当前位置:网站首页>Problems in loading and saving pytorch trained models
Problems in loading and saving pytorch trained models
2022-07-06 08:33:00 【MAR-Sky】
stay gpu Finish training , stay cpu Load on
torch.save(model.state_dict(), PATH)# stay gpu Save after training
# stay cpu Loaded on the model of
model.load_state_dict(torch.load(PATH, map_location='cpu'))
stay cpu Finish training , stay gpu Load on
torch.save(model.state_dict(), PATH)# stay gpu Save after training
# stay cpu Loaded on the model of
model.load_state_dict(torch.load(PATH, map_location='cuda:0'))
Loading contents that need attention in use
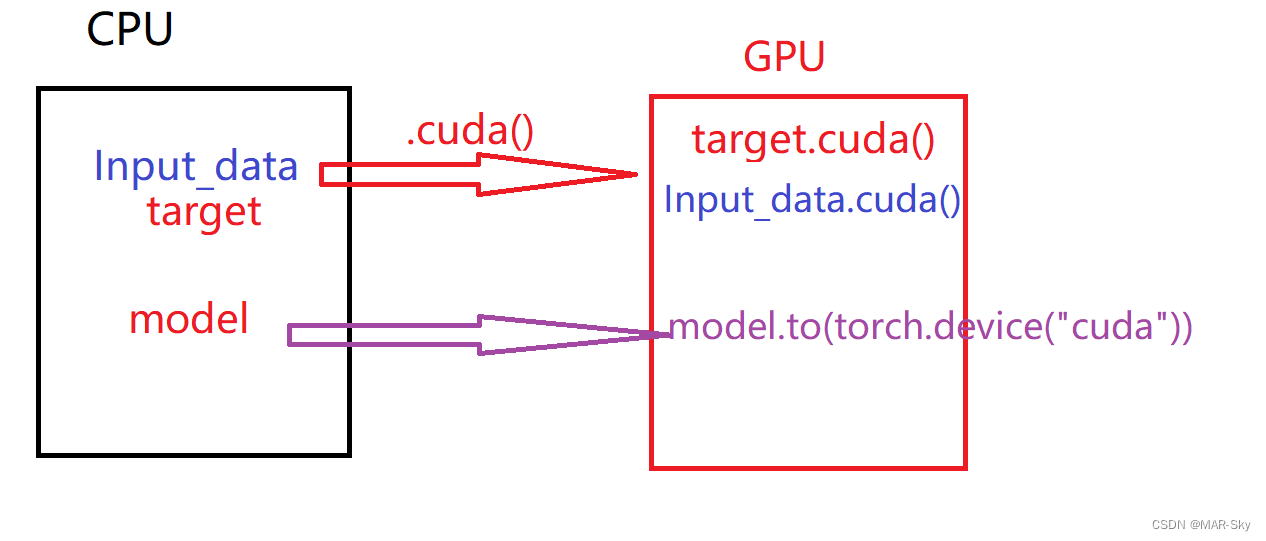
When data is put into GPU, Models that need training should also be put into GPU
''' data_loader:pytorch Load data in '''
for i, sample in enumerate(data_loader): # Traverse the data by batch
image, target = sample # The return value of each batch loading
if CUDA:
image = image.cuda() # Input / output input gpu
target = target.cuda()
# print(target.size)
optimizer.zero_grad() # Optimization function
output = mymodel(image)
mymodel.to(torch.device("cuda"))
Multiple gpu Loading during training
Reference resources :https://blog.csdn.net/weixin_43794311/article/details/120940090
import torch.nn as nn
mymodel = nn.DataParallel(mymodel)
pytorch Medium nn Module USES nn.DataParallel Load the model into multiple GPU, We need to pay attention to , The weight saved by this loading method The parameters will Not used nn.DataParallel Before loading the keywords of the weight parameters saved by the model More than a "module.". Whether to use nn.DataParallel Load model , It may cause the following problems when loading the model next time ,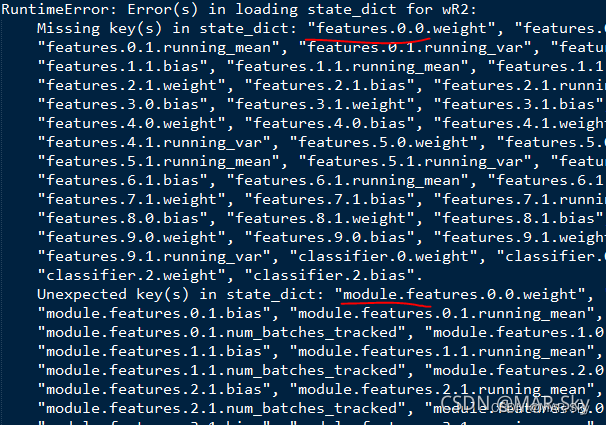
When there is one more in front of the weight parameter “module." when , The easiest way is to use nn.DataParallel Load model ,
边栏推荐
- pcd转ply后在meshlab无法打开,提示 Error details: Unespected eof
- Vocabulary notes for postgraduate entrance examination (3)
- logback1.3. X configuration details and Practice
- Visual implementation and inspection of visdom
- Use dumping to back up tidb cluster data to S3 compatible storage
- What is CSRF (Cross Site Request Forgery)?
- The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
- Browser thread
- MySQL learning records 12jdbc operation transactions
- [brush questions] top101 must be brushed in the interview of niuke.com
猜你喜欢
synchronized 解决共享带来的问题

Beijing invitation media

Mobile phones and computers on the same LAN access each other, IIS settings
PC easy to use essential software (used)
Deep learning: derivation of shallow neural networks and deep neural networks
![[brush questions] top101 must be brushed in the interview of niuke.com](/img/55/5ca957e65d48e19dbac8043e89e7d9.png)
[brush questions] top101 must be brushed in the interview of niuke.com
Ruffian Heng embedded bimonthly, issue 49
MySQL learning records 12jdbc operation transactions

2022.02.13 - NC004. Print number of loops
sublime text没关闭其他运行就使用CTRL+b运行另外的程序问题
随机推荐
Use br to back up tidb cluster data to S3 compatible storage
leetcode刷题 (5.29) 哈希表
被破解毁掉的国产游戏之光
优秀的软件测试人员,都具备这些能力
China dihydrolaurenol market forecast and investment strategy report (2022 Edition)
Bottom up - physical layer
Research and investment forecast report of citronellol industry in China (2022 Edition)
Yyds dry goods inventory three JS source code interpretation eventdispatcher
Beijing invitation media
2022 Inner Mongolia latest construction tower crane (construction special operation) simulation examination question bank and answers
JVM 快速入门
角色动画(Character Animation)的现状与趋势
CISP-PTE实操练习讲解
2022.02.13 - NC004. Print number of loops
FairGuard游戏加固:游戏出海热潮下,游戏安全面临新挑战
如何进行接口测试测?有哪些注意事项?保姆级解读
Cisp-pte practice explanation
Process of obtaining the electronic version of academic qualifications of xuexin.com
MySQL learning record 07 index (simple understanding)
延迟初始化和密封类