当前位置:网站首页>Handling Write Conflicts under Multi-Master Replication (1)-Synchronous and Asynchronous Conflict Detection and Conflict Avoidance
Handling Write Conflicts under Multi-Master Replication (1)-Synchronous and Asynchronous Conflict Detection and Conflict Avoidance
2022-07-31 16:39:00 【HUAWEI CLOUD】
The biggest problem of multi-master replication: write conflicts may occur, which must be resolved.
For example, two users edit the wiki at the same time, as shown in Figure-7.User 1 changes the page title from A->B, and User 2 changes the title from A->C at the same time.Each user's changes are successfully committed to the local master node.But when asynchronously replicating to each other, a conflict is found.Normal master-slave replication does not have this problem.
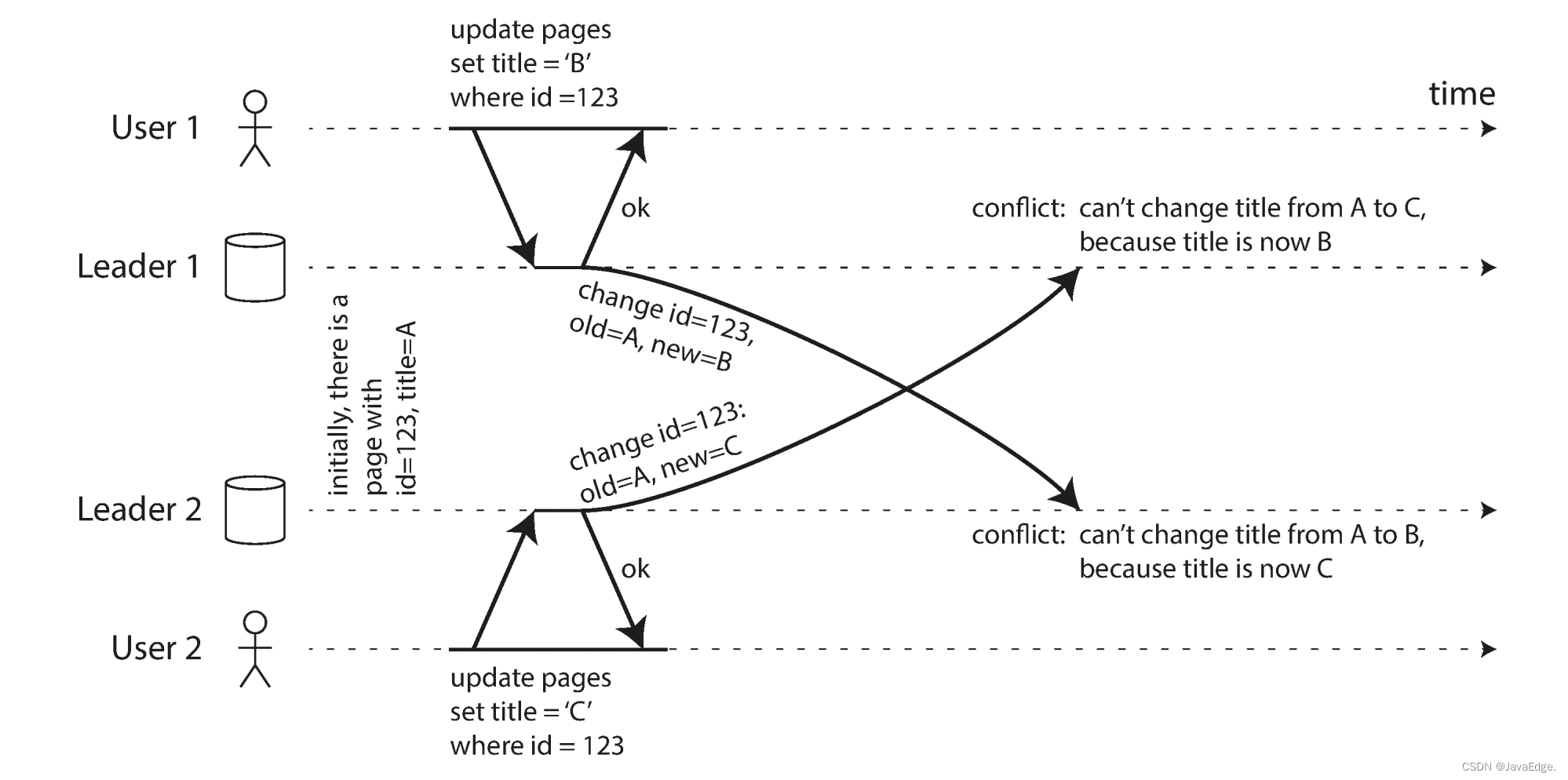
3.2.1 Synchronous and asynchronous conflict detection
If a master-slave replicated database, the second write request will:
- Blocks until the first write is complete
- Or aborted, forcing the user to retry
Under the multi-master replication model, both writes succeed, and conflicts can only be detected asynchronously at a later point in time, when it is too late to ask the user to resolve the conflict.
Theoretically, synchronization conflict detection can be achieved, that is, waiting for the write request to complete the synchronization of all replicas, and then notifying the user that the write is successful.But this will lose the advantage of multi-master: allowing each master to accept write requests independently.Therefore, if you really need synchronization conflict detection, you should consider using master-slave replication with a single master node!
3.2.2 Avoiding conflicts
The best strategy for dealing with conflicts: avoid them, if the application layer can guarantee that all write requests for a particular record go through the same master, there will be no conflicts.In practice, due to the poor conflict resolution implemented by many primary replication models, direct conflict avoidance is the recommended preferred solution.
If users need to edit their own data, it can ensure that requests from specific users are always routed to a specific IDC and read/write using the primary node of that IDC.Different users may correspond to different primary data centers (for example, according to the user's geographic location), but from the user's point of view, this is basically equivalent to the master-slave replication model.
However, it may sometimes be necessary to change the pre-designated primary node, possibly because:
- IDC failure, traffic needs to be rerouted to another IDC
- Or possibly because the user has roamed to another location, near a different IDC
At this time, the conflict avoidance method is no longer effective, and there must be a plan to deal with the possibility of simultaneous writing by different master nodes.
边栏推荐
- .NET 20th Anniversary Interview - Zhang Shanyou: How .NET technology empowers and changes the world
- 动态规划之线性dp(下)
- [TypeScript] In-depth study of TypeScript type operations
- LevelSequence源码分析
- 6-22漏洞利用-postgresql数据库密码破解
- 关于柱状图的经典画法总结
- tooltips使用教程(鼠标悬停时显示提示)
- .NET 20周年专访 - 张善友:.NET 技术是如何赋能并改变世界的
- tensorflow2.0 cnn(layerwise)
- jeecg主从数据库读写分离配置「建议收藏」
猜你喜欢
动态规划(一)
C language "the third is" upgrade (mode selection + AI chess)
动态规划之线性dp(上)

.NET 20th Anniversary Interview - Zhang Shanyou: How .NET technology empowers and changes the world
.NET 20周年专访 - 张善友:.NET 技术是如何赋能并改变世界的

LevelSequence源码分析

GP 6总体架构学习笔记

T - sne + data visualization parts of the network parameters
SringMVC中个常见的几个问题
上传图片-微信小程序(那些年的坑记录2022.4)
随机推荐
【C语言】LeetCode27.移除元素
How to switch remote server in gerrit
How Redis handles concurrent access
【Yugong Series】July 2022 Go Teaching Course 020-Array of Go Containers
【7.28】代码源 - 【Fence Painting】【合适数对(数据加强版)】
牛客网刷题(一)
i.MX6ULL驱动开发 | 33 - NXP原厂网络设备驱动浅读(LAN8720 PHY)
LeetCode_733_Image rendering
Premiere Pro 2022 for (pr 2022)v22.5.0
[TypeScript]OOP
【网络通信三】研华网关Modbus服务设置
最后写入胜利(丢弃并发写入)
arm按键控制led灯闪烁(嵌入式按键实验报告)
Stuck in sill idealTree buildDeps during npm installation, npm installation is slow, npm installation is stuck in one place
GP 6 overall architecture study notes
go图书管理系统
【pytorch】pytorch 自动求导、 Tensor 与 Autograd
Implementing distributed locks based on Redis (SETNX), case: Solving oversold orders under high concurrency
复杂高维医学数据挖掘与疾病风险分类研究
C语言-函数