当前位置:网站首页>Mapreduce实例(六):倒排索引
Mapreduce实例(六):倒排索引
2022-07-06 09:01:00 【笑看风云路】
大家好,我是风云,欢迎大家关注我的博客 或者 微信公众号【笑看风云路】,在未来的日子里我们一起来学习大数据相关的技术,一起努力奋斗,遇见更好的自己!
倒排索引原理
- "倒排索引"是文档检索系统中最常用的数据结构,被广泛地应用于全文搜索引擎。
- 它主要是用来存储某个单词(或词组)在一个文档或一组文档中的存储位置的映射,即提供了一种根据"内容来查找文档"的方式。由于不是根据"文档来确定文档所包含"的内容,而是进行相反的操作,因而被称为倒排索引(Inverted Index)
- 实现"倒排索引"主要关注的信息为:单词、文档URL及词频
倒排索引主要是用来存储某个单词(或词组)在一个文档或一组文档中的存储位置的映射,即提供了一种根据"内容来查找文档"的方式。
实现思路
根据MapReduce的处理过程给出倒排索引的设计思路:
(1)Map过程
首先使用默认的TextInputFormat类对输入文件进行处理,得到文本中每行的偏移量及其内容。显然,Map过程首先必须分析输入的<key,value>对,得到倒排索引中需要的三个信息:单词、文档URL和词频,接着我们对读入的数据利用Map操作进行预处理,如下图所示:
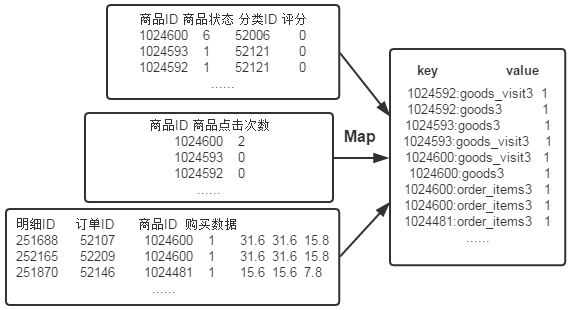
这里存在两个问题:
第一,<key,value>对只能有两个值,在不使用Hadoop自定义数据类型的情况下,需要根据情况将其中两个值合并成一个值,作为key或value值。
第二,通过一个Reduce过程无法同时完成词频统计和生成文档列表,所以必须增加一个Combine过程完成词频统计。
这里将商品ID和URL组成key值(如"1024600:goods3"),将词频(商品ID出现次数)作为value,这样做的好处是可以利用MapReduce框架自带的Map端排序,将同一文档的相同单词的词频组成列表,传递给Combine过程,实现类似于WordCount的功能。
(2)Combine过程
经过map方法处理后,Combine过程将key值相同的value值累加,得到一个单词在文档中的词频,如下图所示。如果直接将下图所示的输出作为Reduce过程的输入,在Shuffle过程时将面临一个问题:所有具有相同单词的记录(由单词、URL和词频组成)应该交由同一个Reducer处理,但当前的key值无法保证这一点,所以必须修改key值和value值。这次将单词(商品ID)作为key值,URL和词频组成value值(如"goods3:1")。这样做的好处是可以利用MapReduce框架默认的HashPartitioner类完成Shuffle过程,将相同单词的所有记录发送给同一个Reducer进行处理。
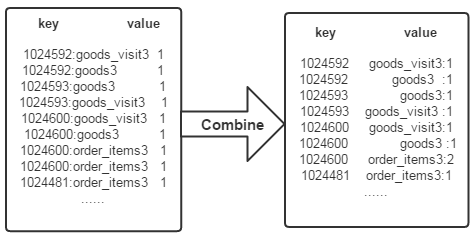
(3)Reduce过程
经过上述两个过程后,Reduce过程只需将相同key值的所有value值组合成倒排索引文件所需的格式即可,剩下的事情就可以直接交给MapReduce框架进行处理了。如下图所示
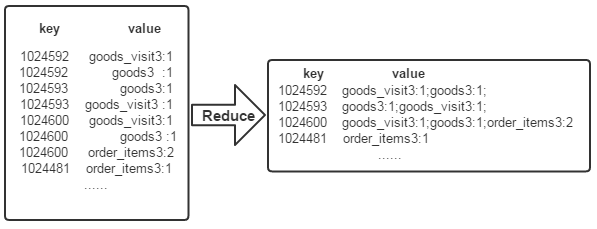
代码编写
Map代码
首先使用默认的TextInputFormat类对输入文件进行处理,得到文本中每行的偏移量及其内容。显然,Map过程首先必须分析输入的<key,value>对,得到倒排索引中需要的三个信息:单词、文档URL和词频,这里存在两个问题:第一,<key,value>对只能有两个值,在不使用Hadoop自定义数据类型的情况下,需要根据情况将其中两个值合并成一个值,作为key或value值。第二,通过一个Reduce过程无法同时完成词频统计和生成文档列表,所以必须增加一个Combine过程完成词频统计。
public static class doMapper extends Mapper<Object, Text, Text, Text>{
public static Text myKey = new Text(); // 存储单词和URL组合
public static Text myValue = new Text(); // 存储词频
//private FileSplit filePath; // 存储Split对象
@Override // 实现map函数
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String filePath=((FileSplit)context.getInputSplit()).getPath().toString();
if(filePath.contains("goods")){
String val[]=value.toString().split("\t");
int splitIndex =filePath.indexOf("goods");
myKey.set(val[0] + ":" + filePath.substring(splitIndex));
}else if(filePath.contains("order")){
String val[]=value.toString().split("\t");
int splitIndex =filePath.indexOf("order");
myKey.set(val[2] + ":" + filePath.substring(splitIndex));
}
myValue.set("1");
context.write(myKey, myValue);
}
}
Combiner代码
经过map方法处理后,Combine过程将key值相同的value值累加,得到一个单词在文档中的词频。如果直接将输出作为Reduce过程的输入,在Shuffle过程时将面临一个问题:所有具有相同单词的记录(由单词、URL和词频组成)应该交由同一个Reducer处理,但当前的key值无法保证这一点,所以必须修改key值和value值。这次将单词作为key值,URL和词频组成value值。这样做的好处是可以利用MapReduce框架默认的HashPartitioner类完成Shuffle过程,将相同单词的所有记录发送给同一个Reducer进行处理。
public static class doCombiner extends Reducer<Text, Text, Text, Text>{
public static Text myK = new Text();
public static Text myV = new Text();
@Override //实现reduce函数
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
// 统计词频
int sum = 0 ;
for (Text value : values) {
sum += Integer.parseInt(value.toString());
}
int mysplit = key.toString().indexOf(":");
// 重新设置value值由URL和词频组成
myK.set(key.toString().substring(0, mysplit));
myV.set(key.toString().substring(mysplit + 1) + ":" + sum);
context.write(myK, myV);
}
}
Reduce代码
经过上述两个过程后,Reduce过程只需将相同key值的value值组合成倒排索引文件所需的格式即可,剩下的事情就可以直接交给MapReduce框架进行处理了。
public static class doReducer extends Reducer<Text, Text, Text, Text>{
public static Text myK = new Text();
public static Text myV = new Text();
@Override // 实现reduce函数
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
// 生成文档列表
String myList = new String();
for (Text value : values) {
myList += value.toString() + ";";
}
myK.set(key);
myV.set(myList);
context.write(myK, myV);
}
}
完整代码
package mapreduce;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MyIndex {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance();
job.setJobName("InversedIndexTest");
job.setJarByClass(MyIndex.class);
job.setMapperClass(doMapper.class);
job.setCombinerClass(doCombiner.class);
job.setReducerClass(doReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
Path in1 = new Path("hdfs://localhost:9000/mymapreduce9/in/goods3");
Path in2 = new Path("hdfs://localhost:9000/mymapreduce9/in/goods_visit3");
Path in3 = new Path("hdfs://localhost:9000/mymapreduce9/in/order_items3");
Path out = new Path("hdfs://localhost:9000/mymapreduce9/out");
FileInputFormat.addInputPath(job, in1);
FileInputFormat.addInputPath(job, in2);
FileInputFormat.addInputPath(job, in3);
FileOutputFormat.setOutputPath(job, out);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
public static class doMapper extends Mapper<Object, Text, Text, Text>{
public static Text myKey = new Text();
public static Text myValue = new Text();
//private FileSplit filePath;
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String filePath=((FileSplit)context.getInputSplit()).getPath().toString();
if(filePath.contains("goods")){
String val[]=value.toString().split("\t");
int splitIndex =filePath.indexOf("goods");
myKey.set(val[0] + ":" + filePath.substring(splitIndex));
}else if(filePath.contains("order")){
String val[]=value.toString().split("\t");
int splitIndex =filePath.indexOf("order");
myKey.set(val[2] + ":" + filePath.substring(splitIndex));
}
myValue.set("1");
context.write(myKey, myValue);
}
}
public static class doCombiner extends Reducer<Text, Text, Text, Text>{
public static Text myK = new Text();
public static Text myV = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
int sum = 0 ;
for (Text value : values) {
sum += Integer.parseInt(value.toString());
}
int mysplit = key.toString().indexOf(":");
myK.set(key.toString().substring(0, mysplit));
myV.set(key.toString().substring(mysplit + 1) + ":" + sum);
context.write(myK, myV);
}
}
public static class doReducer extends Reducer<Text, Text, Text, Text>{
public static Text myK = new Text();
public static Text myV = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
String myList = new String();
for (Text value : values) {
myList += value.toString() + ";";
}
myK.set(key);
myV.set(myList);
context.write(myK, myV);
}
}
}
-------------- end ----------------
微信公众号:扫描下方二维码或 搜索 笑看风云路 关注
边栏推荐
- Global and Chinese market of bank smart cards 2022-2028: Research Report on technology, participants, trends, market size and share
- Redis之连接redis服务命令
- Simclr: comparative learning in NLP
- LeetCode41——First Missing Positive——hashing in place & swap
- Redis之主从复制
- 甘肃旅游产品预订增四倍:“绿马”走红,甘肃博物馆周边民宿一房难求
- 基于B/S的医院管理住院系统的研究与实现(附:源码 论文 sql文件)
- Solve the problem of inconsistency between database field name and entity class attribute name (resultmap result set mapping)
- 068.查找插入位置--二分查找
- BN folding and its quantification
猜你喜欢

Kratos战神微服务框架(一)
MapReduce工作机制

Ijcai2022 collection of papers (continuously updated)

Pytest之收集用例规则与运行指定用例
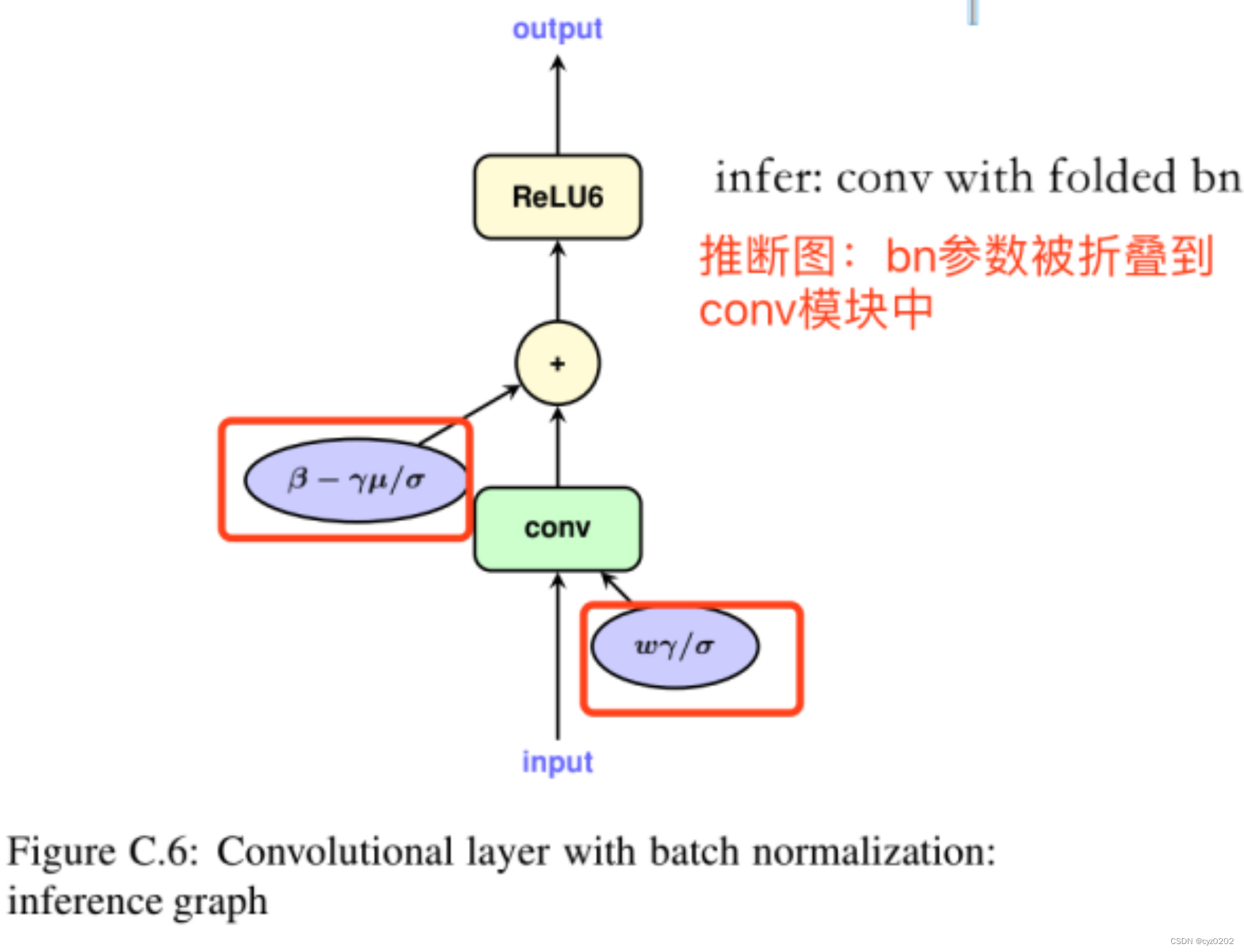
BN folding and its quantification
Nacos installation and service registration
Redis之持久化实操(Linux版)
IDS cache preheating, avalanche, penetration
LeetCode41——First Missing Positive——hashing in place & swap

Redis之Bitmap
随机推荐
Redis之哨兵模式
Selenium+Pytest自动化测试框架实战
MapReduce工作机制
Global and Chinese market of metallized flexible packaging 2022-2028: Research Report on technology, participants, trends, market size and share
一文读懂,DDD落地数据库设计实战
go-redis之初始化連接
Kratos战神微服务框架(一)
Servlet learning diary 8 - servlet life cycle and thread safety
Withdrawal of wechat applet (enterprise payment to change)
Lua script of redis
Redis' performance indicators and monitoring methods
Blue Bridge Cup_ Single chip microcomputer_ PWM output
[three storage methods of graph] just use adjacency matrix to go out
Sqlmap installation tutorial and problem explanation under Windows Environment -- "sqlmap installation | CSDN creation punch in"
Servlet learning diary 7 -- servlet forwarding and redirection
有软件负载均衡,也有硬件负载均衡,选择哪个?
LeetCode41——First Missing Positive——hashing in place & swap
Detailed explanation of cookies and sessions
英雄联盟轮播图手动轮播
Selenium+Pytest自动化测试框架实战(下)