当前位置:网站首页>如何正确截取字符串(例:应用报错信息截取入库操作)
如何正确截取字符串(例:应用报错信息截取入库操作)
2022-07-06 08:49:00 【搏·梦】
文章目录
1. 前言
在参与工作的时候,发现有时候会把一些错误信息落库操作,但错误信息的长度又是没办法提前预知其大小,因此,默认会在存储错误信息字段上设置默认值,但也会因为偶然事情,导致错误信息长度大于该字段定义的长度,从而入库操作失败。
为了解决上述问题,必然会需要对错误信息进行字符串substring截取操作。
通常截取字符串,方式如下:
String str = "错误信息"; String errMsg = str.substring(0, "具体字段大小值"); xxxDao.insert(errMsg);但会不会出现截取字符串出现乱码的情况呢?如下:
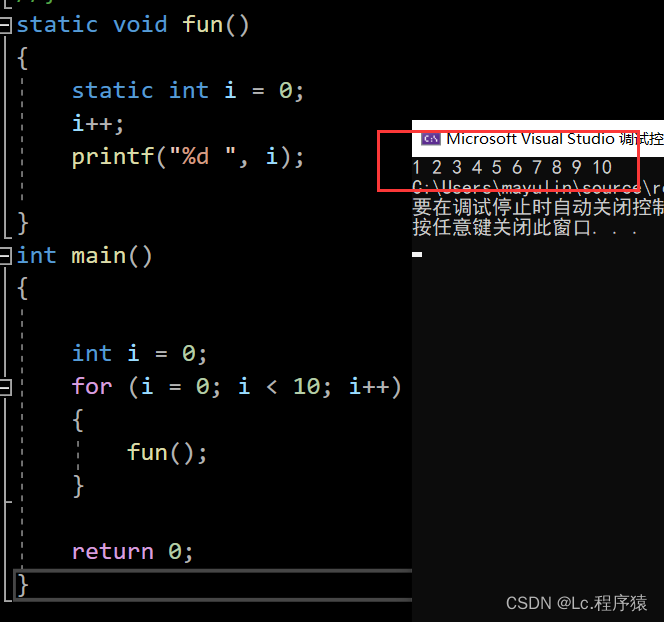
当一个错误信息String存储的是这个表情:public class demo { public static void main(String[] args) { String str = "\uD83D\uDe06"; System.out.println(str); } }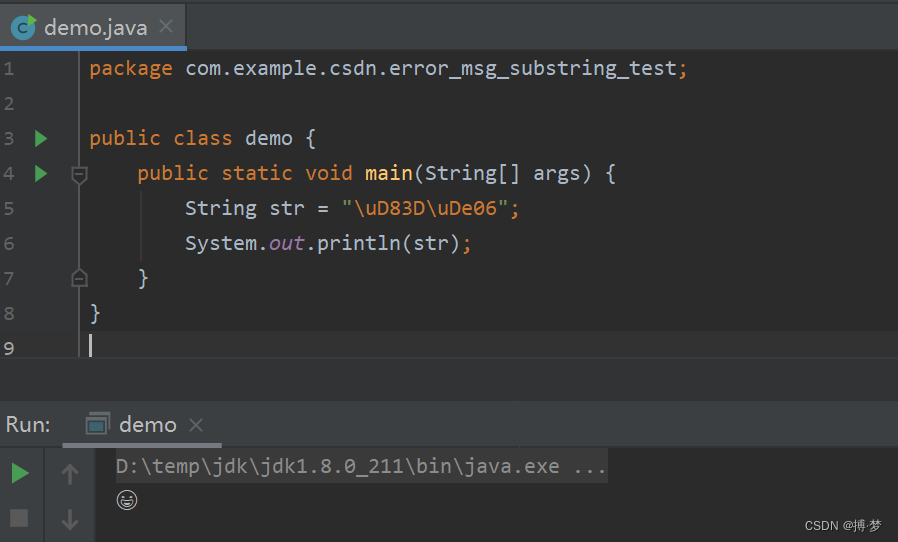
现要求只要保留错误信息长度只有1:public class demo { public static void main(String[] args) { String str = "\uD83D\uDe06"; System.out.println("str的输出:" + str); System.out.println("str原有的长度:" + str.length()); System.out.println("str截取长度为1的时候: " + str.substring(0, 1)); } }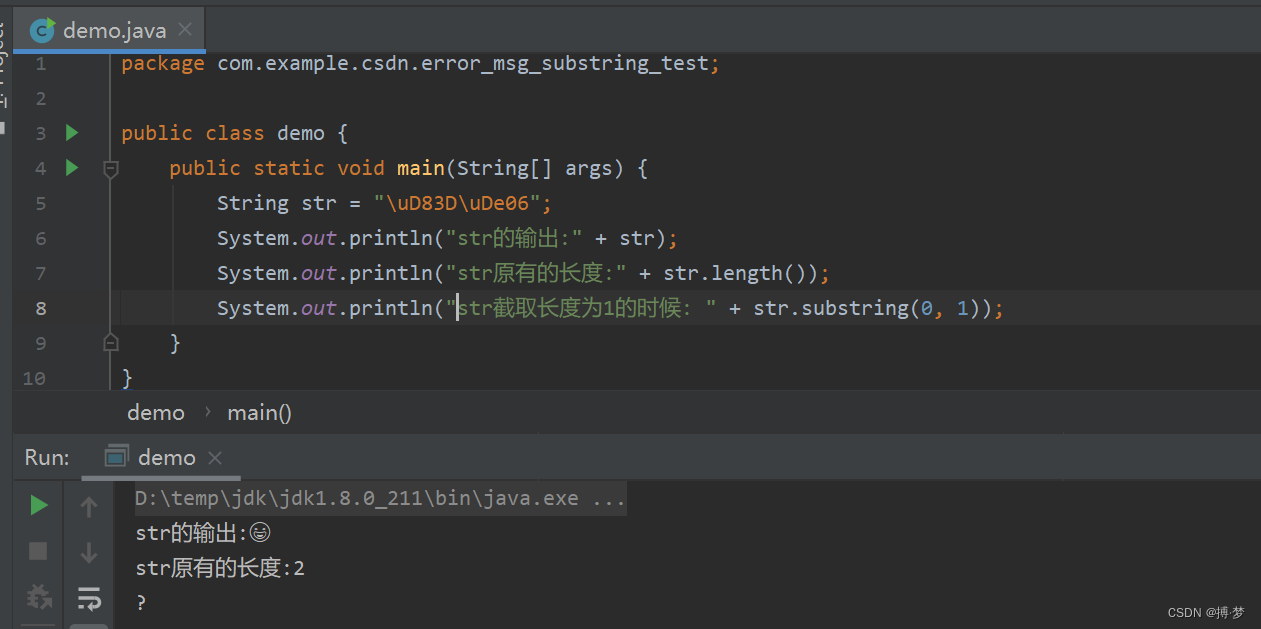
从上图可以知道,这截取的字符串已不是人可以看得懂的了。问题总结一句话:
要如何正确截取字符串呢?
2. 解析
1. 字节与字符区别
- 字节:是计算机信息技术用于计量存储容量的一种计量单位,通常情况下:一个字节等于八位。通俗来说:字节就是单位
- 字符:是指计算机中使用的字母、数字、字和符号。如:A,1,小明等,这些都可以叫字符。
- 通常常用字符集是gbk、utf8
- gbk中:一个英文字符由一个字节组成,一个中文字符由两个字节组成。
- uft8中:一个英文字符由一个字节组成,一个中文字符由三个字节组成。
2. java中的char
- 在java中,String字符串其实是由一个个字符组成的,而在java中char代表一个字符,它是采用 UTF-16 来表示字符,将字符定义为固定宽度的 16 位实体,也就是所谓的2个字节(8位为1字节)
- 这就说明在java中char类型的变量可以存储一个中文汉字。
- char 这个类型是 16位的。它可以有65536种取值,即65536个编号,每个编号可以代表1种字符。
但实际上这些编号还远远不够用,比如表情,特殊生僻字等等,因此需要更加多编号代表其他字符,原本一个char可以代表一种字符,现在用一下排列组合,用两个char代表另一种字符,这样子就可以多很多很多种情况,很多种编号。
3. 代理项(Surrogate)
- 代理项(Surrogate),是一种仅在 UTF-16 中用来表示补充字符的方法。在 UTF-16 中,为补充字符分配两个 16 位的 Unicode 代码单元:
- 第一个代码单元,被称为高代理项代码单元或前导代码单元
- 第二个代码单元,被称为低代理项代码单元或尾随代码单元。
- 在 UTF-16 中用其2048个来作为代理项,
- 编号为 U+D800 至 U+DBFF 的规定为「High Surrogates」,共1024个。
- 编号为 U+DC00至 U+DFFF 的规定为「Low Surrogates」,也是1024个
- 它们两两组合出现,就又可以多表示1048576种字符。
- 如果丢失一个高位代理Surrogates或者低位代理Surrogates,就会出现乱码。
- 特殊字符是由 高位代理项+低位代理项 构成。
4. 截取字符串
设当前有个字符串String str = ”表情:“;
现需求:分别截取长度最大为 1、2、3、4的字符串出来,不允许有乱码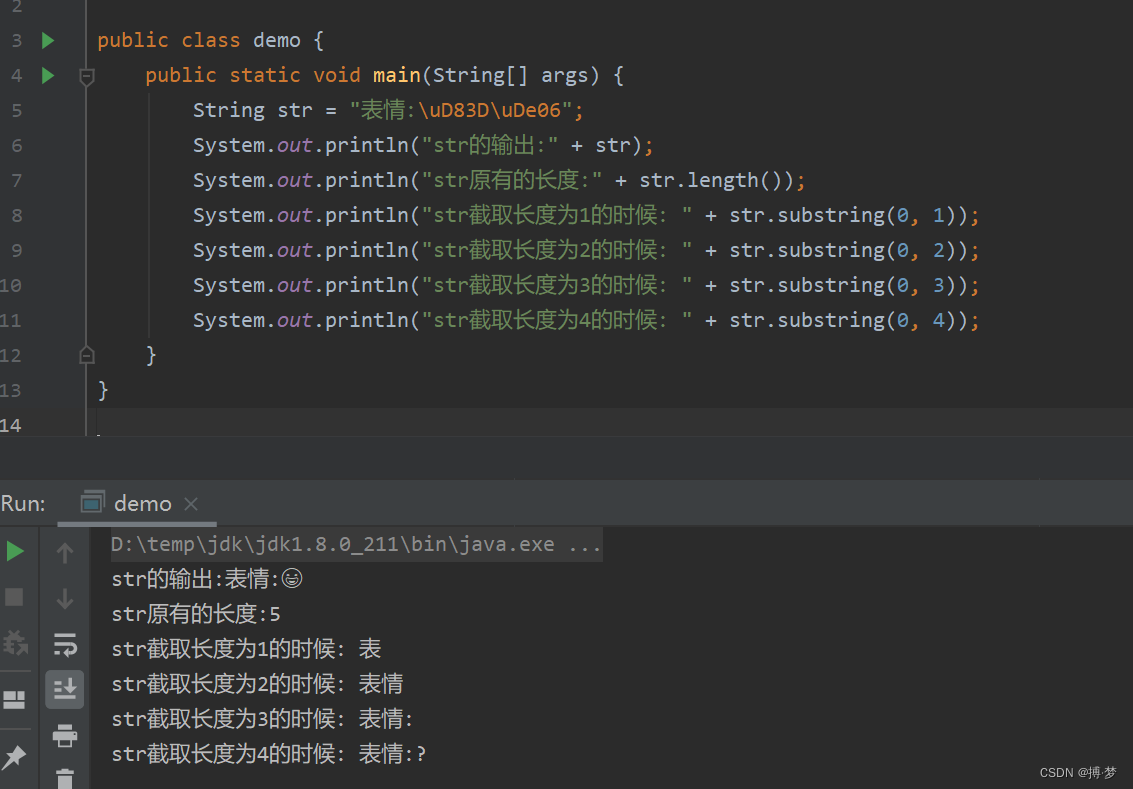
public class demo { public static void main(String[] args) { // 1. str 字符串长度为5,即是占两个长度(char) String str = "表情:\uD83D\uDe06"; System.out.println("str的输出:" + str); System.out.println("str原有的长度:" + str.length()); System.out.println("str截取长度为1的时候: " + str.substring(0, 1)); System.out.println("str截取长度为2的时候: " + str.substring(0, 2)); System.out.println("str截取长度为3的时候: " + str.substring(0, 3)); // 2. 这里输出的时候乱码了,因为之前所说的: // 如果丢失一个高位代理Surrogates或者低位代理Surrogates,就会出现乱码 System.out.println("str截取长度为4的时候: " + str.substring(0, 4)); } }因此在截取字符串的时候,不能想当然的根据长度截取,应考虑到高低位代理项的问题:
public class demo { public static void main(String[] args) { String str = "表情:\uD83D\uDe06"; System.out.println("str的输出:" + str); // 设要截取的长度为4 int length = 4; // 找到第四个字符 // length - 1 是因为下标从0开始的 char c = str.charAt(length - 1); // 判断其是否为高位代理 if (Character.isHighSurrogate(c)) { // 若为高位代理项,说明会把两个char的字符截取到一半出现乱码 // 因此要去掉该高位代理项 // 这里 length - 1 是因为substring(0,3) 包左不包右 // 因此 只有 0 1 2下标的char字符 只有三位 System.out.println(str.substring(0, length - 1)); } else { // 若不为高位代理项,有可能是低位代理项 // 但是截取都到了低位代理项,说明前面已经包含高位代理项,不会乱码 // 还有可能就是一个char的字符,肯定不会乱码 System.out.println(str.substring(0, length)); } } }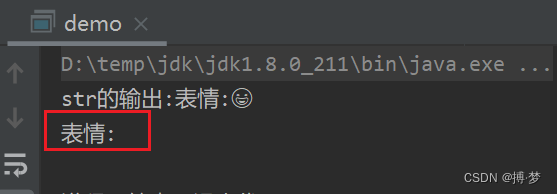
5. 将string插入数据库中
1. mysql与oracle中varchar的区别
- 设在两种数据库中存储的编码都是utf8:
- 在mysql中varchar(5):5代表5个字符,可以存储5个字符,即五个英文、或五个中文、只要存入的字符串长度是5都可以插入。
- 在oracle中varchar(5):5代表5个字节,是字节,是字节。当然它也可以存储五个英文,但是最多只能存储1个中文,因为一个中文占3个字节,还有两个字节的位置,也就是最多再存储2个英文。
- 字节与字符的区别,上文有解释,简单来说就是字符 > 字节
- mysql不理这个字符占多少个字节,它理到底可以存多少字符
2. 演示两者varchar区别
- 在mysql中,准备表与代码如下:

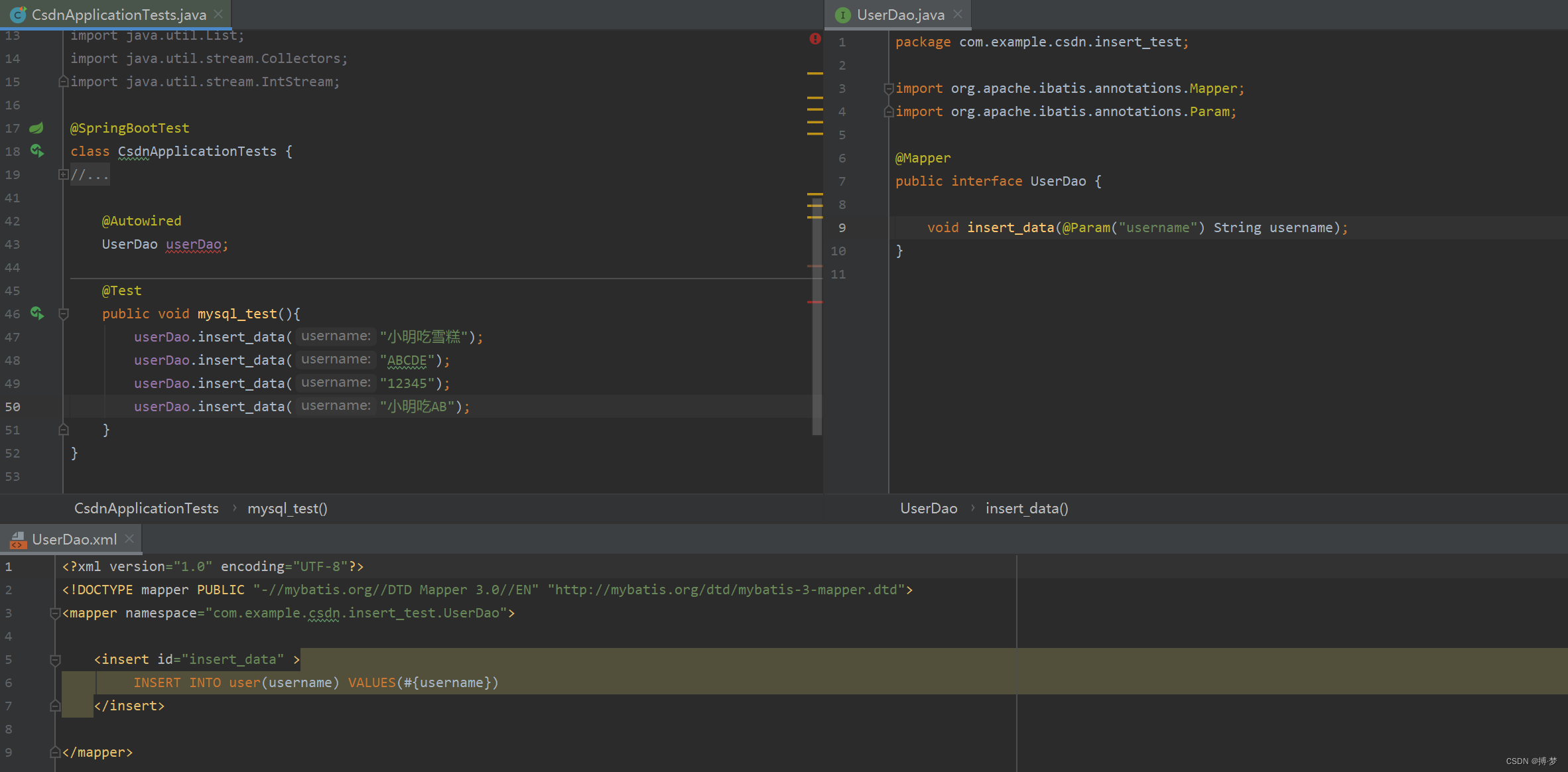
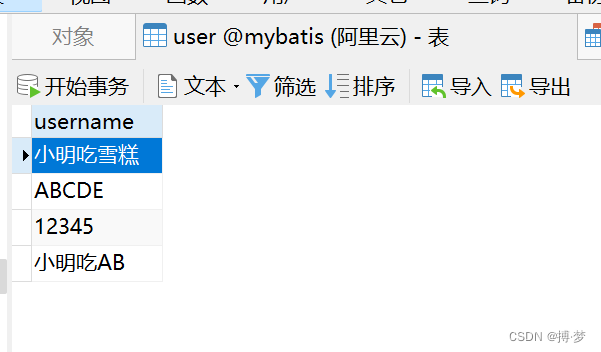
- 在oracle中,表与代码都不变:
在执行第一句:userDao.insert_data(“小明吃雪糕”),则报错如下: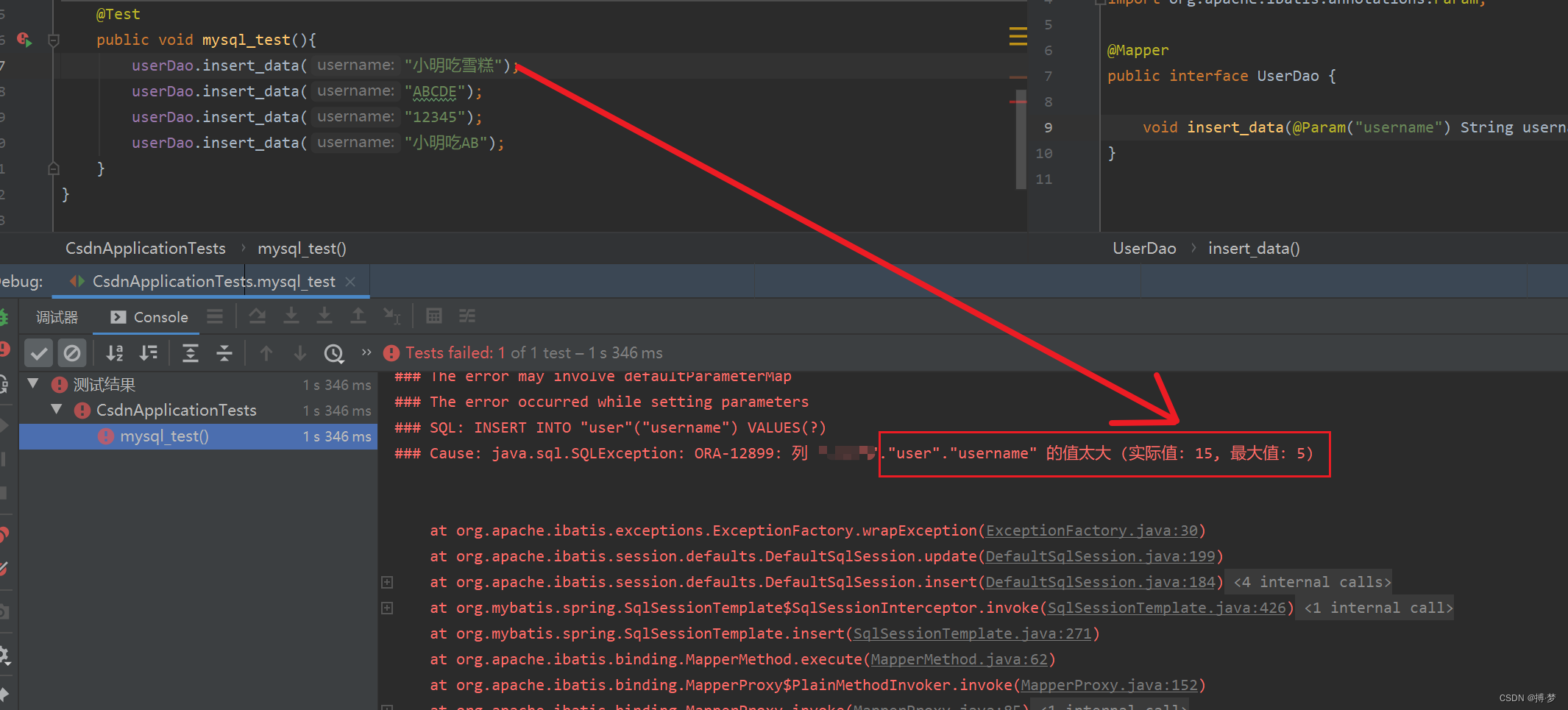
执行第二句,第三句的是可以插入的: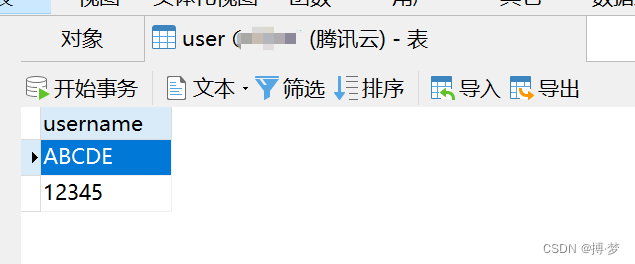
在执行最后一句:userDao.insert_data(“小明吃AB”);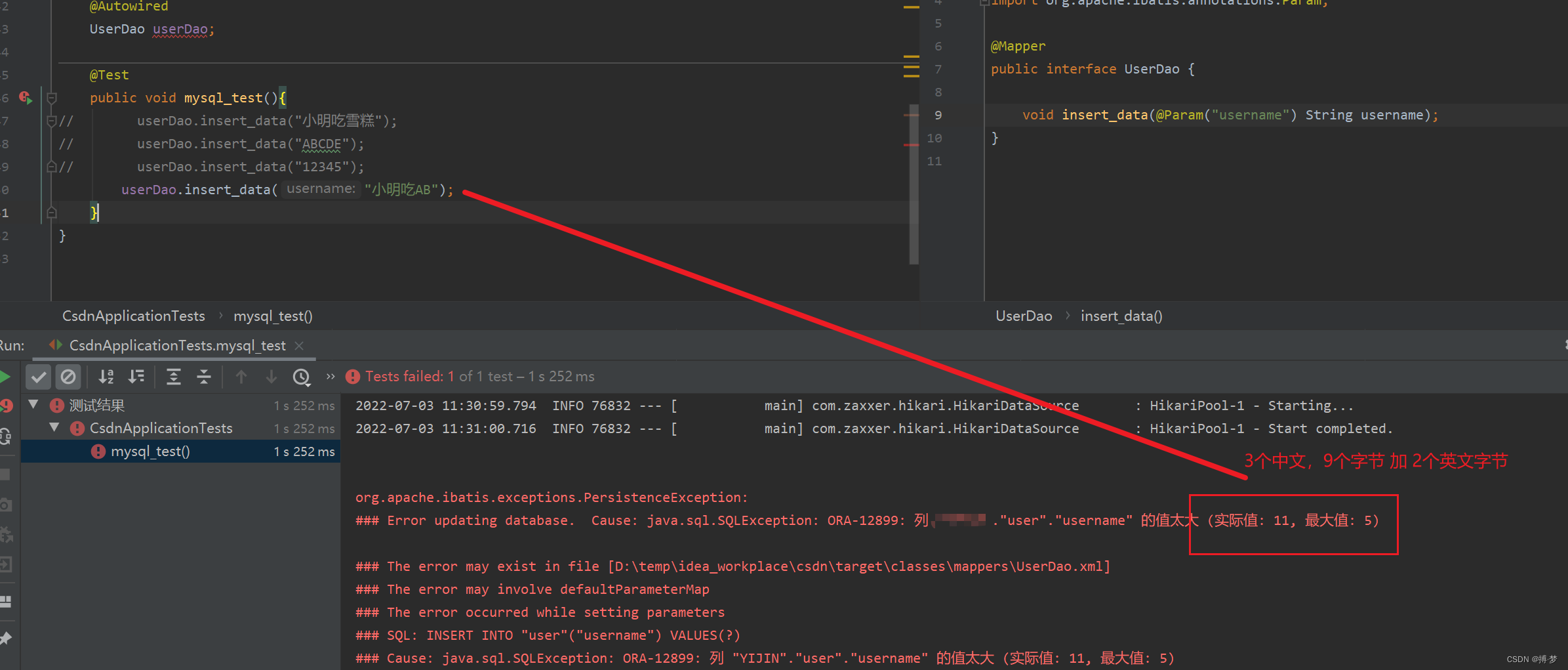
3. 将错误信息入库(mysql、oracle)
- 在mysql中只理到底可以存多少字符,只需要判断截取会不会截取到乱码即可。
- 在oracle中由于是理到底可以存储多少个字节,要先将字符转按编码转换,然后再判断截取会不会截取到乱码。
- 有的人不理解为什么要提及这个区别:
本来str = ”小明的表情" 是长度为5,但是转utf8 则是 15了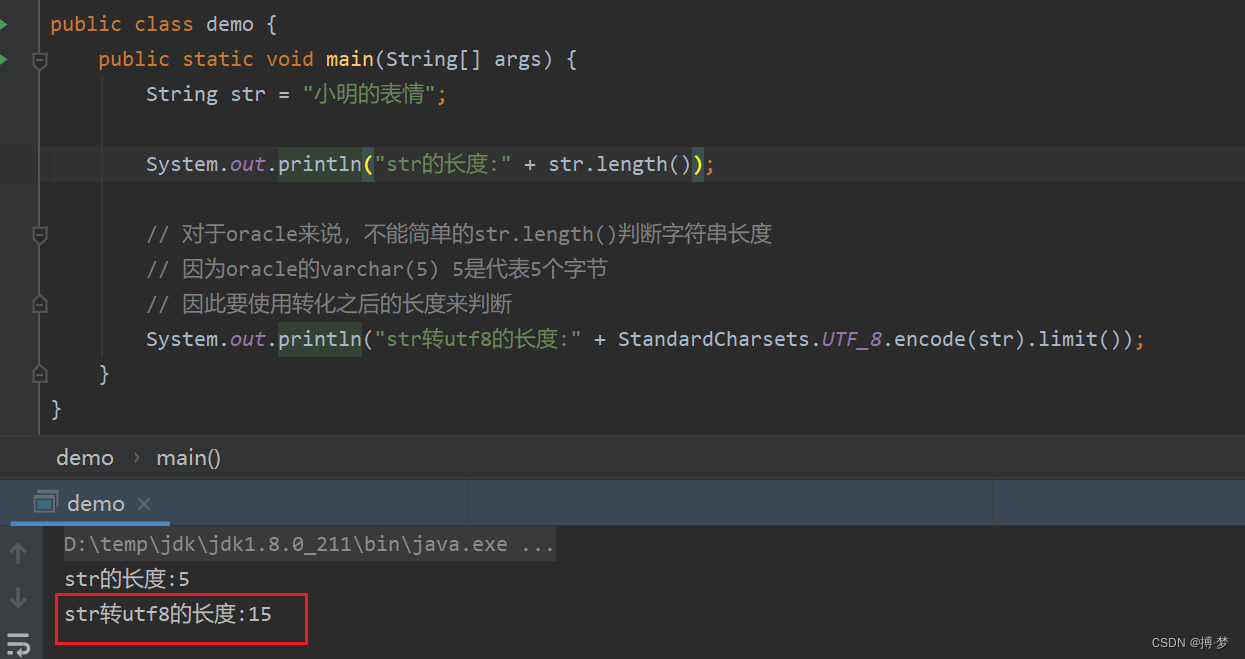
4. 演示(将字符串插入数据库中)
mysql中,因为是varchar(5)代表可以存储5个字符:
@SpringBootTest class CsdnApplicationTests { @Autowired UserDao userDao; @Test public void mysql_test() { // 长度为5的str userDao.insert_data(handleString("表情:\uD83D\uDE06", 5)); // 长度为6的str userDao.insert_data(handleString("他表情:\uD83D\uDE06", 5)); // 长度很长很长的str userDao.insert_data(handleString("小明吃雪糕之后,他的表情是:\uD83D\uDE06", 5)); } private static String handleString(String str, int length) { if (str.length() > length) { // 找到最后一位字符 char c = str.charAt(length - 1); // 判断是否为高代理项 if (Character.isHighSurrogate(c)) { // 若为高代理项,说明目前截取两个char的字符一半,有乱码 // 因此 多截一个 str = str.substring(0, length - 1); } else { // 到这里就是正常的char或者低代理项 // 低代理项 则说明前面已经包括了高代理项 // 因此不会有乱码,不用特殊处理 str = str.substring(0, length); } } return str; } }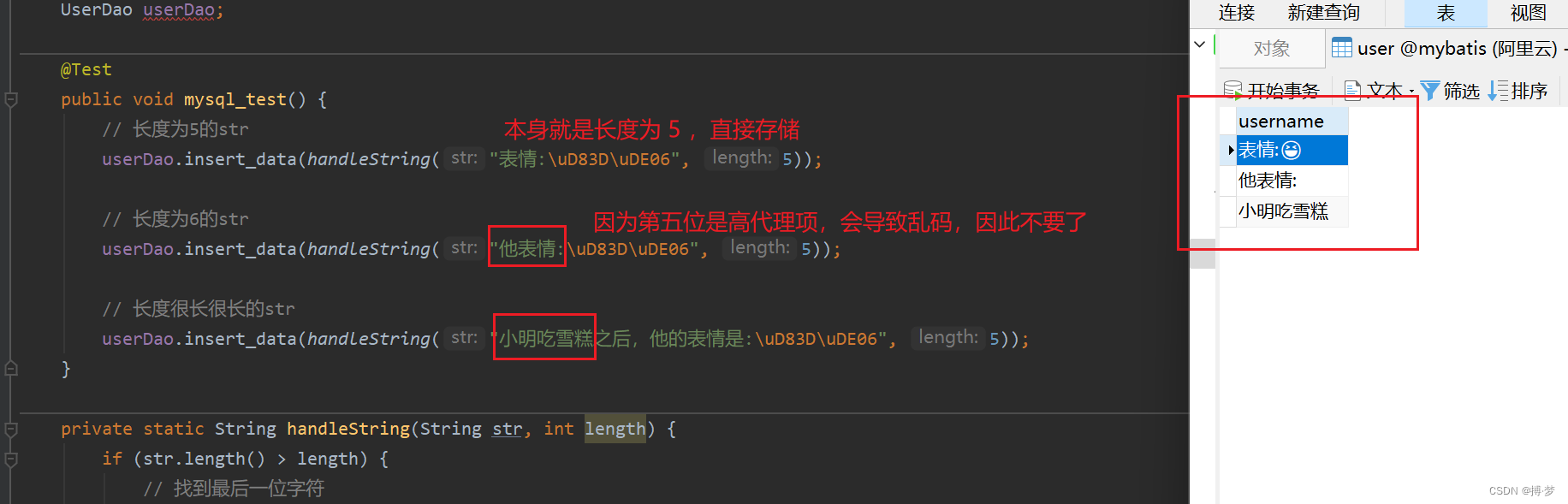
oracle中,因为是varchar(5)只能存储一个中文:
@SpringBootTest class CsdnApplicationTests { @Autowired UserDao userDao; @Test public void oracle_test() { // 长度为 5的str userDao.insert_data(handleString("表情:\uD83D\uDE06",5)); // 长度为 6的str userDao.insert_data(handleString("他表情:\uD83D\uDE06",5)); // 长度很长很长的str userDao.insert_data(handleString("小明吃雪糕之后,他的表情是:\uD83D\uDE06",5)); } private static String handleString(String str, int length) { // 若本身str就比length长很多,优先截取一次,优化下面转utf8的效率 if (str.length() > length) { // 找到最后一位字符 char c = str.charAt(length - 1); // 判断是否为高代理项 if (Character.isHighSurrogate(c)) { // 若为高代理项,说明目前截取两个char的字符一半,有乱码 // 因此 多截一个 str = str.substring(0, length - 1); } else { // 到这里就是正常的char或者低代理项 // 低代理项 则说明前面已经包括了高代理项 // 因此不会有乱码,不用特殊处理 str = str.substring(0, length); } } // 针对oracle的字节,优先转字符编码格式 // 若转义之后 仍然是大于指定的length,则还需要继续截取,再截掉最后一位 while (StandardCharsets.UTF_8.encode(str).limit() > length) { // 从上面已经截取过的str找到最后一位 char c = str.charAt(str.length() - 1); // 判断是否是低代理项, if (Character.isLowerCase(c)) { // 因为转utf8的时候发现还是长了,需要再截掉一位 // 而这一位如果是低代理项,则必须把前面的高代理项也去掉,不然会乱码 // 因此多截取了一位 str = str.substring(0, str.length() - 2); } else { // 如果是正常的或者是高代理项,则截掉一位就好了 str = str.substring(0, str.length() - 1); } } return str; } }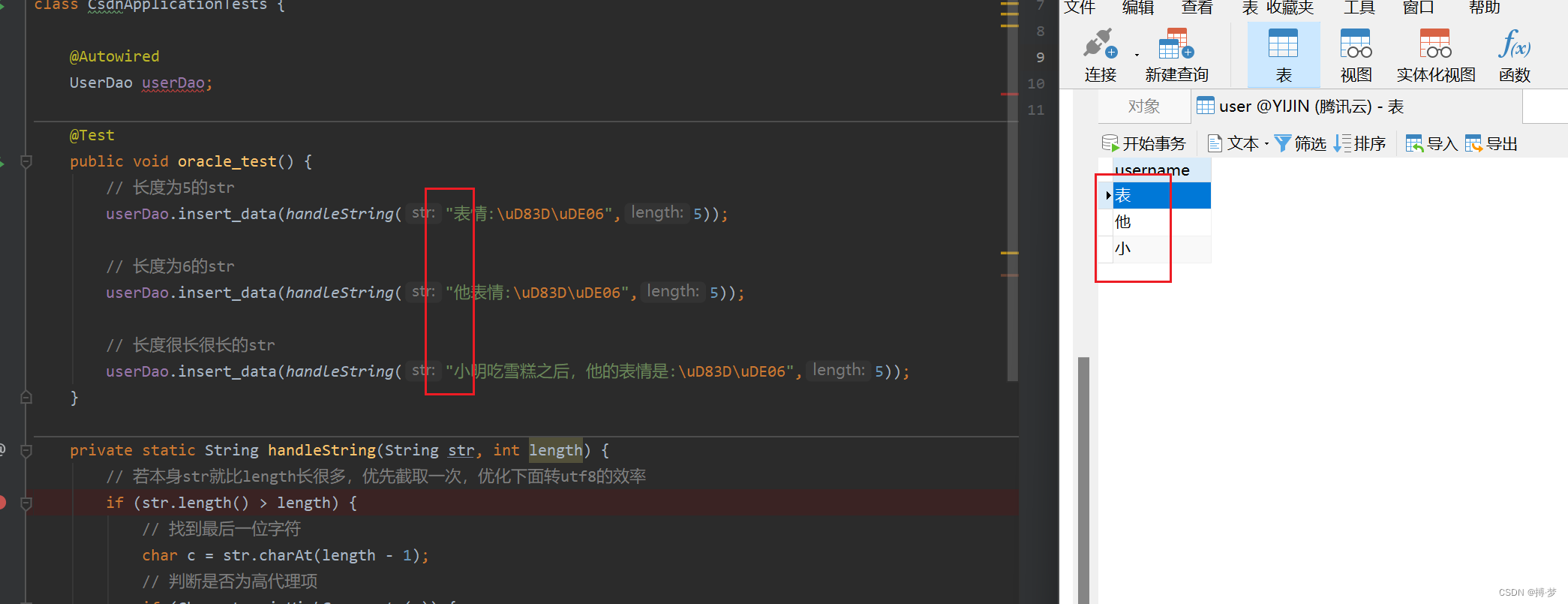
完美插入,并没有报错。
3. 总结
- 对于特殊的字符串,不能想当然的使用str.subString(0, length),因为还需要考虑两个char组成的字符,会不会截取到中间,导致乱码的问题。
- 理解什么是高位代理项、低位代理项。
- 对于数据库mysql、oracle的varchar的区别,在截取字符串的时候,oracle还需要加上转编码格式之后的比较长度大小。
边栏推荐
- R language ggplot2 visualization: place the title of the visualization image in the upper left corner of the image (customize Title position in top left of ggplot2 graph)
- Computer graduation design PHP Zhiduo online learning platform
- opencv+dlib实现给蒙娜丽莎“配”眼镜
- C language double pointer -- classic question type
- C语言双指针——经典题型
- Generator parameters incoming parameters
- 深度剖析C语言数据在内存中的存储
- poi追加写EXCEL文件
- @JsonBackReference和@JsonManagedReference(解决对象中存在双向引用导致的无限递归)
- 电脑清理,删除的系统文件
猜你喜欢

深度剖析C语言指针
C语言深度解剖——C语言关键字
![[embedded] print log using JLINK RTT](/img/22/c37f6e0f3fb76bab48a9a5a3bb3fe5.png)
[embedded] print log using JLINK RTT

Fairguard game reinforcement: under the upsurge of game going to sea, game security is facing new challenges
C语言双指针——经典题型

被破解毁掉的国产游戏之光
![[MySQL] multi table query](/img/eb/9d54df9a5c6aef44e35c7a63b286a6.jpg)
[MySQL] multi table query
Delay initialization and sealing classes
Deep anatomy of C language -- C language keywords
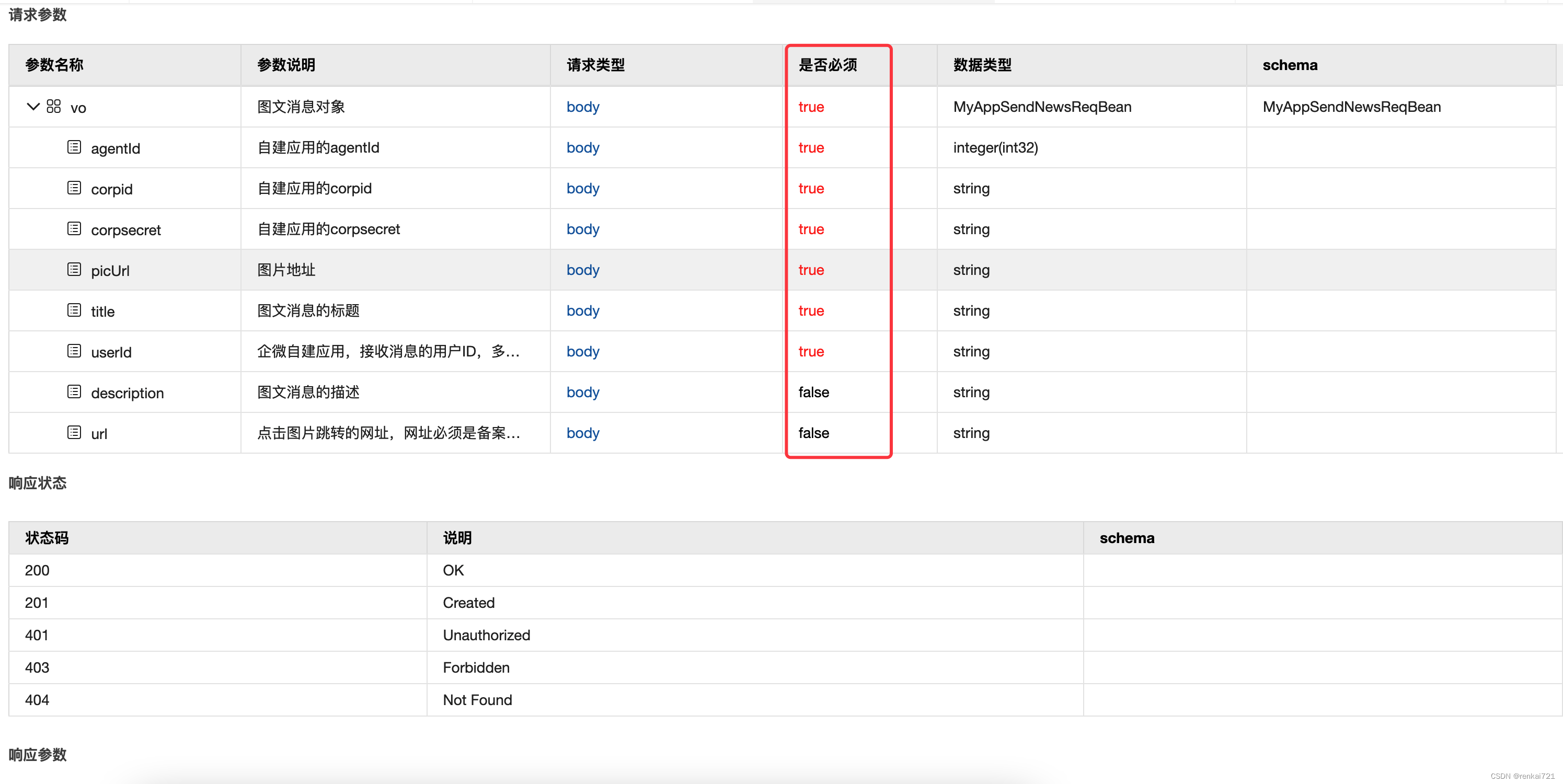
Swagger setting field required is mandatory
随机推荐
Promise 在uniapp的简单使用
【嵌入式】使用JLINK RTT打印log
R language uses the principal function of psych package to perform principal component analysis on the specified data set. PCA performs data dimensionality reduction (input as correlation matrix), cus
Fairguard game reinforcement: under the upsurge of game going to sea, game security is facing new challenges
LeetCode:26. 删除有序数组中的重复项
如何有效地进行自动化测试?
Delay initialization and sealing classes
vb.net 随窗口改变,缩放控件大小以及保持相对位置
Double pointeur en langage C - - modèle classique
Deep anatomy of C language -- C language keywords
Visual implementation and inspection of visdom
@JsonBackReference和@JsonManagedReference(解决对象中存在双向引用导致的无限递归)
visdom可视化实现与检查介绍
torch建立的网络模型使用torchviz显示
自动化测试框架有什么作用?上海专业第三方软件测试公司安利
Swagger setting field required is mandatory
Roguelike game into crack the hardest hit areas, how to break the bureau?
LeetCode:498. 对角线遍历
深度剖析C语言数据在内存中的存储
LeetCode:836. 矩形重叠