指针法(优化)
int Partition(int* arr, int left, int right)
{
int key_i = left; // 存放基准值元素下标
int prev = left;
int cur = prev + 1;
while (cur <= right)
{
if (arr[cur] < arr[key_i] && ++prev != cur)
swap(&arr[prev], &arr[cur]);
cur++;
}
swap(&arr[prev], &arr[key_i]);
return prev;
}
void QuickSort(int* arr, int left, int right)
{
assert(arr);
if (left >= right) // 序列元素个数小于等于1,已经有序,不需要排序
{
return;
}
int key_i = Partition(arr, left, right);
// 左子序列下标范围: [left,key_i-1] key_i 右子序列下标范围: [key_i+1,right]
QuickSort(arr, left, key_i - 1);
QuickSort(arr, key_i + 1, right);
}
int main()
{
int arr[10] = {
5,9,4,6,1,2,8,10,7,3 };
PrintArray(arr, 10);
QuickSort(arr, 0,9);
PrintArray(arr, 10);
return 0;
}
输出
5 9 4 6 1 2 8 10 7 3
1 2 3 4 5 6 7 8 9 10
2.4 快速排序的优化
2.4.1 三数取中
当每次选取key值是序列的中位数时,可以把序列分为长度相等的左右子序列,快速排序时间复杂度为:O(N*log₂N)。但如果每次选取的key是序列的最小值或最大值时,序列分为一个子序列为空,另一个子序列长度为序列长度-1情况,时间复杂度为:O(N^2)。上文中选取key划分左右子序列,对key的选择都是序列最左边元素或序列最右边元素,当序列基本有序,很容易出现选取的key为最小值或最大值,影响快速排序效率。有人提出三数取中的优化方法,每次选取序列最左边元素、序列中间元素、序列最右边元素,比较三个元素大小,选取中间元素做为key。但是key元素位置可能不是序列最左边或最右边位置,根据上文中选取key划分左右子序列的方法,让key元素与序列最左边(最右边)元素交换位置即可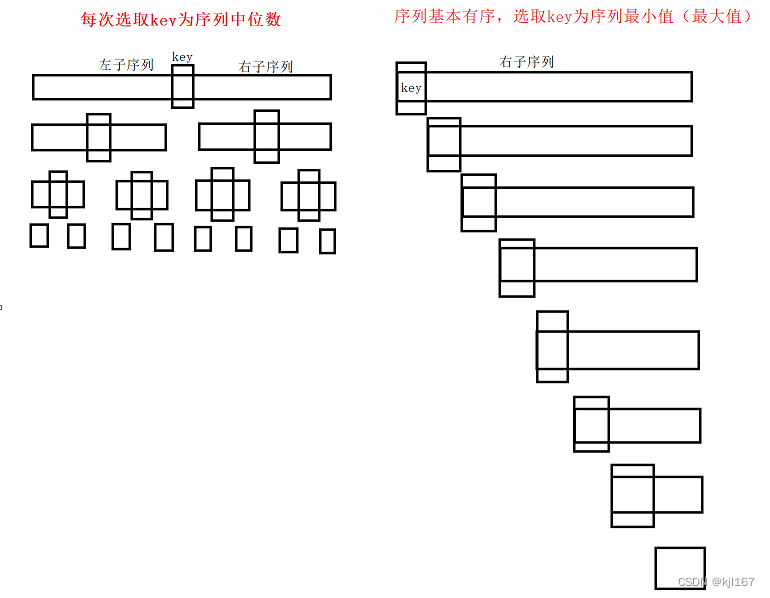
int GetMiddle(int* arr, int left, int right)
{
int middle = left + (right - left) / 2;
if (arr[left] < arr[middle])
{
if (arr[middle] < arr[right])
{
return middle;
}
else if (arr[left] < arr[right])
{
return right;
}
else
{
return left;
}
}
else
{
if (arr[middle] > arr[right])
{
return middle;
}
else if (arr[left] < arr[right])
{
return left;
}
else
{
return right;
}
}
}
int Partition(int* arr, int left, int right)
{
//三数取中
int middle = GetMiddle(arr, left, right);
swap(&arr[left], &arr[middle]);
int key_i = left; // 存放基准值元素下标
int prev = left;
int cur = prev + 1;
while (cur <= right)
{
if (arr[cur] < arr[key_i] && ++prev != cur)
swap(&arr[prev], &arr[cur]);
cur++;
}
swap(&arr[prev], &arr[key_i]);
return prev;
}
2.4.2 小区间优化
当序列(区间)元素个数较少时,继续使用快速排序将导致递归次数大大增加。例如:某个子序列有10个元素,首先递归1次划分左右两个子序列,每个子序列元素个数大约为4。左右两个子序列递归分别递归继续划分左右子序列,每个子序列元素个数大约为2…直到每个子序列元素个数小于等于1为止,此时大约递归了:2^0+2^1+2^2+2^3 = 15次。为了对子序列中10个元素排序需要递归15次,整个快速排序过程中有很多这样子序列,这些子序列递归次数几乎占整个快速排序递归次数的一大半。对于区间元素个数较少时可以使用直接插入排序,减少大量递归带来的开销
直接插入排序可参考这篇博客: https://blog.csdn.net/kjl167/article/details/125872807/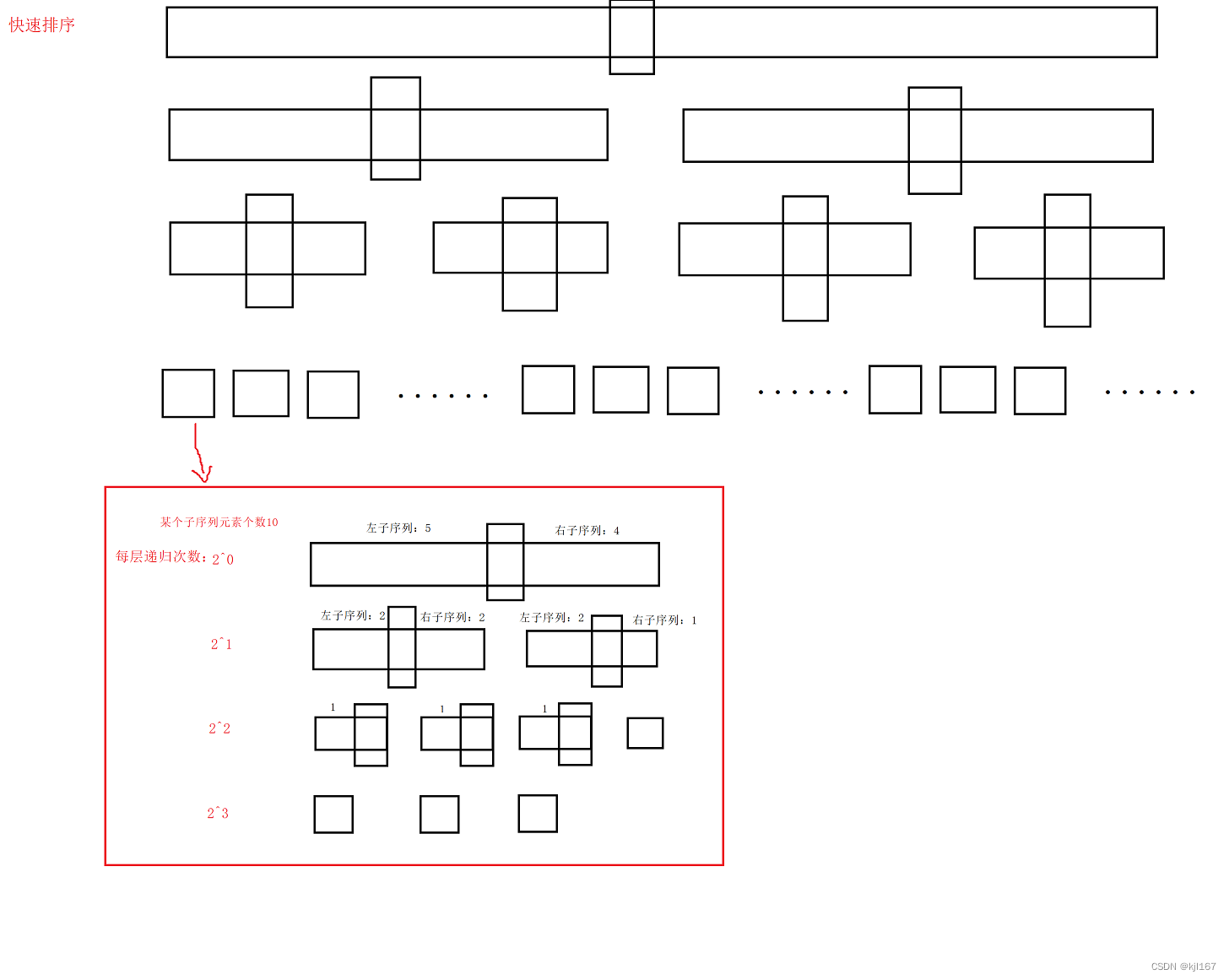
void InsertSort(int* arr, int n)
{
assert(arr);
for (int i = 0; i < n - 1;i++) // 待排序次数为n-1,下标小于等于i的元素已经是有序的
{
int end = i;
int elem = arr[end+1]; // 待插入元素
while (end >= 0)
{
if (elem < arr[end])
{
arr[end + 1] = arr[end];
end--;
}
else
{
break;
}
}
arr[end + 1] = elem;
}
}
void QuickSort(int* arr, int left,int right)
{
assert(arr);
if (left >= right) // 序列元素个数小于等于1,已经有序,不需要排序
{
return;
}
// 小区间优化,当区间元素个数小于等于10用直接插入排序让区间有序,而不是通过递归让区间有序,减少快速排序的递归次数
if (right - left + 1 <= 10)
{
InsertSort(arr + left, right - left + 1); // 子序列(区间)不一定位于数组开头位置,所以arr不一定是区间起始位置,arr+left才是
}
else
{
int key_i = Partition(arr, left, right);
// 左子序列下标范围: [left,key_i-1] key_i 右子序列下标范围: [key_i+1,right]
QuickSort(arr, left, key_i - 1);
QuickSort(arr, key_i + 1, right);
}
}
2.4.3 非递归实现快速排序
上文中快速排序通过递归实现,每次递归调用会消耗一定栈空间大小,栈大小是很有限的。虽然通过三数取中以及小区间优化对快速排序进行了优化,减少了递归次数,但如果遇到待排序序列所有元素几乎相同时,递归深度趋近于N,快速排序的空间复杂度为:O(N),很容易造成栈溢出。
void InitStack(Stack* p)
{
assert(p);
p->data = (ElemType*)malloc(sizeof(ElemType) * SIZE); // SIZE为栈空间初始化大小,在Stack.h头文件定义
p->top = 0;
p->capacity = SIZE;
}
void DestroyStack(Stack* p)
{
assert(p);
free(p->data);
p->data = NULL;
p->top = p->capacity = 0;
}
void Push(Stack* p, ElemType elem)
{
assert(p);
if (p->top == p->capacity) // 栈空间已满,需要扩容
{
int newCapacity = p->capacity * 2;
ElemType* tmp = realloc(p->data, sizeof(ElemType) * newCapacity);
if (tmp == NULL) // 扩容失败,报错并退出
{
printf("realloc fail\n");
exit(-1);
}
p->data = tmp;
p->capacity = newCapacity;
}
// 栈空间扩容成功,元素入栈
p->data[p->top] = elem;
p->top++;
}
ElemType Pop(Stack* p)
{
assert(p);
if (p->top == 0)
{
printf("栈为空,元素出栈失败\n");
return -1;
}
else
{
ElemType elem = p->data[p->top - 1]; // 待出栈元素
p->top--;
return elem;
}
}
int EmptyStack(const Stack* p)
{
assert(p);
return p->top == 0 ? 1 : 0;
}
void QuickSortNoRecurse(int* arr, int left, int right)
{
assert(arr);
if (left >= right) // 序列元素个数小于等于1,已经有序,不需要排序
{
return;
}
Stack s;
InitStack(&s); // 初始化栈
Push(&s, left);
Push(&s, right);
while (!EmptyStack(&s))
{
/* 由于栈是先进后出,我们是left先入栈,right后入栈,所有先出栈的是right */
int right_i = Pop(&s);
int left_i = Pop(&s);
// 小区间优化,当区间元素个数小于等于10用直接插入排序让区间有序
if (right_i - left_i + 1 <= 10)
{
InsertSort(arr + left_i, right_i - left_i + 1); // 子序列(区间)不一定位于数组开头位置,所以arr不一定是区间起始位置,arr+left才是
}
else
{
int key_i = Partition(arr, left_i, right_i);
/* 左子序列:[left_i , key_i - 1] 右子序列:[key_i + 1 , right_i] 由于栈是先进后出,右子序列先入栈,左子序列后入栈,可以确保出栈先对左子序列排序 */
if (key_i + 1 < right_i) // 右子序列元素个数大于1才需要入栈等待排序
{
Push(&s, key_i + 1);
Push(&s, right_i);
}
if (left_i < key_i - 1) // 右子序列元素个数大于1才需要入栈等待排序
{
Push(&s, left_i);
Push(&s, key_i - 1);
}
}
}
DestroyStack(&s); // 销毁栈
}
2.5 时间复杂度与空间复杂度
每次选key为序列的中位数时,时间复杂度最好为:O(N*log₂N),空间复杂度为:O(log₂N)。当序列中元素几乎相同时,时间复杂度最坏为:O(N*2),空间复杂度为:O(N)
说明:
●快速排序是一个不稳定的排序算法
●快速排序面对序列元素几乎相同时,效率很差
边栏推荐
- Multithreading (2)
- Error: Not a signal or slot declaration
- lua learning
- 倒计时 2 天|云原生 Meetup 广州站,等你来!
- In 2022, you still can't "low code"?Data science can also play with Low-Code!
- 语法基础(变量、输入输出、表达式与顺序语句完成情况)
- Chinese characters to Pinyin
- How to solve the error cannot update secondary snapshot during a parallel operation when the PostgreSQL database uses navicat to open the table structure?
- QT语言文件制作
- Object.defineProperty monitors data changes in real time and updates the page
猜你喜欢

shell statement to modify txt file or sh file
2022-08-04 第六小组 瞒春 学习笔记
tree table lookup
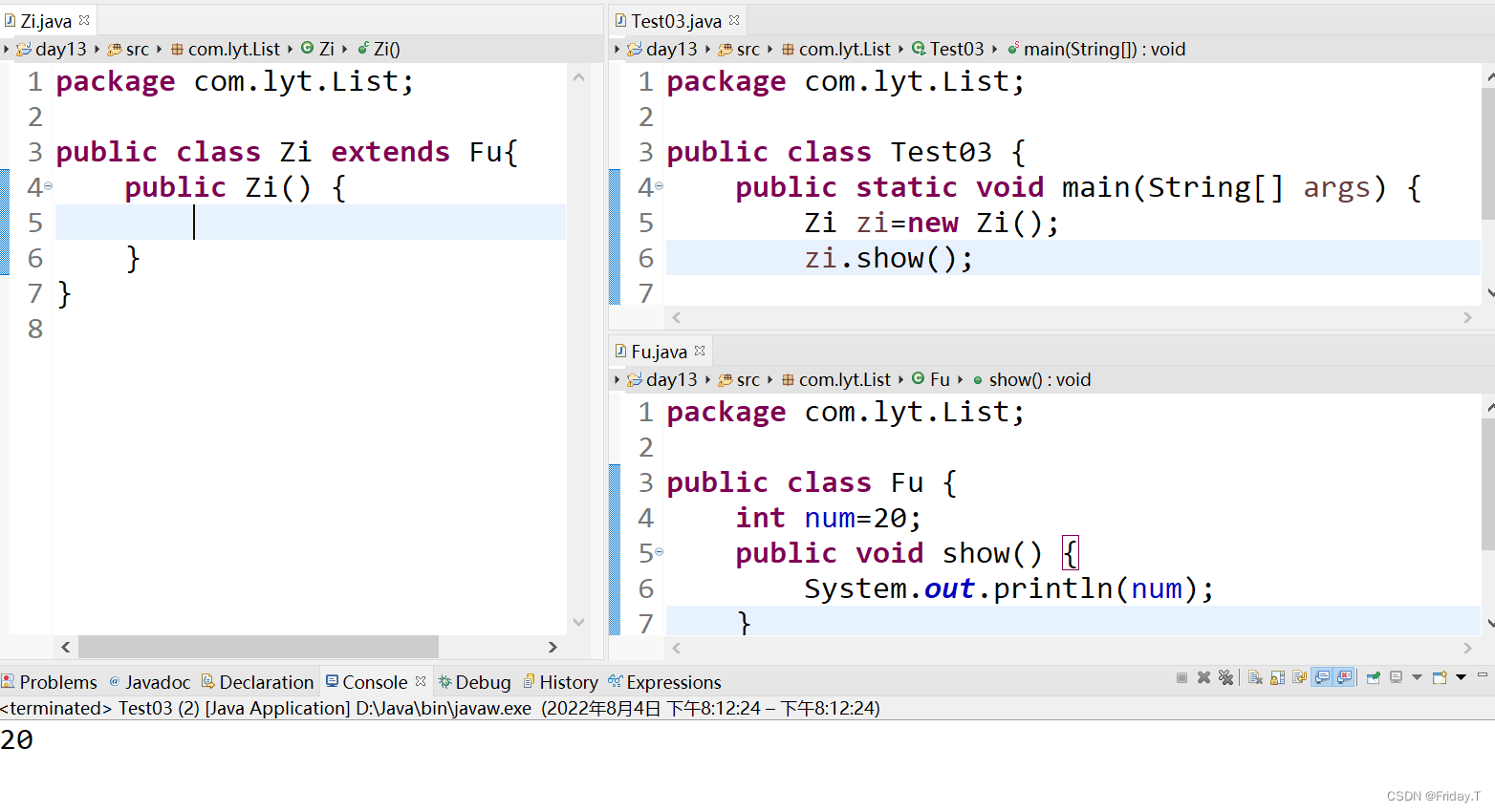
Access Characteristics of Constructor under Inheritance Relationship

word分栏小记

沃谈小知识 |“远程透传”那点事儿
云原生(三十二) | Kubernetes篇之平台存储系统介绍
DAY22: sqli-labs shooting range clearance wp (Less01~~Less20)

线上MySQL的自增id用尽怎么办?
Multithreading (2)
随机推荐
语法基础(变量、输入输出、表达式与顺序语句)
shell statement to modify txt file or sh file
Study Notes-----Left-biased Tree
1484. Sell Products by Date
Programmer's Tanabata Romantic Moment
优炫数据库的单节点如何转集群
[Fortune-telling-60]: "The Soldier, the Tricky Way"-2-Interpretation of Sun Tzu's Art of War
虚拟内存原理与技术
dmp(dump)转储文件
Review 51 MCU
CPDA|How Operators Learn Data Analysis (SQL) from Negative Foundations
HDU 1114:Piggy-Bank ← 完全背包问题
(十一)元类
Access Characteristics of Constructor under Inheritance Relationship
Distributed systems revisited: there will never be a perfect consistency scheme...
Likou - preorder traversal, inorder traversal, postorder traversal of binary tree
627. Change of gender
使用二维码传输文件的小工具 - QFileTrans 1.2.0.1
2022-08-04:输入:去重数组arr,里面的数只包含0~9。limit,一个数字。 返回:要求比limit小的情况下,能够用arr拼出来的最大数字。 来自字节。
QStyle平台风格