当前位置:网站首页>The worse the AI performance, the higher the bonus? Doctor of New York University offered a reward for the task of making the big model perform poorly
The worse the AI performance, the higher the bonus? Doctor of New York University offered a reward for the task of making the big model perform poorly
2022-07-05 18:40:00 【Zhiyuan community】
The bigger the model 、 The worse the performance, the better the prize ?
The total bonus is 25 Ten thousand dollars ( Renminbi conversion 167 ten thousand )?
such “ Out of line ” It really happened , A man named Inverse Scaling Prize( Anti scale effect Award ) The game of caused heated discussion on twitter .

The competition was organized by New York University 7 Jointly organized by researchers .
Originator Ethan Perez Express , The main purpose of this competition , It is hoped to find out which tasks will make the large model show anti scale effect , So as to find out some problems in the current large model pre training .
Now? , The competition is receiving contributions , The first round of submissions will end 2022 year 8 month 27 Japan .
Competition motivation
People seem to acquiesce , As the language model gets bigger , The operation effect will be better and better .
However , Large language models are not without flaws , For example, race 、 Gender and religious prejudice , And produce some fuzzy error messages .

The scale effect shows , With the number of parameters 、 The amount of computation used and the size of the data set increase , The language model will get better ( In terms of test losses and downstream performance ).
We assume that some tasks have the opposite trend : With the increase of language model testing loss , Task performance becomes monotonous 、 The effect becomes worse , We call this phenomenon anti scale effect , Contrary to the scale effect .
This competition aims to find more anti scale tasks , Analyze which types of tasks are prone to show anti scale effects , Especially those tasks that require high security .
meanwhile , The anti scale effect task will also help to study the potential problems in the current language model pre training and scale paradigm .
As language models are increasingly applied to real-world applications , The practical significance of this study is also increasing .
Collection of anti scale effect tasks , It will help reduce the risk of adverse consequences of large language models , And prevent harm to real users .
Netizen disputes
But for this competition , Some netizens put forward different views :
I think this is misleading . Because it assumes that the model is static , And stop after pre training .
This is more a problem of pre training on standard corpora with more parameters , Not the size of the model .

Software engineer James Agree with this view :
Yes , This whole thing is a hoax . Anything a small model can learn , Large models can also .
The deviation of the small model is larger , therefore “ Hot dogs are not hot dogs ” It may be recognized as 100% Right , When the big model realized that it could make cakes similar to hot dogs , The accuracy will drop to 98%.

James Even further proposed “ Conspiracy theories ” View of the :
Maybe the whole thing is a hoax —— Let people work hard , And show the training data when encountering difficult tasks , This experience will be absorbed by large models , Large models will eventually be better .
So they don't need to give bonuses , You will also get a better large-scale model .

Regarding this , Originator Ethan Perez Write in the comment :
Clarify it. , The focus of this award is to find language model pre training that will lead to anti scale effect , Never or rarely seen category .
This is just a way to use large models . There are many other settings that can lead to anti scale effects , Not included in our awards .

边栏推荐
猜你喜欢
Idea configuring NPM startup
技术分享 | 常见接口协议解析
Trust counts the number of occurrences of words in the file
技术分享 | 接口测试价值与体系
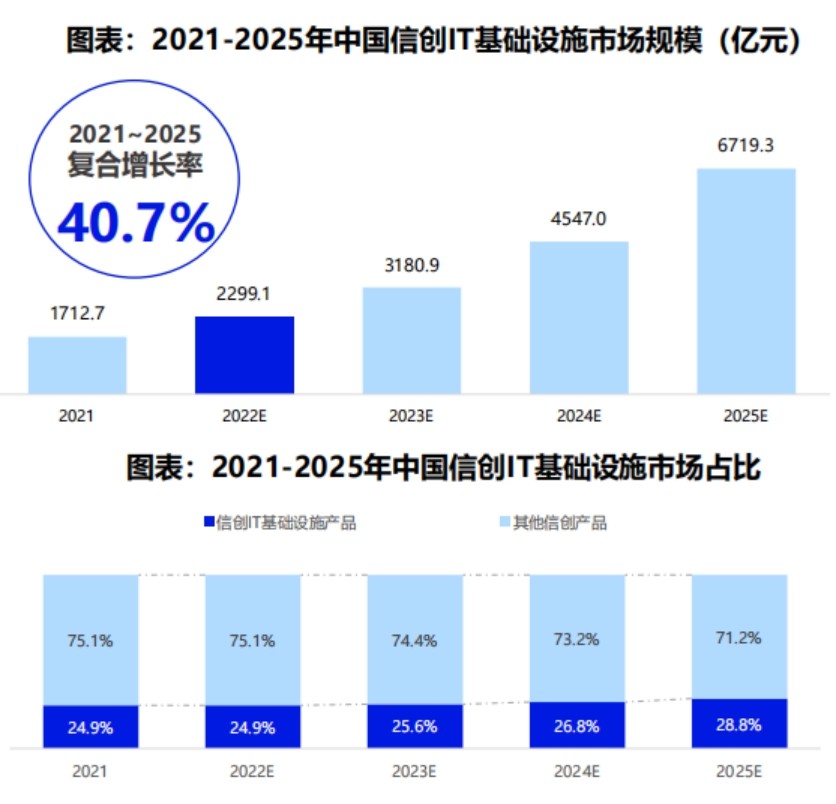
《2022中国信创生态市场研究及选型评估报告》发布 华云数据入选信创IT基础设施主流厂商!
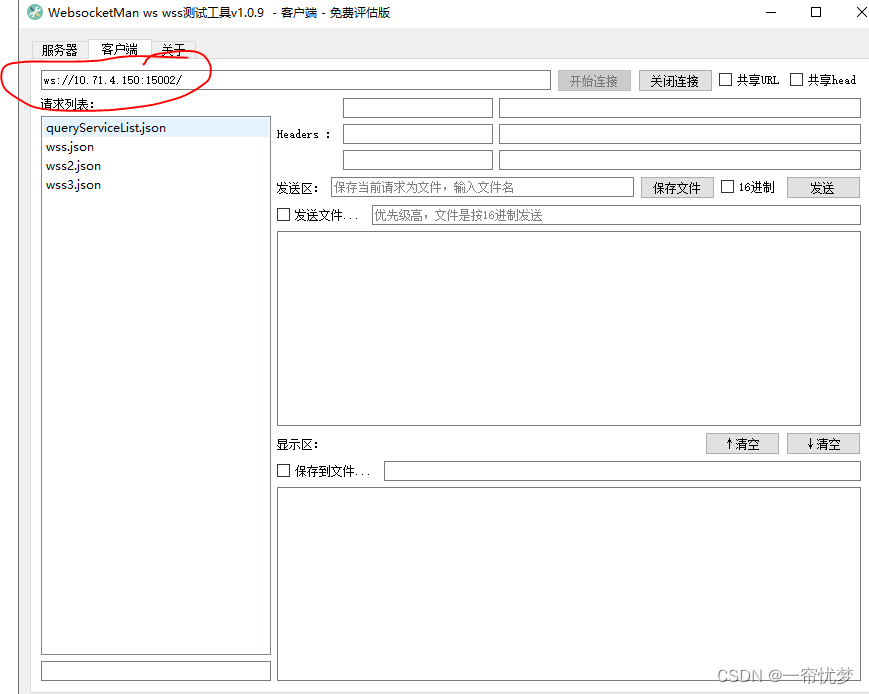
Use of websocket tool
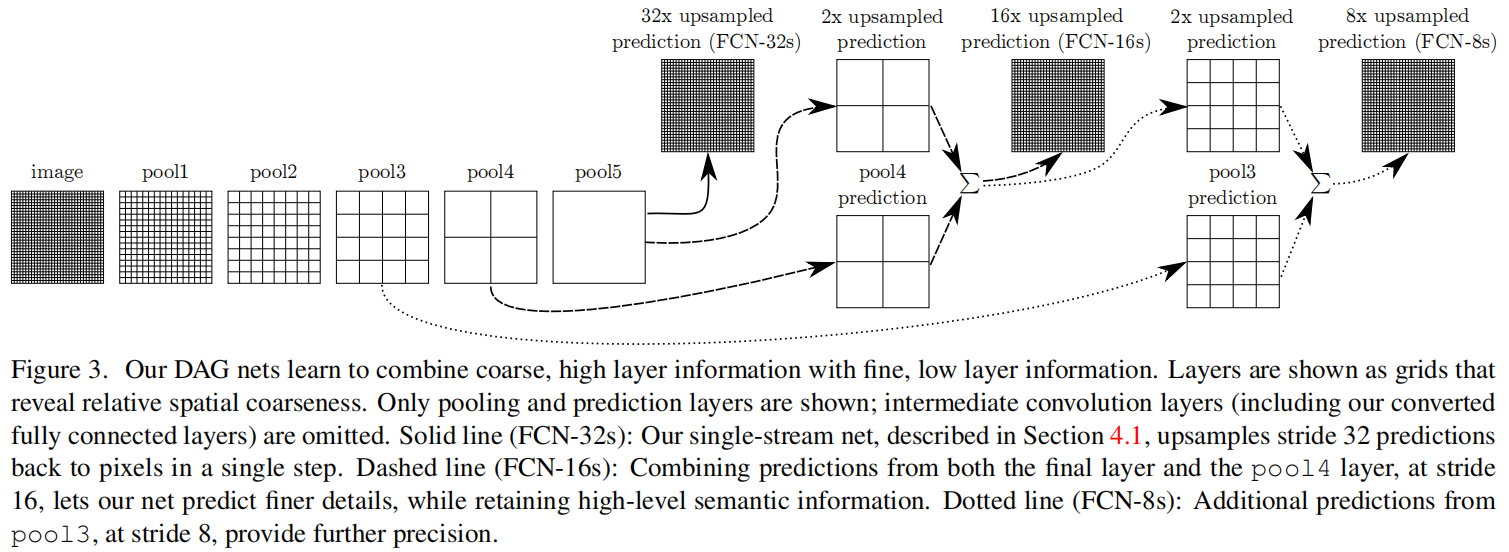
FCN: Fully Convolutional Networks for Semantic Segmentation
爬虫01-爬虫基本原理讲解
MYSQL中 find_in_set() 函数用法详解
Use JMeter to record scripts and debug
随机推荐
【在优麒麟上使用Electron开发桌面应】
音视频包的pts,dts,duration的由来.
Solutions contents have differences only in line separators
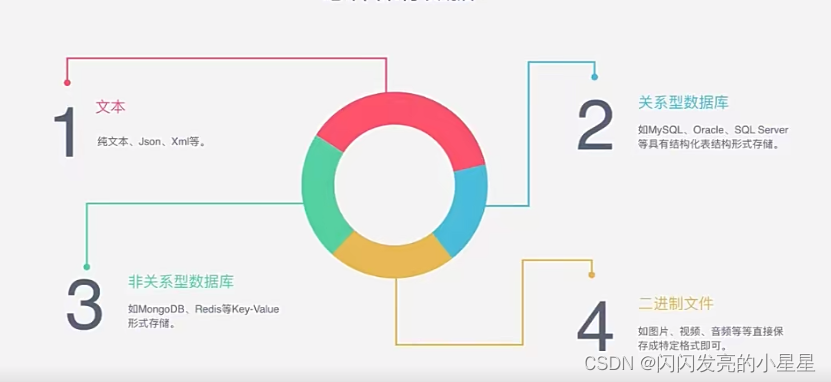
什么是文本挖掘 ?「建议收藏」
How to write good code defensive programming
写作写作写作写作
FCN: Fully Convolutional Networks for Semantic Segmentation
@Extension, @spi annotation principle
技术分享 | 接口测试价值与体系
7-1 链表也简单fina
Various pits of vs2017 QT
输油管的布置数学建模matlab,输油管布置的数学模型
Memory leak of viewpager + recyclerview
小程序 修改样式 ( placeholder、checkbox的样式)
[QNX hypervisor 2.2 user manual]6.3.2 configuring VM
[use electron to develop desktop on youqilin]
使用JMeter录制脚本并调试
Pytorch yolov5 training custom data
Is it safe to open an account, register and dig money? Is there any risk? Is it reliable?
常见时间复杂度