当前位置:网站首页>Intel distiller Toolkit - Quantitative implementation 1
Intel distiller Toolkit - Quantitative implementation 1
2022-07-06 08:57:00 【cyz0202】
This series of articles
Intel Distiller tool kit - Quantitative realization 1
Intel Distiller tool kit - Quantitative realization 2
Distiller
- Distiller yes Intel 2019 A toolkit supporting neural network compression was developed around , Supported methods include prune 、 quantitative 、 Distillation 、 Low immature decomposition, etc ;
- In this paper, Distiller How to realize the quantitative scheme ; because Distiller 19 Almost no longer updated after years , Therefore, we mainly introduce the classical quantization scheme , For learning ;
Distiller Quantitative realization
- First , I will quote Distiller examples Implemented within gnmt Quantization code , Through this example distiller Quantitative framework ; The code is as follows

- You can see that the above code has 3 A step
- Collect statistics ( Also known as calibrator ,QuantCalibrationStatsCollector)
- Create quantizer ( Here is the post training quantizer PostTrainLinearQuantizer)
- Quantizer quantization model (prepare_model)
- The following focuses on the creation and application of quantizers ( Above 2/3 Step )
Quantizer
- distiller The main idea of realizing quantizer yes module Replace Law , Modules to be quantified , Such as conv、linear、embedding、 No arguments ops( Rujia 、 ride 、concat) etc. , Use a wrapper (wrapper) encapsulated ; When inferring wrapper For input 、 The weight ( No arguments module No, ) Quantify , Then it is handed over to the encapsulated real module (conv、linear、 No arguments op etc. ) Calculate , Finally, do inverse quantization as needed ;
- notes :distiller Add up (elementwise_add)、 Multiplication by element ( Dot product /elementwise_mul)、 Matrix multiplication (matMul)、 Batch matrix multiplication (BatchMatMul)、concat Use both nn.Module encapsulate , In order to distiller It works module Replace Law Carry out unified quantitative processing ;
- Now let's take a look at Quantizer Definition of base class , The code is as follows ( Made notes , But if readers haven't seen it distiller Complete source code , You may not understand , Recommend interested readers to see the source code ), It is mainly divided into the following parts
- Important variables
- quantitative bits Set up : various module Default Settings 、 External override settings (overrides); Defined Qbits class
- Quantify replacement plants : namely replacement_factory, With dict The form records the replacement to be quantified module Of wrapper; This parameter is specified by Quantizer Subclass settings , The next article will introduce ;
- Parameters to be quantified :params_to_quantize, Record all parameters to be quantified and their related conditions ( Where module、 quantitative bits etc. )
- Parameter quantization function :param_quantization_fn, A function that quantifies parameters , from Quantizer Subclass settings
- Processing flow (prepare_model)
- Preprocessing : Such as BN Fold ( Trained and inferred BN The usage is different )、 Activate optimization, etc
- Quantitative substitution : To be quantified module With corresponding wrapper Replace ;
- post-processing
- Source code is as follows
class Quantizer(object): r""" Base class for quantizers. Args: model (torch.nn.Module): The model to be quantized optimizer (torch.optim.Optimizer): An optimizer instance, required in cases where the quantizer is going to perform changes to existing model parameters and/or add new ones. Specifically, when train_with_fp_copy is True, this cannot be None. bits_activations/weights/bias (int): Default number of bits to use when quantizing each tensor type. Value of None means do not quantize. overrides (OrderedDict): Dictionary mapping regular expressions of layer name patterns to dictionary with overrides of default values. The keys in the overrides dictionary should be parameter names that the Quantizer accepts default values for in its init function. The parameters 'bits_activations', 'bits_weights', and 'bits_bias' which are accepted by the base Quantizer are supported by default. Other than those, each sub-class of Quantizer defines the set of parameter for which it supports over-riding. OrderedDict is used to enable handling of overlapping name patterns. So, for example, one could define certain override parameters for a group of layers, e.g. 'conv*', but also define different parameters for specific layers in that group, e.g. 'conv1'. The patterns are evaluated eagerly - the first match wins. Therefore, the more specific patterns must come before the broad patterns. train_with_fp_copy (bool): If true, will modify layers with weights to keep both a quantized and floating-point copy, such that the following flow occurs in each training iteration: 1. q_weights = quantize(fp_weights) 2. Forward through network using q_weights 3. In back-prop: 3.1 Gradients calculated with respect to q_weights 3.2 We also back-prop through the 'quantize' operation from step 1 4. Update fp_weights with gradients calculated in step 3.2 """ def __init__(self, model, optimizer=None, bits_activations=None, bits_weights=None, bits_bias=None, overrides=None, train_with_fp_copy=False): if overrides is None: overrides = OrderedDict() if not isinstance(overrides, OrderedDict): raise TypeError('overrides must be an instance of collections.OrderedDict or None') if train_with_fp_copy and optimizer is None: raise ValueError('optimizer cannot be None when train_with_fp_copy is True') # Get the relationship between nodes of the calculation graph , In order to optimize the activation function later self.adjacency_map = None # To be populated during prepare_model() # Default quantification bits Set up self.default_qbits = QBits(acts=bits_activations, wts=bits_weights, bias=bits_bias) self.overrides = overrides self.model = model self.optimizer = optimizer # Stash some quantizer data in the model so we can re-apply the quantizer on a resuming model self.model.quantizer_metadata = {'type': type(self), 'params': {'bits_activations': bits_activations, 'bits_weights': bits_weights, 'bits_bias': bits_bias, 'overrides': copy.deepcopy(overrides)}} for k, v in self.overrides.items(): if any(old_bits_key in v.keys() for old_bits_key in ['acts', 'wts', 'bias']): raise ValueError("Using 'acts' / 'wts' / 'bias' to specify bit-width overrides is deprecated.\n" "Please use the full parameter names: " "'bits_activations' / 'bits_weights' / 'bits_bias'") qbits = QBits(acts=v.pop('bits_activations', self.default_qbits.acts), wts=v.pop('bits_weights', self.default_qbits.wts), bias=v.pop('bits_bias', self.default_qbits.bias)) v['bits'] = qbits # Prepare explicit mapping from each layer to QBits based on default + overrides patterns = [] regex_overrides = None # Need coverage module Default quantization settings if overrides: patterns = list(overrides.keys()) regex_overrides_str = '|'.join(['(^{0}$)'.format(pattern) for pattern in patterns]) regex_overrides = re.compile(regex_overrides_str) self.module_qbits_map = {} self.module_overrides_map = {} # Set each module The quantification of bits for module_full_name, module in model.named_modules(): # Need to account for scenario where model is parallelized with DataParallel, which wraps the original # module with a wrapper module called 'module' :) name_to_match = module_full_name.replace('module.', '', 1) qbits = self.default_qbits override_entry = self.overrides.get(name_to_match, OrderedDict()) if regex_overrides: m_overrides = regex_overrides.match(name_to_match) if m_overrides: group_idx = 0 groups = m_overrides.groups() while groups[group_idx] is None: group_idx += 1 override_entry = copy.deepcopy(override_entry or self.overrides[patterns[group_idx]]) qbits = override_entry.pop('bits', self.default_qbits) self._add_qbits_entry(module_full_name, type(module), qbits) self._add_override_entry(module_full_name, override_entry) # Mapping from module type to function generating a replacement module suited for quantization # To be populated by child classes # Unspecified layer types return None by default. self.replacement_factory = defaultdict(lambda: None) # Pointer to parameters quantization function, triggered during training process # To be populated by child classes self.param_quantization_fn = None # Parameter quantization function self.train_with_fp_copy = train_with_fp_copy self.params_to_quantize = [] # A dictionary of replaced modules and their respective names. self.modules_processed = OrderedDict() # Processed module def _add_qbits_entry(self, module_name, module_type, qbits): if module_type not in [nn.Conv2d, nn.Conv3d, nn.Linear, nn.Embedding]: # For now we support weights quantization only for Conv, FC and Embedding layers (so, for example, we don't # support quantization of batch norm scale parameters) qbits = QBits(acts=qbits.acts, wts=None, bias=None) self.module_qbits_map[module_name] = qbits def _add_override_entry(self, module_name, entry): self.module_overrides_map[module_name] = entry # def prepare_model(self, dummy_input=None): """ Traverses the model and replaces sub-modules with quantized counterparts according to the bit-width and overrides configuration provided to __init__(), and according to the replacement_factory as defined by the Quantizer sub-class being used. Note: If multiple sub-modules within the model actually reference the same module, then that module is replaced only once, according to the configuration (bit-width and/or overrides) of the first encountered reference. Toy Example - say a module is constructed using this bit of code: shared_relu = nn.ReLU self.relu1 = shared_relu self.relu2 = shared_relu When traversing the model, a replacement will be generated when 'self.relu1' is encountered. Let's call it `new_relu1'. When 'self.relu2' will be encountered, it'll simply be replaced with a reference to 'new_relu1'. Any override configuration made specifically for 'self.relu2' will be ignored. A warning message will be shown. """ msglogger.info('Preparing model for quantization using {0}'.format(self.__class__.__name__)) self.model.quantizer_metadata["dummy_input"] = dummy_input if dummy_input is not None: summary_graph = distiller.SummaryGraph(self.model, dummy_input) # obtain adjacency_map self.adjacency_map = summary_graph.adjacency_map(dedicated_modules_only=False) self._pre_prepare_model(dummy_input) # Preprocessing :BN Fold 、 With active module Optimization, etc. self._pre_process_container(self.model) # Start quantifying module Substitution and other main work for module_name, module in self.model.named_modules(): qbits = self.module_qbits_map[module_name] curr_parameters = dict(module.named_parameters()) for param_name, param in curr_parameters.items(): n_bits = qbits.bias if param_name.endswith('bias') else qbits.wts if n_bits is None: continue fp_attr_name = param_name if self.train_with_fp_copy: hack_float_backup_parameter(module, param_name, n_bits) # Backup float Parameters fp_attr_name = FP_BKP_PREFIX + param_name # Record the relevant information of the parameters to be quantified : Where module, Is there a fp copy, Quantization settings self.params_to_quantize.append(_ParamToQuant(module, module_name, fp_attr_name, param_name, n_bits)) param_full_name = '.'.join([module_name, param_name]) msglogger.info( "Parameter '{0}' will be quantized to {1} bits".format(param_full_name, n_bits)) # If an optimizer was passed, assume we need to update it # The optimizer may need to be updated ( If new parameters are added ) if self.optimizer: optimizer_type = type(self.optimizer) new_optimizer = optimizer_type(self._get_updated_optimizer_params_groups(), **self.optimizer.defaults) self.optimizer.__setstate__({'param_groups': new_optimizer.param_groups}) self._post_prepare_model() # post-processing msglogger.info('Quantized model:\n\n{0}\n'.format(self.model)) def _pre_prepare_model(self, dummy_input): pass def _pre_process_container(self, container, prefix=''): def replace_msg(module_name, modules=None): msglogger.debug('Module ' + module_name) if modules: msglogger.debug('\tReplacing: {}.{}'.format(modules[0].__module__, modules[0].__class__.__name__)) msglogger.debug('\tWith: {}.{}'.format(modules[1].__module__, modules[1].__class__.__name__)) else: msglogger.debug('\tSkipping') # Iterate through model, insert quantization functions as appropriate # Traverse model Internal module, perform Quantization module replace for name, module in container.named_children(): full_name = prefix + name if module in self.modules_processed: previous_name, previous_wrapper = self.modules_processed[module] warnings.warn("Module '{0}' references to same module as '{1}'." ' Replacing with reference the same wrapper.'.format(full_name, previous_name), UserWarning) if previous_wrapper: replace_msg(full_name, (module, previous_wrapper)) setattr(container, name, previous_wrapper) else: replace_msg(full_name) continue current_qbits = self.module_qbits_map[full_name] if current_qbits.acts is None and current_qbits.wts is None: if self.module_overrides_map[full_name]: raise ValueError("Adding overrides while not quantizing is not allowed.") # We indicate this module wasn't replaced by a wrapper No substitution replace_msg(full_name) self.modules_processed[module] = full_name, None else: # We use a type hint comment to let IDEs know replace_fn is a function # Get to be quantified module Of wrapper( namely replace_fn, Here's how ) replace_fn = self.replacement_factory[type(module)] # type: Optional[Callable] # If the replacement function wasn't specified - continue without replacing this module. if replace_fn is not None: valid_kwargs, invalid_kwargs = distiller.filter_kwargs(self.module_overrides_map[full_name], replace_fn) if invalid_kwargs: raise TypeError("""Quantizer of type %s doesn't accept \"%s\" as override arguments for %s. Allowed kwargs: %s""" % (type(self), list(invalid_kwargs), type(module), list(valid_kwargs))) # Replace what you want to quantify module To encapsulate module new_module = replace_fn(module, full_name, self.module_qbits_map, **valid_kwargs) replace_msg(full_name, (module, new_module)) # Add to history of prepared submodules self.modules_processed[module] = full_name, new_module setattr(container, name, new_module) # If a "leaf" module was replaced by a container, add the new layers to the QBits mapping if not distiller.has_children(module) and distiller.has_children(new_module): for sub_module_name, sub_module in new_module.named_modules(): self._add_qbits_entry(full_name + '.' + sub_module_name, type(sub_module), current_qbits) self.module_qbits_map[full_name] = QBits(acts=current_qbits.acts, wts=None, bias=None) if distiller.has_children(module): # For container we call recursively self._pre_process_container(module, full_name + '.') def _get_updated_optimizer_params_groups(self): """ Returns a list of model parameter groups and optimizer hyper-parameter overrides, as expected by the __init__ function of torch.optim.Optimizer. This is called after all model changes were made in prepare_model, in case an Optimizer instance was passed to __init__. Subclasses which add parameters to the model should override as needed. :return: List of parameter groups """ # Default implementation - just return all model parameters as one group return [{'params': self.model.parameters()}] def _post_prepare_model(self): pass def quantize_params(self): """ Quantize all parameters using self.param_quantization_fn (with the defined number of bits for each parameter) """ for ptq in self.params_to_quantize: q_param = self.param_quantization_fn(getattr(ptq.module, ptq.fp_attr_name), ptq) if self.train_with_fp_copy: setattr(ptq.module, ptq.q_attr_name, q_param) else: getattr(ptq.module, ptq.q_attr_name).data = q_param.data
- Important variables
Summary
This paper introduces distiller And the partial realization of its quantization function , Mainly a brief introduction Quantizer The implementation of this base class ; Subsequent quantizer implementations inherit from this base class ;
Because the code is long , Consider space , The implementation of the quantizer will be described in the following articles (Intel Distiller tool kit - Quantitative realization 2) Introduce ;
边栏推荐
- Leetcode: Jianzhi offer 03 Duplicate numbers in array
- LeetCode:26. 删除有序数组中的重复项
- Target detection - pytorch uses mobilenet series (V1, V2, V3) to build yolov4 target detection platform
- MongoDB 的安装和基本操作
- After PCD is converted to ply, it cannot be opened in meshlab, prompting error details: ignored EOF
- LeetCode:124. Maximum path sum in binary tree
- 随手记01
- [embedded] cortex m4f DSP Library
- Promise 在uniapp的简单使用
- LeetCode:221. Largest Square
猜你喜欢
Mongodb installation and basic operation

Charging interface docking tutorial of enterprise and micro service provider platform
LeetCode:236. The nearest common ancestor of binary tree
Excellent software testers have these abilities
LeetCode:498. 对角线遍历
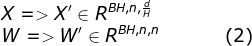
CUDA implementation of self defined convolution attention operator

Advance Computer Network Review(1)——FatTree
![[OC]-<UI入门>--常用控件-UIButton](/img/4d/f5a62671068b26ef43f1101981c7bb.png)
[OC]-<UI入门>--常用控件-UIButton
可变长参数

SimCLR:NLP中的对比学习
随机推荐
[OC]-<UI入门>--常用控件-提示对话框 And 等待提示器(圈)
力扣每日一题(二)
Esp8266-rtos IOT development
LeetCode:剑指 Offer 42. 连续子数组的最大和
多元聚类分析
The harm of game unpacking and the importance of resource encryption
Variable length parameter
广州推进儿童友好城市建设,将探索学校周边200米设安全区域
opencv+dlib实现给蒙娜丽莎“配”眼镜
Mongodb installation and basic operation
[today in history] February 13: the father of transistors was born The 20th anniversary of net; Agile software development manifesto was born
Detailed explanation of heap sorting
LeetCode:26. 删除有序数组中的重复项
[OC-Foundation框架]--<Copy对象复制>
KDD 2022论文合集(持续更新中)
Advanced Computer Network Review(4)——Congestion Control of MPTCP
Leetcode: Sword finger offer 48 The longest substring without repeated characters
Simclr: comparative learning in NLP
Excellent software testers have these abilities
Navicat premium create MySQL create stored procedure