当前位置:网站首页>Persistence practice of redis (Linux version)
Persistence practice of redis (Linux version)
2022-07-06 09:13:00 【~Pompeii】
Catalog
- Redis Persistence practice (Linux edition )
- 1. Introduction to persistence
- 2.RDB Related configuration
- 3.RDB Manual start mode -save
- 4.RDB Manual start mode -save working principle
- 5.RDB Manual start mode -bgsave working principle
- 6.RDB Manual start mode -bgsave
- 7.RDB Automatic start mode - Modify the configuration
- 8.RDB Automatic start mode - Modify how the configuration works
- 9.RDB Comparison of three startup modes
- 10.RDB Special starting form
- 11.RDB Advantages and disadvantages
- 12.AOF Introduce
- 13.AOF How to write data
- 14.AOF Three strategies for writing data (appendfsync)
- 15.AOF Rewrite Preface
- 16.AOF Introduction to rewriting
- 17.AOF Rewriting effect
- 18.AOF Rewriting rule
- 19.AOF Manual override mode -bgrewriteaof
- 20.AOF Auto rewrite mode - Modify the configuration
- 21.AOF Manual override mode -bgrewriteaof working principle
- 22.AOF Rewrite process
- 23.RDB And AOF difference
- 24.RDB And AOF Choice problem
- 25. Persistent application scenarios
Redis Persistence practice (Linux edition )
1. Introduction to persistence
Using permanent storage media to save data , The working mechanism of restoring the saved data at a specific time is called persistence .
Prevent accidental loss of data , Ensure data security
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-04Lw0D1n-1656561836130)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220629115629373.png)]](/img/2b/2ab4ba19fe383b431fd31c2b21e6ac.png)
2.RDB Related configuration
The following and save What's relevant is 1234;
and bgsave What's relevant is 12345;
and RDB The manual start mode is related to 12346;( although RDB The manual starting mode is RDB, But with 5 irrelevant )
and AOF What's relevant is 2789;
and AOF Manual rewriting is related to 2789;
and AOF Manual automatic rewriting is related to 2789 10 11;
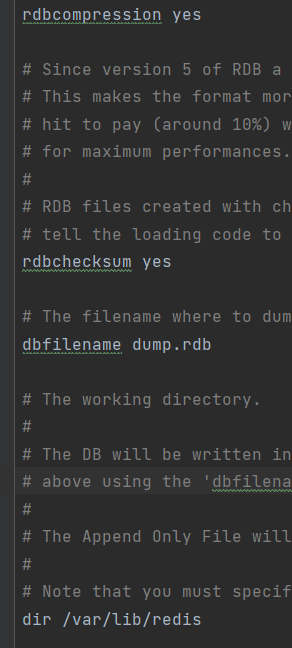
1.dbfilename dump.rdb:
explain : Set the local database file name , The default value is dump.rdb
Experience : Usually set to dump- Port number .rdb
2.dir:
explain :rdb Path to file
Experience : It is usually set to a directory with large storage space , Directory name data
3.rdbcompression yes:
explain : Set whether to compress data when storing to local database , The default is yes, use LZF Compress
Experience : It is usually on by default , If set to no, Can save CPU The elapsed time , But it makes the stored files bigger ( huge )
4.rdbchecksum yes:
explain : Set whether to RDB File format verification , The verification process is carried out in the process of writing and reading files
Experience : It is usually on by default , If set to no, It can save the reading and writing process about 10% Time consuming , However, there is a certain risk of data corruption
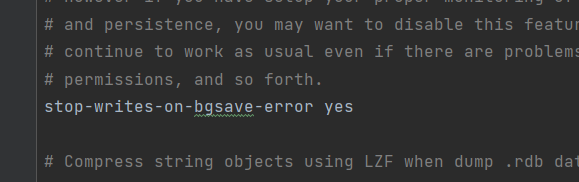
5.stop-writes-on-bgsave-error yes:
explain : If there is an error in the background stored procedure , Whether to stop the save operation
Experience : Usually, it defaults to open
6.save second changes:
effect : Meet the time limit key When the number of changes reaches the specified number, persistence is carried out
Parameters :
second: Monitor the time frame
changes: monitor key Amount of change
7.appendonly no:
appendonly yes|no
Open or not AOF Persistence function , The default is not on
8.appendfsync everysec:
appendfsync always|everysec|no
AOF Write data strategy , Default everysec
9.appendfilename “appendonly.aof” :
appendfilename filename
AOF Persistent filename , The default file name is not appendonly.aof, Recommended configuration is appendonly- Port number .aof,AOF The path to save the persistent file is the same as RDB Persistent files are consistent
10.auto-aof-rewrite-percentage 100:
auto-aof-r ewrite-percentage percentage
11.auto-aof-rewrite-min-size 64mb:
auto-aof-rewrite-min-size size
Refers to the percentage of automatic rewriting
download redis Post default configuration :

![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-pZl2i8TE-1656561836131)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220630095206633.png)]](/img/29/3a784b8bc4ec407496e1c33122714f.png)

3.RDB Manual start mode -save
download redis Post default data directory :
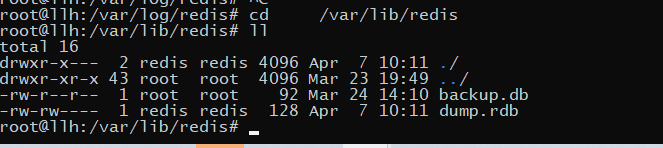
Delete both
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-3SAH5xG9-1656561836132)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220630095348781.png)]](/img/56/006c8952b8ee7af9205ae7cf47ce8f.png)
Preservation , There will be another dump.rdb file
save
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-tqcE0HsA-1656561836132)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220630095527740.png)]](/img/6e/090d4c8a0b5de9ac229adb200c0f6a.png)
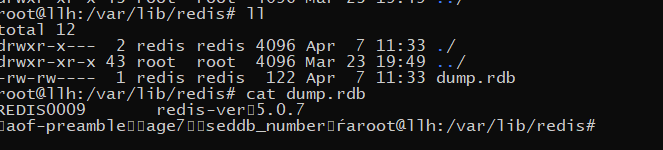
Save again , Although it is a binary file , But it can be vaguely found rdb The documents have changed
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-LQvXC6Pr-1656561836133)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220630095552941.png)]](/img/f6/5776acc51288ce514f1c60478f9a9c.png)

Turn off the server

Open the server again

The client can still view the key we just saved
4.RDB Manual start mode -save working principle
The order is as follows , return “save”
save
Be careful :save The execution of the instruction blocks the current Redis The server , Until now RDB Until the process is complete , It may cause long-term congestion , Online environment is not recommended ( If the following save If it takes too long ,get Will block )
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-7v7Nhkx4-1656561836133)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220630100230830.png)]](/img/7b/0254d3b86df58dbabfc900ebecd4e5.png)
5.RDB Manual start mode -bgsave working principle
The order is as follows , return “Background saving started”
bgsave
For resolution save The directive “ Too much data , How to deal with the low efficiency caused by single thread execution ” problem ;
Start the background save operation manually , But not immediately ;
bgsave The order is for save Optimization of blocking problem .Redis It's all about RDB operation ( namely “RDB Automatic start mode - Modify the configuration ”) All use bgsave The way ,save The command can be discarded ,bgsave And save I'm using one rdb file
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-cZBNOzwh-1656561836134)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220630100555810.png)]](/img/83/f48d6a53e3133d1afd112a5a12100f.png)
6.RDB Manual start mode -bgsave
Then bgsave operation , Discovery tips “Background saving started”
see dump.rdb, Vaguely found that there was a beijing

7.RDB Automatic start mode - Modify the configuration
Related to the following configurations :
save second changes
8.RDB Automatic start mode - Modify how the configuration works
1." Auto start mode configuration " It should be set according to the actual business situation , If the frequency is too high or too low, performance problems will occur , The results can be catastrophic :
For example, don't set it to “ Two key Change once and store once ” Frequency too high
2." Auto start mode configuration " For in the second And changes Settings usually have complementary correspondence , Try not to set up an inclusive relationship :
Such as the first “ The setting time is short and the amount of change is small , Set to 1 Second change 1 Time key”, Set another Cheng “100 Second change 100 Time key”,“100 Second change 100 Time key” Will be “1 Second change 1 Time key” To limit , So generally second When I was a child changes Just set it big ,second When I was big changes Just set small
3." Auto start mode configuration " After startup, execute bgsave operation :
save 900 1 The meaning is : When the time comes 900 seconds , If redis The data happened, at least 1 Changes , execute bgsave
Each instruction will return a result to redis, The following three conditions must be met :
1. Will have an impact on the data :
such as get The operation has no effect
2. It really made an impact :
If there is an impact on the data, but the data value does not change , It's not called “ It really made an impact ”, The value must be changed before it really has an impact
3. No data comparison :
That is, if we treat the same key Twice in a row set Instructions , There will be no data comparison ,redis Think it's two key There is a change
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-GOxiNNii-1656561836135)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220630101055030.png)]](/img/ff/18dcc7a884f526132cf425615c2675.png)
9.RDB Comparison of three startup modes
notes :”RDB Automatic start mode : And “bgsave” equally , Omit here
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-PLCUEzXh-1656561836135)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220630101614948.png)]](/img/5e/c43d35d56dcb776a9b2393fc398a24.png)
10.RDB Special starting form
10.1 Copy in full
Copy in full :
Explain in detail in master-slave replication
10.2 Restart the server while the server is running
If you restart the server while the server is running , It will start automatically RDB preservation
debug reload
10.3 Specify to save data when shutting down the server while the server is running
If you restart the server while the server is running , It will start automatically RDB preservation
Execute by default shutdown On command , Automatic execution bgsave( If it's not on AOF Persistence function )
shutdown save
11.RDB Advantages and disadvantages
RDB advantage :
1.RDB Is a compact binary , High storage efficiency
2.RDB What's stored inside is redis A snapshot of data at a point in time , Perfect for data backup , Full scale replication and other scenarios
3.RDB It's faster to recover data than AOF Much faster
4. application : Every X Hours to perform bgsave Backup , And will RDB Copy the file to the remote machine , For disaster recovery .
RDB shortcoming
1.RDB Whether it's executing instructions or using configuration , Unable to achieve real-time persistence , There is a high probability of data loss
2.bgsave The instructions are executed every time they run fork Action create subprocess , To sacrifice some performance , Extra consumption of memory
3.Redis In many versions of RDB Unified version of file format , There may be incompatibility of data formats among different versions of services
such as :2.0redis Of rdb file 4.0 I can't read it , In fact, there are solutions , stay 2.0 After saving the data to the file through the program , Then restore it to 4.0 The kind of data source format ,4.0 You can't read it
4. A large amount of data is stored , Low efficiency , Based on the idea of snapshot , Every read and write is all data , When the amount of data is huge , Very inefficient
5. Big data IO Low performance
6. The risk of data loss caused by downtime
12.AOF Introduce
about RDB The shortcomings of ,AOF Make corrections ,AOF The solution is as follows :
1. Don't write full data , Only part of the data is recorded
2. Reduce the difficulty of distinguishing whether the data has changed , Change record data to record operation process
3. Record all operations , Eliminate the risk of data loss
AOF(append only file) Persistence : Each write is logged as a separate log , Reexecute on reboot AOF The command in the file achieves the purpose of recovering data . And RDB In contrast, it can simply describe the process of changing recorded data to recorded data generation
AOF Its main function is to solve the real-time problem of data persistence , So far Redis The mainstream way of persistence
13.AOF How to write data
When the server receives the instructions we executed , The server did not immediately record aof In the document , Instead, it was placed in a temporary area , namely “AOF Write command to be operated ” The corresponding buffer , After a certain stage , Synchronize the commands in the past buffer to aof Just in the file
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-22O4brJf-1656561836136)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220630103158349.png)]](/img/57/25011c1290d223d789e6e812da01a4.png)
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-80QrBWgn-1656561836136)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220630103532755.png)]](/img/92/f0200471acad2cf0cf4d20486c7ea8.png)
14.AOF Three strategies for writing data (appendfsync)
1.always( Every time )
Each write operation is synchronized to AOF In file , Data zero error , Low performance , Not recommended
2.everysec( Per second )
Synchronizes the instructions in the buffer to per second AOF In file , The accuracy of the data is high , Higher performance , It is recommended to use , Lost in the event of a sudden system outage 1 Seconds of data
3.no( System control )
The operating system controls each synchronization to AOF The period of the document , The whole process is uncontrollable
15.AOF Rewrite Preface
Look at the following questions , According to traditional thinking ,AOF Will 6 Pieces of data are written aof file , As commands are written AOF, The file will get bigger and bigger
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-jTVnMsZ1-1656561836137)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220630104021442.png)]](/img/36/2e46237ae5e2e64095951d4b256408.png)
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-oZCfdSr4-1656561836137)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220630104043944.png)]](/img/b8/4ea8dd429dba6027d3e95516abd87f.png)
16.AOF Introduction to rewriting
In order to solve the problem demonstrated above ,Redis Introduced AOF Rewrite mechanism to compress file volume .
AOF File rewriting is to Redis In process data is converted to write command and synchronized to new AOF Documentation process . In short, it is to convert the execution results of several commands on the same data into the instructions corresponding to the final result data for recording .
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-aDPXvbl8-1656561836138)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220630104218463.png)]](/img/d7/8c636dcc25babd877dbec2b1447924.png)
17.AOF Rewriting effect
AOF Rewriting effect
1. Reduce disk usage , Improve disk utilization
2. Improve persistence efficiency , Reduce persistent write time , Improve IO performance
3. Reduce data recovery time , Improve data recovery efficiency
18.AOF Rewriting rule
1. Data that has timed out in the process is no longer written to the file
2. Ignore invalid instructions , In process data generation is used when rewriting , So new AOF Write command to keep only the final data in the file :
Such as del key1、 hdel key2、srem key3、set key4 111、set key4 222 etc.
3. Multiple write commands for the same data are combined into one command :
Such as lpush list1 a、lpush list1 b、 lpush list1 c Can be converted to :lpush list1 a b c.
In order to prevent client buffer overflow caused by excessive data , Yes list、set、hash、zset Other types , Each instruction can write at most 64 Elements
19.AOF Manual override mode -bgrewriteaof
bgrewriteaof
The following two demos are video screenshots :
demonstration 1:
many times set value
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-jKWCfqmX-1656561836138)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220630105700070.png)]](/img/3b/78b73c57f530d3e9d3977aa19b80a3.png)
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-yIp6eq9U-1656561836139)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220630105711829.png)]](/img/79/036a75020b1164a8ad14fdd22f2a53.png)
After execution bgrewriteaof Output “Background append only file rewriting started” Immediately switch to “127.0.0.1:6379”, This does not mean that the rewrite has been completed , Only in the log file can we see whether the rewrite has been completed

![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-4ksZJZ7y-1656561836139)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220630105830250.png)]](/img/c5/71d307c7949909faee3a9ef34a4c1c.png)
Demo two :
many times lpush
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-ed9ant93-1656561836140)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220630105853889.png)]](/img/57/ae339d16878f2f69583b99e9747a41.png)
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-MLuSytQM-1656561836140)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220630105905668.png)]](/img/ea/bbecde12a4cfde02e251a2a94d3a82.png)
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-B51ZKdly-1656561836140)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220630105948568.png)]](/img/31/c634574bb769c9f7932e1c54e8ec9b.png)

![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-NratQ5QQ-1656561836141)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220630110007959.png)]](/img/c8/4a55adfb126586033731d6099cd318.png)
20.AOF Auto rewrite mode - Modify the configuration
1. It is mainly related to the following configurations :
auto-aof-rewrite-min-size size
auto-aof-rewrite-percentage percentage
2. Automatically rewrite trigger comparison parameters ( Operation instruction info
Get specific information ):
aof_current_size : Refers to the current situation aof How much is in the buffer , Note that this does not refer to the number of stored instructions !
aof_base_size:
3. Automatically override trigger conditions :
Here's the picture :

info
stay Persistence below :
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-AxPzIBHp-1656561836141)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220630110448200.png)]](/img/8f/b7d9cce3ba89147f16fc53b3a1287e.png)
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-aTRVLUzR-1656561836141)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220630110504338.png)]](/img/a6/ff2bc9a536ade2d91668de47c1443d.png)
21.AOF Manual override mode -bgrewriteaof working principle
"AOF Manual override mode bgrewriteaof working principle " And bgsave Is very similar
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-XiPAjSD1-1656561836142)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220630111050897.png)]](/img/3a/dcfa2e1a371be4bf7b5364ccd97129.png)
22.AOF Rewrite process
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-AkIcZirS-1656561836142)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220630111210957.png)]](/img/b7/7c58ed903eef1556bc82b8d4573c0f.png)
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-AuXQIqkA-1656561836142)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220630111256529.png)]](/img/26/2895e72f51128d4ceee32a442acecb.png)
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-st0OUh4O-1656561836142)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220630111640966.png)]](/img/23/532a8e022ccbd0f606834f3b3aa09b.png)
23.RDB And AOF difference
AOF Prior to the RDB start-up
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-UlyAeFwU-1656561836143)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220630111752775.png)]](/img/16/3e894491cfa955bc60319104104b45.png)
24.RDB And AOF Choice problem
1. It is very sensitive , The default... Is recommended AOF Persistence scheme
AOF Persistence strategy uses everysecond, Every second fsync once . The strategy redis It can still maintain good processing performance , When something goes wrong , At most 0-1 Seconds of data .
Be careful : because AOF The file storage volume is large , And the recovery speed is slow
2. Data presentation phase validity , It is recommended to use RDB Persistence scheme
Data can be well done in the phase without loss ( This stage is manually maintained by developers or operation and maintenance personnel ), And the recovery speed is faster , Phase point data recovery usually uses RDB programme
Be careful : utilize RDB Implementing compact data persistence makes Redis It's very low , Sum up carefully :
3. Comprehensive comparison
1)RDB And AOF Your choice is actually a trade-off , Each has its advantages and disadvantages
2) If you can't afford to lose data within a few minutes , Very sensitive to business data , choose AOF
3) If it can withstand data loss within a few minutes , And pursue the recovery speed of large data sets , choose RDB
4) Disaster recovery options RDB
5) Double insurance strategy , At the same time open RDB and AOF, After restart ,Redis priority of use AOF To recover data , Reduce the amount of lost data
25. Persistent application scenarios
None of the following redlines need persistence
Tip1: Just put the last one id+1 That's it , No persistence , Temporary storage is ok
Tip3: Refer to “ Whether the data in the cache needs to be persisted ”, Because the cached data comes from the database , So no persistence
Tip4: Shopping carts are stored in the database
Tip5: For snapping up data , Speed needs to be very fast , So you need persistence , And there are few coupons
Tip6: Be similar to Tip7, It's just temporary , Persistence is required
Tip12: If the blacklist is permanently stored , Data is stored ; If the blacklist is short-term storage ,redis Li Cun ; The white list is basically stored in the database
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-2shMdi22-1656561836143)(C:/Users/86158/AppData/Roaming/Typora/typora-user-images/image-20220630112022005.png)]](/img/79/68a324c4b5318903e6e8504bc91219.png)
边栏推荐
- Intel Distiller工具包-量化实现3
- Implement window blocking on QWidget
- The carousel component of ant design calls prev and next methods in TS (typescript) environment
- Digital people anchor 618 sign language with goods, convenient for 27.8 million people with hearing impairment
- Redis之哨兵模式
- Detailed explanation of dynamic planning
- [OC-Foundation框架]---【集合数组】
- go-redis之初始化连接
- Seven layer network architecture
- 【shell脚本】——归档文件脚本
猜你喜欢
Nacos installation and service registration
Nacos 的安装与服务的注册

Intel Distiller工具包-量化实现2

Mise en œuvre de la quantification post - formation du bminf
Reids之缓存预热、雪崩、穿透
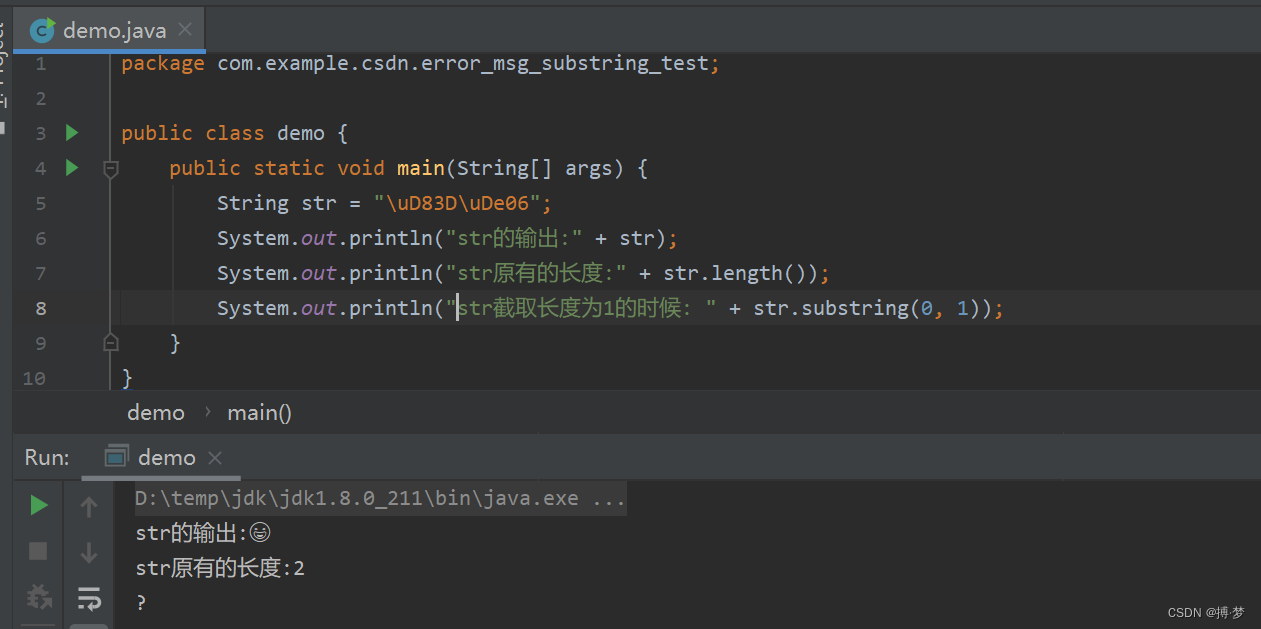
How to intercept the string correctly (for example, intercepting the stock in operation by applying the error information)
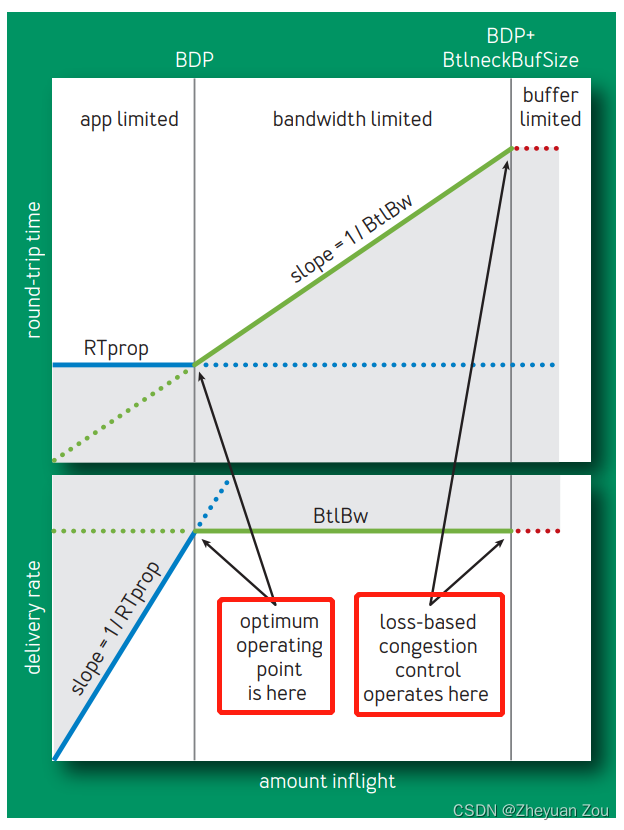
Advanced Computer Network Review(3)——BBR
![[today in history] February 13: the father of transistors was born The 20th anniversary of net; Agile software development manifesto was born](/img/70/d275009134fcbf9ae984c0f278659e.jpg)
[today in history] February 13: the father of transistors was born The 20th anniversary of net; Agile software development manifesto was born
![[sword finger offer] serialized binary tree](/img/e2/25c9322da3acda06c4517b0c50f81e.png)
[sword finger offer] serialized binary tree
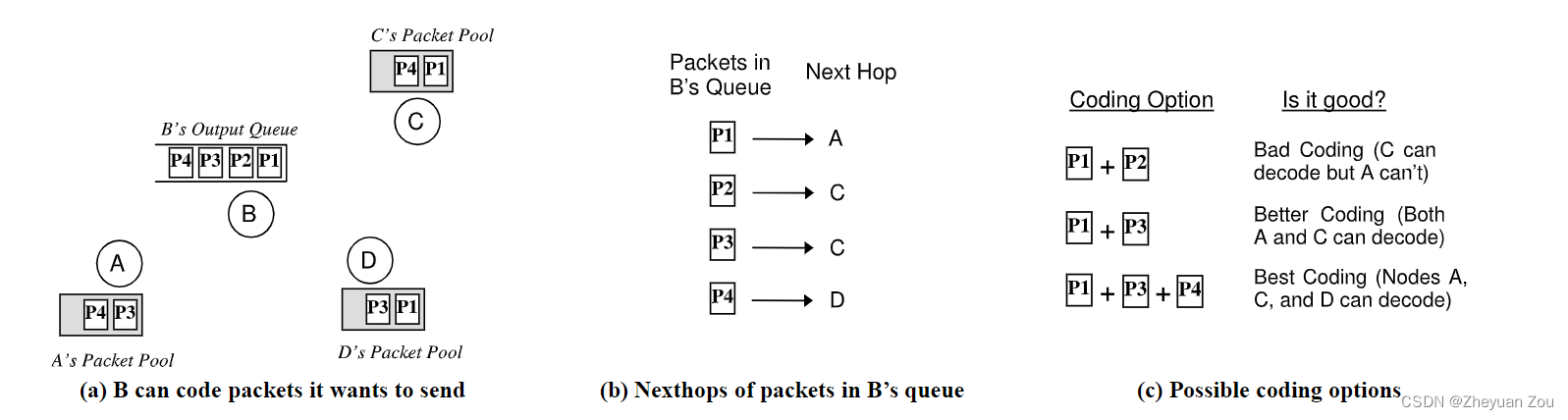
Advanced Computer Network Review(5)——COPE
随机推荐
Implement window blocking on QWidget
Pytest参数化你不知道的一些使用技巧 /你不知道的pytest
Improved deep embedded clustering with local structure preservation (Idec)
CUDA realizes focal_ loss
七层网络体系结构
CUDA implementation of self defined convolution attention operator
After reading the programmer's story, I can't help covering my chest...
LeetCode:387. The first unique character in the string
QML type: locale, date
[oc]- < getting started with UI> -- learning common controls
多元聚类分析
Selenium+Pytest自动化测试框架实战
Booking of tourism products in Gansu quadrupled: "green horse" became popular, and one room of B & B around Gansu museum was hard to find
[text generation] recommended in the collection of papers - Stanford researchers introduce time control methods to make long text generation more smooth
KDD 2022论文合集(持续更新中)
QML type: overlay
[OC]-<UI入门>--常用控件的学习
SAP ui5 date type sap ui. model. type. Analysis of the parsing format of date
Cesium draw points, lines, and faces
Advance Computer Network Review(1)——FatTree