当前位置:网站首页>[论文笔记] MapReduce: Simplified Data Processing on Large Clusters
[论文笔记] MapReduce: Simplified Data Processing on Large Clusters
2022-08-05 03:13:00 【PeakCrosser】
MapReduce: Simplified Data Processing on Large Clusters
MapReduce: 大型集群上的简化数据处理 [Paper]
OSDI’04
摘要
MapReduce 是一种用于处理和生成大型数据集的编程模型和相关实现 .
用户指定一个处理键值对以生成一组中间键值对的 m a p map map 函数, 以及一个合并与同一中间键关联的所有中间值的 r e d u c e reduce reduce 函数.
特点: 自动并行化并在大型集群上执行. 运行时系统负责对输入数据进行分区、调度程序执行、处理机器故障以及管理所需的机器间通信等细节.
1 介绍
分布式计算的输入数据很大, 处理并行计算、分发数据和处理故障等分布式所具有的问题掩盖了原本问题的简单计算.
MapReduce 使用用户指定的 map(映射) 和 reduce(归约) 操作的函数模型进行并行化大型计算, 并将重新执行作为主要的容错机制.
文章贡献:
- 可以实现大规模计算的自动并行化和分布式的简单而强大的接口 MapReduce, 结合该接口的实现可在大型商用 PC 集群上实现高性能
2 编程模型
MapReduce 编程模型
- 输入: 一组键值对
- 输出: 一组键值对
- M a p Map Map 函数: 用户编写, 接受一个输入键值对并生成一组中间键值对. MapReduce 库将与同一中间键关联的所有中间值组合在一起传递给 R e d u c e Reduce Reduce 函数.
- R e d u c e Reduce Reduce 函数: 用户编写, 接受中间键和该键的一组值, 将这些值合并在一起以生成一组可能更小(少)的值(通常每次调用只产生零个或一个输出值).
2.1 例子
单词计数
2.2 类型
m a p ( k 1 , v 1 ) → l i s t ( k 2 , v 2 ) r e d u c e ( k 2 , l i s t ( v 2 ) ) → l i s t ( v 2 ) \begin{aligned} &map(k1,v1)\rightarrow list(k2,v2)\\ &reduce(k2,list(v2))\rightarrow list(v2) \end{aligned} map(k1,v1)→list(k2,v2)reduce(k2,list(v2))→list(v2)
输入键值与输出键值来自不同的域, 中间键值与输出键值来自同一域. (以上述单词计数为例, 输入键值是文件名和文件内容, 中间键值是单词和对应的数量, 输出是单词的数量)
- 注: 此处的输入输出都是以单个 m a p map map 或 r e d u c e reduce reduce 函数来看的, 因此输入是一个键值对, 输出是一个值列表; 而对整个执行工作而言, 由于有多个 m a p map map 和 r e d u c e reduce reduce 任务, 因此整体输入是一组键值对, 输出也是一组键值对(每个 r e d u c e reduce reduce 对应一个输出列表).
2.3 更多例子
- 分布式 grep(文本搜索)
- URL 访问频率计数
- 反向网络链接图
- 每个主件的分词向量(Term-Vector)
- 倒排索引
- 分布式排序
3 实现
MapReduce 接口可根据环境有不同的实现.
3.1 执行概览
通过自动将输入数据划分为 M M M 个分片(splits)的集合, M a p Map Map 调用分布在多台机器上.
通过使用分区函数(如 h a s h ( k e y ) m o d R hash(key)\ mod\ R hash(key) mod R)将中间键空间划分为 R R R 个片段来分布 R e d u c e Reduce Reduce 调用. 分区数( R R R)和分区函数由用户指定.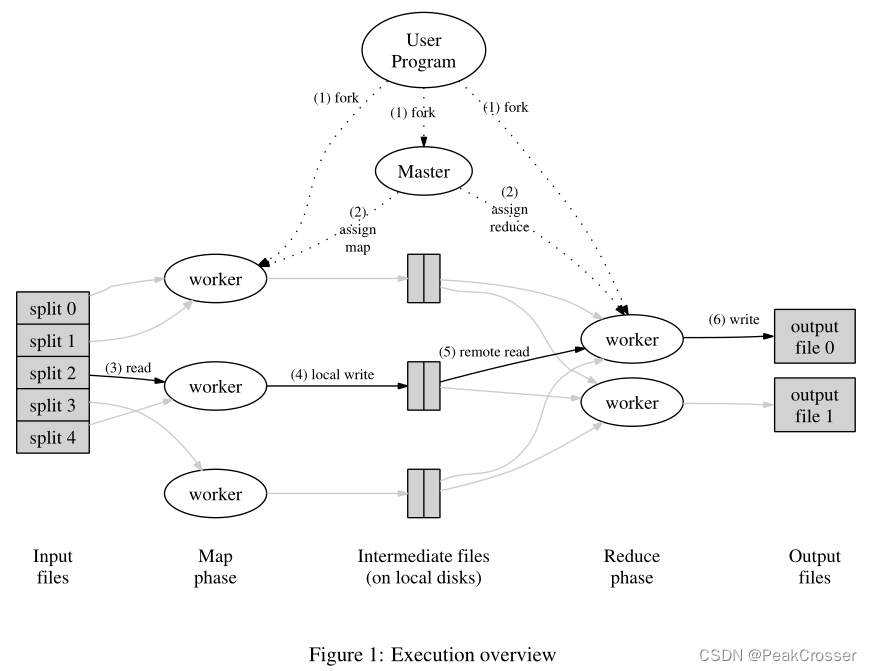
- 将输入的文件划分为 M M M 个分片
- 有一个主程序(master)和其余多个工作程序(worker). 有 M M M 个 map 任务和 R R R 个 reduce 任务需要要分配. master 挑选空闲的 worker 分配一个 map 或 reduce 任务. (注: 这里的主程序和工作程序的"程序"可以理解为一个"节点"或"线程")
- 执行 map 任务的 worker 从输入数据中解析出键值对并每一对传递给 M a p Map Map 函数. 产生的中间键值对缓存在内存中.
- 定期将缓存的中间键值对写入本地磁盘, 并通过分区函数将其分为 R R R 个分区. 这些缓冲对的位置被传回 master, master 将这些位置转发给 reduce worker
- reduce worker 被 master 通知中间键值的位置后, 使用远程过程调用从 map worker 的本地磁盘读取缓存的数据(中间键值对). 当读取完所有中间数据后会按中间键进行排序 通过排序将许多不同的键映射到同一个 reduce 任务. 数据从 map worker 到 reduce worker 的这一过程也被称作 shuffle(洗牌).
- reduce worker 遍历已排序的中间数据, 并对于遇到的每个唯一中间键将键和相应的中间值集合传递给用户的 R e d u c e Reduce Reduce 函数. 其函数输出被附加到这个 reduce 分区的最终输出文件中.
- 所有 map 任务和 reduce 任务都完成后, master 唤醒用户程序. 用户程序中的
MapReduce调用返回到用户代码.
成功完成 MapReduce 执行后, 执行的输出在 R R R 个输出文件中(每个 reduce 任务一个, 文件名由用户指定).
3.2 master 数据结构
存储每个 map 任务和 reduce 任务的状态(idle、in-process 或 completed), 和 worker 的身份(对于非空闲任务).
对于每个完成的 map 任务,存储 map 任务产生的 R R R 个中间文件的位置和大小.
3.3 容错
worker 故障
master 定期对每个工作节点进行 ping 操作. 若在一定时间内没有收到 worker 的响应, 则 master 将该 worker 标记为故障. 故障的 worker 上已完成的和进行中的 map 任务或进行中的 reduce 任务会被重置为空闲并有资格被重新调度.
已完成的 map 任务失败时需重新执行, 因为其输出存储在故障机器的本地磁盘上而无法访问. 已完成的 reduce 任务不需要重新执行, 因为其输出存储在全局文件系统中.
当有 map 任务执行失败时, 所有执行 reduce 任务的 worker 会收到重新执行的通知. 任何尚未从故障 map worker 读取数据的 reduce 任务将从重新执行该任务的 map worker 上读取数据.
master 故障
MapReduce 考虑到只有一个 master 发生故障的概率较小, 因此选择 master 故障时中止 MapReduce 计算.
出现故障时的语义
当用户提供的 map 和 reduce 运算符是其输入值的确定性函数时, MapReduce 产生的输出与整个程序的无故障顺序执行产生的输出相同.
依靠 map 和 reduce 任务输出的原子性提交(atomic commit)来实现这个属性.
当一个 reduce 任务完成时, reduce worker 自动将其临时输出文件重命名为最终输出文件. 依靠底层文件系统提供的原子重命名操作来保证最终的文件系统状态只包含一次 reduce 任务执行产生的数据.
当 map 和/或 reduce 是非确定性的运算符时, 特定 reduce 任务的输出等价于由非确定性程序在顺序执行下产生的任务输出(由于非确定性重新存在不同的执行顺序从而可能产生不同的任务输出).
- 注: 此处笔者理解为, 若计算可以转换成一个确定顺序的串行程序, 则 MapReduce 的输出与该串行程序相同; 若转换的串行程序不唯一, 则 MapReduce 的输出同样是这其中的一个.
3.4 局部性
MapReduce master 尝试在包含相应输入数据副本的机器上调度 map 任务, 若不能满足则会尝试在该任务输入数据的副本附近安排一个 map 任务.
大多数(map 任务的)输入数据都是在本地读取的, 且不消耗网络带宽.
3.5 任务粒度
map 阶段细分为 M M M 个片段, reduce 阶段细分为 R R R 个片段. 理想情况下 M M M 和 R R R 应远大于 worker 机器的数量.
实现中 M M M 和 R R R 的大小有实际限制, 因为 master 必须做出 O ( M + R ) O(M + R) O(M+R) 的调度决策并在内存中保持 O ( M ∗ R ) O(M*R) O(M∗R) 的状态.
R R R 经常受到用户的限制, 因为每个 reduce 任务的输出最终在一个单独的输出文件中.
3.6 备份任务
- Def: 落后者(straggler): 一台机器需要非常长的时间才能完成计算中最后几个 map 或 reduce 任务之一.
当 MapReduce 操作接近完成时, master 会安排备份执行剩余的进行中的任务
4 改进
4.1 分区函数
用户可以指定 reduce 任务/输出文件的数量 ( R R R).
4.2 顺序保证
在给定的分区内, 中间键/值对以递增的键顺序处理
4.3 组合器(Combiner)函数
某些情况下每个 map 任务产生的中间键存在显着的重复, 用户指定一个可选的 C o m b i n e r Combiner Combiner 函数在通过网络发送中间件数据之前对其进行部分合并.
C o m b i n e r Combiner Combiner 函数在每台执行 map 任务的机器上执行. 通常与 r e d u c e reduce reduce 函数代码相同, 区别在 combiner 函数的输出是写到中间文件中而非最终输出文件中.
4.4 输入输出类型
用户可以通过提供简单 r e a d e r reader reader 接口实现来添加对新输入类型的支持
4.5 副作用
在某些情况下, 生成辅助文件作为 map 和/或 reduce 运算符的附加输出很方便.
通常, 应用程序会写入一个临时文件, 并在该文件完全生成后自动重命名该文件.
4.6 跳过不良记录
MapReduce 库检测导致确定性崩溃的记录并跳过这些记录以向前推进.
每个 worker 进程会有一个信号处理程序, 用于捕获段违规和总线错误. 用户代码生成一个信号时,信号处理程序会向 master 发送一个包含序列号的"last gasp" UDP 数据包.
当 master 在特定记录上看到多个故障时, 下一次重新执行相应的 Map 或 Reduce 任务时应跳过该记录
4.7 本地执行
开发了 MapReduce 库的替代实现, 它在本地机器上按顺序执行 MapReduce 操作的所有工作, 以便于调试.
4.8 状态信息
master 运行一个内部 HTTP 服务器并导出一组显示计算进度的状态页面供人类使用.
4.9 计数器
MapReduce 库提供了一个计数器(Counter)工具来计算各种事件的发生次数.
来自各个 worker 机器的计数器值会定期传播到 master. master从成功的 map 和 reduce 任务中聚合计数器值, 并在 MapReduce 操作完成时将它们返回给用户代码.
笔者总结
本文的核心在于提出了分布式计算的通用接口 MapReduce. 同时利用了重复执行实现容错, 利用局部性优化减少网络通信, 通过备份加速计算等.
MapReduce 在 map 任务后的 shuffle(洗牌) 操作将中间键值按键名传输到相应的 reduce worker, 这一过程必然会导致网络通信, 且传输数据总量较大, 一定程度上是 MapReduce 的性能瓶颈.
MapReduce 整体看来扩展性良好且易于编程(分布式编程的细节被隐藏), 但不是最高效和灵活的(Ref: MIT 6.824 Lec1 Note)
边栏推荐
猜你喜欢
Data storage practice based on left-order traversal

大像素全景制作完成后,推广方式有哪些?

Countdown to 2 days|Cloud native Meetup Guangzhou Station, waiting for you!
静态方法获取配置文件数据
你要的七夕文案,已为您整理好!
冒泡排序与快速排序

人人都在说的数据中台,你需要关注的核心特点是什么?
![[Qixi Festival] Romantic Tanabata, code teaser.Turn love into a gorgeous three-dimensional scene and surprise her (him)!(send code)](/img/10/dafea90158adf9d43c4f025414fef7.png)
[Qixi Festival] Romantic Tanabata, code teaser.Turn love into a gorgeous three-dimensional scene and surprise her (him)!(send code)
Use SuperMap iDesktopX data migration tool to migrate ArcGIS data
【七夕节】浪漫七夕,代码传情。将爱意变成绚烂的立体场景,给她(他)一个惊喜!(送代码)
随机推荐
1667. Fix names in tables
QT:神奇QVarient
undo problem
1527. Patients suffering from a disease
【 genius_platform software platform development 】 : seventy-six vs the preprocessor definitions written cow force!!!!!!!!!!(in the other groups conding personnel told so cow force configuration to can
ASP.NET应用程序--Hello World
思考(八十八):使用 protobuf 自定义选项,做数据多版本管理
Linux下常见的开源数据库,你知道几个?
22-07-31周总结
J9 Digital Currency: What is the creator economy of web3?
undo问题
Syntax basics (variables, input and output, expressions and sequential statements)
解决端口占用问题 Port xxxx was already in use
Use SuperMap iDesktopX data migration tool to migrate map documents and symbols
How to sort multiple fields and multiple values in sql statement
Bubble Sort and Quick Sort
论治理与创新,2022 开放原子全球开源峰会 OpenAnolis 分论坛圆满落幕
Syntax basics (variables, input and output, expressions and sequential statement completion)
In 2022, you still can't "low code"?Data science can also play with Low-Code!
Cloud Native (32) | Introduction to Platform Storage System in Kubernetes