当前位置:网站首页>Current situation and trend of character animation
Current situation and trend of character animation
2022-07-06 08:39:00 【daoboker】
One 、 Personal needs
demand :
- By the joystick ( user ) Take the root track of the virtual character trajectory To control the user's orientation , At the same time, through control input, we can synthesize actions that are difficult for people to do .
- If data set is missing , It can be used Reinforcement learning To complete some actions controlled by the handle, such as flying kick , We should also be able to meet the user's needs wherever they point , And the movements of other parts of the body are completed by dynamic catching ( You can consider the action styles of different characters ), That is, each kind of semantics must be decided by the user .
- Consider the method of inserting frames , That is, use action libraries from different sources 、 Game control 、 Capture, etc. to combine for frame insertion , After discussion, we decided to adopt the second point .
Existing problems :
Mobile capture data is expensive and lacks large data sets , And the existing data sets, such as character animation, currently capture data displacement is not perfect , Mobile capture can't let the character in VR Walk infinitely , Mobile capture can't let users complete leap and other actions , This is also achieved by synthesizing actions through user control input …
Two 、 Character animation (Character Animation) The current situation and trend of China's economic development
- State machine animation , A lot of work 、 Transition is easy to be distorted , Slipping feet, die piercing, etc ;
- Motion Matching, Choose animation through algorithm “ state ”, Need a lot of dynamic capture data, pay attention to matching speed ;
- Based on data driven AI Method ,PFNN etc. , Deep learning is introduced, and the neural network memorizes the motion capture animation to predict the animation of the next frame , During training, the next frame of the dynamic capture data segment is used as the label ;
This category is calledKinematic animation (Kinematic-based Animation), Mainly Daniel Holden And the work of his brothers . Its limitation is that all animation samples are preset ( For example, mobile capture recording ),AI It's also these preset actions , When outputting animation AI The influence of virtual physical environment on characters is not considered . Physical animation (Physics-based Animation)
The way physical animation drives characters is completely different from the way kinematic animation . For kinematic animation , We directly assign the pose of the character , For example, its joint position ; For physical animation , We are motors that control every joint like robots , The joint motor outputs torque to change the position of the joint , At the same time, this process is strictly affected by the laws of Physics .
The pioneering work of this piece is Xuebin Peng Of DeepMimic, Take a section of dynamic capture data as input , And then use DRL Training to get a control strategy , Then use this control strategy to make the simulation agent Reproduce this action in the physics engine .DeepMimic Provides a set of extensible DRL Framework to imitate learning different motion skill.
Most of the work in the following years is basically based on DeepMimic, These jobs are similar , Ideas are based on kinematic-based Of motion generator (PFNN Wait for neural network or motion matching And traditional technology ) To generate refenece motion, And then use physical-based The way to track these reference motion.
1. Kinematic animation
Phase-functioned neural networks for character control’17
https://blog.csdn.net/zb1165048017/article/details/103990505
This article USES the Phase Function The phase function goes periodic Cycle dynamically changing weights , This Phase In this paper, it is used to specify the landing state of the foot, that is, the phase of the right foot when it lands is 0, When the left foot lands, the phase is π, The next time the right foot lands, the phase is 2 π.
When doing mobile fishing , Usually, a certain control parameter is used to change the weight of the trained neural network , The next frame will be Sports style leads to the specified behavior state . For example, it was originally walking , If the input is always go , The weight remains the same , Then all the animation frames generated later are very sad to cross to running or other sports styles . Adjust the weight dynamically and directionally through a certain control parameter , It can pull the movement from the feature space of walking to the hidden feature space of running , Then reconstruct the bone animation data from the feature space ( Euler Angle 、3D Coordinates, etc ).
So when multiple motion segments are interpolated into a new motion , By adjusting the mixing weights, we can build a smooth, natural and wide-ranging motion .
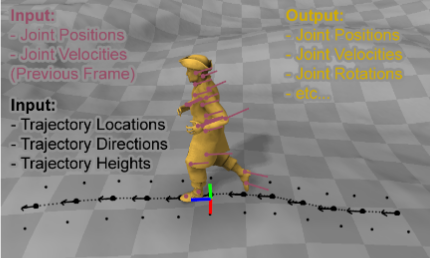
As shown in the figure above , Pink is the position and speed of the character's joints in the previous frame . The black part is the position of the down sampling track 、 Direction and height . Yellow is the character's grid , Use the joint position and rotation output by the system to deform .
Data sets :
Capture all kinds of terrain ( obstacle , steep hill , Platform, etc ), All kinds of behavior ( go 、 jogging 、 run 、 Crouch 、 jumping 、 Different steps, etc ), About an hour of data ,60FPS,1.5G.CMU Of BVH Dynamic capture data format , Include 30 The rotation angle of a joint ,1 The position of the root joint .
Data labels :
- Phase label :
When the foot landing time is obtained , The phase when the right foot just hits the ground phase Marked as 0, Mark the phase of the left foot when it just lands as π, Mark the phase of the next right foot landing as 2 π. - Gait tags :
Binary label vector , Represents 8 Different sports styles , Manual marking is required .
Neural State Machine for Character-Scene Interactions’19
In the last article, a fixed phase function was forced to decompose the network weights [Holden et al. 2017], This is only suitable for periodic circular motion . In this paper , The author proposes a neural state machine , To model a wide range of periodicity and Aperiodicity motion , Including sports 、 sit 、 standing 、 Lift and avoid collisions .
Compared with the previous article , It mainly deals with the interaction of more complex game scenes , Such as carrying boxes 、 Sitting on a stool or something .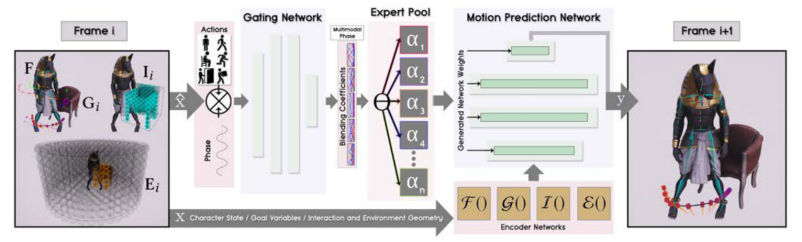
As shown in the figure above , The system structure consists of Gating Network and Motion Prediction Network Two modules make up . Gated network Take the current state parameter subset and the target action vector as input , Output the expert mixing coefficient as the prediction network weights, Then it is used to generate a motion prediction network . Motion prediction network Control the attitude trajectory of the previous frame 、 Target parameters 、 Interaction Parameters 、 Environment parameters are used as input to predict the current frame .
For example, the user only needs instructions “ Sitting in a chair ” As the desired target action . Then input this into the gating network , Activate the expert weights it needs to generate the next frame action .
Data sets :
The author captures a person approaching and sitting on a chair through the prop environment 、 Avoid obstacles when walking 、 Open and go through the door 、 Pick up 、 The actions of moving and dropping a box build a data set . And built some more complex scenes , For example, sitting on a chair partially under the table , In this way, people need to stretch their legs or put their hands on the table to complete the sitting action . from XSens Inertial motion capture system Collect and output a total of 94 Minutes of motion capture data .
Data labels :
- Action tag :
Each frame of data is annotated with a current and target action tag . such as “ Free ”、“ walk ”、“ function ”、“ sit ”、“ open ”、“ climb ” or “ carry ”, Or two combinations (“ carry + idle ”、“ carry + walk ”), They describe the motion type of the current frame . By using the target tag as the target parameter G() Part of the training system . - Phase label :
For periodic motion , According to the left / Right / The phase when the left foot lands is defined as 0、π and 2π, The intermediate phase is calculated by interpolation . For non periodic movements like sitting , In the coordinate system of the beginning and end of the transformation , The phase is defined as 0 and 2π, The middle part is calculated by interpolation again .
learned motion matching’20
It can be seen from the bottom left figure , The traditional motion matching algorithm includes three main stages :
Projection: Use nearest neighbor search to find the best matching feature vector to match the query vector in the database ;
Stepping: Advance the index in the matching database ;
Decompression: Find the relevant posture corresponding to the current index in the matching database in the animation database, and then match .
The lower right figure shows the method of using neural network to predict the next frame , Which is used to replace the database Motion Matching The network can be disassembled into three unique neural networks P、S、D.
- P The network is responsible for according to the query vector Search out the matching x,z;
- S The network is responsible for tracking according to the previous frame x,z Predict the next frame x,z;
- D The network is responsible for x, z Predict the pose information of the current frame y.
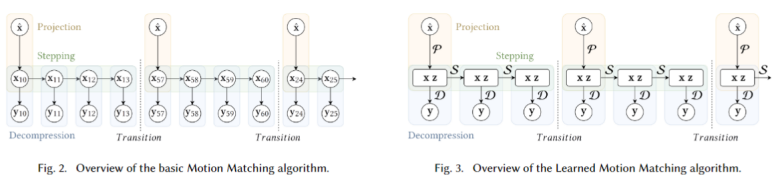
Recent methods show that , The model based on neural network can be effectively applied to generate real motion in many difficult situations , Including navigation on rough terrain [Holden wait forsomeone 2017 year , Last one ], Quadruped movement [Zhang wait forsomeone 2018 year ], And interaction with the environment or other roles [Lee wait forsomeone 2018 year ;Starke et al. 2019]. However , Such a model is often difficult to control , Behavior is unpredictable , Long training time , And may produce animation of lower quality than the original training set [Büttner 2019;Zinno 2019].
The author also uses a data enhancement technique ,Carpet unrolling for character control on uneven terrain One used in this paper is called “ The carpet unfolds ” Automatic data enhancement technology , It can produce all kinds of turns and movements on rough terrain . The result is an inclusion of about 700000 An extensive database of frame animations . However, when matching with basic motion, this large enhanced database is very inefficient , But it's easy to adapt to the author's method .
When the environment is composed of uneven terrain and huge obstacles , This problem is even more challenging , Because this requires the role to perform various steps 、 climbing 、 Jumping or avoiding action , In order to follow the user's instructions . under these circumstances , We need a framework that can learn from a large number of high-dimensional motion data , Because there may be a large combination of different motion trajectories and corresponding geometric shapes .
2. Physics animation
DeepMimic: Example-Guided Deep Reinforcement Learning’18
ubuntu Environment configuration
bvh2mimic Format of reinforcement learning training set
This article consists of a paragraph motion capture As input , And then use DRL Training to get a control strategy , Then use this control strategy to make the simulation agent stay physics simulation Repeat this action in .DeepMimic A set of scalable Of DRL Framework to imitate learning different motion skill.
Most of the work in the following years is basically based on DeepMimic, These jobs are similar , Ideas are based on kinematic-based Of motion generator (PFNN Wait for neural network or motion matching And traditional technology ) To generate refenece motion, And then use physical-based The way to track these reference motion.
Whole DeepMimic The required input Divided into three parts : One is called Character Of Agent Model ; to want to Agent Reference actions for learning (reference motion); to want to Agent The task accomplished (task) Defined by the reward function. After training, you will get a controllable Agent At the same time, it satisfies the controller that is similar to the reference action and can complete the task (controller).DeepMimic Our physical environment uses Bullet .
State: The position of each part of the body , Rotation angle , Angular velocity, etc .
Action: The direction each joint needs to turn ( Target angle ), Then the angle is converted into torque and other information is input into the physical environment .
Reward: In two parts , The first part encourages Character Imitate what learning provides reference motion; The second part drives Character To complete the set task .
More results :
in general , The author only provides different reference movements for humanoid animals , Can learn more than 24 Skills .

In addition to imitating motion capture , You can also train the human form to perform some additional tasks , For example, kick randomly placed targets , Or throw the ball to the target .

Without dynamic capture data . The author manually animated some key frames of Tyrannosaurus Rex , Then train a strategy to simulate these keyframes .
trick1:
Reference state initialization (Reference State Initialization,RSI)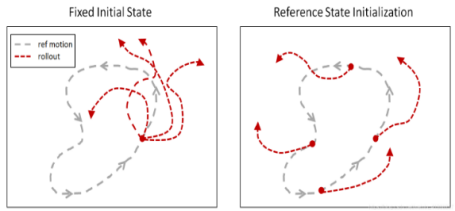
RSI By initializing the agent to a state randomly sampled from the reference action , Provide it with rich initial state distribution .( Including starting directly in midair )
trick2:
Early termination (Early Termination,ET)
If the agent is trapped in a certain state , It is no longer possible to successfully learn movements , Then the episode Will terminate in advance , To avoid continuing the simulation .

Left :RSI+ET; in : nothing RSI; Right : nothing ET
AMP: Adversarial Motion Priors for Stylized Physics-Based Character Control’21
pytorch Version implementation
This paper gives a reference motion data set that defines the required motion style of a character , For system Gan The discriminator trains a motion a priori , During training for policy Policy specifies style reward𝑟𝑆𝑡. These style rewards are combined with task rewards , It is used for training to make the simulated character meet the specific task goals g The strategy of .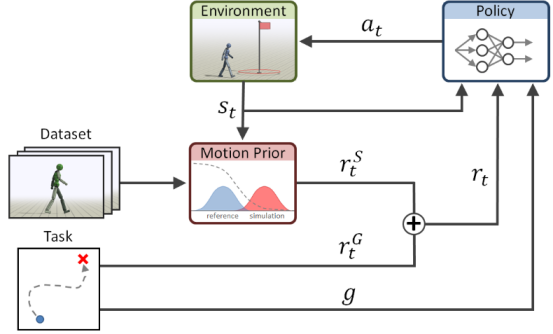
Compared with the previous Deepmimic, This system can be directly applied to the original motion data , There is no need to annotate the task or split the clip into personal skills . Style goals act as task independent motion priors , Independent of specific tasks , And encourage strategies to generate actions similar to the behavior described in the dataset . Finally, training one can achieve high level task( Flying kick , Throw the ball ), It can make motion Go to the fitting low level motion database(style, Dynamic capture data ) Network of .
3、 ... and 、 appendix
Motion Matching Basic concepts of :
Data preprocessing :
In order to save the calculation amount at runtime , First of all, pre calculate the dynamic capture data , Export a copy Motion Matching The data set needed to speed up the search , For basic movement, it is generally necessary to pre calculate the following data for each frame :
Each frame of action corresponds to an attitude data (pose) And the trajectory of the character for a period of time in the future (trajectory)
class Pose
{
Vector3 RootVelocity;
Vector3 LeftFootPosition;
Vector3 LeftFootVelocity;
Vector3 RightFootPosition;
Vector3 RightFootVelocity;
}
class TrajectoryPoint
{
Vector3 Position;
Vector3 Velocity;
}
class Trajectory
{
TrajectoryPoint[]points=new\ trajectoryPoint[3];
}
match Algorithm running :
Input : Input according to the player's handle , Give the expected Trajectory
Output : Go to database Search to match the action that should be played in the next frame , There are two conditions that need to be met ,
- Start from the next frame , Future frames Trajectory Consistent with the expected trajectory entered .
- The pose to be played can smoothly connect with the current pose , No jump .
边栏推荐
- 深度剖析C语言数据在内存中的存储
- 自动化测试框架有什么作用?上海专业第三方软件测试公司安利
- The mysqlbinlog command uses
- Sort according to a number in a string in a column of CSV file
- 2022.02.13 - 238. Maximum number of "balloons"
- Leetcode skimming (5.29) hash table
- 【Nvidia开发板】常见问题集 (不定时更新)
- swagger设置字段required必填
- JS native implementation shuttle box
- Process of obtaining the electronic version of academic qualifications of xuexin.com
猜你喜欢
2022.02.13 - NC001. Reverse linked list
Fibonacci sequence

IoT -- 解读物联网四层架构
延迟初始化和密封类
堆排序详解
The harm of game unpacking and the importance of resource encryption
JVM performance tuning and practical basic theory - Part 1
marathon-envs项目环境配置(强化学习模仿参考动作)
Process of obtaining the electronic version of academic qualifications of xuexin.com
生成器参数传入参数
随机推荐
MySQL learning record 11jdbcstatement object, SQL injection problem and Preparedstatement object
Delay initialization and sealing classes
LDAP Application Section (4) Jenkins Access
电脑清理,删除的系统文件
Visual implementation and inspection of visdom
On the day of resignation, jd.com deleted the database and ran away, and the programmer was sentenced
swagger设置字段required必填
ROS compilation calls the third-party dynamic library (xxx.so)
Tcp/ip protocol
leetcode刷题 (5.28) 哈希表
China Light conveyor belt in-depth research and investment strategy report (2022 Edition)
gcc动态库fPIC和fpic编译选项差异介绍
Verrouillage [MySQL]
FairGuard游戏加固:游戏出海热潮下,游戏安全面临新挑战
poi追加写EXCEL文件
After PCD is converted to ply, it cannot be opened in meshlab, prompting error details: ignored EOF
2022.02.13 - NC002. sort
Problems in loading and saving pytorch trained models
PLT in Matplotlib tight_ layout()
On the inverse order problem of 01 knapsack problem in one-dimensional state