当前位置:网站首页>CV learning notes - deep learning
CV learning notes - deep learning
2022-07-03 10:08:00 【Moresweet cat】
Deep learning
1. neural network
1. summary
Cited example : Mechanism of biological neural network
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-AInTSLwa-1639290184011)(./imgs/image-20211212115335280.png)]](/img/ae/5039857d77dacd95e0b34c677c8e6c.jpg)
The basic working principle of biological neural network :
There are multiple dendrites at the input of a neuron , It is mainly used to receive input information . Input information is processed by synapse , The letter to be entered
Interest accumulation , When the processed input information is greater than a specific threshold , It will transmit information through axons , At this time, it is called neuron
To be activated . contrary , When the processed input information is less than the threshold , Neurons are in a state of inhibition , It doesn't transmit like other neurons
Information . Or send a small message .
Artificial neural network :
Artificial neural network is divided into two stages :
- Receive from others n Signals from neurons , These input signals are matched with corresponding weights
The weighted sum is passed to the next stage .( Pre activation phase ) It's the sum - Pass the weighted result of pre activation to the activation function It's the f
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-D3HZgd1V-1639290184013)(./imgs/image-20211212115838916.png)]](/img/3c/17be54376fc389449e0e3dab06ad54.jpg)
The concepts of artificial neural network and biological neural network correspond :
| Biological neural networks | Artificial neural network |
|---|---|
| nucleus | Neuron |
| Dendrites | Input |
| axon | Output |
| synaptic | The weight |
Artificial neuron :
Input : x 1 , x 2 , x 3 x_1,x_2,x_3 x1,x2,x3
Output :output
simplified model : Agree that there are only two possibilities for each input (1 or 0)
- All inputs are 1, Indicates that the input conditions are all true , Output is 1
- All inputs are 0, Indicates that none of the input conditions is true , Output is 0
【 example 】 Judge whether watermelon is good or bad
Input :[ Color : dark green , roots : Curl up , Knock sound : Murmur ]
Output : Good melon (1)
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-G8idRLM6-1639290184013)(./imgs/image-20211212120934112.png)]](/img/60/e4c50e2e9f6f42486d9c98e3a45cb9.jpg)
neural network : It is formed by interconnected neurons , These neurons have weights and errors during network training
To update the deviation , The goal is to find an approximation of an unknown function . Its principle is influenced by the physiological structure of our brain —— Cross connected neurons inspire . But unlike a neuron in the brain that can connect to any neuron within a certain distance ,
Artificial neural networks have discrete layers 、 Direction of connectivity and data dissemination .
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-kEwQDHo9-1639290184014)(./imgs/image-20211212121126020.png)]](/img/77/ed87dc9fa46b8c1989729239e4cdee.jpg)
2. Types of neural networks
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-e7vYBlCT-1639290184015)(./imgs/image-20211212121223368.png)]](/img/a8/4701d07aa1112f52839620d2508143.jpg)
3. Neuron
Neuron is the most basic unit of neural network , It originated from the human body , Imitate human neurons , Function is also related to the God of the human body
Jing Yuan is consistent , Get the input of the signal , After data processing , Then give a result as output or as the next neuron
Input .
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-hiiMJbGa-1639290184016)(./imgs/image-20211212121510691.png)]](/img/c8/d46b0fc9a19b963eaf19a3e1f9919e.jpg)
4. Parameters in neural networks
Input : It's the eigenvector . The eigenvector represents the direction of change . Or say , Is the most representative of the characteristics of this thing
towards .
The weight ( A weight ): It's characteristic value . There are positive and negative , Strengthen or suppress , Same as eigenvalue . The absolute value of the weight , generation
The influence of input signal on neurons is shown in table .
The essence : When the vector is n Dimensional space time , That is, the input vector and the weight vector are n dimension , That is to say n Inputs 、 Weight time , Yes
h = ( x 1 , x 2 , . . . ) ( ω 1 , ω 2 , . . . ) T + b h=(x_1,x_2,...)(\omega_1,\omega_2,...)^T+b h=(x1,x2,...)(ω1,ω2,...)T+b
Neurons are when h Greater than 0 Time output 1,h Less than 0 Time output 0 Such a model , Its essence is to divide the feature space into two parts , Think that the two halves belong to two classes respectively .
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-SNtVyfZP-1639290184017)(./imgs/image-20211212123438000.png)]](/img/2d/07f4332be5ef6a6006f9ea5dc1857c.jpg)
5. Multilayer neural network
Because neurons can only divide the feature space into two , In the face of complex problems , This method obviously cannot meet the demand , Therefore, a multilayer neural network is proposed .
Neural network is a kind of operation model , By a large number of nodes ( Neuron ) And the mutual connection between . The connection between each two nodes represents a weighted value for the signal passing through the connection , Call it weight , This is equivalent to the memory of the artificial neural network .
The output of the network depends on the connection mode of the network , The weight value is different from the excitation function . The network itself is usually an approximation to some algorithm or function in nature , It could also be an expression of a logical strategy .
Single layer neural network ( perceptron )
Multilayer neural network : Neural network is composed of multiple neurons , The result of the former neuron is the input of the latter neuron , Combined in turn . The neural network is generally divided into three layers , The first layer acts as the input layer , The last layer is the output layer , All in the middle are hidden layers .
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-XFIs8kRh-1639290184017)(./imgs/image-20211212124026024.png)]](/img/d5/036a07c21126cb6c1e16b8c2e7e416.jpg)
Theoretical proof , Any multilayer network can be approximately represented by a three-layer network .
Generally, experience is used to determine how many nodes the hidden layer should have , In the process of testing, you can also constantly adjust the number of nodes to achieve the best results .
6. Feedforward neural networks
The artificial neural network model mainly considers the topology of network links 、 Neuron characteristics 、 Learn the rules, etc .
Feedforward neural networks : Feedforward neural networks (FNN) It is the first type of simple artificial neural network invented in the field of artificial intelligence . Inside it , Parameters propagate unidirectionally from the input layer through the hidden layer to the output layer . Unlike Recurrent Neural Networks , It will not form a directed ring inside . The following figure shows a simple feedforward neural network :
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-N9MiB4zc-1639290184018)(./imgs/image-20211212124549670.png)]](/img/71/8002631ba648ebfd8db11decf35011.jpg)
FNN By an input layer 、 One ( Shallow networks ) Or more ( Deep networks , Therefore, it is called deep learning ) Hidden layer , And an output layer . Every layer ( Except for the output layer ) Connect with the next layer . This connection is FNN The key to architecture , It has two main characteristics : Weighted average and activation function .
Classification of Feedforward Neural Networks :
- ( monolayer ) perceptron
There is only a single-layer neural network , It is regarded as the simplest form of feedforward neural network , It is a binary linear classifier .
- Multilayer perceptron
It is an artificial neural network with forward structure , It can be seen as a directed graph , It consists of multiple node layers , Each layer is fully connected to the next layer . In addition to the input node , Each node is a neuron with nonlinear activation function ( Or processing unit ), It is the generalization of single-layer perceptron , It overcomes the weakness that the perceptron can not recognize the linear inseparable data .
7. Design Neural Networks
- Before using neural network training data , The number of layers of neural network must be determined , And the number of units per level
- When the feature vector is introduced into the input layer, it is usually standardized to 0-1 Between ( To speed up the learning process )
- Discrete variables can be encoded into the possible values of an eigenvalue corresponding to each input unit
such as : The eigenvalue A I could take three values ( a 0 , a 1 , a 2 ) (a_0,a_1,a_2) (a0,a1,a2), have access to 3 The input units represent A.
If A= a 0 a_0 a0, So on behalf of a 0 a_0 a0 The cell value of 1, Other take 0;1,0,0
If A= a 1 a_1 a1, So on behalf of a 1 a_1 a1 The cell value of 1, Other take 0, And so on 0,1,0 - Neural network can be used for classification (classification) problem , You can also solve regression (regression) problem
- For the classification problem , If it is 2 class , It can be represented by an output unit (0 and 1 Represent the 2 class ); If more than 2 class , Then every
A category is represented by an output unit Such as 001 - There are no clear rules to design how many hidden layers are best , It can be tested and improved according to the experimental test, error and accuracy .
- For the classification problem , If it is 2 class , It can be represented by an output unit (0 and 1 Represent the 2 class ); If more than 2 class , Then every
8. Perceptual knowledge of the hidden layer
For example, face recognition :
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-vu500Pmg-1639290184019)(./imgs/image-20211212140841263.png)]](/img/74/bd1ecd4ca6292fa1df342e82437fd9.jpg)
Each of the above subnetworks , It can also be further decomposed into smaller problems , For example, the question of whether the upper left is an eye , Can be divided into
The solution is :
- Do you have eyeballs ?
- Do you have eyelashes ?
- Do you have iris ?
- …
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-FgbUcWOq-1639290184020)(./imgs/image-20211212141006509.png)]](/img/2e/5e826eaa515b740706c323d034b6b0.jpg)
This sub network can be further decomposed ,. Decompose layer after layer , Until the answer is simple enough to be answered on a single neuron .
2. Activation function
1. summary
The state of neurons : In the neural network , Neurons in active state are called active state , Neurons that are inactive are called inhibitory . Activation function endows neurons with the ability of self-learning and adaptation .
The function of activation : The function of activation function is to introduce nonlinear learning and processing ability into neural network . Activation function is a core unit of neural network design .
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-ncqZioI3-1639290184021)(./imgs/image-20211212125111919.png)]](/img/21/4c81b683c05fc56ff0d8f08d64aaf2.jpg)
With sigmoid Activation function y = 1 1 + e − x y=\frac{1}{1+e^{-x}} y=1+e−x1 For example :
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-zDkDp4Oc-1639290184021)(./imgs/image-20211212125255988.png)]](/img/34/b72dda71b7fd1508ff199174ee7f62.jpg)
2. Commonly used activation functions
There are three conditions for activating a function
- nonlinear
- It's very small
- monotonous
- sigmoid function
y = l o g s i g ( x ) = 1 1 + e − x y=logsig(x)=\frac{1}{1+e^{-x}} y=logsig(x)=1+e−x1
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-FLvgDoyw-1639290184022)(./imgs/image-20211212125825978.png)]](/img/5e/03e4f3686e399ef1074c8c27e38c5f.jpg)
sigmoid There are two main disadvantages :
- Gradient saturated , Look at the picture , The gradient of values on both sides is 0;
- The average value of the results is not 0, This is what we don't want , Because this causes the input of neurons in the posterior layer to be true or false
0 Mean signal , This will have an impact on the gradient .
- tanh function
y = t a n s i g ( x ) = e x − e − x e x + e − x y=tansig(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}} y=tansig(x)=ex+e−xex−e−x
t a n h ( x ) = 2 σ ( 2 x ) − 1 tanh(x)=2\sigma(2x)-1 tanh(x)=2σ(2x)−1
- ReLU function ( Linear rectifier layer )
f ( x ) = m a x ( 0 , x ) f(x)=max(0,x) f(x)=max(0,x)
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-pxAev16c-1639290184024)(./imgs/image-20211212130126400.png)]](/img/7f/0f7cd07ddbfa2ab7624a8fb586f4fa.jpg)
3. Comparison of activation functions
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-PoT12YCn-1639290184024)(./imgs/image-20211212130334551.png)]](/img/71/f06f15c08c1aa41017dac29462df30.jpg)
4. Neurons are sparse
Unilateral inhibition :ReLU A function is actually a piecewise linear function , Change all negative values to 0, And the positive value remains the same , This operation is called unilateral inhibition .
Because of this unilateral inhibition , So that the neurons in the neural network also have Sparse activation .( Simulate the characteristics of the human brain , At the same time , There are only neurons in human brain 1%~4% To be activated , Most of them are in a state of inhibition )
When the model increases N After the layer , Theoretically ReLU The activation rate of neurons will decrease 2 Of N Times the power .
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-uH0AUHLv-1639290184025)(./imgs/image-20211212130557795.png)]](/img/cb/246b307cd529b4ad69af1f51ad42a3.jpg)
3. Deep learning
machine learning & Artificial intelligence & Deep learning :
Machine learning is the core of artificial intelligence , A discipline that studies how to use machines to simulate human learning activities .
Deep learning ( Multilayer artificial neural network ) It's a branch of machine learning , The method of representational learning of data .
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-NeYdwqf6-1639290184025)(./imgs/image-20211212115159593.png)]](/img/82/704551500af925a84eb1bdcf6a9803.jpg)
Deep neural network & Deep learning : The traditional neural network has developed to the case of multiple hidden layers , Neural networks with multiple hidden layers are called deep neural networks , The research of machine learning based on deep neural network is called deep learning . If you need to refine and differentiate , that , Deep neural network can be understood as the structure of traditional multilayer network 、 Optimization of methods .
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-j6MB2u1Y-1639290184026)(./imgs/image-20211212141240747.png)]](/img/ac/93018aeb89cb0bfb618c1c3f7c1389.jpg)
Deep learning , Multilayer artificial neural network
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-vidJZOeY-1639290184026)(./imgs/image-20211212141857069.png)]](/img/5c/7a88ffc5a27c94f5cf95725a2bf458.jpg)
Personal study notes , Just learn to communicate , Reprint please indicate the source !
边栏推荐
- Leetcode bit operation
- For new students, if you have no contact with single-chip microcomputer, it is recommended to get started with 51 single-chip microcomputer
- Liquid crystal display
- STM32 running lantern experiment - library function version
- The new series of MCU also continues the two advantages of STM32 product family: low voltage and energy saving
- Leetcode - 460 LFU cache (Design - hash table + bidirectional linked hash table + balanced binary tree (TreeSet))*
- LeetCode - 673. 最长递增子序列的个数
- Simple use of MySQL (addition, deletion, modification and query)
- yocto 技术分享第四期:自定义增加软件包支持
- 03 fastjason solves circular references
猜你喜欢
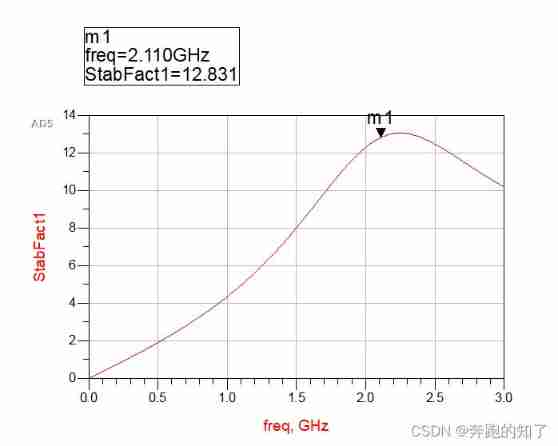
ADS simulation design of class AB RF power amplifier
03 FastJson 解决循环引用
![[untitled] proteus simulation of traffic lights based on 89C51 Single Chip Microcomputer](/img/90/4de927e797ec9c2bb70e507392bed0.jpg)
[untitled] proteus simulation of traffic lights based on 89C51 Single Chip Microcomputer
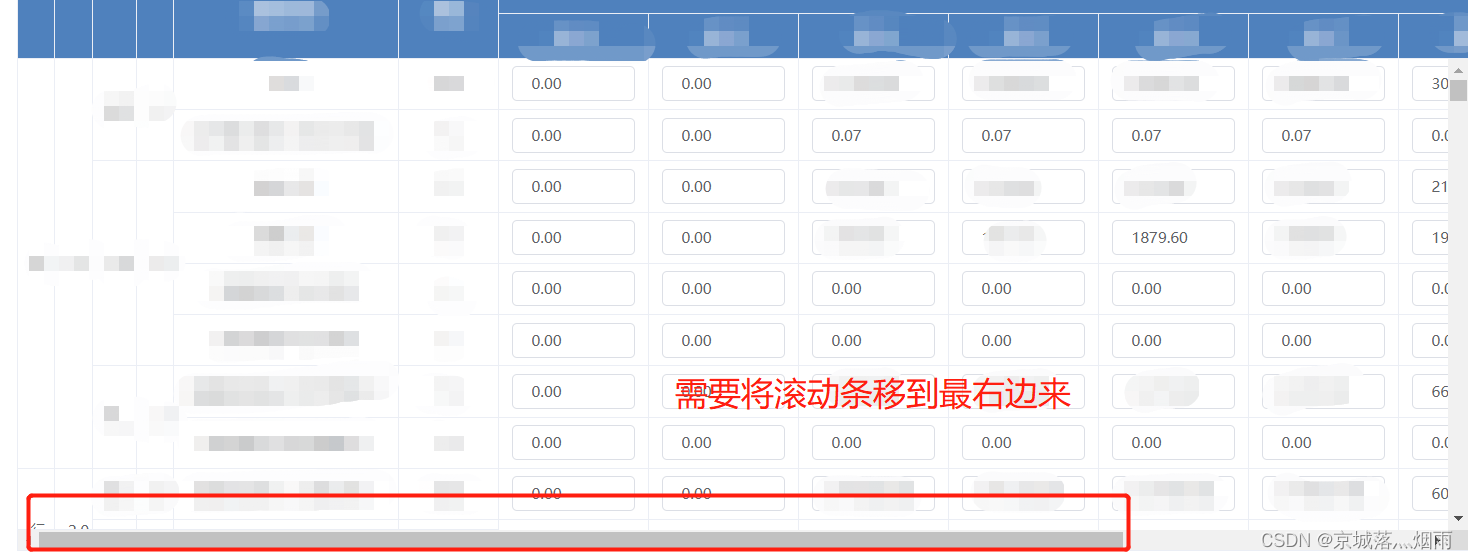
El table X-axis direction (horizontal) scroll bar slides to the right by default
Leetcode bit operation

yocto 技術分享第四期:自定義增加軟件包支持

It is difficult to quantify the extent to which a single-chip computer can find a job

Windows下MySQL的安装和删除

2021-10-27

Connect Alibaba cloud servers in the form of key pairs
随机推荐
QT is a method of batch modifying the style of a certain type of control after naming the control
A lottery like scissors, stone and cloth (C language)
Leetcode bit operation
2021-10-28
Not many people can finally bring their interests to college graduation
LeetCode - 919. Full binary tree inserter (array)
LeetCode - 673. Number of longest increasing subsequences
2312. Selling wood blocks | things about the interviewer and crazy Zhang San (leetcode, with mind map + all solutions)
Swing transformer details-1
Do you understand automatic packing and unpacking? What is the principle?
Stm32f04 clock configuration
4G module at command communication package interface designed by charging pile
For new students, if you have no contact with single-chip microcomputer, it is recommended to get started with 51 single-chip microcomputer
Opencv note 21 frequency domain filtering
Windows下MySQL的安装和删除
getopt_ Typical use of long function
Openeuler kernel technology sharing - Issue 1 - kdump basic principle, use and case introduction
Design of charging pile mqtt transplantation based on 4G EC20 module
Simulate mouse click
2021-01-03