当前位置:网站首页>Chapter 1 :Application of Artificial intelligence in Drug Design:Opportunity and Challenges
Chapter 1 :Application of Artificial intelligence in Drug Design:Opportunity and Challenges
2022-07-06 09:03:00 【UniversalNature】
reading notes of《Artificial Intelligence in Drug Design》
List of articles
Chapter 1 Application of Artificial intelligence in Drug Design : Opportunity and Challenges
1.Introduction : What Challenges Does Drug Design Face
- R&D cost increased dramatically.
 - Hits with promising potency and ADMET properties are chosen as “lead compounds” —— these then need to be optimized for potency and selectivity while maintaining an appropriate ADMET profile. This process is often ineffective at finding molecules with the right pharmacodynamic and pharmacokinetic properties in patients.- Datasets problem:
- Hits with promising potency and ADMET properties are chosen as “lead compounds” —— these then need to be optimized for potency and selectivity while maintaining an appropriate ADMET profile. This process is often ineffective at finding molecules with the right pharmacodynamic and pharmacokinetic properties in patients.- Datasets problem:
- Many datasets are disproportionately focused on a small range of well-studied endpoints.
- Datasets describing in vitro activities of compounds is larger than those describing their in vivo effects.
- Consistent annotation of data is challenging.
- There is little hope of conducting simulations of complex physiological systems, necessitating the use of empirical models.
2. Application of Artificial Intelligence in Drug Design
2.1.Virtual Screening
2.1.1.Introduction
- HTS(high-throughput screening) screens large chemical libraries against project relevant activity assays.
- VS(virtual screening) attempts to address the shortcomings of HTS by screening compounds in silico rather than in vitro.
- VS can be categorized into two types: ligand-based VS and structure-based VS.
- ligand-based VS uses a set of compounds that are known to be active and tries to identify other molecules. This needs a predictive model to prioritize active compounds.
- structure-based VS evaluates a ligand based on the complementarity of 3D structures with the target’s binding pockets. This needs 3D information which is hard to obtain.
2.1.2.Dataset Bias in Machine Learning-Based Virtual Screening
- Molecular datasets used in VS incorporate bias due to several reasons.
- Their size is comparably small relative to the space of potential molecules.
- The nature of drug development pipelines leads to bias : synthesis efforts typically focus around known successful molecules.
- Novel molecules are often proposed in series that grow during hit selection and lead optimization. As a result, explored regions of chemical space are formed of clusters rather than uniform samples.
- The practitioners should be careful about how they split their dataset for training and testing. (Butina-Taylor)
- Another caveat that practitioners should be aware of is the lack of universally accepted chemical datasets on which to evaluate models for VS. (DUD-E, MUV, AVE)
- Bias is not always undesirable.
2.1.3.Receptor Structure-Based Virtual Screening (Docking)
- Most ML approaches to structure-based VS have focused on improving the scoring function. Gnina and AtomNet have develop their own standalone scoring functions. Other ML model (such as △VinaRF) for scoring attempt to improve rather than replace.
- One way to improve scoring functions is to tailor them to the problem of interest. ML model is more suitable than traditional docking algorithms.
- An important limitation of current ML model with respect to traditional docking algorithms is that they generally lack the capabilities to produce docking poses, so they rely on external software to obtain them. This means ML model performance is capped by the performance of external pose generation.
2.1.4.Ligand-Based Methods (QSAR)
What characterizes ligand-based VS is that it does not utilize any information about the receptor. Therefore, it can be applied to general problems.
QSAR and ML model is similar: both are supervised methods that identify pattern in molecular data to learn a target signal.
In addition to fitting complicated target functions, ML model can allows a greater breadth of molecular representations, some of them is very abstract but important such as molecule-induced transcriptomic signatures or cell painting imaging profiles.
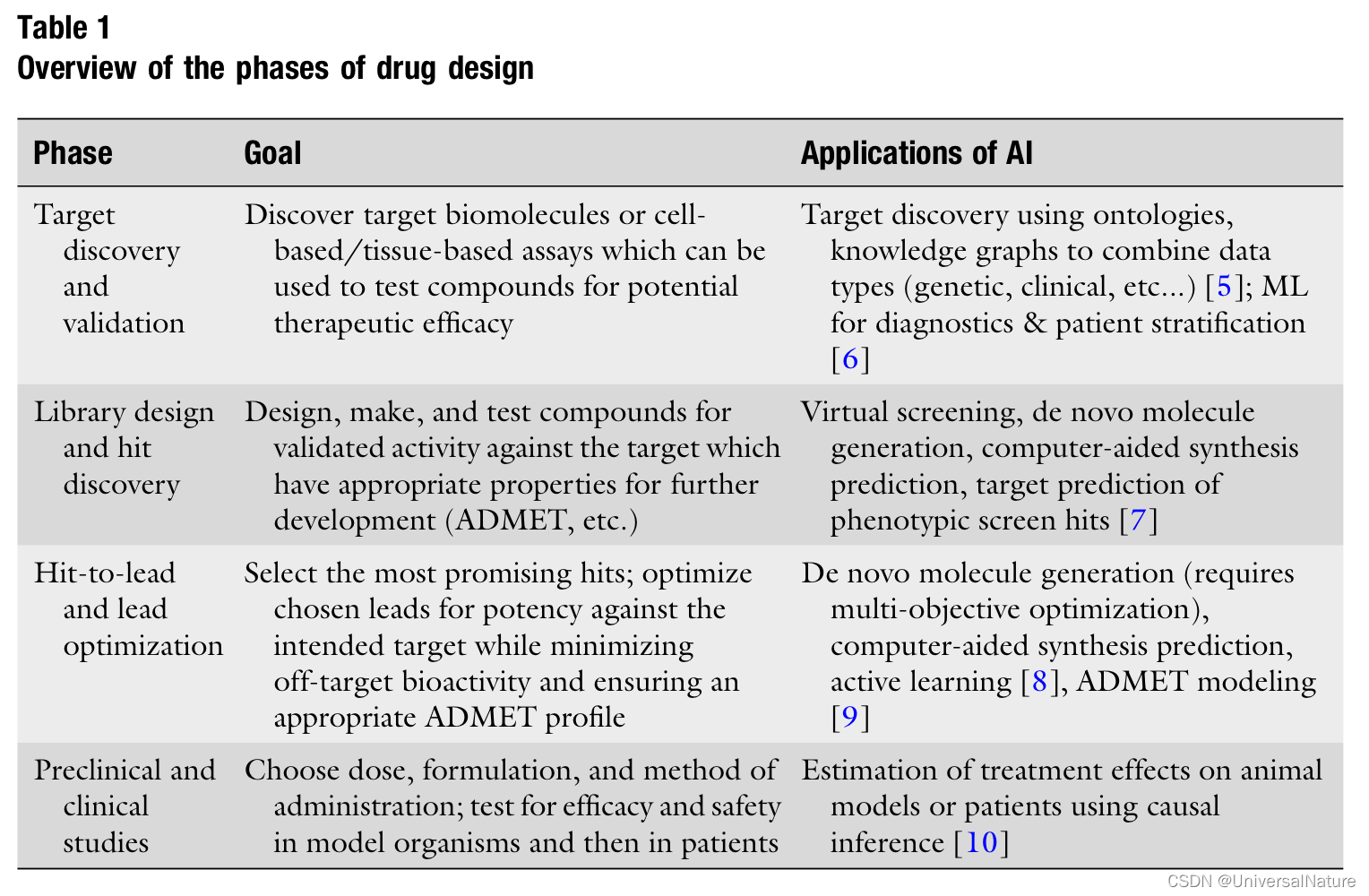
In addition to using new biological data types, another advantage of some ML model is that they can learn their own representation from a dataset. VAE’s latent space is usually smaller in size than the input, so the model is forced to find a compressed representation of the input.
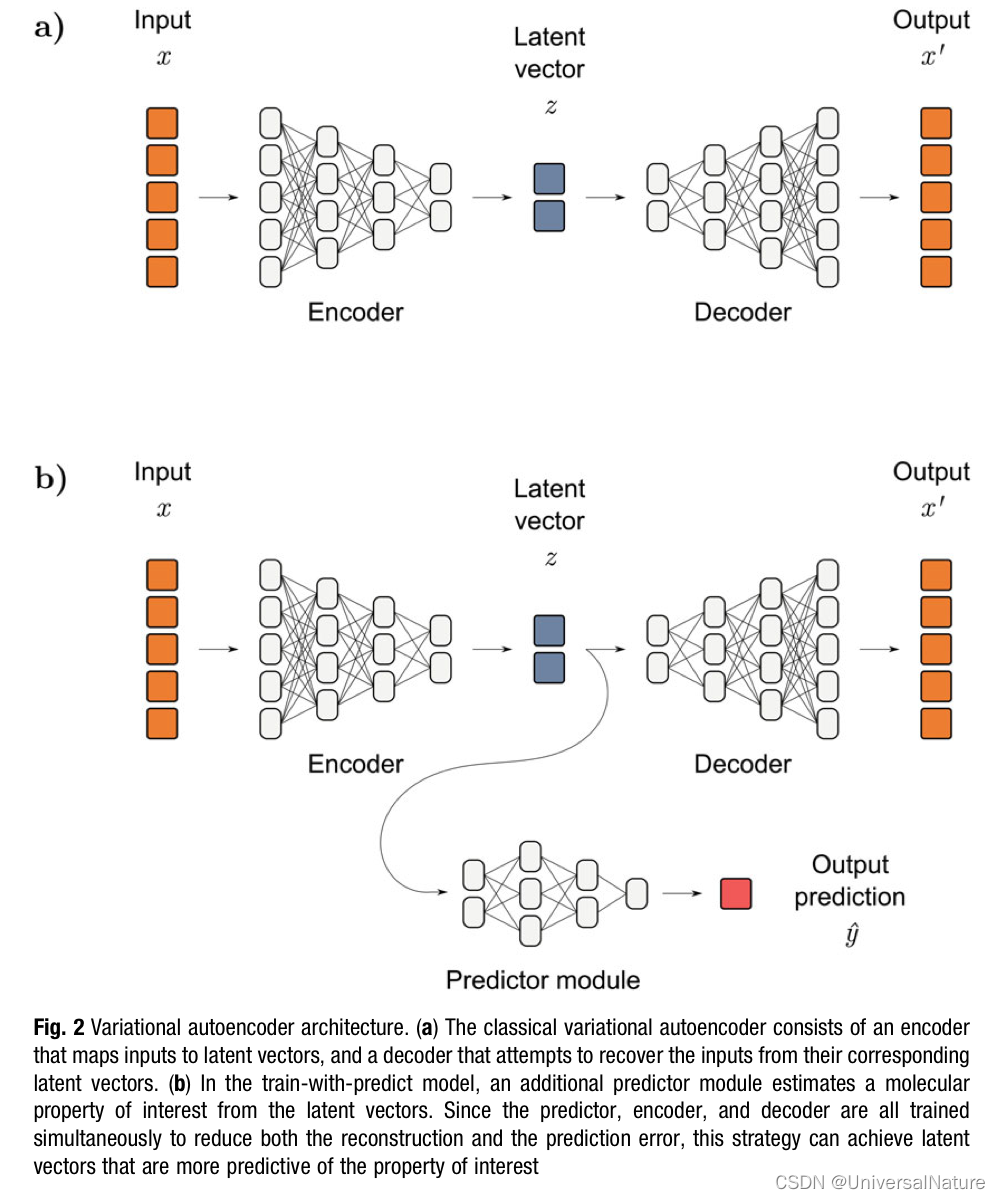
Some ML models accepted flexible training regimes which presents another opportunity for improvement of ligand-based. There are several methods based on the idea of shared knowledge, such as transfer learning, multitask learning, self-supervised learning.
Flexibility brings practical difficulties, too. The high degree of choice makes it difficult to decide what model is most promising for a specific problem. The part of challenge is that it is difficult to diagnose why a ML method is successful.
2.1.5.Hybrid VS (Incomprehensible)
- Hybrid VS refer to statistic al models for bioactivity prediction that incorporate information about the receptor, but in more abstract form than a geometric description of the binding pocket. It is often considered an expansion of ligand-based VS and QSAR.
- The most common type of Hybrid VS are proteochemometirc models (PCM).
- Many of the opportunities and limitations discussed in Ligand-Based VS is applicable here.
- PCM is the flexibility and customizability of input representations. DeppDTA and DGraphDTA could produce target representations.
- PCM is building models that scale to the big-data regime, such as collaborative filtering.
- ML is helpful for PCM in uncertainty quantification. A work that applied a Gaussian process to PCM found that Bayesian model achieved calibrated variance estimates for each prediction.
- ML could be used to design novel hybrid workflows different from PCM, such as DeepDocking.
边栏推荐
- 注意力机制的一种卷积替代方式
- CUDA implementation of self defined convolution attention operator
- Alibaba cloud server mining virus solution (practiced)
- Intel Distiller工具包-量化实现2
- opencv+dlib实现给蒙娜丽莎“配”眼镜
- [OC-Foundation框架]-<字符串And日期与时间>
- 一改测试步骤代码就全写 为什么不试试用 Yaml实现数据驱动?
- BMINF的后训练量化实现
- UML diagram memory skills
- Advanced Computer Network Review(3)——BBR
猜你喜欢
Nacos 的安装与服务的注册

Esp8266-rtos IOT development
A convolution substitution of attention mechanism

LeetCode:221. 最大正方形
自定义卷积注意力算子的CUDA实现

Simclr: comparative learning in NLP
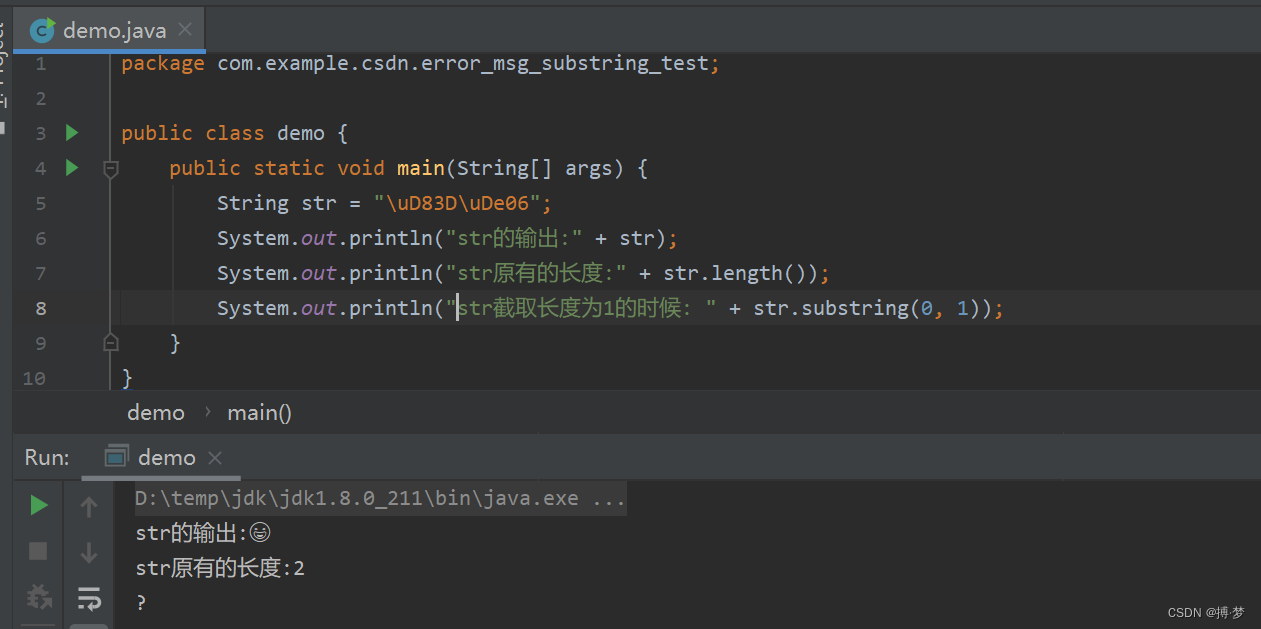
如何正确截取字符串(例:应用报错信息截取入库操作)
After reading the programmer's story, I can't help covering my chest...
vb. Net changes with the window, scales the size of the control and maintains its relative position
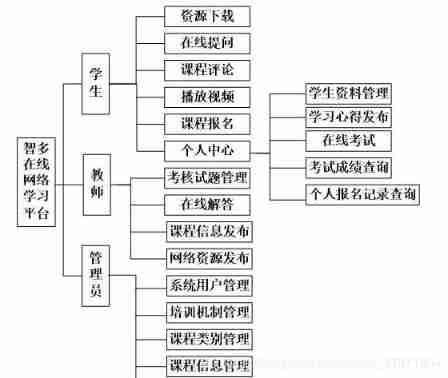
Computer graduation design PHP Zhiduo online learning platform
随机推荐
MySQL uninstallation and installation methods
注意力机制的一种卷积替代方式
CUDA实现focal_loss
LeetCode:394. String decoding
【文本生成】论文合集推荐丨 斯坦福研究者引入时间控制方法 长文本生成更流畅
Leetcode: Jianzhi offer 03 Duplicate numbers in array
LeetCode:221. 最大正方形
LeetCode:124. 二叉树中的最大路径和
UML圖記憶技巧
CUDA implementation of self defined convolution attention operator
[MySQL] limit implements paging
【剑指offer】序列化二叉树
Unsupported operation exception
TP-LINK enterprise router PPTP configuration
AcWing 2456. 记事本
[today in history] February 13: the father of transistors was born The 20th anniversary of net; Agile software development manifesto was born
I-BERT
TDengine 社区问题双周精选 | 第三期
LeetCode:162. Looking for peak
Ijcai2022 collection of papers (continuously updated)