当前位置:网站首页>Mise en œuvre de la quantification post - formation du bminf
Mise en œuvre de la quantification post - formation du bminf
2022-07-06 08:54:00 【Cyz0202】
BMINF
- BMINFC'est un grand outil de raisonnement de modèle développé par l'Université Tsinghua,À l'heure actuelle, lesCPMOptimisation inférentielle des modèles de série.Cet outil implémente la mémoire/Optimisation de l'ordonnancement de la mémoire vidéo,Utilisationcupy/cudaLa quantification post - formation a été réalisée Fonctions équivalentes,Cet article documente et analyse la mise en oeuvre quantitative post - formation de cet outil.
- Principaux sujets de préoccupationcupyFonctionnementcudaRéalisation de la partie quantifiée,Les principes relatifs à la quantification ne seront peut - être pas détaillés,Le lecteur doit consulter d'autres documents;
- BMINFL'équipe a récemment beaucoup remanié le Code;L'exemple de code que j'utilise ci - dessous est8Il y a un mois.,Le lecteur veut voirBMINFCode source correspondant,Veuillez vérifier0.5Version
Analyse du Code de mise en œuvre1
Le Code d'entrée de la Section de quantification est principalement utilisé dans tools/migrate_xxx.py,Voici tools/migrate_cpm2.pyPar exemple;
mainFonctions
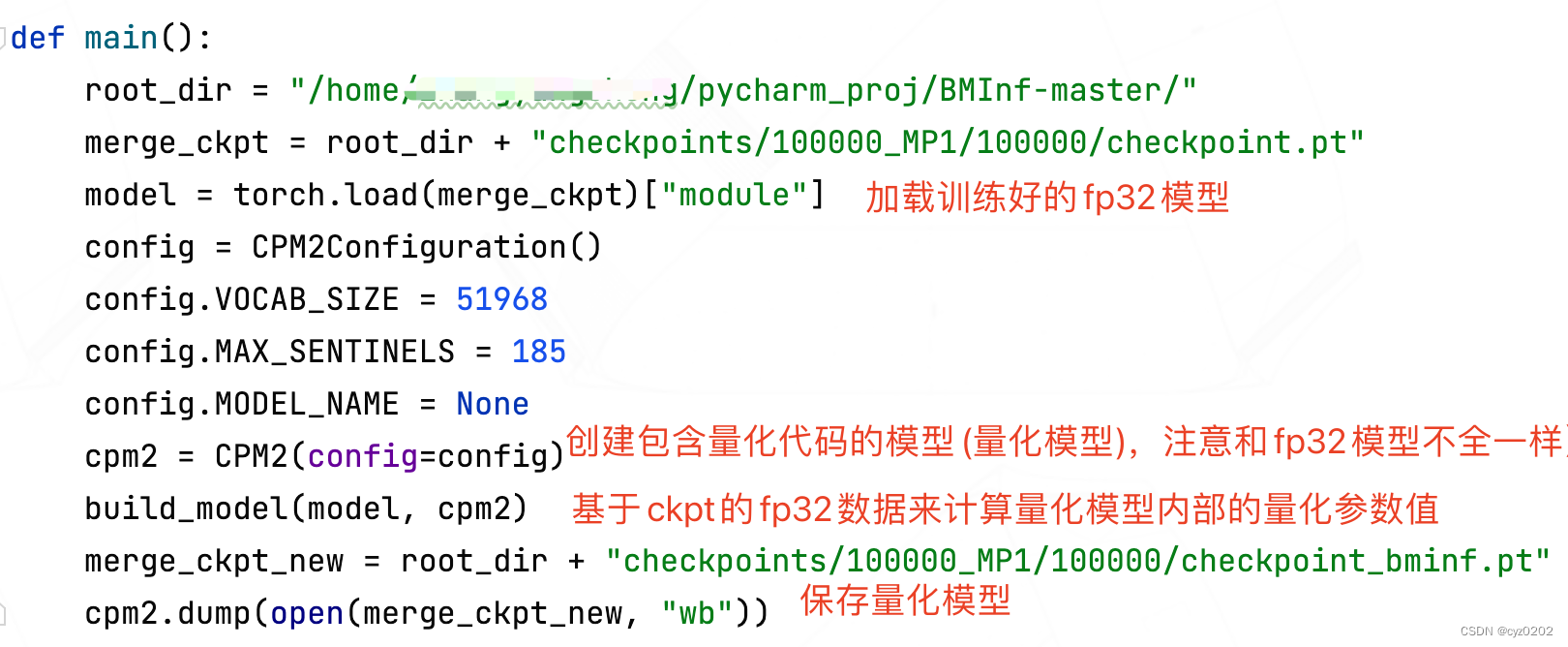
build_modelFonctions:Basé surckptDefp32Les données calculent les valeurs des paramètres de quantification à l'intérieur du modèle de quantification

scale_build_parameterFonctions: Calcul de la quantification symétrique scale,Et vascale Et les résultats quantifiés sont placés dans les paramètres correspondants du modèle quantifié ( Ce qui précède correspond à model.encoder_kv.w_project_kv_scaleEtw_project_kv)

Regardez celui qui a sauvegardé les résultats quantifiés model.encoder_kv.w_project_kv_scaleEtw_project_kvComment ça se définit

build_encoder/decoderFonctions:Appel principalbuild_block,Traiter chaqueblock(layer)

build_blockFonctions: Ou copier une partie module Paramètres et quantification de l'autre partie moduleParamètres pour

Résumé:Ce qui précède vient defp32 Le modèle aura différents paramètres copy Réalisation à l'emplacement correspondant du modèle quantitatif ; Voici comment le modèle de quantification utilise les paramètres de quantification +cupy+cudaEffectuer des calculs,Réaliser l'accélération;
Analyse du Code de mise en œuvre2
- Pardecoder Attention utilisée module: partial_attetionAnalyse par exemple(bminf/layers/attention)
- C'est le Code.,Voir les notes
class PartialAttention(Layer):
def __init__(self, dim_in, dim_qkv, num_heads, is_self_attn):
self.is_self_attn = is_self_attn # self_attnToujourscross_attn
self.dim_in = dim_in
self.num_heads = num_heads
self.dim_qkv = dim_qkv
if self.is_self_attn:
self.w_project_qkv = Parameter((3, dim_qkv * num_heads, dim_in), cupy.int8) # Utilisation du poidsint8Quantification, Ici, on reçoit. fp32Deckpt Résultats quantifiés des paramètres correspondants
self.w_project_qkv_scale = Parameter((3, dim_qkv * num_heads, 1), cupy.float16) # scaleUtiliserfp16;Ce qui est remarquable, c'est quescaleC'est vrai.dim_inCette dimension
else:
self.w_project_q = Parameter((dim_qkv * num_heads, dim_in), cupy.int8) # cross_attn shapeC'est un peu différent.
self.w_project_q_scale = Parameter((dim_qkv * num_heads, 1), cupy.float16)
# Refaire avant la sortie linear
self.w_out = Parameter((dim_in, dim_qkv * num_heads), cupy.int8)
self.w_out_scale = Parameter((dim_in, 1), cupy.float16)
def quantize(self, allocator: Allocator, value: cupy.ndarray, axis=-1):
""" Fonction de quantification,allocatorAssigner la mémoire vive,value C'est à quantifier. fp16/32Valeur;axis Est une dimension quantitative Remarquez qu'un quantizeFonctions, C'est du vrai travail. ======================================================== VoiciquantizeMise en œuvre de la fonction: def quantize(x: cupy.ndarray, out: cupy.ndarray, scale: cupy.ndarray, axis=-1): assert x.dtype == cupy.float16 or x.dtype == cupy.float32 assert x.shape == out.shape if axis < 0: axis += len(x.shape) assert scale.dtype == cupy.float16 assert scale.shape == x.shape[:axis] + (1,) + x.shape[axis + 1:] # scale on gpu Calculscale( Mode symétrique ) quantize_scale_kernel(x, axis=axis, keepdims=True, out=scale) quantize_copy_half(x, scale, out=out) # Calcul Résultats quantitatifs ======================================================== Voiciquantize_scale_kernelEtquantize_copy_half/floatRéalisation: # Retour àquantize_scale_kernelC'est ça.cudaFonctions sur, Calcul de la quantification scale quantize_scale_kernel = create_reduction_func( # kernelÇa veut direcudaFonctions sur,Voilà.cupyJeancuda Créer la fonction correspondante (kernel) 'bms_quantize_scale', # Nom de la fonction créée ('e->e', 'f->e', 'e->f', 'f->f'), # Spécifier l'entrée->Type de données de sortie(Denumpy,Par exemple:eReprésentantfloat16,f- Oui.float32) ('min_max_st<type_in0_raw>(in0)', 'my_max(a, b)', 'out0 = abs(a.value) / 127', 'min_max_st<type_in0_raw>'), # cuda Ce qui sera fait None, _min_max_preamble # Si vous avez besoin d'une structure de données personnalisée, etc , C'est écrit ici. , Ligne précédente min_max_st、my_maxAttends, c'estbminf Auteur personnalisé , Ça ne se voit pas ici. ) # Retourquantize_copy_halfEncore une foiscudaFonctions,Cette fonction estcuda Calculer la valeur de quantification =x/scale; Notez que la quantification symétrique n'a pas zero_point quantize_copy_half = create_ufunc( 'bms_quantize_copy_half', ('ee->b', 'fe->b', 'ff->b'), 'out0 = nearbyintf(half(in0 / in1))') # halfÇa veut direfp16 quantize_copy_float = create_ufunc( 'bms_quantize_copy_float', ('ee->b', 'fe->b', 'ff->b'), 'out0 = nearbyintf(float(in0 / in1))') ======================================================== """
if axis < 0:
axis += len(value.shape)
# Ci - dessous3 L'allocation de ligne est affichée à la valeur quantifiée 、scale
nw_value = allocator.alloc_array(value.shape, cupy.int8)
scale_shape = value.shape[:axis] + (1,) + value.shape[axis + 1:]
scale = allocator.alloc_array(scale_shape, cupy.float16)
# Fonction de quantification réelle ,Calculscale Valeur stockée dans scaleMoyenne, Calculer la valeur quantifiée stockée dans nw_valueMoyenne
quantize(value, nw_value, scale, axis=axis)
return nw_value, scale # Renvoie la valeur quantifiée 、scale
def forward(self,
allocator: Allocator,
curr_hidden_state: cupy.ndarray, # (batch, dim_model)
past_kv: cupy.ndarray, # (2, batch, num_heads, dim_qkv, past_kv_len)
position_bias: Optional[cupy.ndarray], # (1#batch, num_heads, past_kv_len)
past_kv_mask: cupy.ndarray, # (1#batch, past_kv_len)
decoder_length: Optional[int], # int
):
batch_size, dim_model = curr_hidden_state.shape
num_heads, dim_qkv, past_kv_len = past_kv.shape[2:]
assert past_kv.shape == (2, batch_size, num_heads, dim_qkv, past_kv_len)
assert past_kv.dtype == cupy.float16
assert num_heads == self.num_heads
assert dim_qkv == self.dim_qkv
assert curr_hidden_state.dtype == cupy.float16
if self.is_self_attn:
assert decoder_length is not None
if position_bias is not None:
assert position_bias.shape[1:] == (num_heads, past_kv_len)
assert position_bias.dtype == cupy.float16
assert past_kv_mask.shape[-1] == past_kv_len
# value->(batch, dim_model), scale->(batch, 1) Ici.one decoder-step,Donc non.seq-len
# Quantifier l'entrée
value, scale = self.quantize(allocator, curr_hidden_state[:, :], axis=1)
if self.is_self_attn: # Auto - attention
qkv_i32 = allocator.alloc_array((3, batch_size, self.num_heads * self.dim_qkv, 1), dtype=cupy.int32)
else:
qkv_i32 = allocator.alloc_array((batch_size, self.num_heads * self.dim_qkv, 1), dtype=cupy.int32)
if self.is_self_attn:
# De l'attention ,qkv Il faut une transformation linéaire. ;UtiliserigemmJeancudaMise en œuvre8bit matmul;
# On verra plus tard. igemmRéalisation
igemm(
allocator,
self.w_project_qkv.value, # (3, num_head * dim_qkv, dim_model)
True, # Transposition
value[cupy.newaxis], # (1, batch_size, dim_model)
False,
qkv_i32[:, :, :, 0] # (3, batch_size, num_head * dim_qkv)
)
else:
# Quand on se croise ,C'est exact.qFaire une transformation linéaire
igemm(
allocator,
self.w_project_q.value[cupy.newaxis], # (1, num_head * dim_qkv, dim_model)
True,
value[cupy.newaxis], # (1, batch_size, dim_model)
False,
qkv_i32[cupy.newaxis, :, :, 0] # (1, batch_size, num_head * dim_qkv)
)
# release value
del value
# convert int32 to fp16 Transformer le résultat de la transformation linéaire ci - dessus int32Convertir enfp16
# Notez que l'ensemble du processus n'est pas unique int8OuintCalcul du type
assert qkv_i32._c_contiguous
qkv_f16 = allocator.alloc_array(qkv_i32.shape, dtype=cupy.float16)
if self.is_self_attn:
""" elementwise_copy_scale = create_ufunc('bms_scaled_copy', ('bee->e', 'iee->e', 'iee->f', 'iff->f'), 'out0 = in0 * in1 * in2') """
elementwise_copy_scale( # Effectuer une contre - quantification ,Je l'ai.fp16ÀoutÀ l'intérieur
qkv_i32, # (3, batch_size, num_head * dim_qkv, 1)
self.w_project_qkv_scale.value[:, cupy.newaxis, :, :], # (3, 1#batch_size, dim_qkv * num_heads, 1)
scale[cupy.newaxis, :, :, cupy.newaxis], # (1#3, batch_size, 1, 1)
out=qkv_f16
)
else:
elementwise_copy_scale(
qkv_i32, # (1, batch_size, num_head * dim_qkv, 1)
self.w_project_q_scale.value, # (dim_qkv * num_heads, 1)
scale[:, :, cupy.newaxis], # (batch_size, 1, 1)
out=qkv_f16
)
del scale
del qkv_i32
# reshape
assert qkv_f16._c_contiguous
if self.is_self_attn:
qkv = cupy.ndarray((3, batch_size, self.num_heads, self.dim_qkv), dtype=cupy.float16, memptr=qkv_f16.data)
query = qkv[0] # (batch, num_heads, dim_qkv)
past_kv[0, :, :, :, decoder_length] = qkv[1] # Stocker comme historique kv, Éviter les doubles calculs ultérieurs
past_kv[1, :, :, :, decoder_length] = qkv[2]
del qkv
else:
query = cupy.ndarray((batch_size, self.num_heads, self.dim_qkv), dtype=cupy.float16, memptr=qkv_f16.data)
del qkv_f16
# calc attention score(fp16)
attention_score = allocator.alloc_array((batch_size, self.num_heads, past_kv_len, 1), dtype=cupy.float16)
fgemm( # Les scores d'attention sont calculés en utilisant float-gemmCalcul
allocator,
query.reshape(batch_size * self.num_heads, self.dim_qkv, 1), # (batch_size * num_heads, dim_qkv, 1)
False,
past_kv[0].reshape(batch_size * self.num_heads, self.dim_qkv, past_kv_len),
# ( batch_size * num_heads, dim_qkv, past_kv_len)
True,
attention_score.reshape(batch_size * self.num_heads, past_kv_len, 1)
# (batch_size * num_heads, past_kv_len, 1)
)
# maskCalcul
""" mask_attention_kernel = create_ufunc( 'bms_attention_mask', ('?ff->f',), 'out0 = in0 ? in1 : in2' # Sélecteur ) """
mask_attention_kernel(
past_kv_mask[:, cupy.newaxis, :, cupy.newaxis], # (batch, 1#num_heads, past_kv_len, 1)
attention_score,
cupy.float16(-1e10),
out=attention_score # (batch_size, self.num_heads, past_kv_len, 1)
)
if position_bias is not None:
attention_score += position_bias[:, :, :, cupy.newaxis] # (1#batch, num_heads, past_kv_len, 1)
# Calculsoftmax floatSituation
temp_attn_mx = allocator.alloc_array((batch_size, self.num_heads, 1, 1), dtype=cupy.float16)
cupy.max(attention_score, axis=-2, out=temp_attn_mx, keepdims=True)
attention_score -= temp_attn_mx
cupy.exp(attention_score, out=attention_score)
cupy.sum(attention_score, axis=-2, out=temp_attn_mx, keepdims=True)
attention_score /= temp_attn_mx
del temp_attn_mx
# Calculsoftmax*V
out_raw = allocator.alloc_array((batch_size, self.num_heads, self.dim_qkv, 1), dtype=cupy.float16)
fgemm( # Toujours utiliséfloat gemm
allocator,
attention_score.reshape(batch_size * self.num_heads, past_kv_len, 1),
False,
past_kv[1].reshape(batch_size * self.num_heads, self.dim_qkv, past_kv_len),
False,
out_raw.reshape(batch_size * self.num_heads, self.dim_qkv, 1)
)
assert out_raw._c_contiguous
# Je l'ai.softmax(qk)*vRésultats
out = cupy.ndarray((batch_size, self.num_heads * self.dim_qkv), dtype=cupy.float16, memptr=out_raw.data)
del attention_score
del out_raw
# Le vecteur de résultat de l'attention continue de quantifier , Pour le faire à nouveau linear
# (batch_size, num_heads * dim_qkv, 1), (batch_size, 1, 1)
out_i8, scale = self.quantize(allocator, out, axis=1)
project_out_i32 = allocator.alloc_array((batch_size, dim_model, 1), dtype=cupy.int32)
# Refaire avant la sortie linear projection(igemm)
igemm(
allocator,
self.w_out.value[cupy.newaxis], # (1, dim_in, dim_qkv * num_heads)
True,
out_i8[cupy.newaxis],
False,
project_out_i32[cupy.newaxis, :, :, 0]
)
assert project_out_i32._c_contiguous
# (batch, dim_model, 1)
project_out_f16 = allocator.alloc_array(project_out_i32.shape, dtype=cupy.float16)
# La contre - quantification donne le résultat final de l'attention fp16
elementwise_copy_scale(
project_out_i32,
self.w_out_scale.value, # (1#batch_size, dim_model, 1)
scale[:, :, cupy.newaxis], # (batch, 1, 1)
out=project_out_f16
)
return project_out_f16[:, :, 0] # (batch, dim_model)
- Résumé des codes ci - dessus :Comme vous pouvez le voir, c'est principalement vrailinear Quantifier ,Autresnorm、score、softmax Tout est là. float16Calcul supérieur;Tout le processus estint、floatUtilisation alternative,Quantification、 Utilisation alternative de la contre - quantification
- igemmFonctions:cupyComment fairecuda Multiplier la matrice entière sur ,C'est basé surcuda Écrivez les spécifications.
def _igemm(allocator : Allocator, a, aT, b, bT, c, device, stream):
assert isinstance(a, cupy.ndarray)
assert isinstance(b, cupy.ndarray)
assert isinstance(c, cupy.ndarray)
assert len(a.shape) == 3 # (batch, m, k)
assert len(b.shape) == 3 # (batch, n, k)
assert len(c.shape) == 3 # (batch, n, m)
assert a._c_contiguous
assert b._c_contiguous
assert c._c_contiguous
assert a.device == device
assert b.device == device
assert c.device == device
lthandle = get_handle(device) # Pour le momentgpuCréationhandler
# Accèsbatch_size
num_batch = 1
if a.shape[0] > 1 and b.shape[0] > 1:
assert a.shape[0] == b.shape[0]
num_batch = a.shape[0]
elif a.shape[0] > 1:
num_batch = a.shape[0]
else:
num_batch = b.shape[0]
# Calculstride,batch Échantillon de travée interne
if a.shape[0] == 1:
stride_a = 0
else:
stride_a = a.shape[1] * a.shape[2] # m*k
if b.shape[0] == 1:
stride_b = 0
else:
stride_b = b.shape[1] * b.shape[2] # n*k
if aT: # Besoin de transposition ;aTEn généralTrue
m, k1 = a.shape[1:] # a [bs,m,k1]
else:
k1, m = a.shape[1:]
if bT:
k2, n = b.shape[1:]
else: # bTEn généralFalse
n, k2 = b.shape[1:] # b [bs,n,k]
assert k1 == k2 # a*b => k La taille de la dimension doit être la même
k = k1
assert c.shape == (num_batch, n, m) # c = a*b
stride_c = n * m
## compute capability: cudaVersion
# Ampere >= 80
# Turing >= 75
cc = int(device.compute_capability)
v1 = ctypes.c_int(1) # Définir une constante1, Suite donnée CUDA Facteur requis par la spécification
v0 = ctypes.c_int(0) # Définir une constante0
""" # Paramètresa/b/c 3 Propriétés des matrices (rt, m, n, ld, order, batch_count, batch_offset)=> MatrixLayout_tPointeur # LayoutCache Utilisé pour créer la représentation d'une matrice dans la mémoire explicite (C'est - à - dire:layout),Inclure les types de données,Nombre de lignes、Nombre de colonnes,batchTaille, Ordre de stockage de la mémoire (order, Inclure le mode de stockage des colonnes 、 Mode de stockage en ligne, etc. )... # cublasLtC'est le chargementcudaSous le Répertoire d'installationcublast libJe l'ai.; # Ce qui suit concerne: cublasLtFonction de,Veuillez passer à l'étape suivante pour plus de détailsbminfCode source etcudaOfficiellementdocVoir ============================================================ class LayoutCache(HandleCache): # Dans le Codelayoutcache(...)Appellecreate,Et renvoie le pointeur def create(self, rt, m, n, ld, order, batch_count, batch_offset): # Créer une nouvelle matricelayoutPointeur ret = cublasLt.cublasLtMatrixLayout_t() # Le pointeur ci - dessus pointe vers la nouvelle matrice layout;rt-Type de données;m/nÇa veut direrow/col;ld-leading_dimension Nombre de lignes en mode colonne ;checkCublasStatus Vérifier le succès de l'opération en fonction de l'état de retour cublasLt.checkCublasStatus( cublasLt.cublasLtMatrixLayoutCreate(ret, rt, m, n, ld) ) # Définir les propriétés du format de stockage de la matrice cublasLt.checkCublasStatus( cublasLt.cublasLtMatrixLayoutSetAttribute(ret, cublasLt.CUBLASLT_MATRIX_LAYOUT_ORDER, ctypes.byref(ctypes.c_int32(order)), ctypes.sizeof(ctypes.c_int32)) ) # Définir la matrice batch_countPropriétés(batch Nombre d'échantillons internes ) cublasLt.checkCublasStatus( cublasLt.cublasLtMatrixLayoutSetAttribute(ret, cublasLt.CUBLASLT_MATRIX_LAYOUT_BATCH_COUNT, ctypes.byref(ctypes.c_int32(batch_count)), ctypes.sizeof(ctypes.c_int32)) ) cublasLt.checkCublasStatus( cublasLt.cublasLtMatrixLayoutSetAttribute(ret, cublasLt.CUBLASLT_MATRIX_LAYOUT_STRIDED_BATCH_OFFSET, ctypes.byref(ctypes.c_int64(batch_offset)), ctypes.sizeof(ctypes.c_int64)) ) return ret # Libérer l'espace d'affichage occupé après utilisation def release(self, x): cublasLt.checkCublasStatus(cublasLt.cublasLtMatrixLayoutDestroy(x)) ============================================================ # Notez ce qui suit Représentation row=shape[2], col=shape[1], Contrairement à la réalité ; C'est ce qu'il dit. , C'est pour comparer cudaFaire correspondre;Pourcc>=75De, Ça passera quand même. transformRetour en arrièrerow=shape[1], col=shape[2];Voir ci - dessous """
layout_a = layout_cache(cublasLt.CUDA_R_8I, a.shape[2], a.shape[1], a.shape[2], cublasLt.CUBLASLT_ORDER_COL, a.shape[0], stride_a) # a- Oui.int8+Colonnes Stockage
layout_b = layout_cache(cublasLt.CUDA_R_8I, b.shape[2], b.shape[1], b.shape[2], cublasLt.CUBLASLT_ORDER_COL, b.shape[0], stride_b) # b- Oui.int8+Colonnes Stockage
layout_c = layout_cache(cublasLt.CUDA_R_32I, c.shape[2], c.shape[1], c.shape[2], cublasLt.CUBLASLT_ORDER_COL, c.shape[0], stride_c) # c- Oui.int32+Colonnes Stockage
if cc >= 75:
# use tensor core
trans_lda = 32 * m # leading dimension of a
if cc >= 80:
trans_ldb = 32 * round_up(n, 32) # round_upC'est exact.nArrondi À 32Multiple de,Par exemple:28->32, 39->64
else:
trans_ldb = 32 * round_up(n, 8)
trans_ldc = 32 * m
stride_trans_a = round_up(k, 32) // 32 * trans_lda # (「k」// 32) * 32 * m >= k*m Prends - le. QueaMoyenne1Échantillons Plus gros. 32 Espace multiple ,Par exemple:k=40->k=64 => stride_trans_a=64*m
stride_trans_b = round_up(k, 32) // 32 * trans_ldb
stride_trans_c = round_up(n, 32) // 32 * trans_ldc
trans_a = allocator.alloc( stride_trans_a * a.shape[0] ) # Rapport de distributionaPlus gros.32 Espace multiple ,Attention, parce que c'estint8(1Octets), Donc la taille de l'espace =Nombre d'éléments
trans_b = allocator.alloc( stride_trans_b * b.shape[0] )
trans_c = allocator.alloc( ctypes.sizeof(ctypes.c_int32) * stride_trans_c * c.shape[0] ) # Attention, oui.int32,Non, pas du tout.int8
# Créationtrans_a/b/cDelayout
layout_trans_a = layout_cache(cublasLt.CUDA_R_8I, m, k, trans_lda, cublasLt.CUBLASLT_ORDER_COL32, a.shape[0], stride_trans_a)
if cc >= 80:
layout_trans_b = layout_cache(cublasLt.CUDA_R_8I, n, k, trans_ldb, cublasLt.CUBLASLT_ORDER_COL32_2R_4R4, b.shape[0], stride_trans_b) # Utilisez desCOLMode de stockage
else:
layout_trans_b = layout_cache(cublasLt.CUDA_R_8I, n, k, trans_ldb, cublasLt.CUBLASLT_ORDER_COL4_4R2_8C, b.shape[0], stride_trans_b)
layout_trans_c = layout_cache(cublasLt.CUDA_R_32I, m, n, trans_ldc, cublasLt.CUBLASLT_ORDER_COL32, num_batch, stride_trans_c)
# CréationaDetranform descriptorEt la mise en placetransposePropriétés(Comme ci - dessus.layout,DeCUDAExigences de spécification),Retourdescriptor;transform Les principaux attributs sont le type de données , Transposition, etc.
# Notez que le type de données utilisé est INT32,Parce quetransform L'opération multiplie l'entrée par un facteur ( Il s'agit du type entier défini ci - dessus v1/v0), Les deux types doivent correspondre , Donc Laissez l'entrée de INT8->INT32, Laisser le calcul terminé INT32->INT8( Voir utilisation ci - dessous )
transform_desc_a = transform_cache(cublasLt.CUDA_R_32I, aT)
transform_desc_b = transform_cache(cublasLt.CUDA_R_32I, not bT)
transform_desc_c = transform_cache(cublasLt.CUDA_R_32I, False)
""" # CréationCUDAFonctionscublasLtMatrixTransform(CUDA Ne peut pas simplement passer par un a.TLaisse tomber.aTransposition, Nécessite des spécifications plus complexes ) cublasLtMatrixTransform = LibFunction(lib, "cublasLtMatrixTransform", cublasLtHandle_t, cublasLtMatrixTransformDesc_t, ctypes.c_void_p, ctypes.c_void_p, cublasLtMatrixLayout_t, ctypes.c_void_p, ctypes.c_void_p, cublasLtMatrixLayout_t, ctypes.c_void_p, cublasLtMatrixLayout_t, cudaStream_t, cublasStatus_t) # cublasLtMatrixTransform() => C = alpha*transformation(A) + beta*transformation(B) Opération de transformation de matrice cublasStatus_t cublasLtMatrixTransform( cublasLtHandle_t lightHandle, cublasLtMatrixTransformDesc_t transformDesc, const void *alpha, # En général1 const void *A, cublasLtMatrixLayout_t Adesc, const void *beta, # En général0,En ce moment C=transform(A) const void *B, cublasLtMatrixLayout_t Bdesc, void *C, cublasLtMatrixLayout_t Cdesc, cudaStream_t stream); """
cublasLt.checkCublasStatus(
cublasLt.cublasLtMatrixTransform( # C'est exact.a Effectuer une opération de transformation ( La transformation définie ci - dessus est 32I Et aT)
lthandle, transform_desc_a,
ctypes.byref(v1), a.data.ptr, layout_a,
ctypes.byref(v0), 0, 0, # Non utiliséB
trans_a.ptr, layout_trans_a, stream.ptr
)
)
cublasLt.checkCublasStatus(
cublasLt.cublasLtMatrixTransform( # C'est exact.b Effectuer une opération de transformation ( La transformation définie ci - dessus est 32I Et not bT)
lthandle, transform_desc_b,
ctypes.byref(v1), b.data.ptr, layout_b,
ctypes.byref(v0), 0, 0,
trans_b.ptr, layout_trans_b, stream.ptr
)
)
if a.shape[0] != num_batch:
layout_trans_a = layout_cache(cublasLt.CUDA_R_8I, m, k, trans_lda, cublasLt.CUBLASLT_ORDER_COL32, num_batch, 0)
if b.shape[0] != num_batch:
if cc >= 80:
layout_trans_b = layout_cache(cublasLt.CUDA_R_8I, n, k, trans_ldb, cublasLt.CUBLASLT_ORDER_COL32_2R_4R4, num_batch, 0)
else:
layout_trans_b = layout_cache(cublasLt.CUDA_R_8I, n, k, trans_ldb, cublasLt.CUBLASLT_ORDER_COL4_4R2_8C, num_batch, 0)
# CréationmatmulDescripteur: Type de données intermédiaires ,Type de calcul(Type d'entrée / sortie),aT,bT
# UtiliserINT32EnregistrerINT8Résultats des calculs; Les deux derniers paramètres représentent a/b Transposition
matmul_desc = matmul_cache(cublasLt.CUDA_R_32I, cublasLt.CUBLAS_COMPUTE_32I, False, True)
""" # Calcul D = alpha*(A*B) + beta*(C) cublasStatus_t cublasLtMatmul( cublasLtHandle_t lightHandle, cublasLtMatmulDesc_t computeDesc, const void *alpha, const void *A, cublasLtMatrixLayout_t Adesc, const void *B, cublasLtMatrixLayout_t Bdesc, const void *beta, const void *C, cublasLtMatrixLayout_t Cdesc, void *D, cublasLtMatrixLayout_t Ddesc, const cublasLtMatmulAlgo_t *algo, void *workspace, size_t workspaceSizeInBytes, cudaStream_t stream); """
cublasLt.checkCublasStatus( cublasLt.cublasLtMatmul(
lthandle, # gpuPoignée
matmul_desc,
ctypes.byref(ctypes.c_int32(1)), # alpha=1
trans_a.ptr, # aDonnées
layout_trans_a, # aFormat
trans_b.ptr,
layout_trans_b,
ctypes.byref(ctypes.c_int32(0)), # beta=0,Non.COffset,C'est - à - dire:D = alpha*(A*B)
trans_c.ptr, # Non utilisé
layout_trans_c, # Non utilisé
trans_c.ptr, # DC'est - à - dire:C,De in-place(Remplacer en place)
layout_trans_c,
0,
0,
0,
stream.ptr
))
cublasLt.checkCublasStatus(
cublasLt.cublasLtMatrixTransform( # Selontransform_desc_cLes résultatsCFais - le une foistransform(int32,Pas de transposition)
lthandle, transform_desc_c,
ctypes.byref(v1), trans_c.ptr, layout_trans_c,
ctypes.byref(v0), 0, 0,
c.data.ptr, layout_c,
stream.ptr
)
)
else:
pass # La différence entre ici et ci - dessus est Utiliser les anciennes versionscuda, Par conséquent, l'omission n'est plus nécessaire. , Si vous êtes intéressé, vérifiez le code source vous - même
Résumé
- Ce qui précède concerneBMINF Analyse des codes d'implémentation quantifiés , Pour apprendre à quantifier +cupy+cuda(Plus précisément:cublasLt)Réalisation;
- Le Code n'implémente que la quantification symétrique la plus simple ;Utilisercupy+cublasLt Réalisation de la quantification de la couche linéaire ; Tout le processus est quantifié et contre - quantifié ,intEtfloat Utilisation alternative de ;
- Du processus décrit ci - dessus C++ La version est également appelée cublasLt Même fonction ,C'est similaire.,Intéressé à voirNVIDIAExemple-LtIgemmTensor
- Ce qui précède ne concerne que CUDA/cublasLtApplication partielle de, Pour plus d'applications, voir CUDAManuel officiel;
- C'est une omission.,Je vous en prie.
边栏推荐
- LeetCode:221. 最大正方形
- Warning in install. packages : package ‘RGtk2’ is not available for this version of R
- TDengine 社区问题双周精选 | 第三期
- SAP ui5 date type sap ui. model. type. Analysis of the parsing format of date
- MongoDB 的安装和基本操作
- LeetCode:34. Find the first and last positions of elements in a sorted array
- I-BERT
- [OC-Foundation框架]--<Copy对象复制>
- LeetCode:394. 字符串解码
- LeetCode:剑指 Offer 04. 二维数组中的查找
猜你喜欢
After PCD is converted to ply, it cannot be opened in meshlab, prompting error details: ignored EOF

Using pkgbuild:: find in R language_ Rtools check whether rtools is available and use sys The which function checks whether make exists, installs it if not, and binds R and rtools with the writelines
TCP/IP协议
多元聚类分析

企微服务商平台收费接口对接教程

LeetCode:221. 最大正方形
BMINF的後訓練量化實現
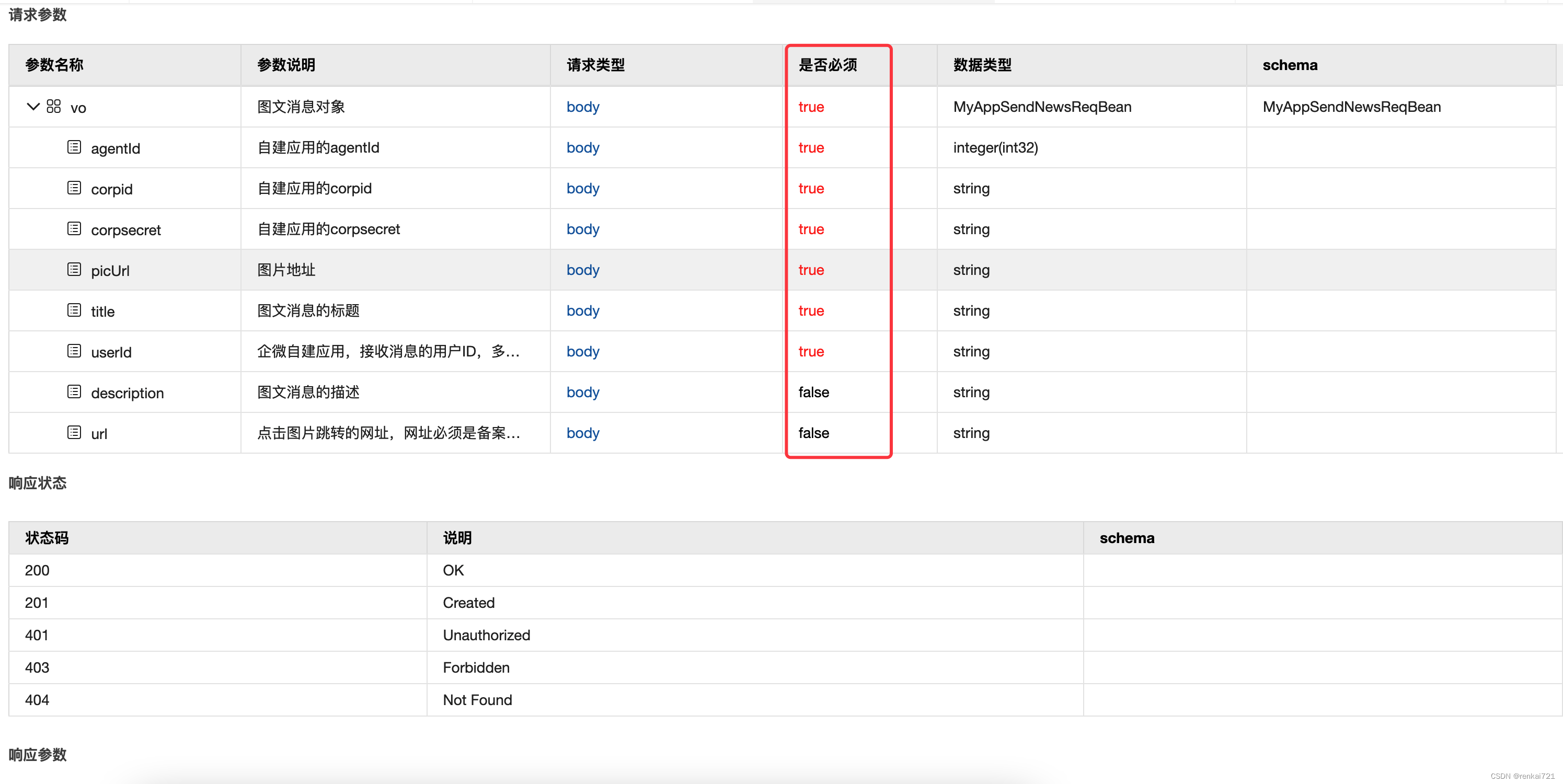
swagger设置字段required必填
![[OC]-<UI入门>--常用控件的学习](/img/2c/d317166e90e1efb142b11d4ed9acb7.png)
[OC]-<UI入门>--常用控件的学习
Warning in install. packages : package ‘RGtk2’ is not available for this version of R
随机推荐
LeetCode:剑指 Offer 03. 数组中重复的数字
Problems encountered in connecting the database of the project and their solutions
[NVIDIA development board] FAQ (updated from time to time)
Promise 在uniapp的简单使用
Shift Operators
Compétences en mémoire des graphiques UML
Visual implementation and inspection of visdom
Intel Distiller工具包-量化实现3
Cesium draw points, lines, and faces
企微服务商平台收费接口对接教程
[OC-Foundation框架]-<字符串And日期与时间>
LeetCode:26. 删除有序数组中的重复项
UML diagram memory skills
LeetCode:387. The first unique character in the string
The harm of game unpacking and the importance of resource encryption
Generator parameters incoming parameters
Tdengine biweekly selection of community issues | phase III
Esp8266-rtos IOT development
MYSQL卸载方法与安装方法
LeetCode:剑指 Offer 04. 二维数组中的查找