当前位置:网站首页>Flink 解析(四):恢复机制
Flink 解析(四):恢复机制
2022-07-06 09:32:00 【Stray_Lambs】
目录
Flink恢复机制
任何一个框架都存在出错的可能,所以都会有自己的一套恢复机制,例如Spark是采用血缘关系从头开始执行,如果有checkpoint就从checkpoint开始执行。Flink主要是根据每一个operator的状态以及全局的一个快照进行一个错误的恢复。
前提条件是Flink的checkpoint机制会与持久化存储进行交互,读写流与状态。
那么就需要:
- 一个能够回放一段时间内数据的持久化数据源,例如持久化消息队列(例如 Apache Kafka、RabbitMQ、 Amazon Kinesis、 Google PubSub 等)或文件系统(例如 HDFS、 S3、 GFS、 NFS、 Ceph 等)。
- 存放状态的持久化存储,通常为分布式文件系统(比如 HDFS、 S3、 GFS、 NFS、 Ceph 等)。
Checkpoint是什么
要了解Flink的恢复机制,首先我们需要了解,什么是Checkpoint。Checkpoint是Flink的检查点,是根据配置文件周期性基于Stream中各个Operator的状态而产生的全局性的SnapShot快照。然后定期持久化的存储到一些外设中,一旦Flink程序出现崩溃状态,则可以通过选择这些SnapShot快照进行快速恢复,从而修正因故障所产生的程序数据中断问题。其中,Flink的CheckPoint机制原理主要是来源于“Chandy-Lamport algorithm”。
这里简单介绍一下这个算法,首先这个算法的目标就是为了保证产生的快照必须具有一致性,并且不能stop the world,即不能影响程序的正常执行。其中分为三个阶段,初始化快照、扩散快照与完成快照。具体的详情就需要大家去看看其他文献了,这里就不多赘述了。
这里顺便区分一个概念,就是State与Checkpoint的关系。
State一般指的是一个具体的Task/Operator的状态(operator的状态表示一些算子在运行的过程中会产生的一些中间结果)。而State的数据默认是存储在了Java的堆内存/TaskManage的节点内存中,并且State可以被记录,在失败中可以用于恢复数据。有点局部状态的感觉。
Checkpoint有点类似与全局状态的感觉。表示的是一个FlinkJob在某个特定的时刻的一份全局快照,即保存了所有的Task/Operator的状态。可以理解为将所有的某个时刻的State持久化存储到外设中。
Savepoint保存点
Savepoint是基于Flink检查点机制的应用完整快照备份机制。主要是用来保存某个集群的某个时刻的状态,使得集群从保存的状态恢复回来。一般工程上用于应用升级、集群迁移、Flink版本更新、A/B测试等等。保存点可以理解为是一个Map(算子ID -> State),其中的算子是有状态的算子。
由于一两句难以说明sp与cp的区别,我直接上个链接……
检查点协调器
Flink中存在CheckpointCoordinator,主要是负责协调Flink算子的State的分布式快照。当触发形成快照的时候,CheckpointCoordinator向输入端Source算子注入Barrier消息,也就是栅栏,区分前后两个批次的数据。然后当所有的Task任务中的检查点都确认完成后,所有的Task将会上报State句柄。
Checkpoint
Checkpoint保存什么信息
Checkpoint中其实主要是保存第i次已经消费到的offset信息,以及每个Task中对应的键值对信息,即一些连接器(connectors)、窗口以及任何用户自定义的状态。记录发生的Checkpoint当前的状态,并且存储到对用的状态后端中(具体什么是状态后端,立个flag,后续详细写一下…)。
Checkpoint如何保存信息
Flink采用异步barrier快照的方式来产生快照信息。当JobManager中的Checkpoint coordinator让taskManager开始进行checkpoint的时候,会让所有的source端记录他们的偏移量,并且会产生一个递增编号的checkpoint barriers插入到source的流中。这些barriers栅栏主要是区分每个checkpoint前后流,并且每个barrier都会携带一个其所属的快照ID编号。比如,Checkpoint n将包含每个operator的state,并且对应的opertor算子一定表示消费了checkpoint barrier n之前的所有事件,并且不包含n之后的任何事件产生的状态。
当Barrier从数据流源头被注入并行数据流中之后,Barrier会随着向下游传递,遇到非数据源算子后,所有的输入流中收到了快照n的Barrier时,该算子就会对自己的State快照保存,并且向自己的下游广播发送快照n的Barrier。直到Sink算子接收到Barrier后,就会有两种情况。
(1)如果是引擎内严格一次处理保证,当 Sink 算子已经收到了所有上游的 Barrie n 时, Sink 算子对自己的 State 进行快照,然后通知检查点协调器( CheckpointCoordinator) 。当所有的算子都向检查点协调器汇报成功之后,检查点协调器向所有的算子确认本次快照完成。
(2)如果是端到端严格一次处理保证,当 Sink 算子已经收到了所有上游的 Barrie n 时, Sink 算子对自己的 State 进行快照,并预提交事务(两阶段提交的第一阶段),再通知检查点协调器( CheckpointCoordinator) ,检查点协调器向所有的算子确认本次快照完成,Sink 算子提交事务(两阶段提交的第二阶段),本次事务完成。
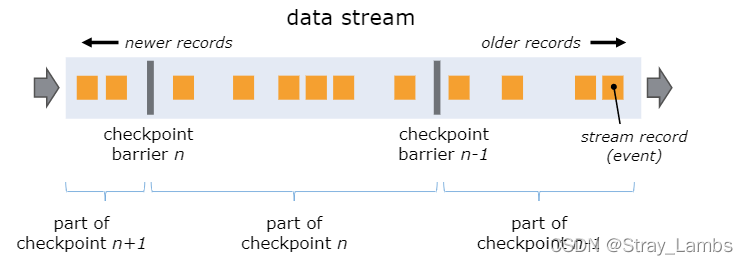
当job graph中的每个operator都接收到了barriers的数据时,就会记录下其当时状态。如果某个算子拥有两个及以上的输入流(例如CoProcessFunction)会执行barrier对齐,以便确定当前快照能够包含消费输入流check barrier n之前(但不超过)的所有事件而产生的状态。
Barrier 对齐
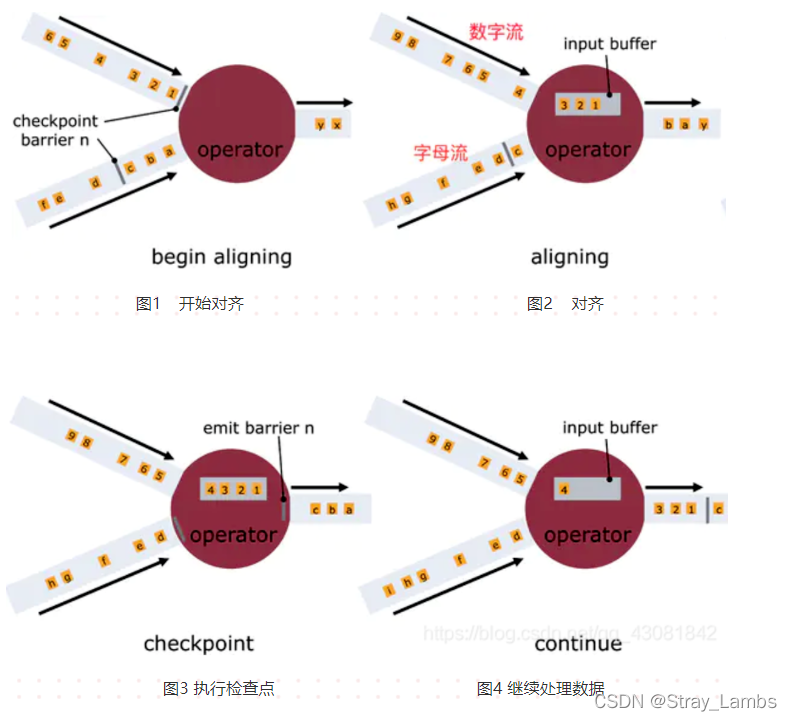
一旦Operator从输入流接收到CheckPoint barrier n,它就不能处理来自该流的任何数据记录,直到它从其他所有输入接收到barrier n为止。否则,它会混合属于快照n的记录和属于快照n + 1的记录;
如上图所示:
图1,算子收到数字流的Barrier,字母流对应的barrier尚未到达
图2,算子收到数字流的Barrier,会继续从数字流中接收数据,但这些流只能被搁置,记录不能被处理,而是放入缓存中,等待字母流 Barrier到达。在字母流到达前, 1,2,3数据已经被缓存。
图3,字母流到达,算子开始对齐State进行异步快照,并将Barrier向下游广播,并不等待快照执行完毕。
图4,算子做异步快照,首先处理缓存中积压数据,然后再从输入通道中获取数据。
那么什么时候需要Barrier对齐,什么时候不需要呢。
barrier不对齐:就是指当还有其他流的barrier还没到达时,为了不影响性能,也不用理会,直接处理barrier之后的数据。等到所有流的barrier的都到达后,就可以对该Operator做CheckPoint了;
如上面所说,barrier不对齐就会有可能重复消费的情况出现,因为不需要等待落后的数据,导致部分数据可能存在重复消费的情况。如果需要Exactly once的场景,那么必须要barrier 对齐,如果可以at least once 则可以不需要barrier 对齐。
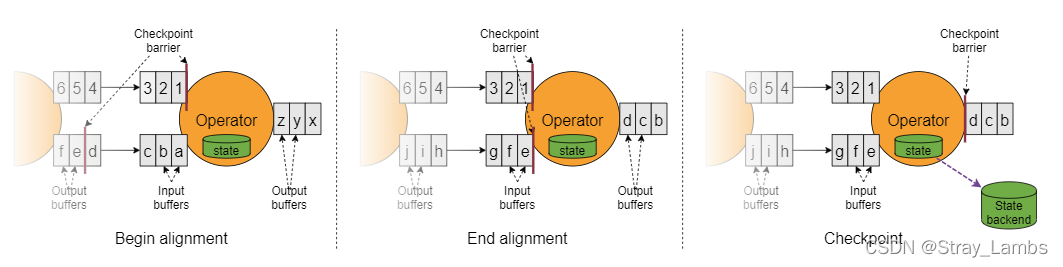
Flink中状态后端采用写时复制(copy-on-write)机制允许当异步生成旧版本的状态快照时,能够不受影响地继续流处理。只有当快照被持久保存之后,旧版本的状态才会被垃圾回收。
精准一次性(exactly once)
当流处理应用程序发生错误的时候,结果可能会产生丢失或者重复。Flink 根据你为应用程序和集群的配置,可以产生以下结果:
- Flink 不会从快照中进行恢复(at most once)
- 没有任何丢失,但是你可能会得到重复冗余的结果(at least once)
- 没有丢失或冗余重复(exactly once)
Flink 通过回退和重新发送 source 数据流从故障中恢复,当理想情况被描述为精确一次时,这并不意味着每个事件都将被精确一次处理。相反,这意味着 每一个事件都会影响 Flink 管理的状态精确一次。
Barrier 只有在需要提供精确一次的语义保证时需要进行对齐(Barrier alignment)。如果不需要这种语义,可以通过配置 CheckpointingMode.AT_LEAST_ONCE 关闭 Barrier 对齐来提高性能。
端到端精准一次
为了实现端到端的精确一次,以便 sources 中的每个事件都仅精确一次对 sinks 生效,必须满足以下条件:
- 你的 sources 必须是可重放的
- 你的 sinks 必须是事务性的(或幂等的)
Job失败后,从检查点恢复
Flink提供了应用自动恢复机制以及手动作业恢复机制。
应用自动恢复机制
Flink设置有作业失败重启策略,包含三种
- 定期恢复策略:fixed-delay。 固定延迟重启策略会尝试一个给定的次数来重启Job,如果超过最大的重启次数,Job最终将失败,在连续两次重启尝试之间,重启策略会等待一个固定时间,默认Integer.MAX_VALUE次
- 失败比率策略:failure-rate。失败率重启策略在job失败后重启,但是超过失败率后,Job会最终被认定失败,在两个连续的重启尝试之间,重启策略会等待一个固定的时间。
- 直接失败策略:None 失败不重启。
手动作业恢复机制
因为Flink检查点目录分别对应的是JobId,每通过flink run 方式/页面提交方式恢复都会重新生成 jobId,Flink 提供了在启动之时通过设置 -s .参数指定检查点目录的功能,让新的 jobld 读取该检查点元文件信息和状态信息,从而达到指定时间节点启动作业的目的。
Job失败后,从保存点恢复机制
从保存点恢复作业并不简单,尤其是在作业变更(如修改逻辑、修复 bug) 的情况下, 需要考虑如下几点:
(1)算子的顺序改变
如果对应的 UID 没变,则可以恢复,如果对应的 UID 变了恢复失败。
(2)作业中添加了新的算子
如果是无状态算子,没有影响,可以正常恢复,如果是有状态的算子,跟无状态的算子 一样处理。
(3)从作业中删除了一个有状态的算子
默认需要恢复保存点中所记录的所有算子的状态,如果删除了一个有状态的算子,从保存点回复的时候被删除的OperatorID找不到,所以会报错 可以通过在命令中添加
-- allowNonReStoredSlale (short: -n )跳过无法恢复的算子 。
(4)添加和删除无状态的算子
如果手动设置了 UID 则可以恢复,保存点中不记录无状态的算子 如果是自动分配的 UID ,那么有状态算子的可能会变( Flink 一个单调递增的计数器生成 UID,DAG 改版,计数器极有可能会变) 很有可能恢复失败。
参考
边栏推荐
- Basic knowledge of assembly language
- On the clever use of stream and map
- When it comes to Google i/o, this is how ByteDance is applied to flutter
- redux使用说明
- Activiti directory (III) deployment process and initiation process
- The "advertising maniacs" in this group of programmers turned Tiktok advertisements into ar games
- Which is more important for programming, practice or theory [there are some things recently, I don't have time to write an article, so I'll post an article on hydrology, and I'll fill in later]
- Activiti目录(一)重点介绍
- 唯有學C不負眾望 TOP5 S1E8|S1E9:字符和字符串&&算術運算符
- Mongodb在node中的使用
猜你喜欢
![Which is more important for programming, practice or theory [there are some things recently, I don't have time to write an article, so I'll post an article on hydrology, and I'll fill in later]](/img/a1/7dd41e75d6768159317b65e436030d.jpg)
Which is more important for programming, practice or theory [there are some things recently, I don't have time to write an article, so I'll post an article on hydrology, and I'll fill in later]
字节跳动海外技术团队再夺冠:高清视频编码已获17项第一
手把手带你做强化学习实验--敲级详细

字节跳动春招攻略:学长学姐笔经面经,还有出题人「锦囊」

Redis standalone startup
Solr word segmentation analysis
算数运算指令
Some instructions on whether to call destructor when QT window closes and application stops

吴军三部曲见识(四) 大家智慧
8086 CPU 内部结构
随机推荐
The 116 students spent three days reproducing the ByteDance internal real technology project
Idea breakpoint debugging skills, multiple dynamic diagram package teaching package meeting.
吴军三部曲见识(五) 拒绝伪工作者
逻辑运算指令
肖申克的救赎有感
搭建flutter环境入坑集合
Activiti目录(五)驳回、重新发起、取消流程
一个数10年工作经验的微服务架构老师的简历
在 vi 编辑器中的命令模式下,删除当前光标处的字符使用 __ 命 令。
Assembly language segment definition
Activiti目录(四)查询代办/已办、审核
Login to verify the simple use of KOA passport Middleware
MySQL string function
原型链继承
汇编语言段定义
On the clever use of stream and map
Interview collection library
Compile homework after class
MySQL字符串函数
Data transfer instruction