当前位置:网站首页>Intel Distiller工具包-量化实现3
Intel Distiller工具包-量化实现3
2022-07-06 08:51:00 【cyz0202】
本系列文章
回顾
- 上面文章中介绍了Distiller及Quantizer基类,后训练量化器;基类定义了重要的变量,如replacement_factory(dict,用于记录待量化module对应的wrapper);此外定义了量化流程,包括 预处理(BN折叠,激活优化等)、量化模块替换、后处理 等主要步骤;后训练量化器则在基类的基础上实现了后训练量化的功能;
- 本文继续介绍继承自Quantizer的子类量化器,包括
- PostTrainLinearQuantizer(前文)
- QuantAwareTrainRangeLinearQuantizer(本文)
- PACTQuantizer(后续)
- NCFQuantAwareTrainQuantizer(后续)
- 本文代码也挺多的,由于没法全部贴出来,有些地方说的不清楚的,还请读者去参考源码;
QuantAwareTrainRangeLinearQuantizer
- 量化感知训练量化器;将量化过程插入模型代码中,对模型进行训练;该过程使得模型参数对对量化过程有所拟合,所以最终得到的模型的效果 一般要比 后训练量化模型要好一些;
- QuantAwareTrainRangeLinearQuantizer的类定义如下:可以看到比后训练量化器的定义简单不少;

- 构造函数:前面都是检查和默认设置;核心是红框中 对 参数、激活值 设置的 量化感知 方式;
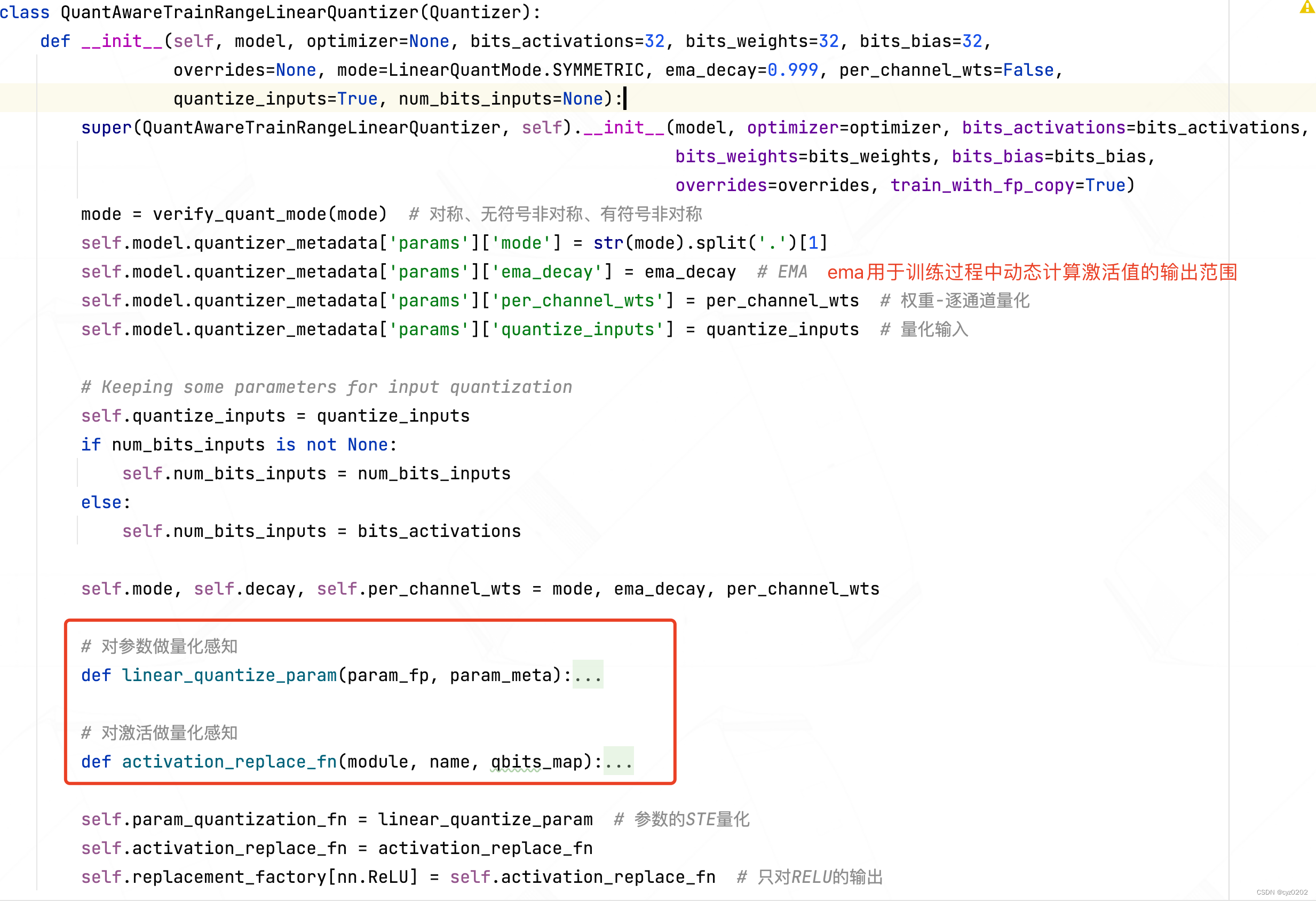
- activation_replace_fn:这是对激活值做量化感知的实现方式,和前文后训练量化使用的 模块替换方式 一样,即返回一个 wrapper,这里是 FakeQuantizationWrapper
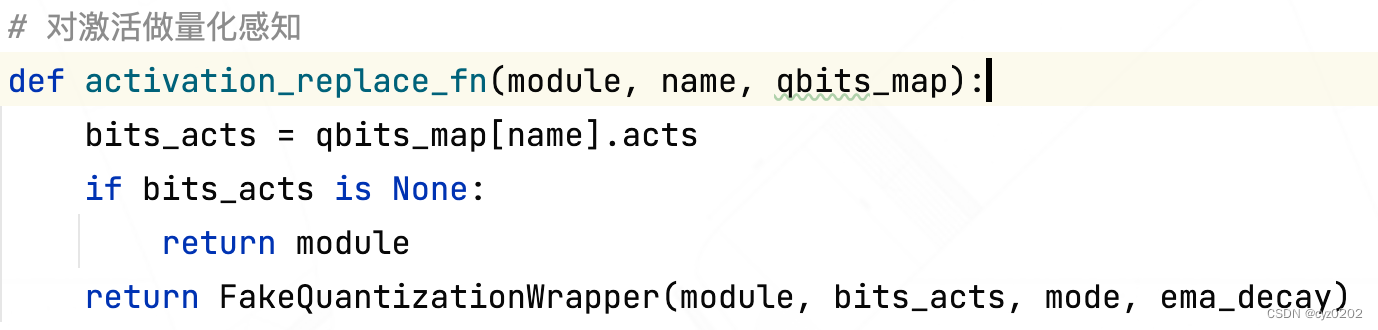
- FakeQuantizationWrapper:定义如下,forward中输入先经过原module计算(得到的是原来的激活输出),然后对输出(下一个module的输入)做伪量化(fake_q);
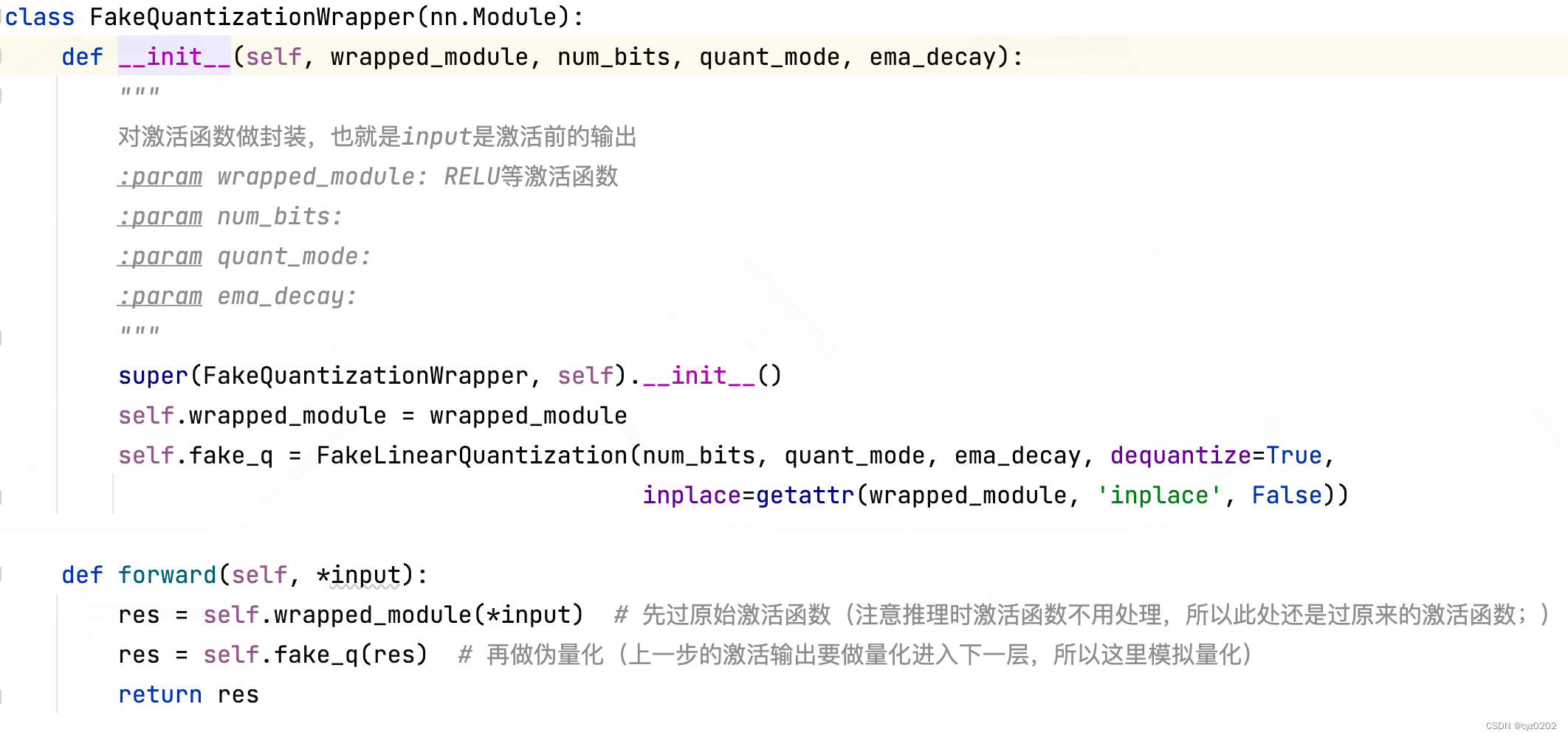
- FakeLinearQuantization:定义如下,该module做的事是 对输入做伪量化;具体细节包括 训练过程确定 激活值的范围并更新scale、zp(infer则直接使用训练过程最后的scale、zp);使用 LinearQuantizeSTE(straight-through-estimator) 实现伪量化;
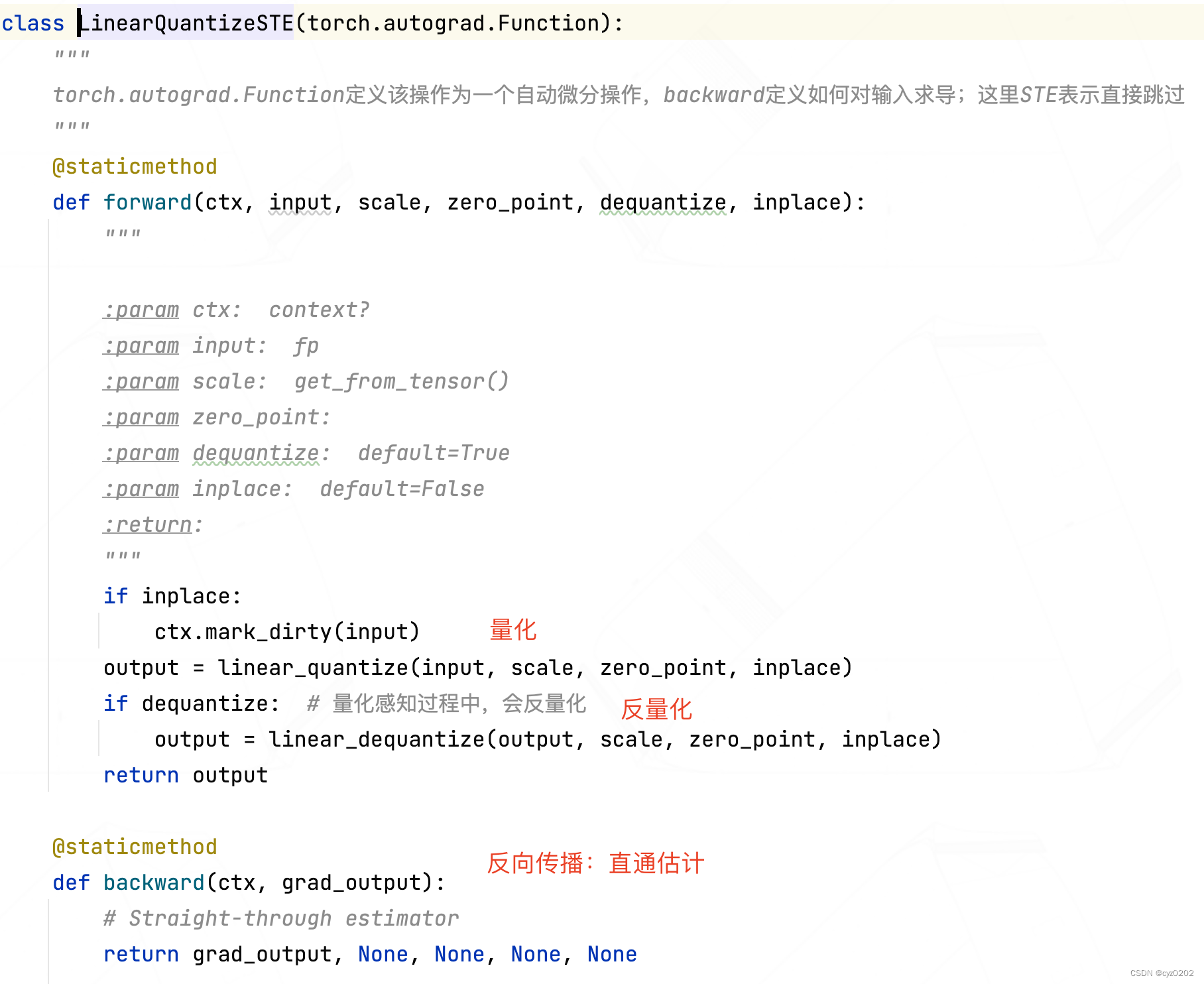
class FakeLinearQuantization(nn.Module): def __init__(self, num_bits=8, mode=LinearQuantMode.SYMMETRIC, ema_decay=0.999, dequantize=True, inplace=False): """ :param num_bits: :param mode: :param ema_decay: 激活值范围使用EMA进行跟踪 :param dequantize: :param inplace: """ super(FakeLinearQuantization, self).__init__() self.num_bits = num_bits self.mode = mode self.dequantize = dequantize self.inplace = inplace # We track activations ranges with exponential moving average, as proposed by Jacob et al., 2017 # https://arxiv.org/abs/1712.05877(激活值范围使用EMA进行跟踪) # We perform bias correction on the EMA, so we keep both unbiased and biased values and the iterations count # For a simple discussion of this see here: # https://www.coursera.org/lecture/deep-neural-network/bias-correction-in-exponentially-weighted-averages-XjuhD self.register_buffer('ema_decay', torch.tensor(ema_decay)) # 设置buffer,buffer用于非参的存储,会存于model state_dict self.register_buffer('tracked_min_biased', torch.zeros(1)) self.register_buffer('tracked_min', torch.zeros(1)) # 保存无偏值 self.register_buffer('tracked_max_biased', torch.zeros(1)) # 保存有偏值 self.register_buffer('tracked_max', torch.zeros(1)) self.register_buffer('iter_count', torch.zeros(1)) # 保存迭代次数 self.register_buffer('scale', torch.ones(1)) self.register_buffer('zero_point', torch.zeros(1)) def forward(self, input): # We update the tracked stats only in training # # Due to the way DataParallel works, we perform all updates in-place so the "main" device retains # its updates. (see https://pytorch.org/docs/stable/nn.html#dataparallel) # However, as it is now, the in-place update of iter_count causes an error when doing # back-prop with multiple GPUs, claiming a variable required for gradient calculation has been modified # in-place. Not clear why, since it's not used in any calculations that keep a gradient. # It works fine with a single GPU. TODO: Debug... if self.training: # 训练阶段要收集收据 with torch.no_grad(): current_min, current_max = get_tensor_min_max(input) # input是激活函数输出值 self.iter_count += 1 # 有偏值为正常加权值,无偏值为 有偏值/(1-decay**step) self.tracked_min_biased.data, self.tracked_min.data = update_ema(self.tracked_min_biased.data, current_min, self.ema_decay, self.iter_count) self.tracked_max_biased.data, self.tracked_max.data = update_ema(self.tracked_max_biased.data, current_max, self.ema_decay, self.iter_count) if self.mode == LinearQuantMode.SYMMETRIC: max_abs = max(abs(self.tracked_min), abs(self.tracked_max)) actual_min, actual_max = -max_abs, max_abs if self.training: # 激活值的范围数值经EMA更新后需要重新计算scale和zp self.scale.data, self.zero_point.data = symmetric_linear_quantization_params(self.num_bits, max_abs) else: actual_min, actual_max = self.tracked_min, self.tracked_max signed = self.mode == LinearQuantMode.ASYMMETRIC_SIGNED if self.training: # 激活值的范围数值经EMA更新后需要重新计算scale和zp self.scale.data, self.zero_point.data = asymmetric_linear_quantization_params(self.num_bits, self.tracked_min, self.tracked_max, signed=signed) input = clamp(input, actual_min.item(), actual_max.item(), False) # 执行量化、反量化操作,并且该过程无需额外梯度 input = LinearQuantizeSTE.apply(input, self.scale, self.zero_point, self.dequantize, False) return input - LinearQuantizeSTE:这是实现伪量化的核心,定义如下;它被定义为 torch.autograd.Function,指定了如何反向传播(STE方式)
- 接下来看一下对参数的量化感知实现(linear_quantize_param),直接使用LinearQuantizeSTE

- 注:distiller的量化感知训练量化器中虽然定义了如何 对参数做量化感知训练,但是并没有使用,有点奇怪;
总结
- 本文介绍了distiller量化器基类Quantizer的一个子类:PostTrainLinearQuantizer;
- 核心部分是 激活值、参数值的 量化感知训练的实现;对激活值量化感知的实现还是采用wrapper的方式,对参数则是直接使用STE;具体细节包括了 FakeQuantizationWrapper、FakeLinearQuantization、LinearQuantizeSTE;
边栏推荐
- UML图记忆技巧
- [today in history] February 13: the father of transistors was born The 20th anniversary of net; Agile software development manifesto was born
- Target detection - pytorch uses mobilenet series (V1, V2, V3) to build yolov4 target detection platform
- Revit 二次开发 HOF 方式调用transaction
- Sublime text in CONDA environment plt Show cannot pop up the problem of displaying pictures
- Pytorch view tensor memory size
- To effectively improve the quality of software products, find a third-party software evaluation organization
- CSP first week of question brushing
- [OC]-<UI入门>--常用控件-提示对话框 And 等待提示器(圈)
- Warning in install. packages : package ‘RGtk2’ is not available for this version of R
猜你喜欢
可变长参数
Simple use of promise in uniapp
Navicat Premium 创建MySql 创建存储过程

ESP8266-RTOS物联网开发
Warning in install. packages : package ‘RGtk2’ is not available for this version of R

深度剖析C语言数据在内存中的存储
PC easy to use essential software (used)
Screenshot in win10 system, win+prtsc save location
C語言雙指針——經典題型
Analysis of the source code of cocos2d-x for mobile game security (mobile game reverse and protection)
随机推荐
The harm of game unpacking and the importance of resource encryption
Visual implementation and inspection of visdom
可变长参数
The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
Cesium draw points, lines, and faces
C語言雙指針——經典題型
The network model established by torch is displayed by torch viz
Computer cleaning, deleted system files
Current situation and trend of character animation
Revit secondary development Hof method calls transaction
R language uses the principal function of psych package to perform principal component analysis on the specified data set. PCA performs data dimensionality reduction (input as correlation matrix), cus
Generator parameters incoming parameters
Detailed explanation of heap sorting
SAP ui5 date type sap ui. model. type. Analysis of the parsing format of date
POI add write excel file
Target detection - pytorch uses mobilenet series (V1, V2, V3) to build yolov4 target detection platform
Introduction to the differences between compiler options of GCC dynamic library FPIC and FPIC
LeetCode:26. 删除有序数组中的重复项
[MySQL] limit implements paging
After PCD is converted to ply, it cannot be opened in meshlab, prompting error details: ignored EOF