当前位置:网站首页>MapReduce instance (VIII): Map end join
MapReduce instance (VIII): Map end join
2022-07-06 09:33:00 【Laugh at Fengyun Road】
MR Realization Map End join
Hello everyone , I am Fengyun , Welcome to my blog perhaps WeChat official account 【 Laugh at Fengyun Road 】, In the days to come, let's learn about big data related technologies , Work hard together , Meet a better self !
Use scenarios and principles
Map End join It means that the data reaches map Merge before processing functions , Efficiency is much higher than Reduce End join, because Reduce End join Is to pass all the data Shuffle, Very resource intensive .
- Map End join Usage scenarios of :
- The data in a table is very small 、 A table has a large amount of data
- principle :
- Map End join It is an optimization for the above scenarios : Load all the data in the small table into memory , Press keyword Index . The data in the large table is used as map The input of , Yes map() Function each pair <key,value> Input , You can easily connect with small data that has been loaded into memory . Press the connection result key Output , after shuffle Stage , To reduce The end is already pressed key Grouped and connected data .
Realize the idea
- First, when submitting the job, put the small table file in the DistributedCache in , And then from DistributedCache Take out the small table for join Connected <key,value> Key value pair , Split it into memory ( Can be placed HashMap In a container )
- To rewrite MyMapper Class setup() Method , Because this method precedes map Method execution , Read the smaller table into a HashMap in .
- rewrite map function , Read the contents of the large table row by row , One by one and HashMap Compare the contents of , if Key identical , Then format the data , And then directly output .
- map Function output <key,value> Key value pairs first pass shuffle hold key All with the same value value Put it into an iterator to form values, And then <key,values> Key value pairs are passed to reduce function ,reduce Function input key Copy directly to the output key, Input values Through enhanced version for Loop through output one by one , The number of cycles determines <key,value> Number of outputs .
Code writing
Mapper Code
public static class MyMapper extends Mapper<Object, Text, Text, Text>{
private Map<String, String> dict = new HashMap<>();
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
String fileName = context.getLocalCacheFiles()[0].getName();
System.out.println(fileName);
BufferedReader reader = new BufferedReader(new FileReader(fileName));
String codeandname = null;
while (null != ( codeandname = reader.readLine() ) ) {
String str[]=codeandname.split("\t");
dict.put(str[0], str[2]+"\t"+str[3]);
}
reader.close();
}
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String[] kv = value.toString().split("\t");
if (dict.containsKey(kv[1])) {
context.write(new Text(kv[1]), new Text(dict.get(kv[1])+"\t"+kv[2]));
}
}
}
This part is divided into setup Methods and map Method . stay setup In this method, we first use getName() Get the current file name orders1 And assign it to fileName, And then use bufferedReader Read the cache file in memory . Use readLine() Method to read each line of record , Use this record split(“\t”) Method interception , And order_items The same fields in the file str[0] As key Values in map aggregate dict in , Select the field to be displayed as value.map Function receive order_items File data , And use split(“\t”) The intercepted data is stored in the array kv[] in ( among kv[1] And str[0] The fields represented are the same ), use if Judge , If in memory dict A collection of key Value inclusion kv[1], Then use context Of write() Method output key2/value2 value , among kv[1] As key2, other dict.get(kv[1])+“\t”+kv[2] As value2.
Reduce Code
public static class MyReducer extends Reducer<Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
for (Text text : values) {
context.write(key, text);
}
}
}
map Function output <key,value > The key value pair first passes through a suffle hold key All with the same value value Put it into an iterator to form values, And then <key,values> Key value pairs are passed to reduce function ,reduce Function input key Copy directly to the output key, Input values Through enhanced version for Loop through output one by one .
Complete code
package mapreduce;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MapJoin {
public static class MyMapper extends Mapper<Object, Text, Text, Text>{
private Map<String, String> dict = new HashMap<>();
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
String fileName = context.getLocalCacheFiles()[0].getName();
//System.out.println(fileName);
BufferedReader reader = new BufferedReader(new FileReader(fileName));
String codeandname = null;
while (null != ( codeandname = reader.readLine() ) ) {
String str[]=codeandname.split("\t");
dict.put(str[0], str[2]+"\t"+str[3]);
}
reader.close();
}
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String[] kv = value.toString().split("\t");
if (dict.containsKey(kv[1])) {
context.write(new Text(kv[1]), new Text(dict.get(kv[1])+"\t"+kv[2]));
}
}
}
public static class MyReducer extends Reducer<Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
for (Text text : values) {
context.write(key, text);
}
}
}
public static void main(String[] args) throws ClassNotFoundException, IOException, InterruptedException, URISyntaxException {
Job job = Job.getInstance();
job.setJobName("mapjoin");
job.setJarByClass(MapJoin.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
Path in = new Path("hdfs://localhost:9000/mymapreduce5/in/order_items1");
Path out = new Path("hdfs://localhost:9000/mymapreduce5/out");
FileInputFormat.addInputPath(job, in);
FileOutputFormat.setOutputPath(job, out);
URI uri = new URI("hdfs://localhost:9000/mymapreduce5/in/orders1");
job.addCacheFile(uri);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
-------------- end ----------------
WeChat official account : Below scan QR code or Search for Laugh at Fengyun Road Focus on 
边栏推荐
- CAP理论
- Vs All comments and uncomments
- Compilation of libwebsocket
- 【深度学习】语义分割:论文阅读:(2021-12)Mask2Former
- Selenium+pytest automated test framework practice
- [shell script] use menu commands to build scripts for creating folders in the cluster
- Redis之连接redis服务命令
- 一文读懂,DDD落地数据库设计实战
- Global and Chinese market of bank smart cards 2022-2028: Research Report on technology, participants, trends, market size and share
- Use of activiti7 workflow
猜你喜欢
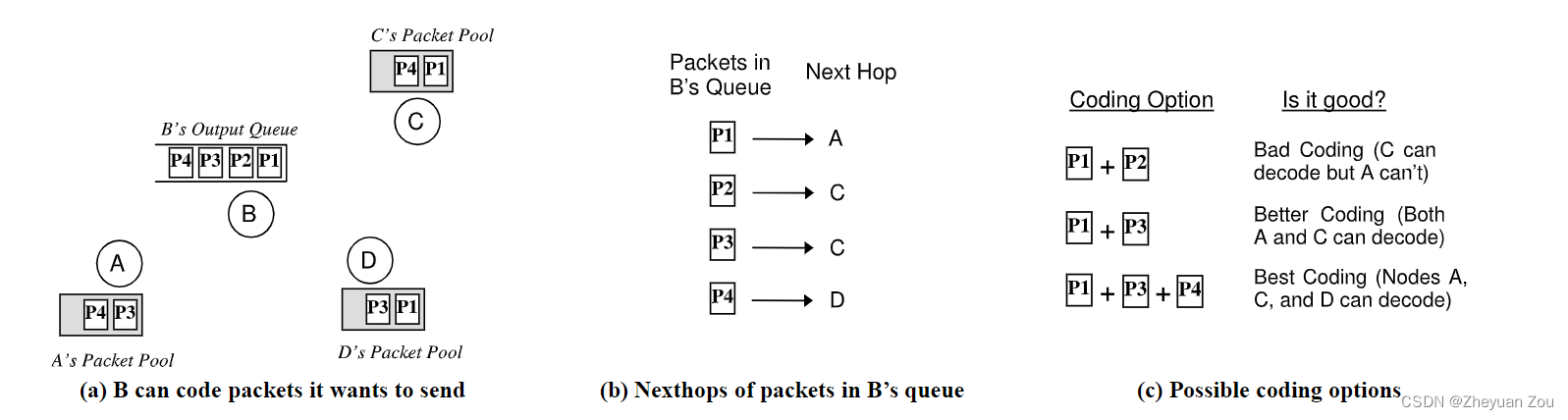
Advanced Computer Network Review(5)——COPE

An article takes you to understand the working principle of selenium in detail
Nacos installation and service registration
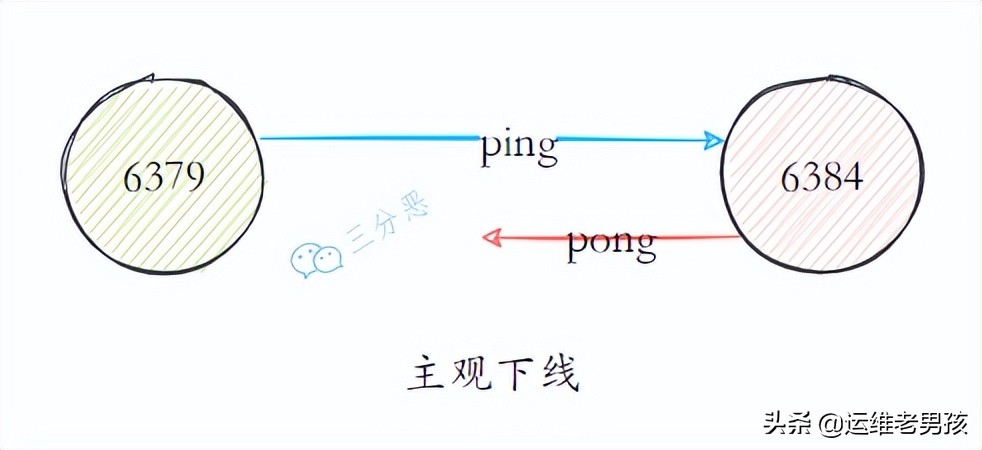
面渣逆袭:Redis连环五十二问,图文详解,这下面试稳了
Kratos ares microservice framework (II)
Design and implementation of online snack sales system based on b/s (attached: source code paper SQL file)

【深度学习】语义分割:论文阅读:(2021-12)Mask2Former
Workflow - activiti7 environment setup

Different data-driven code executes the same test scenario
![[deep learning] semantic segmentation: paper reading: (CVPR 2022) mpvit (cnn+transformer): multipath visual transformer for dense prediction](/img/f1/6f22f00843072fa4ad83dc0ef2fad8.png)
[deep learning] semantic segmentation: paper reading: (CVPR 2022) mpvit (cnn+transformer): multipath visual transformer for dense prediction
随机推荐
Mapreduce实例(七):单表join
AcWing 2456. Notepad
Processes of libuv
Global and Chinese market of linear regulators 2022-2028: Research Report on technology, participants, trends, market size and share
【深度学习】语义分割:论文阅读:(CVPR 2022) MPViT(CNN+Transformer):用于密集预测的多路径视觉Transformer
Mysql database recovery (using mysqlbinlog command)
Webrtc blog reference:
Design and implementation of film and television creation forum based on b/s (attached: source code paper SQL file project deployment tutorial)
Servlet learning diary 8 - servlet life cycle and thread safety
Reids之缓存预热、雪崩、穿透
YARN组织架构
[Yu Yue education] Wuhan University of science and technology securities investment reference
【深度学习】语义分割:论文阅读(NeurIPS 2021)MaskFormer: per-pixel classification is not all you need
Multivariate cluster analysis
【图的三大存储方式】只会用邻接矩阵就out了
[Chongqing Guangdong education] reference materials for nine lectures on the essence of Marxist Philosophy in Wuhan University
Redis之Geospatial
MapReduce instance (IV): natural sorting
Nacos installation and service registration
【shell脚本】——归档文件脚本