当前位置:网站首页>CUDA implementation of self defined convolution attention operator
CUDA implementation of self defined convolution attention operator
2022-07-06 08:56:00 【cyz0202】
reference :fairseq
background
A convolutional alternative to the attention mechanism
In the above article, we talked about designing appropriate convolution to replace the attention mechanism
The convolution of the final design is as follows

among  , And there are
, And there are  ;c representative d This dimension ;
;c representative d This dimension ;
To achieve such convolution , One way to compromise is , Make

 Please refer to the above article for the specific design of , No more details here ;
Please refer to the above article for the specific design of , No more details here ;
In order to realize such convolution more efficiently , Consider the implementation of the user-defined convolution operator CUDA Realization ;
programme
CUDA Implementing custom convolution generally requires several fixed steps , stay CUDA Realization focal_loss This article explains in detail ; Here's a picture , as follows
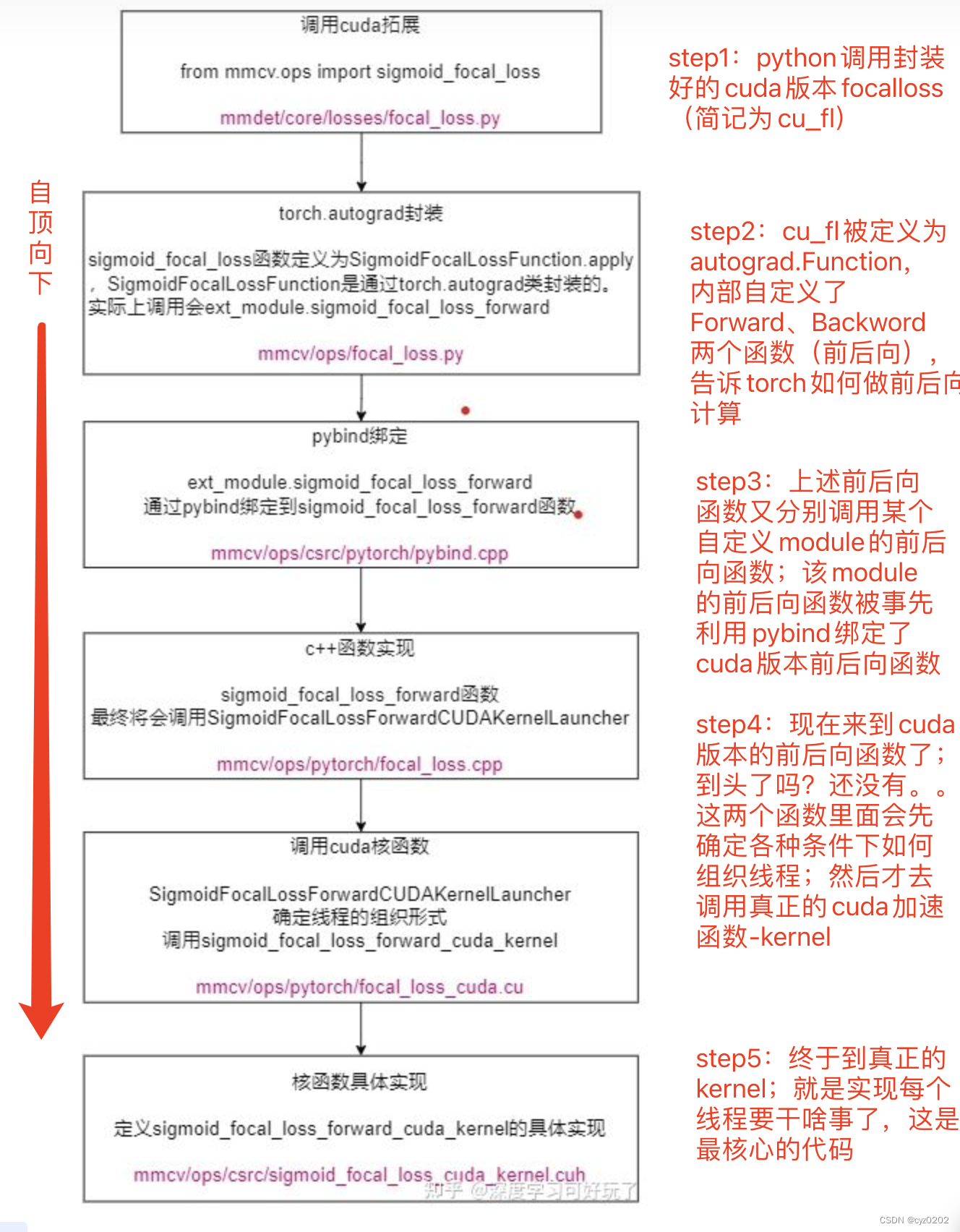
here CUDA The steps of implementing a custom convolution operator are similar to those above , The big difference step4/5, In especial step5 Of kernel Design ;
The following is a general introduction step5 Of kernel Implementation method , other step I won't repeat
kernel Realization
kernel The realization is divided into forward and backward Two steps ;
forward Realization
First look forward; The following code calls forward kernel Entry code for
std::vector <at::Tensor> conv_cuda_forward(at::Tensor input, at::Tensor filters, int padding_l) {
at::DeviceGuard g(input.device());
const auto minibatch = input.size(0); // batch size
const auto numFeatures = input.size(1); // dim(d)
const auto sequenceLength = input.size(2); // seq_len
const auto numHeads = filters.size(0); // H
const auto filterSize = filters.size(1); // K
const auto numFiltersInBlock = numFeatures / numHeads; // d/H
const dim3 blocks(minibatch, numFeatures); // block size (batch,dim)
auto output = at::zeros_like(input); // and input The same size (b, d, n)
auto stream = at::cuda::getCurrentCUDAStream();
if (sequenceLength <= 32) {
switch (filterSize) {
/* Be careful :
* In practice filtersize in [3, 7, 15, 31, 31, 31, 31]
* And padding_l = filtersize - 1
* */
case 3:
if (padding_l == 1) {
/*
* This macro is a macro with parameters , Replaced an anonymous function ; The function of anonymous function is to enumerate the type of the first parameter passed in ,
* If it is at::ScalarType::Double, Just use double Instead of scalar_t, If it is at::ScalarType::Float, Just use float Instead of ,
* If it is at::ScalarType::Half, Just use at::Half Instead of , Then finally return to __VA_ARGS__();
* __VA_ARGS__() Represents the third parameter of the macro , Usually another anonymous function ;
* That is, judge the enumeration type and scalar_t After the assignment ( That is, the above substitution ), Call parameters 3 Anonymous function of and returns the final result ;
* */
AT_DISPATCH_FLOATING_TYPES_AND_HALF(
input.scalar_type(), // Enumerate this data type , Assign value after replacement scalar_t
"conv_forward",
([&] {
conv_forward_kernel<3, 32, 1, scalar_t> // template assignment
<<<blocks, 32, 0, stream>>>( // (grid、block、share_mem、stream)
input.data<scalar_t>(),
filters.data<scalar_t>(),
minibatch,
sequenceLength, // SB>=sequenceLength
numFeatures,
numFiltersInBlock,
output.data<scalar_t>());
}
)
);
}
else if (padding_l == 2) {
AT_DISPATCH_FLOATING_TYPES_AND_HALF(input.scalar_type(), "conv_forward", ([&] {
conv_forward_kernel<3, 32, 2, scalar_t> // template assignment
<<<blocks, 32, 0, stream>>>( // (grid、block、share_mem、stream)
input.data<scalar_t>(), // b*d*n
filters.data<scalar_t>(), // H*k
minibatch, // b or batch_size
sequenceLength, // n; commonly SB>=sequenceLength
numFeatures, // d
numFiltersInBlock, // d/H
output.data<scalar_t>()); // b*d*n
}));
} else {
std::cout << "WARNING: Unsupported padding size - skipping forward pass" << std::endl;
}
break;
/*
* The following is the same as above case almost , No more shows
*/The core content of the above code segment is AT_DISPATHC_FLOATING_TYPES_AND_HALF And its internal call conv_forward_kernel;
AT_DISPATHC_FLOATING_TYPES_AND_HALF The function of is to execute input.scalar_type() => scalar_t;
conv_forward_kernel<3, 32, 2, scalar_t> Is the function template assignment , Represent the filter_size & seq_bound & padding_l & data_type
<<<blocks, 32, 0, stream>>> representative grid & block & share_memory & stream;
here blocks yes batch_size * hidden_size; namely grid from batch_size*hidden_size individual blcoks form ;
32 Then represent 1 individual block Number of internal routes ; combination blocks The definition of , You know every one of them block Deal with a certain layer of a certain sequence hidden data ;
0 It should not be used share memory( Undetermined ),stream Namely cuda stream;
So let's look at that conv_forward_kernel The definition of ; The code comments of the function are relatively clear , I won't go back to ;
template<int FS, int SB, int padding_l, typename scalar_t>
__global__
void conv_forward_kernel(const scalar_t *input,
const scalar_t *filters,
int minibatch, int sequenceLength,
int numFeatures, int numFiltersInBlock,
scalar_t *output) {
// according to grid=(batch,dim) The definition of , You know every one of them block Calculate the same feature
// Such as batchIdx=3,featureIdx=3, be tid Traverse No 3 Samples at various positions of the whole sequence featureIdx=3
// accord with conv Operator settings : The same for the whole sequence every time channel The calculation of
const int tid = threadIdx.x; // Here it is seq All positions on the are the same featureIdx In parallel
const int batchIdx = blockIdx.x; // batch
const int featureIdx = blockIdx.y; // dim, or channel
const int filterIdx = featureIdx / numFiltersInBlock; // cH/d W Which line of parameters should be used
// because cuda The storage of is in the form of pointers , So you need to calculate the offset (b*d*n)
const int IOOffset = numFeatures * sequenceLength * batchIdx +
featureIdx * sequenceLength; // Disposal location
const scalar_t *inputFeature = &input[IOOffset]; // Expanded by line input It's a one-dimensional array
scalar_t *outputFeature = &output[IOOffset];
const scalar_t *inputFilter = &filters[filterIdx * FS]; // H*k One of the lines ; Be careful filter yes n*n
// block Only one dimension , It is commonly SB, Such as 32,64
assert(blockDim.x == SB); // block_x size , To be equal to seq_len
scalar_t filter[FS]; // Storage filter Parameters
#pragma unroll // Loop unrolling
for (int i = 0; i < FS; ++i) {
filter[i] = inputFilter[i]; // Currently used convolution line
}
/* Array : Sequence length +filter size
* Note that the internal shared memory of the thread block ; all tid Only one copy.
* */
__shared__ scalar_t temp[SB + FS];
/*
* Here to deal with tid Places that cannot be indexed ; Or each one tid It is only used to map each input position to temp Corresponding position ;
* temp Other positions should be handled in advance ; That is to say, first Sliding window needs repair 0 operation
* notes : according to padding_l Different settings for ,temp Different filling methods
* The default is padding_l=fs-1, such as fs=5,padding_l=4, That is, the left side is filled 4 individual 0;
* temp Fill the last position 1 individual 0
*/
zeroSharedMem<FS, SB, padding_l>(temp);
/* commonly SB>sequenceLength, therefore numIterations=1
* A special case if sequenceLength>512 numIterations=2
*/
const int numIterations = divUp<int, int>(sequenceLength, SB);
/*
* commonly numIterations=1
* A special case , Such as sequenceLength>512(e.g 1024),SB=512
*/
for (int i = 0; i < numIterations; ++i) { // Too long sequences need to be processed in blocks , because block=SB
const int inputOffset = i * SB;
/* The input to be calculated moves to share memory; Besides, according to seq_len Make more settings 0
* say concretely , It's from fs-1 Start filling the real input sequence ; When the actual sequence length is exceeded , fill 0
* Fill the results into temp Inside (temp The size is SB+FS)
* fs=5 when , Final temp It looks something like this :[0,0,0,0,10,20,30,40,50,60,70,80,0,0,0,0,0,0,0,...]
* output[tid + padding_l] =
* ((inputOffset + tid) < sequenceLength) ? input[inputOffset + tid] : scalar_t(0.0);
* */
load_input_to_shared<FS, SB, padding_l>(inputFeature, inputOffset,
sequenceLength,i, numIterations,
(numIterations == 1),
temp);
/* Sync , Waiting for the present block all tid completion of enforcement
* Every tid Responsible for a position , So wait for all tid hold temp Well populated
* */
__syncthreads();
scalar_t out = 0; // Every tid One out
#pragma unroll // Loop unrolling
for (int j = 0; j < FS; ++j) {
/* Sync above tid Well populated temp after , You can calculate each tid Convolution of corresponding positions
* From here we can see ,temp It is used to fill the satisfaction filter.dot(input) Of calculation
* tid=0 when , The following calculation expansion is :
* out0 = filter[0]*temp[0]+...+filter[fs-1]*temp[fs-1]
* be aware temp[fs-1] Is the first value entered , Not 0; and temp left fs-1 The number goes on 0 Filled
* tid=1 when , The following calculation expansion is :
* out1 = filter[0]*temp[1]+...+filter[fs-1]*temp[1+fs-1]
* here temp[fs-1]、temp[1+fs-1] Valuable , Not 0;
* other tid What you do is equivalent to sliding filter Weighted sum of windows ;
*/
out += filter[j] * temp[tid + j];
}
// Write output
const int outputOffset = inputOffset;
if ((outputOffset + tid) < sequenceLength) {
/*
* Be careful output and input shape equally ,outputFeature Depends on the present block stay grid The position shift of
*
*/
outputFeature[outputOffset + tid] = out;
}
// Sync
__syncthreads();
}
}backwrad Realization
Here are backward kernel The portal implementation
std::vector<at::Tensor> conv_cuda_backward(
at::Tensor gradOutput,
int padding_l,
at::Tensor input,
at::Tensor filters) {
// gradWrtInput
const int minibatch = input.size(0); // batch(b)
const int numFeatures = input.size(1); // d
const int sequenceLength = input.size(2); // seq_len
const int numHeads = filters.size(0); // H
const int filterSize = filters.size(1); // k
const dim3 gradBlocks(minibatch, numFeatures); // (b, d)
const dim3 weightGradFirstpassShortBlocks(minibatch, numHeads); //(b,H)
const dim3 weightGradSecondpassBlocks(numHeads, filterSize); // (H,k)
const int numFiltersInBlock = numFeatures / numHeads; // d/H
auto gradInput = at::zeros_like(input);
auto gradFilters = at::zeros_like(filters);
at::DeviceGuard g(input.device());
auto stream = at::cuda::getCurrentCUDAStream();
switch (filterSize) {
case 3:
// Sequence length <= 32 The situation of
if (sequenceLength <= 32) {
if (padding_l == 1) {
/*
* The implementation here is similar to the following padding_l==2( Actual use part ), Consider that space is no longer displayed
*/
} else if (padding_l == 2) {
AT_DISPATCH_FLOATING_TYPES_AND_HALF(input.scalar_type(), "conv_backward", ([&] {
// Calculate the input gradient
conv_grad_wrt_input_kernel<3, 32, 2, scalar_t>
<<<gradBlocks, 32, 0, stream>>>(
gradOutput.data<scalar_t>(),
filters.data<scalar_t>(),
minibatch,
sequenceLength,
numFeatures,
numFiltersInBlock,
gradInput.data<scalar_t>()
);
at::Tensor tempSumGradFilters = at::zeros({minibatch, numHeads, filterSize},
input.options().dtype(at::kFloat));
// Calculate the weight gradient The first round
conv_grad_wrt_weights_firstpass_short_kernel<3, 32, 2, scalar_t>
<<<weightGradFirstpassShortBlocks, 32, 0, stream>>>(
input.data<scalar_t>(),
gradOutput.data<scalar_t>(),
minibatch,
sequenceLength,
numFeatures,
numFiltersInBlock,
numHeads,
tempSumGradFilters.data<float>()
);
// Calculate the weight gradient The second round
conv_grad_wrt_weights_secondpass_short_kernel<3, 32, scalar_t>
<<<weightGradSecondpassBlocks, 32, 0, stream>>>(
tempSumGradFilters.data<float>(),
minibatch,
numFiltersInBlock,
gradFilters.data<scalar_t>()
);
}));
} else {
std::cout << "WARNING: Unsupported padding size - skipping backward pass" << std::endl;
}
// Sequence length > 32 The situation of
} else if (padding_l == 1) {
/* Similar to the code below , Generally not used , So don't show */
} else if (padding_l == 2) {
AT_DISPATCH_FLOATING_TYPES_AND_HALF(input.scalar_type(), "conv_backward", ([&] {
conv_grad_wrt_input_kernel<3, 32, 2, scalar_t>
<<<gradBlocks, 32, 0, stream>>>(
gradOutput.data<scalar_t>(),
filters.data<scalar_t>(),
minibatch,
sequenceLength,
numFeatures,
numFiltersInBlock,
gradInput.data<scalar_t>());
at::Tensor tempSumGradFilters = at::zeros({minibatch, numFeatures, filterSize},
input.options().dtype(at::kFloat));
conv_grad_wrt_weights_firstpass_kernel<3, 32, 2, scalar_t>
<<<gradBlocks, 32, 0, stream>>>(
input.data<scalar_t>(),
gradOutput.data<scalar_t>(),
minibatch,
sequenceLength,
numFeatures,
numFiltersInBlock,
tempSumGradFilters.data<float>()
);
conv_grad_wrt_weights_secondpass_kernel<3, 32, scalar_t>
<<<weightGradSecondpassBlocks, 32, 0, stream>>>(
tempSumGradFilters.data<float>(),
minibatch,
numFiltersInBlock,
gradFilters.data<scalar_t>()
);
}));
} else {
std::cout << "WARNING: Unsupported padding size - skipping backward pass" << std::endl;
}
break;
/*
* The following is similar to the above , Don't show
*/Here to filter_size = 3,seq_len <= 32,padding_l = 2 The setting of explains how to realize the reverse process ;
And at present, only The process of deriving the gradient of input ( Simpler ); Backward of weight ( A little complicated ) We will continue to explain later ;
Show me the entered reverse process entry code :
// Calculate the input gradient
conv_grad_wrt_input_kernel<3, 32, 2, scalar_t>
<<<gradBlocks, 32, 0, stream>>>(
gradOutput.data<scalar_t>(),
filters.data<scalar_t>(),
minibatch,
sequenceLength,
numFeatures,
numFiltersInBlock,
gradInput.data<scalar_t>()
);conv_grad_wrt_input_kernel<3, 32, 2, scalar_t> Is the input inverse function template assignment , Represent the filter_size & seq_bound & padding_l & data_type
<<<gradBlocks, 32, 0, stream>>> representative grid & block & share_memory & stream;
here gradBlocks( See the code ) yes batch_size * hidden_size; namely grid from batch_size*hidden_size individual blcoks form ;
32 Then represent 1 individual block Number of internal routes ; combination blocks The definition of , You know every one of them block Deal with a certain layer of a certain sequence hidden data ;
0 It should not be used share memory( Undetermined ),stream Namely cuda stream;
Above and forward The process is very similar , actually , The backward process entered here is really similar to the forward process ;
Because the input is in the forward process What to do It's simply and filter( A sliding window ) Multiply and accumulate ; So the backward process is also a simple multiplication and accumulation ; From the implementation code , It will look very similar ;
The mathematical expression of the forward and backward process is as follows ( With padding_l=fs-1 For example ), and
and  It's gradient
It's gradient


It can be found that the forward and backward processes are indeed very similar in form ; The implementation code is as follows
template<int FS, int SB, int padding_l, typename scalar_t>
__global__
void conv_grad_wrt_input_kernel(
const scalar_t *input, // gradOutput
const scalar_t *filters,
int minibatch,
int sequenceLength,
int numFeatures,
int numFiltersInBlock,
scalar_t *output) {
// The derivation of input is very similar to the forward process
const int tid = threadIdx.x;
const int batchIdx = blockIdx.x;
const int featureIdx = blockIdx.y;
const int filterIdx = featureIdx / numFiltersInBlock;
const int IOOffset = numFeatures * sequenceLength * batchIdx + featureIdx * sequenceLength;
const scalar_t *inputFeature = &input[IOOffset];
scalar_t *outputFeature = &output[IOOffset];
const scalar_t *inputFilter = &filters[filterIdx * FS];
assert(blockDim.x == SB);
scalar_t filter[FS];
/* The only difference is reverse loading filter(filter Flip ): Here we can derive the formula from the gradient
* Imagine a sliding window moving to the right , Different weights of the window will pass through the input of the same position , Multiply and accumulate to get the output at different positions
*/
#pragma unroll
for (int i = 0; i < FS; ++i) {
filter[i] = inputFilter[FS - i - 1]; // inputFilter[i]
}
__shared__ scalar_t temp[SB + FS];
// FS-(paddling_l+1) As a filling ,paddling=FS-1 when padding=0
const int padding = FS - padding_l - 1;
zeroSharedMem<FS, SB, padding>(temp);
__syncthreads();
const int numIterations = divUp<int, int>(sequenceLength, SB);
for (int i = 0; i < numIterations; ++i) {
// Read input into shared memory
const int inputOffset = i * SB;
load_input_to_shared<FS, SB, padding>(inputFeature, inputOffset, sequenceLength,
i, numIterations, false, temp);
__syncthreads();
scalar_t out = 0;
#pragma unroll
for (int j = 0; j < FS; ++j) {
out += filter[j] * temp[tid + j];
}
// Write output
const int outputOffset = inputOffset;
if ((outputOffset + tid) < sequenceLength) { // Limit tid
outputFeature[outputOffset + tid] = out;
}
__syncthreads();
}
}TODO: The reverse process of weight is slightly complicated , Let's not talk about ;
summary
- The above introduces the design of user-defined convolution operator CUDA Realization ;
- The realization of forward process and partial backward process are introduced , For reference only ;
- Overall CUDA There is a certain routine for implementing custom operators ; The key point is kernel The design of the , That is, how in the forward and backward process , Make full use of it grid、block Perform parallel computing to achieve maximum acceleration ; That's important
- Level co., LTD. , Welcome to correct
边栏推荐
- LeetCode:124. Maximum path sum in binary tree
- Intel Distiller工具包-量化实现1
- Tcp/ip protocol
- LeetCode:26. Remove duplicates from an ordered array
- 【ROS】usb_ Cam camera calibration
- R language ggplot2 visualization, custom ggplot2 visualization image legend background color of legend
- Using C language to complete a simple calculator (function pointer array and callback function)
- LeetCode:剑指 Offer 42. 连续子数组的最大和
- 可变长参数
- Leetcode: Sword finger offer 48 The longest substring without repeated characters
猜你喜欢
目标检测——Pytorch 利用mobilenet系列(v1,v2,v3)搭建yolov4目标检测平台
Promise 在uniapp的简单使用
Detailed explanation of heap sorting
Current situation and trend of character animation

BMINF的后训练量化实现
可变长参数
【ROS】usb_ Cam camera calibration
MYSQL卸载方法与安装方法
ROS compilation calls the third-party dynamic library (xxx.so)
Sublime text using ctrl+b to run another program without closing other runs
随机推荐
Navicat premium create MySQL create stored procedure
LeetCode:162. Looking for peak
Leetcode: Sword finger offer 48 The longest substring without repeated characters
Export IEEE document format using latex
Mongodb installation and basic operation
Chapter 1 :Application of Artificial intelligence in Drug Design:Opportunity and Challenges
What is the role of automated testing frameworks? Shanghai professional third-party software testing company Amway
[MySQL] limit implements paging
Simple use of promise in uniapp
PC easy to use essential software (used)
Tdengine biweekly selection of community issues | phase III
TP-LINK enterprise router PPTP configuration
LeetCode:34. Find the first and last positions of elements in a sorted array
【嵌入式】使用JLINK RTT打印log
Excellent software testers have these abilities
Leetcode: Sword Finger offer 42. Somme maximale des sous - tableaux consécutifs
Problems in loading and saving pytorch trained models
The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
Light of domestic games destroyed by cracking
CUDA实现focal_loss