当前位置:网站首页>CUDA实现focal_loss
CUDA实现focal_loss
2022-07-06 08:51:00 【cyz0202】
参考自:mmdetection源码阅读:cuda拓展之focal loss - 知乎
读者需要大致了解CUDA编程及损失函数原理;本文不做详细介绍
CUDA实现加速的写法(套路)
图片来自上述参考文献(侵删),红色文字是我加的注释;
这样说可能还是模模糊糊,下面会详细讲解;
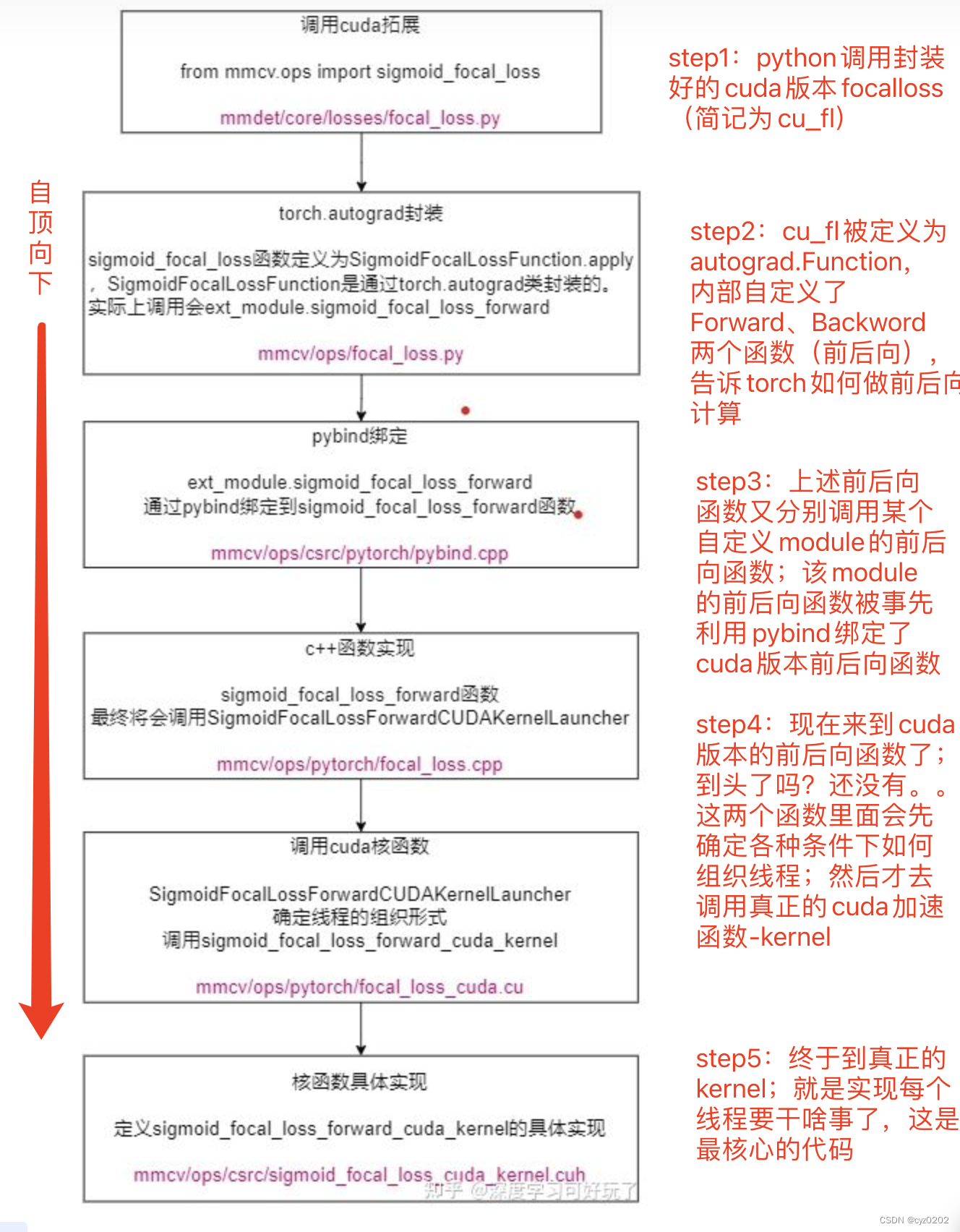
实例讲解:focal_loss cuda实现
注:本节代码内容来自开头参考文章
step1:python端调用(源代码在mmdetection工具包)
- 注意到调用了 _sigmoid_focal_loss(即sigmoid_focal_loss),该函数本质上就是对 cuda版本的focal_loss实现的封装,下面介绍;
from mmcv.ops import sigmoid_focal_loss as _sigmoid_focal_loss
# sigmoid_focal_loss其实就是SigmoidFocalLossFunction的forward方法
class FocalLoss(nn.module):
def forward(self,
pred, # tensor(num_total_anchors, num_classes)
target, # tensor(num_total_anchors, )
):
if if torch.cuda.is_available() and pred.is_cuda:
loss = _sigmoid_focal_loss(pred.contiguous(), target.contiguous(), gamma,alpha, None, 'none')
# 注意要经过contiguous确保内存连续存储!这样在cuda核函数访问连续内存就不会出错
return lossstep2:autograd.Function的使用,用来指定前后向计算方法(为什么:我们用cuda定义了一个算子,封装之后需要用autograd让torch知道怎么来做前后向计算)
- 可以看到继承了Function;使用了ext_module(来自下一步的python-cuda绑定);使用了Function.apply()
class SigmoidFocalLossFunction(Function):
@staticmethod
def forward(ctx,
input,
target,
gamma=2.0,
alpha=0.25,
weight=None,
reduction='mean'):
# 存储reduction_dict、gamma等到ctx,以便反传backward调用
ctx.reduction_dict = {'none': 0, 'mean': 1, 'sum': 2}
assert reduction in ctx.reduction_dict.keys()
ctx.gamma = float(gamma)
ctx.alpha = float(alpha)
ctx.reduction = ctx.reduction_dict[reduction]
output = input.new_zeros(input.size()) # 开辟output的空间
# 调用真正的cuda拓展:这里ext_module即被用来绑定cuda版本的代码的
ext_module.sigmoid_focal_loss_forward(input, target, weight, output, gamma=ctx.gamma, alpha=ctx.alpha)
if ctx.reduction == ctx.reduction_dict['mean']:
output = output.sum() / input.size(0)
elif ctx.reduction == ctx.reduction_dict['sum']:
output = output.sum()
ctx.save_for_backward(input, target, weight) # 保存变量供反向计算使用
return output
@staticmethod
@once_differentiable
def backward(ctx, grad_output):
input, target, weight = ctx.saved_tensors
grad_input = input.new_zeros(input.size())
# 调用真正的cuda拓展
ext_module.sigmoid_focal_loss_backward(input, target,weight, grad_input, gamma=ctx.gamma, alpha=ctx.alpha)
grad_input *= grad_output
if ctx.reduction == ctx.reduction_dict['mean']:
grad_input /= input.size(0)
return grad_input, None, None, None, None, None
# 定义sigmoid_focal_loss为SigmoidFocalLossFunction.apply,apply方法会调用forward
sigmoid_focal_loss = SigmoidFocalLossFunction.applystep3:使用pybind绑定python-cuda(c++),以实现调用python的module来调用cuda的函数;
- 这个过程在c++文件内定义;
- TORCH_EXTENSION_NAME会对应到你指定的一个名字,对于上面代码就是 ext_module(也可以叫张三李四,这个一般在setup.py内指定);
- m表示module,def的第一个参数是名字(name),第二个参数是要绑定的c++/cuda函数,这里就是 ext_module.sigmoid_focal_loss_forward. 绑定到 当前c++文件定义的 sigmoid_focal_loss_forward函数;这个函数就是真正涉及到CUDA加速的函数;下面介绍;
- def 的其他参数就是相关函数的参数了,不影响此处理解,不做赘述
sigmoid_focal_loss_forward函数将会调用SigmoidFocalLossForwardCUDAKernelLauncher函数;见下文
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("sigmoid_focal_loss_forward", &sigmoid_focal_loss_forward,
"sigmoid_focal_loss_forward ", py::arg("input"), py::arg("target"),
py::arg("weight"), py::arg("output"), py::arg("gamma"),
py::arg("alpha"));
}
# 同理sigmoid_focal_loss_backward略step4:SigmoidFocalLossForwardCUDAKernelLauncher,根据各种情况设置CUDA线程的组织形式以及其他一些基本设置(可以理解为准备好环境),然后调用真正的CUDA kernel进行核心部分计算(这里就是focal_loss的计算了,真正干活的)
- Launcher这个名字比较形象,但是读者在其他地方 不一定会见到Launcher这个写法,因为这个不是规定;但是肯定会有相关函数实现这部分功能;
- 以下是c++代码:
- 获取了相关参数并做一些基本判断;还有设置线程组织形式,就是<<<a, b>>>内的a,b
- 准备好环境后,就可以调用kernel了;
- AT_DISPATCH_FLOATING_TYPES_AND_HALF是个带参数的宏,干的事就是把第一个参数(数据类型)传给后面的scalar_t,然后执行[&]()括号里的匿名函数(就是kernel了)
- 此外还注意到Tensor提供了
.data_ptr<scalar_t>()模板成员函数,将返回tensor的连续存储的首地址,并且转换为scalar_t *的指针类型。我们知道tensor在内存中真正存放的是一维连续数组!tensor(B,C,H,W)在内存中真正存放的是长为B*C*H*W的连续数组;data_ptr()返回的就是这个连续数组的首地址;void SigmoidFocalLossForwardCUDAKernelLauncher(Tensor input, Tensor target, Tensor weight, Tensor output, const float gamma, const float alpha) { // input为tensor(num_total_anchors, num_classes) // output为tensor(num_total_anchors, num_classes) // target为tensor(num_total_anchors, ),0 ~ num_class-1表示正样本对应的类别,num_class值表示负样本和忽略样本 int output_size = output.numel(); //等于num_total_anchors*num_classes int num_classes = input.size(1); AT_ASSERTM(target.max().item<long>() <= (long)num_classes, "target label should smaller or equal than num classes"); at::cuda::CUDAGuard device_guard(input.device()); cudaStream_t stream = at::cuda::getCurrentCUDAStream(); AT_DISPATCH_FLOATING_TYPES_AND_HALF( input.scalar_type(), "sigmoid_focal_loss_forward_cuda_kernel", [&] { sigmoid_focal_loss_forward_cuda_kernel<scalar_t> //sigmoid_focal_loss_forward_cuda_kernel是cuda核函数,被定义成模板函数,通过<scalar_t>确定数据类型 <<<GET_BLOCKS(output_size), THREADS_PER_BLOCK, 0, stream>>>( output_size, input.data_ptr<scalar_t>(), target.data_ptr<int64_t>(), weight.data_ptr<scalar_t>(), output.data_ptr<scalar_t>(), gamma, alpha, num_classes); }); AT_CUDA_CHECK(cudaGetLastError()); } //backward略 // 以下是CUDA计算需要设定的线程组织形式,不熟悉的请查阅CUDA编程 #define THREADS_PER_BLOCK 1024、128、512 inline int GET_BLOCKS(const int N) { int optimal_block_num = (N + THREADS_PER_BLOCK - 1) / THREADS_PER_BLOCK; int max_block_num = 65000; return min(optimal_block_num, max_block_num); } // 获得开辟的线程块的x维,使得blockDim.x * gridDim.x要等于N
step5:kernel实现
- 这就是真正干活的了;这时候就得理解focal_loss的计算方式,才知道怎么写了;(其实上面在定义<<<a,b>>>里面的a、b参数时,就应该考虑好这部分的写法)
- 先推导一下focal_loss吧,过程如下

- 接下来就是实现了,kernel的内容代表了每个线程要干啥事;我们这里要计算loss,而且是分类的loss;具体来说,输入包括
- pred,是一个tensor,shape为[num_total_anchors, num_classes];
- 以及target,也是一个tensor,shape为[num_total_anchors];
- 可能还有weight,表示每个类别的损失权重(有些类别不重要,就给小权重,这样即便预测损失大,最后因为权重小对平均损失影响不大)
- 通常实现这种多分类loss,就是softmax;mmdetection使用的是sigmoid+focal_loss;就是利用sigmoid对num_classes里面所有类别计算损失,结合focal_loss(就是正负类加不一样的权重),最后做综合(比如取平均得到平均损失);
- 有了上述思路,我们就知道如何设计CUDA的多线程计算(就是设计kernel了);
- 既然要对每个anchor的num_classes的每个类别计算损失(此时总共要计算N=num_total_anchors*num_classes这个多个损失),那么就让它们都并行计算好了;
- 所以我们需要 num_total_anchors*num_classes 这么多线程;这就是上面 <<<a,b>>>里a的GET_BLOCK参数设置为output_size= num_total_anchors*num_classes的原因;当然可能CUDA并没有这么多可同时用的线程,没关系,再设置个CUDA范围内的总线程数呗,剩下的工作量让这些线程循环执行;这就是上面GET_BLOCK干的事,请看下文
- CUDA要求设置线程块大小(一般叫THREADS_PER_BLOCK)以及线程块数量(一般叫BLOCKS or BLOCK_NUM or BLOCKS_PER_GRID);通常两者乘积尽量稍大于总任务数(比如上面需要计算的损失个数N);但是CUDA没那么多线程,所以也得控制一下两个常量的大小,比如上面GET_BLOCK里最后设置max控制线程块数量了;
- 现在有THREADS_PER_BLOCK*BLOCKS_PER_GRID这么多线程了,可以理解为它们会在CUDA内部并行执行,每个线程计算一个损失,剩下的损失由前面的线程循环执行;
- 根据上面几步的介绍以及上面focal_loss前后向计算的推导,我们可以写出如下kernel,几个注意点:
- CUDA_1D_KERNEL_LOOP(i, n)是个带参数宏,用来定义循环,就是上面说的线程不够循环凑
- i是CUDA自动计算的当前线程的总index,n则是上面计算的总任务数(所有需要计算的损失的数量,即output_size)
- 所以index用来定位当前线程应该计算哪个损失;注意前面提到了,多维的tensor在内存中实际上是一维形式存在的,所以kernel的参数是指针形式的;此时用input[index]就找到了相应的位置了;然后可以计算当前是第几个anchor(文中n)和该anchor的第几类的损失了;
- 接下来的计算就是根据上面的focal_loss的前后向推导公式了;整体算是比较简单的
- 注意后向计算(backward函数),并行线程数可以与前向计算forward不一样,但是计算方式得与forward协调一致(比如对每个位置计算loss的话就要对每个位置计算grad)
- 代码如下
#define CUDA_1D_KERNEL_LOOP(i, n) \ for (int i = blockIdx.x * blockDim.x + threadIdx.x; i < n; \ i += blockDim.x * gridDim.x) // blockDim.x * gridDim.x就是当前开辟的线程总数 template <typename T> __global__ void sigmoid_focal_loss_forward_cuda_kernel( const int nthreads, const T* input, const int64_t* target, const T* weight, T* output, const T gamma, const T alpha, const int num_classes) { // nthreads就是outputsize,等于num_total_anchors*num_classes // const T*就是tensor的连续内存首地址 // input的连续内存长度为num_total_anchors*num_classes,target的连续内存长度为num_total_anchors。 CUDA_1D_KERNEL_LOOP(index, nthreads) { // index等于blockIdx.x * blockDim.x + threadIdx.x,即线程索引 // 因为index就是对应tensor(num_total_anchors,num_classes)的一个元素 int n = index / num_classes; // 所以n就是该元素对应的anchor int c = index % num_classes; // 所以c就是该元素对应的class int64_t t = target[n]; // 获得anchor n 的target label T flag_p = (t == c); // 表示正样本 T flag_n = (t != c); // 表示负样本 // p = sigmoid(x) = 1. / 1. + expf(-x) T p = (T)1. / ((T)1. + expf(-input[index])); // (1 - p)**gamma * log(p) 正样本的focal loss权重 T term_p = pow(((T)1. - p), gamma) * log(max(p, (T)FLT_MIN)); // p**gamma * log(1 - p) 负样本的focal loss权重 T term_n = pow(p, gamma) * log(max((T)1. - p, (T)FLT_MIN)); output[index] = (T)0.; //计算结果放到output tensor中 output[index] += -flag_p * alpha * term_p; output[index] += -flag_n * ((T)1. - alpha) * term_n; if (weight != NULL) { output[index] *= weight[t]; } } } //同理,反向传播 template <typename T> __global__ void sigmoid_focal_loss_backward_cuda_kernel( const int nthreads, const T* input, const int64_t* target, const T* weight, T* grad_input, const T gamma, const T alpha, const int num_classes) { CUDA_1D_KERNEL_LOOP(index, nthreads) { int n = index / num_classes; int c = index % num_classes; int64_t t = target[n]; T flag_p = (t == c); T flag_n = (t != c); // p = sigmoid(x) = 1. / 1. + expf(-x) T p = (T)1. / ((T)1. + exp(-input[index])); // (1 - p)**gamma * (1 - p - gamma*p*log(p)) T term_p = pow(((T)1. - p), gamma) * ((T)1. - p - (gamma * p * log(max(p, (T)FLT_MIN)))); // p**gamma * (gamma * (1 - p) * log(1 - p) - p) T term_n = pow(p, gamma) * (gamma * ((T)1. - p) * log(max((T)1. - p, (T)FLT_MIN)) - p); grad_input[index] = (T)0.; grad_input[index] += -flag_p * alpha * term_p; grad_input[index] += -flag_n * ((T)1. - alpha) * term_n; if (weight != NULL) { grad_input[index] *= weight[t]; } } }
- CUDA_1D_KERNEL_LOOP(i, n)是个带参数宏,用来定义循环,就是上面说的线程不够循环凑
总结
- 以上介绍了mmdetection中的focal_loss算子的CUDA实现;
- 算子实现有比较固定的流程,由顶向下分别是:
- Python调用autograd Function
- 上述autograd定义前后向算法
- 上述前后向算法引用Python用来绑定c++函数的module
- 上述module有前后向函数映射到c++的前后向函数
- c++的前后向函数准备环境(最重要的是线程组织形式)并调用CUDA kernel
- kernel定义CUDA如何实现具体算子(如上面的focal_loss)
- 难点在于如何实现最后kernel;具体的任务要先能分解成 多个线程能并行同时做的,才好实现kernel;
- TODO:其他更复杂算子的CUDA实现
边栏推荐
- [OC]-<UI入门>--常用控件-UIButton
- To effectively improve the quality of software products, find a third-party software evaluation organization
- 随手记01
- @Jsonbackreference and @jsonmanagedreference (solve infinite recursion caused by bidirectional references in objects)
- Double pointeur en langage C - - modèle classique
- LeetCode:673. Number of longest increasing subsequences
- [MySQL] limit implements paging
- ROS compilation calls the third-party dynamic library (xxx.so)
- Revit 二次开发 HOF 方式调用transaction
- C language double pointer -- classic question type
猜你喜欢
![[OC]-<UI入门>--常用控件-UIButton](/img/4d/f5a62671068b26ef43f1101981c7bb.png)

随机推荐
The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
After reading the programmer's story, I can't help covering my chest...
Notes 01
The network model established by torch is displayed by torch viz
项目连接数据库遇到的问题及解决
[today in history] February 13: the father of transistors was born The 20th anniversary of net; Agile software development manifesto was born
[MySQL] multi table query
使用latex导出IEEE文献格式
Indentation of tabs and spaces when writing programs for sublime text
UML圖記憶技巧
C language double pointer -- classic question type
SAP ui5 date type sap ui. model. type. Analysis of the parsing format of date
Unsupported operation exception
Super efficient! The secret of swagger Yapi
Fairguard game reinforcement: under the upsurge of game going to sea, game security is facing new challenges
LeetCode:394. 字符串解码
TP-LINK enterprise router PPTP configuration
可变长参数
Compétences en mémoire des graphiques UML
Leetcode: Sword finger offer 42 Maximum sum of continuous subarrays