当前位置:网站首页>BMINF的后训练量化实现
BMINF的后训练量化实现
2022-07-06 08:51:00 【cyz0202】
BMINF
- BMINF是清华大学开发的大模型推理工具,目前主要针对该团队的CPM系列模型做推断优化。该工具实现了内存/显存调度优化,利用cupy/cuda实现了后训练量化 等功能,本文记录分析该工具的后训练量化实现。
- 主要关注cupy操作cuda实现量化的部分,涉及量化的原理可能不会做详细介绍,需要读者查阅其他资料;
- BMINF团队近期对代码进行较多重构;我下面用的代码示例是8个月前的,读者想查看BMINF对应源代码,请查看0.5版本
实现代码分析1
量化部分的入口代码主要是在 tools/migrate_xxx.py,这里以 tools/migrate_cpm2.py为例;
main函数
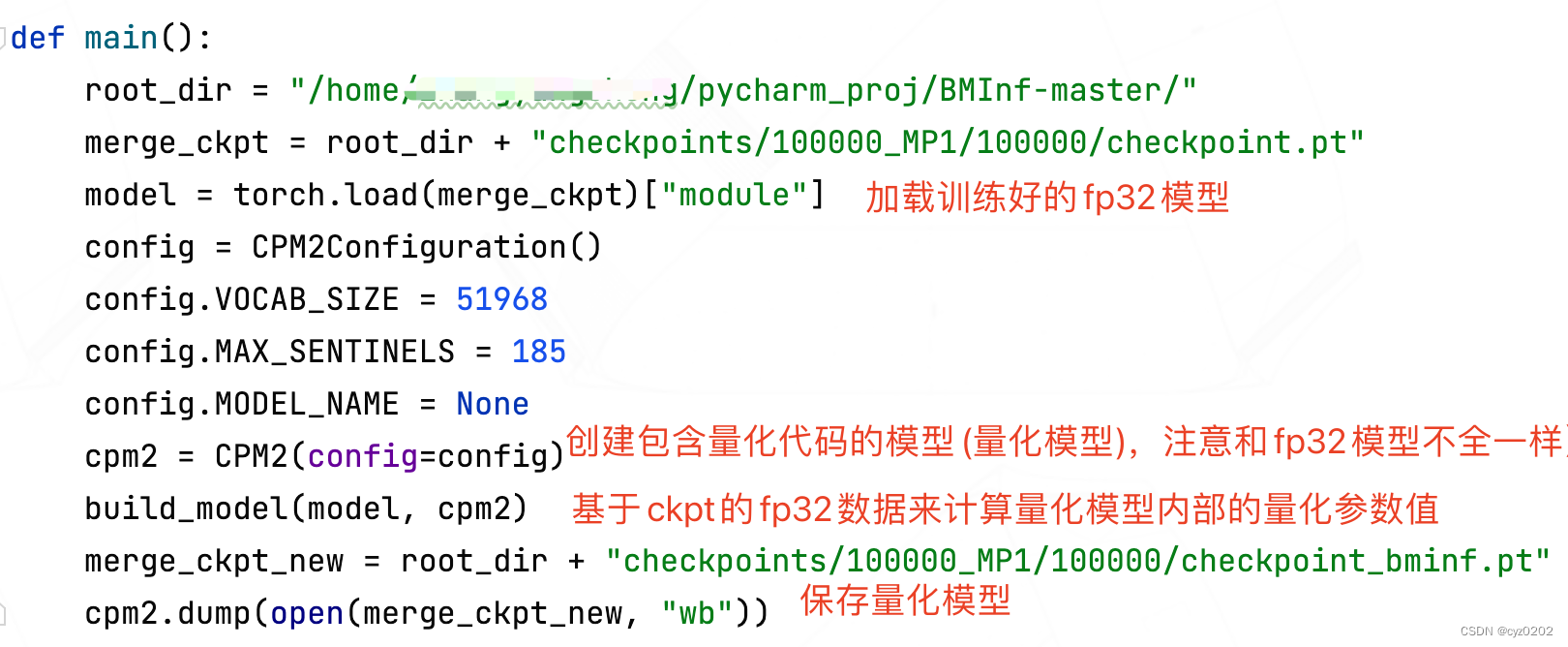
build_model函数:基于ckpt的fp32数据计算量化模型内部的量化参数值

scale_build_parameter函数:计算对称量化的scale,并将scale和量化结果放到量化模型对应参数内(上面对应的是model.encoder_kv.w_project_kv_scale和w_project_kv)

看一下保存量化结果的model.encoder_kv.w_project_kv_scale和w_project_kv是怎么定义的

build_encoder/decoder函数:主要调用build_block,处理每个block(layer)

build_block函数:还是复制部分module的参数和量化另一部分module的参数

小结:以上是从fp32模型将不同参数copy到量化模型对应位置的实现;下面介绍量化模型如何使用量化参数+cupy+cuda进行计算,实现加速;
实现代码分析2
- 以decoder使用的注意力module: partial_attetion为例进行分析(bminf/layers/attention)
- 直接上代码了,请看注释
class PartialAttention(Layer):
def __init__(self, dim_in, dim_qkv, num_heads, is_self_attn):
self.is_self_attn = is_self_attn # self_attn还是cross_attn
self.dim_in = dim_in
self.num_heads = num_heads
self.dim_qkv = dim_qkv
if self.is_self_attn:
self.w_project_qkv = Parameter((3, dim_qkv * num_heads, dim_in), cupy.int8) # 权重使用int8量化,这里会接收fp32的ckpt对应参数量化后的结果
self.w_project_qkv_scale = Parameter((3, dim_qkv * num_heads, 1), cupy.float16) # scale使用fp16;值得注意的是scale是对dim_in这个维度的
else:
self.w_project_q = Parameter((dim_qkv * num_heads, dim_in), cupy.int8) # cross_attn shape有点不一样
self.w_project_q_scale = Parameter((dim_qkv * num_heads, 1), cupy.float16)
# 输出前再做一次linear
self.w_out = Parameter((dim_in, dim_qkv * num_heads), cupy.int8)
self.w_out_scale = Parameter((dim_in, 1), cupy.float16)
def quantize(self, allocator: Allocator, value: cupy.ndarray, axis=-1):
""" 量化函数,allocator分配显存,value是待量化fp16/32值;axis是量化维度 注意到嵌套了一个quantize函数,这是真正干活的 ======================================================== 以下是quantize函数的实现: def quantize(x: cupy.ndarray, out: cupy.ndarray, scale: cupy.ndarray, axis=-1): assert x.dtype == cupy.float16 or x.dtype == cupy.float32 assert x.shape == out.shape if axis < 0: axis += len(x.shape) assert scale.dtype == cupy.float16 assert scale.shape == x.shape[:axis] + (1,) + x.shape[axis + 1:] # scale on gpu 计算scale(对称模式) quantize_scale_kernel(x, axis=axis, keepdims=True, out=scale) quantize_copy_half(x, scale, out=out) # 计算 量化结果 ======================================================== 以下是quantize_scale_kernel和quantize_copy_half/float的实现: # 返回的quantize_scale_kernel是个cuda上的函数,计算量化scale quantize_scale_kernel = create_reduction_func( # kernel指cuda上的函数,这里就是cupy让cuda创建相应函数(kernel) 'bms_quantize_scale', # 创建的函数的名称 ('e->e', 'f->e', 'e->f', 'f->f'), # 指定输入->输出数据类型(来自numpy,如e代表float16,f是float32) ('min_max_st<type_in0_raw>(in0)', 'my_max(a, b)', 'out0 = abs(a.value) / 127', 'min_max_st<type_in0_raw>'), # cuda将会执行的内容 None, _min_max_preamble # 如果需要用到自定义数据结构等,要在这里写明,如上一行min_max_st、my_max等是bminf作者自定义的,这里没展示出来 ) # 返回quantize_copy_half同样是个cuda函数,该函数在cuda上计算量化值=x/scale;注意对称量化没有zero_point quantize_copy_half = create_ufunc( 'bms_quantize_copy_half', ('ee->b', 'fe->b', 'ff->b'), 'out0 = nearbyintf(half(in0 / in1))') # half指fp16 quantize_copy_float = create_ufunc( 'bms_quantize_copy_float', ('ee->b', 'fe->b', 'ff->b'), 'out0 = nearbyintf(float(in0 / in1))') ======================================================== """
if axis < 0:
axis += len(value.shape)
# 以下3行分配显存给量化值、scale
nw_value = allocator.alloc_array(value.shape, cupy.int8)
scale_shape = value.shape[:axis] + (1,) + value.shape[axis + 1:]
scale = allocator.alloc_array(scale_shape, cupy.float16)
# 真正的量化函数,计算scale值存于scale中,计算量化值存于nw_value中
quantize(value, nw_value, scale, axis=axis)
return nw_value, scale # 返回量化值、scale
def forward(self,
allocator: Allocator,
curr_hidden_state: cupy.ndarray, # (batch, dim_model)
past_kv: cupy.ndarray, # (2, batch, num_heads, dim_qkv, past_kv_len)
position_bias: Optional[cupy.ndarray], # (1#batch, num_heads, past_kv_len)
past_kv_mask: cupy.ndarray, # (1#batch, past_kv_len)
decoder_length: Optional[int], # int
):
batch_size, dim_model = curr_hidden_state.shape
num_heads, dim_qkv, past_kv_len = past_kv.shape[2:]
assert past_kv.shape == (2, batch_size, num_heads, dim_qkv, past_kv_len)
assert past_kv.dtype == cupy.float16
assert num_heads == self.num_heads
assert dim_qkv == self.dim_qkv
assert curr_hidden_state.dtype == cupy.float16
if self.is_self_attn:
assert decoder_length is not None
if position_bias is not None:
assert position_bias.shape[1:] == (num_heads, past_kv_len)
assert position_bias.dtype == cupy.float16
assert past_kv_mask.shape[-1] == past_kv_len
# value->(batch, dim_model), scale->(batch, 1) 这里是one decoder-step,所以没有seq-len
# 对输入做量化
value, scale = self.quantize(allocator, curr_hidden_state[:, :], axis=1)
if self.is_self_attn: # 自注意力
qkv_i32 = allocator.alloc_array((3, batch_size, self.num_heads * self.dim_qkv, 1), dtype=cupy.int32)
else:
qkv_i32 = allocator.alloc_array((batch_size, self.num_heads * self.dim_qkv, 1), dtype=cupy.int32)
if self.is_self_attn:
# 自注意力时,qkv都要进行线性变换;使用igemm让cuda执行8bit matmul;
# 稍后展示igemm实现
igemm(
allocator,
self.w_project_qkv.value, # (3, num_head * dim_qkv, dim_model)
True, # 转置
value[cupy.newaxis], # (1, batch_size, dim_model)
False,
qkv_i32[:, :, :, 0] # (3, batch_size, num_head * dim_qkv)
)
else:
# 交叉注意力时,对q做线性变换
igemm(
allocator,
self.w_project_q.value[cupy.newaxis], # (1, num_head * dim_qkv, dim_model)
True,
value[cupy.newaxis], # (1, batch_size, dim_model)
False,
qkv_i32[cupy.newaxis, :, :, 0] # (1, batch_size, num_head * dim_qkv)
)
# release value
del value
# convert int32 to fp16 将上述线性变换结果int32转换为fp16
# 注意整个过程不是单一的int8或者int类型计算
assert qkv_i32._c_contiguous
qkv_f16 = allocator.alloc_array(qkv_i32.shape, dtype=cupy.float16)
if self.is_self_attn:
""" elementwise_copy_scale = create_ufunc('bms_scaled_copy', ('bee->e', 'iee->e', 'iee->f', 'iff->f'), 'out0 = in0 * in1 * in2') """
elementwise_copy_scale( # 执行反量化,得到fp16存于out里面
qkv_i32, # (3, batch_size, num_head * dim_qkv, 1)
self.w_project_qkv_scale.value[:, cupy.newaxis, :, :], # (3, 1#batch_size, dim_qkv * num_heads, 1)
scale[cupy.newaxis, :, :, cupy.newaxis], # (1#3, batch_size, 1, 1)
out=qkv_f16
)
else:
elementwise_copy_scale(
qkv_i32, # (1, batch_size, num_head * dim_qkv, 1)
self.w_project_q_scale.value, # (dim_qkv * num_heads, 1)
scale[:, :, cupy.newaxis], # (batch_size, 1, 1)
out=qkv_f16
)
del scale
del qkv_i32
# reshape
assert qkv_f16._c_contiguous
if self.is_self_attn:
qkv = cupy.ndarray((3, batch_size, self.num_heads, self.dim_qkv), dtype=cupy.float16, memptr=qkv_f16.data)
query = qkv[0] # (batch, num_heads, dim_qkv)
past_kv[0, :, :, :, decoder_length] = qkv[1] # 存储为历史kv,避免后续需要重复计算
past_kv[1, :, :, :, decoder_length] = qkv[2]
del qkv
else:
query = cupy.ndarray((batch_size, self.num_heads, self.dim_qkv), dtype=cupy.float16, memptr=qkv_f16.data)
del qkv_f16
# calc attention score(fp16)
attention_score = allocator.alloc_array((batch_size, self.num_heads, past_kv_len, 1), dtype=cupy.float16)
fgemm( # 计算注意力分数是使用float-gemm计算
allocator,
query.reshape(batch_size * self.num_heads, self.dim_qkv, 1), # (batch_size * num_heads, dim_qkv, 1)
False,
past_kv[0].reshape(batch_size * self.num_heads, self.dim_qkv, past_kv_len),
# ( batch_size * num_heads, dim_qkv, past_kv_len)
True,
attention_score.reshape(batch_size * self.num_heads, past_kv_len, 1)
# (batch_size * num_heads, past_kv_len, 1)
)
# mask计算
""" mask_attention_kernel = create_ufunc( 'bms_attention_mask', ('?ff->f',), 'out0 = in0 ? in1 : in2' # 选择器 ) """
mask_attention_kernel(
past_kv_mask[:, cupy.newaxis, :, cupy.newaxis], # (batch, 1#num_heads, past_kv_len, 1)
attention_score,
cupy.float16(-1e10),
out=attention_score # (batch_size, self.num_heads, past_kv_len, 1)
)
if position_bias is not None:
attention_score += position_bias[:, :, :, cupy.newaxis] # (1#batch, num_heads, past_kv_len, 1)
# 计算softmax float情形
temp_attn_mx = allocator.alloc_array((batch_size, self.num_heads, 1, 1), dtype=cupy.float16)
cupy.max(attention_score, axis=-2, out=temp_attn_mx, keepdims=True)
attention_score -= temp_attn_mx
cupy.exp(attention_score, out=attention_score)
cupy.sum(attention_score, axis=-2, out=temp_attn_mx, keepdims=True)
attention_score /= temp_attn_mx
del temp_attn_mx
# 计算softmax*V
out_raw = allocator.alloc_array((batch_size, self.num_heads, self.dim_qkv, 1), dtype=cupy.float16)
fgemm( # 仍然使用float gemm
allocator,
attention_score.reshape(batch_size * self.num_heads, past_kv_len, 1),
False,
past_kv[1].reshape(batch_size * self.num_heads, self.dim_qkv, past_kv_len),
False,
out_raw.reshape(batch_size * self.num_heads, self.dim_qkv, 1)
)
assert out_raw._c_contiguous
# 得到softmax(qk)*v结果
out = cupy.ndarray((batch_size, self.num_heads * self.dim_qkv), dtype=cupy.float16, memptr=out_raw.data)
del attention_score
del out_raw
# 注意力结果向量继续量化,以便下面再做一次linear
# (batch_size, num_heads * dim_qkv, 1), (batch_size, 1, 1)
out_i8, scale = self.quantize(allocator, out, axis=1)
project_out_i32 = allocator.alloc_array((batch_size, dim_model, 1), dtype=cupy.int32)
# 输出前再做一次linear projection(igemm)
igemm(
allocator,
self.w_out.value[cupy.newaxis], # (1, dim_in, dim_qkv * num_heads)
True,
out_i8[cupy.newaxis],
False,
project_out_i32[cupy.newaxis, :, :, 0]
)
assert project_out_i32._c_contiguous
# (batch, dim_model, 1)
project_out_f16 = allocator.alloc_array(project_out_i32.shape, dtype=cupy.float16)
# 反量化得到最终注意力结果fp16
elementwise_copy_scale(
project_out_i32,
self.w_out_scale.value, # (1#batch_size, dim_model, 1)
scale[:, :, cupy.newaxis], # (batch, 1, 1)
out=project_out_f16
)
return project_out_f16[:, :, 0] # (batch, dim_model)
- 以上代码小结:可以看到主要是对linear做量化,其他如norm、score、softmax等都是直接在float16上计算;整个过程是int、float交替使用,量化、反量化交替使用
- igemm函数:cupy如何在cuda上执行整型矩阵相乘,就是根据cuda规范写就行
def _igemm(allocator : Allocator, a, aT, b, bT, c, device, stream):
assert isinstance(a, cupy.ndarray)
assert isinstance(b, cupy.ndarray)
assert isinstance(c, cupy.ndarray)
assert len(a.shape) == 3 # (batch, m, k)
assert len(b.shape) == 3 # (batch, n, k)
assert len(c.shape) == 3 # (batch, n, m)
assert a._c_contiguous
assert b._c_contiguous
assert c._c_contiguous
assert a.device == device
assert b.device == device
assert c.device == device
lthandle = get_handle(device) # 为当前gpu创建handler
# 获取batch_size
num_batch = 1
if a.shape[0] > 1 and b.shape[0] > 1:
assert a.shape[0] == b.shape[0]
num_batch = a.shape[0]
elif a.shape[0] > 1:
num_batch = a.shape[0]
else:
num_batch = b.shape[0]
# 计算stride,batch内跨样本
if a.shape[0] == 1:
stride_a = 0
else:
stride_a = a.shape[1] * a.shape[2] # m*k
if b.shape[0] == 1:
stride_b = 0
else:
stride_b = b.shape[1] * b.shape[2] # n*k
if aT: # 需要转置;aT一般为True
m, k1 = a.shape[1:] # a [bs,m,k1]
else:
k1, m = a.shape[1:]
if bT:
k2, n = b.shape[1:]
else: # bT一般为False
n, k2 = b.shape[1:] # b [bs,n,k]
assert k1 == k2 # a*b => k维度大小要相同
k = k1
assert c.shape == (num_batch, n, m) # c = a*b
stride_c = n * m
## compute capability: cuda版本
# Ampere >= 80
# Turing >= 75
cc = int(device.compute_capability)
v1 = ctypes.c_int(1) # 设置常量1,后续作为CUDA规范要求的系数
v0 = ctypes.c_int(0) # 设置常量0
""" # 设置a/b/c 3个矩阵的属性(rt, m, n, ld, order, batch_count, batch_offset)=> MatrixLayout_t指针 # LayoutCache用来创建某个矩阵在显存中的表现形式(即layout),包括数据类型,行数、列数,batch大小,内存存储顺序(order,包括列存储模式、行存储模式等等)。。。 # cublasLt是加载cuda安装目录下cublast lib得到的; # 以下涉及cublasLt的函数,具体内容请移步bminf源代码和cuda官方doc查看 ============================================================ class LayoutCache(HandleCache): # 代码中layoutcache(...)会调用create,并返回指针 def create(self, rt, m, n, ld, order, batch_count, batch_offset): # 创建一个新的矩阵layout指针 ret = cublasLt.cublasLtMatrixLayout_t() # 上述指针指向新建的矩阵layout;rt-数据类型;m/n指row/col;ld-leading_dimension 列模式下是行数;checkCublasStatus根据返回状态检查操作是否成功 cublasLt.checkCublasStatus( cublasLt.cublasLtMatrixLayoutCreate(ret, rt, m, n, ld) ) # 设置矩阵的存储格式属性 cublasLt.checkCublasStatus( cublasLt.cublasLtMatrixLayoutSetAttribute(ret, cublasLt.CUBLASLT_MATRIX_LAYOUT_ORDER, ctypes.byref(ctypes.c_int32(order)), ctypes.sizeof(ctypes.c_int32)) ) # 设置矩阵的batch_count属性(batch内样本数量) cublasLt.checkCublasStatus( cublasLt.cublasLtMatrixLayoutSetAttribute(ret, cublasLt.CUBLASLT_MATRIX_LAYOUT_BATCH_COUNT, ctypes.byref(ctypes.c_int32(batch_count)), ctypes.sizeof(ctypes.c_int32)) ) cublasLt.checkCublasStatus( cublasLt.cublasLtMatrixLayoutSetAttribute(ret, cublasLt.CUBLASLT_MATRIX_LAYOUT_STRIDED_BATCH_OFFSET, ctypes.byref(ctypes.c_int64(batch_offset)), ctypes.sizeof(ctypes.c_int64)) ) return ret # 用完后释放占用的显存空间 def release(self, x): cublasLt.checkCublasStatus(cublasLt.cublasLtMatrixLayoutDestroy(x)) ============================================================ # 注意以下写法 表示 row=shape[2], col=shape[1],与实际相反;该处之所以这样写,是为了与稍早前的cuda做匹配;对于cc>=75的,还是会通过transform变换回row=shape[1], col=shape[2];见下文 """
layout_a = layout_cache(cublasLt.CUDA_R_8I, a.shape[2], a.shape[1], a.shape[2], cublasLt.CUBLASLT_ORDER_COL, a.shape[0], stride_a) # a是int8+列 存储
layout_b = layout_cache(cublasLt.CUDA_R_8I, b.shape[2], b.shape[1], b.shape[2], cublasLt.CUBLASLT_ORDER_COL, b.shape[0], stride_b) # b是int8+列 存储
layout_c = layout_cache(cublasLt.CUDA_R_32I, c.shape[2], c.shape[1], c.shape[2], cublasLt.CUBLASLT_ORDER_COL, c.shape[0], stride_c) # c是int32+列 存储
if cc >= 75:
# use tensor core
trans_lda = 32 * m # leading dimension of a
if cc >= 80:
trans_ldb = 32 * round_up(n, 32) # round_up对n上取整 到 32的倍数,如28->32, 39->64
else:
trans_ldb = 32 * round_up(n, 8)
trans_ldc = 32 * m
stride_trans_a = round_up(k, 32) // 32 * trans_lda # (「k」// 32) * 32 * m >= k*m 取 比a中1个样本 大一点的 32倍数空间,如k=40->k=64 => stride_trans_a=64*m
stride_trans_b = round_up(k, 32) // 32 * trans_ldb
stride_trans_c = round_up(n, 32) // 32 * trans_ldc
trans_a = allocator.alloc( stride_trans_a * a.shape[0] ) # 分配比a大一点的32倍数空间,注意因为是int8(1个字节),所以空间大小=元素数目
trans_b = allocator.alloc( stride_trans_b * b.shape[0] )
trans_c = allocator.alloc( ctypes.sizeof(ctypes.c_int32) * stride_trans_c * c.shape[0] ) # 注意是int32,不是int8
# 创建trans_a/b/c的layout
layout_trans_a = layout_cache(cublasLt.CUDA_R_8I, m, k, trans_lda, cublasLt.CUBLASLT_ORDER_COL32, a.shape[0], stride_trans_a)
if cc >= 80:
layout_trans_b = layout_cache(cublasLt.CUDA_R_8I, n, k, trans_ldb, cublasLt.CUBLASLT_ORDER_COL32_2R_4R4, b.shape[0], stride_trans_b) # 使用更高级的COL存储模式
else:
layout_trans_b = layout_cache(cublasLt.CUDA_R_8I, n, k, trans_ldb, cublasLt.CUBLASLT_ORDER_COL4_4R2_8C, b.shape[0], stride_trans_b)
layout_trans_c = layout_cache(cublasLt.CUDA_R_32I, m, n, trans_ldc, cublasLt.CUBLASLT_ORDER_COL32, num_batch, stride_trans_c)
# 创建a的tranform descriptor并设置transpose属性(类似上面layout,属于CUDA规范要求),返回descriptor;transform主要属性包括数据类型,是否转置等
# 注意到使用的数据类型是INT32,是因为transform操作会让输入乘以某个系数(这里指上面定义的整型v1/v0),两者类型要匹配,所以先让输入从INT8->INT32,计算结束再让INT32->INT8(见下文使用处)
transform_desc_a = transform_cache(cublasLt.CUDA_R_32I, aT)
transform_desc_b = transform_cache(cublasLt.CUDA_R_32I, not bT)
transform_desc_c = transform_cache(cublasLt.CUDA_R_32I, False)
""" # 创建CUDA函数cublasLtMatrixTransform(CUDA不能简单通过一个a.T就让a转置,需要较复杂的规范) cublasLtMatrixTransform = LibFunction(lib, "cublasLtMatrixTransform", cublasLtHandle_t, cublasLtMatrixTransformDesc_t, ctypes.c_void_p, ctypes.c_void_p, cublasLtMatrixLayout_t, ctypes.c_void_p, ctypes.c_void_p, cublasLtMatrixLayout_t, ctypes.c_void_p, cublasLtMatrixLayout_t, cudaStream_t, cublasStatus_t) # cublasLtMatrixTransform() => C = alpha*transformation(A) + beta*transformation(B) 矩阵变换操作 cublasStatus_t cublasLtMatrixTransform( cublasLtHandle_t lightHandle, cublasLtMatrixTransformDesc_t transformDesc, const void *alpha, # 一般为1 const void *A, cublasLtMatrixLayout_t Adesc, const void *beta, # 一般为0,此时 C=transform(A) const void *B, cublasLtMatrixLayout_t Bdesc, void *C, cublasLtMatrixLayout_t Cdesc, cudaStream_t stream); """
cublasLt.checkCublasStatus(
cublasLt.cublasLtMatrixTransform( # 对a执行变换操作(上面定义的变换是 32I 和 aT)
lthandle, transform_desc_a,
ctypes.byref(v1), a.data.ptr, layout_a,
ctypes.byref(v0), 0, 0, # 不使用B
trans_a.ptr, layout_trans_a, stream.ptr
)
)
cublasLt.checkCublasStatus(
cublasLt.cublasLtMatrixTransform( # 对b执行变换操作(上面定义的变换是 32I 和 not bT)
lthandle, transform_desc_b,
ctypes.byref(v1), b.data.ptr, layout_b,
ctypes.byref(v0), 0, 0,
trans_b.ptr, layout_trans_b, stream.ptr
)
)
if a.shape[0] != num_batch:
layout_trans_a = layout_cache(cublasLt.CUDA_R_8I, m, k, trans_lda, cublasLt.CUBLASLT_ORDER_COL32, num_batch, 0)
if b.shape[0] != num_batch:
if cc >= 80:
layout_trans_b = layout_cache(cublasLt.CUDA_R_8I, n, k, trans_ldb, cublasLt.CUBLASLT_ORDER_COL32_2R_4R4, num_batch, 0)
else:
layout_trans_b = layout_cache(cublasLt.CUDA_R_8I, n, k, trans_ldb, cublasLt.CUBLASLT_ORDER_COL4_4R2_8C, num_batch, 0)
# 创建matmul描述子:中间数据类型,计算类型(输入输出类型),aT,bT
# 使用INT32保存INT8计算结果;后两个参数表示a/b是否转置
matmul_desc = matmul_cache(cublasLt.CUDA_R_32I, cublasLt.CUBLAS_COMPUTE_32I, False, True)
""" # 计算 D = alpha*(A*B) + beta*(C) cublasStatus_t cublasLtMatmul( cublasLtHandle_t lightHandle, cublasLtMatmulDesc_t computeDesc, const void *alpha, const void *A, cublasLtMatrixLayout_t Adesc, const void *B, cublasLtMatrixLayout_t Bdesc, const void *beta, const void *C, cublasLtMatrixLayout_t Cdesc, void *D, cublasLtMatrixLayout_t Ddesc, const cublasLtMatmulAlgo_t *algo, void *workspace, size_t workspaceSizeInBytes, cudaStream_t stream); """
cublasLt.checkCublasStatus( cublasLt.cublasLtMatmul(
lthandle, # gpu句柄
matmul_desc,
ctypes.byref(ctypes.c_int32(1)), # alpha=1
trans_a.ptr, # a数据
layout_trans_a, # a格式
trans_b.ptr,
layout_trans_b,
ctypes.byref(ctypes.c_int32(0)), # beta=0,不加C偏置,即D = alpha*(A*B)
trans_c.ptr, # 不使用
layout_trans_c, # 不使用
trans_c.ptr, # D即C,属于 in-place(原地替换)
layout_trans_c,
0,
0,
0,
stream.ptr
))
cublasLt.checkCublasStatus(
cublasLt.cublasLtMatrixTransform( # 根据transform_desc_c对结果C做一次transform(int32,不转置)
lthandle, transform_desc_c,
ctypes.byref(v1), trans_c.ptr, layout_trans_c,
ctypes.byref(v0), 0, 0,
c.data.ptr, layout_c,
stream.ptr
)
)
else:
pass # 这里与上面不同之处是 使用老版本cuda,因此省略不再赘述,感兴趣的请自己去查看源代码
总结
- 以上是针对BMINF量化实现代码的分析,用来学习量化+cupy+cuda(具体是cublasLt)的实现;
- 代码只实现了最简单的对称量化;使用cupy+cublasLt实现线性层的量化;整个过程是量化和反量化,int和float的交替使用;
- 上述过程的C++版本也是去调用cublasLt相同函数,写法类似,感兴趣的可查看NVIDIA例子-LtIgemmTensor
- 上面只涉及CUDA/cublasLt的部分应用,更多的应用可参考 CUDA官方手册;
- 难免疏漏,敬请指教
边栏推荐
- JVM quick start
- LeetCode:394. String decoding
- LeetCode:124. 二叉树中的最大路径和
- After PCD is converted to ply, it cannot be opened in meshlab, prompting error details: ignored EOF
- C语言双指针——经典题型
- hutool优雅解析URL链接并获取参数
- LeetCode:673. Number of longest increasing subsequences
- sublime text中conda环境中plt.show无法弹出显示图片的问题
- The mysqlbinlog command uses
- LeetCode:387. 字符串中的第一个唯一字符
猜你喜欢
Chapter 1 :Application of Artificial intelligence in Drug Design:Opportunity and Challenges

Esp8266-rtos IOT development
704 binary search

Export IEEE document format using latex

Mobile phones and computers on the same LAN access each other, IIS settings
【嵌入式】Cortex M4F DSP库
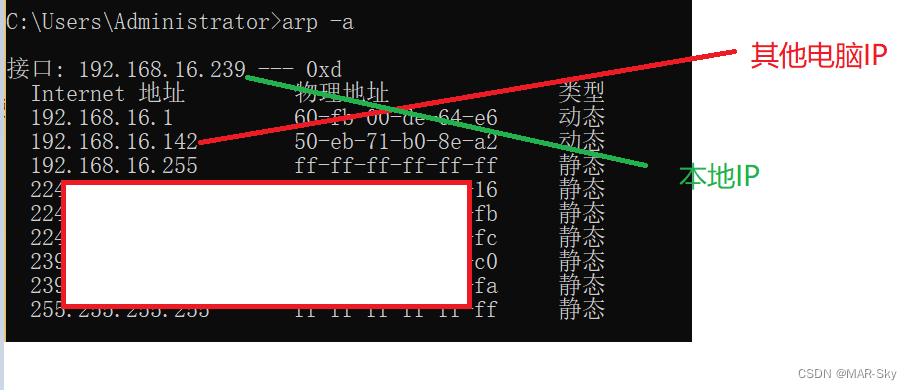
View computer devices in LAN

The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
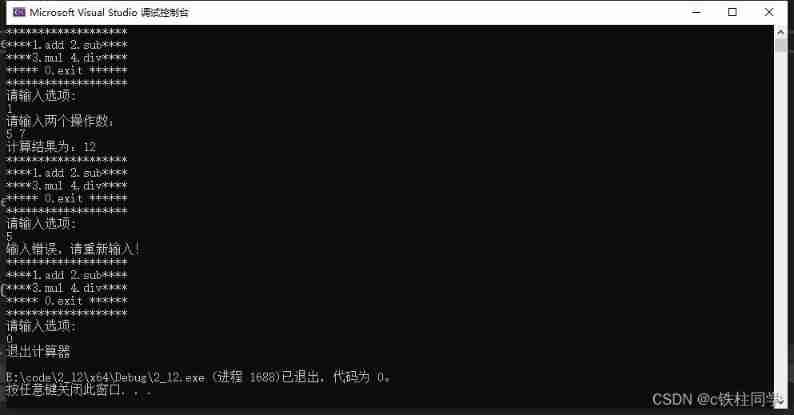
Using C language to complete a simple calculator (function pointer array and callback function)
Warning in install. packages : package ‘RGtk2’ is not available for this version of R
随机推荐
The mysqlbinlog command uses
Bitwise logical operator
PC easy to use essential software (used)
LeetCode:221. Largest Square
C language double pointer -- classic question type
同一局域网的手机和电脑相互访问,IIS设置
LeetCode:162. 寻找峰值
有效提高软件产品质量,就找第三方软件测评机构
Excellent software testers have these abilities
SAP ui5 date type sap ui. model. type. Analysis of the parsing format of date
Using C language to complete a simple calculator (function pointer array and callback function)
Crash problem of Chrome browser
Navicat Premium 创建MySql 创建存储过程
LeetCode:221. 最大正方形
LeetCode:236. The nearest common ancestor of binary tree
LeetCode:214. 最短回文串
CSP first week of question brushing
ROS compilation calls the third-party dynamic library (xxx.so)
自动化测试框架有什么作用?上海专业第三方软件测试公司安利
Image,cv2读取图片的numpy数组的转换和尺寸resize变化