当前位置:网站首页>自定义卷积注意力算子的CUDA实现
自定义卷积注意力算子的CUDA实现
2022-07-06 08:51:00 【cyz0202】
参考文献:fairseq
背景
我们在上面这篇文章讲到了设计适当的卷积来替代注意力机制
最终设计的卷积如下

其中 , 且有
, 且有 ;c代表d这个维度;
;c代表d这个维度;
要实现这样的卷积,有一种折中的方式是,令

 的具体设计请参考上述文章,此处不再赘述;
的具体设计请参考上述文章,此处不再赘述;
为了更高效的实现这样的卷积,考虑对该自定义卷积算子进行CUDA实现;
方案
CUDA 实现自定义卷积一般需要几个固定的步骤,在 CUDA实现focal_loss 这篇文章中详细说明了;这里引用一张图,如下
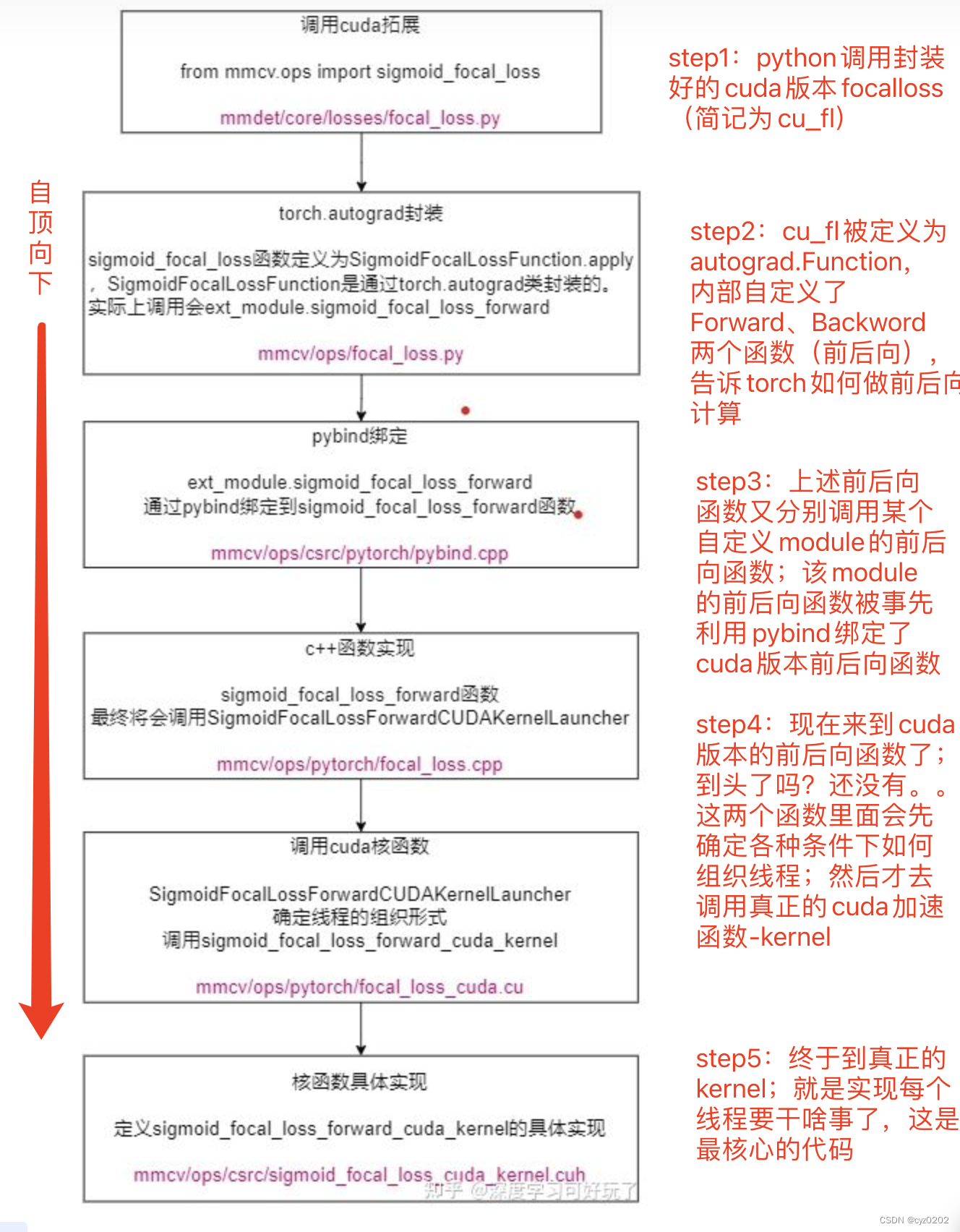
这里CUDA实现自定义卷积算子的步骤和上面差不多,最大的区别是 step4/5,尤其是step5的kernel设计;
以下大致介绍step5的kernel实现方法,其他step不再赘述
kernel实现
kernel实现分为forward和backward两步;
forward实现
先来看forward;以下代码是调用forward kernel的入口代码
std::vector <at::Tensor> conv_cuda_forward(at::Tensor input, at::Tensor filters, int padding_l) {
at::DeviceGuard g(input.device());
const auto minibatch = input.size(0); // batch size
const auto numFeatures = input.size(1); // dim(d)
const auto sequenceLength = input.size(2); // seq_len
const auto numHeads = filters.size(0); // H
const auto filterSize = filters.size(1); // K
const auto numFiltersInBlock = numFeatures / numHeads; // d/H
const dim3 blocks(minibatch, numFeatures); // block大小 (batch,dim)
auto output = at::zeros_like(input); // 和input一样大小 (b, d, n)
auto stream = at::cuda::getCurrentCUDAStream();
if (sequenceLength <= 32) {
switch (filterSize) {
/* 注意:
* 实践中 filtersize in [3, 7, 15, 31, 31, 31, 31]
* 且 padding_l = filtersize - 1
* */
case 3:
if (padding_l == 1) {
/*
* 这个宏是个带参宏,替换了一个匿名函数;匿名函数的功能是对传入的第一个参数做类型枚举,
* 如果是at::ScalarType::Double,就用double代替scalar_t,如果是at::ScalarType::Float,就用float代替,
* 如果是at::ScalarType::Half,就用at::Half代替,然后最后返回__VA_ARGS__();
* __VA_ARGS__()代表宏的第三个参数,一般是另一个匿名函数;
* 也就是判断完枚举类型并对scalar_t赋值后(即上面的替代),调用参数3的匿名函数进行计算并返回最终结果;
* */
AT_DISPATCH_FLOATING_TYPES_AND_HALF(
input.scalar_type(), // 对这个数据类型进行枚举,替换后赋值scalar_t
"conv_forward",
([&] {
conv_forward_kernel<3, 32, 1, scalar_t> // template赋值
<<<blocks, 32, 0, stream>>>( // (grid、block、share_mem、stream)
input.data<scalar_t>(),
filters.data<scalar_t>(),
minibatch,
sequenceLength, // SB>=sequenceLength
numFeatures,
numFiltersInBlock,
output.data<scalar_t>());
}
)
);
}
else if (padding_l == 2) {
AT_DISPATCH_FLOATING_TYPES_AND_HALF(input.scalar_type(), "conv_forward", ([&] {
conv_forward_kernel<3, 32, 2, scalar_t> // template赋值
<<<blocks, 32, 0, stream>>>( // (grid、block、share_mem、stream)
input.data<scalar_t>(), // b*d*n
filters.data<scalar_t>(), // H*k
minibatch, // b or batch_size
sequenceLength, // n; 一般SB>=sequenceLength
numFeatures, // d
numFiltersInBlock, // d/H
output.data<scalar_t>()); // b*d*n
}));
} else {
std::cout << "WARNING: Unsupported padding size - skipping forward pass" << std::endl;
}
break;
/*
* 以下内容和上面case差不多,就不再展示了
*/上述代码段的核心内容是 AT_DISPATHC_FLOATING_TYPES_AND_HALF 及其内部调用的 conv_forward_kernel;
AT_DISPATHC_FLOATING_TYPES_AND_HALF的作用就是执行 input.scalar_type() => scalar_t;
conv_forward_kernel<3, 32, 2, scalar_t> 是函数模版赋值,分别代表filter_size & seq_bound & padding_l & data_type
<<<blocks, 32, 0, stream>>> 代表 grid & block & share_memory & stream;
这里blocks是 batch_size * hidden_size;即grid由batch_size*hidden_size个blcoks组成;
32则代表1个block内线程数;结合blocks的定义,可知每个block处理一个某个序列的某层hidden数据;
0应该是不使用share memory(未确定),stream就是cuda stream;
下面具体看看conv_forward_kernel的定义;功能的代码注释较为清晰,就不再赘述了;
template<int FS, int SB, int padding_l, typename scalar_t>
__global__
void conv_forward_kernel(const scalar_t *input,
const scalar_t *filters,
int minibatch, int sequenceLength,
int numFeatures, int numFiltersInBlock,
scalar_t *output) {
// 根据grid=(batch,dim)的定义,可知每个block计算某个样本各个位置上相同的feature
// 如batchIdx=3,featureIdx=3,则tid遍历第3个样本整个序列各个位置的featureIdx=3
// 符合conv算子的设置:每次对整个序列相同channel的计算
const int tid = threadIdx.x; // 这里在seq上各个位置的相同featureIdx进行并行
const int batchIdx = blockIdx.x; // batch
const int featureIdx = blockIdx.y; // dim,亦即channel
const int filterIdx = featureIdx / numFiltersInBlock; // cH/d W应该使用第几行参数
// 由于cuda的存储是指针形式的,所以需要计算偏移量(b*d*n)
const int IOOffset = numFeatures * sequenceLength * batchIdx +
featureIdx * sequenceLength; // 处理位置
const scalar_t *inputFeature = &input[IOOffset]; // 按行展开的input是个一维数组
scalar_t *outputFeature = &output[IOOffset];
const scalar_t *inputFilter = &filters[filterIdx * FS]; // H*k中的某一行;注意filter是n*n
// block只有一维,一般就是SB,如32,64
assert(blockDim.x == SB); // block_x大小,要等于seq_len
scalar_t filter[FS]; // 存储filter参数
#pragma unroll // 循环展开
for (int i = 0; i < FS; ++i) {
filter[i] = inputFilter[i]; // 当前使用的卷积行
}
/* 数组:序列长度+filter大小
* 注意是线程块的内部共享存储器;所有tid只有一份
* */
__shared__ scalar_t temp[SB + FS];
/*
* 这里处理tid索引不到的地方;或者说每个tid只用来将输入每个位置一一映射到temp相应位置;
* temp其他位置要事先处理;即先进行 滑动窗口需要的 补0 操作
* 注:根据padding_l的不同设置,temp填充方式不同
* 默认是padding_l=fs-1,比如fs=5,padding_l=4,即左侧填充4个0;
* temp最后一个位置再填充1个0
*/
zeroSharedMem<FS, SB, padding_l>(temp);
/* 一般SB>sequenceLength,所以numIterations=1
* 特殊情况 if sequenceLength>512 numIterations=2
*/
const int numIterations = divUp<int, int>(sequenceLength, SB);
/*
* 一般numIterations=1
* 特殊情况,如sequenceLength>512(e.g 1024),SB=512
*/
for (int i = 0; i < numIterations; ++i) { // 太长序列需要分块处理,因为block=SB
const int inputOffset = i * SB;
/* 要计算的输入移到share memory;此外根据seq_len进行更多置0
* 具体来说,就是从fs-1开始填充真实输入序列;超过真实序列长度时,填充0
* 填充结果放到temp里面(temp大小为SB+FS)
* fs=5时,最终temp大致是这样的:[0,0,0,0,10,20,30,40,50,60,70,80,0,0,0,0,0,0,0,...]
* output[tid + padding_l] =
* ((inputOffset + tid) < sequenceLength) ? input[inputOffset + tid] : scalar_t(0.0);
* */
load_input_to_shared<FS, SB, padding_l>(inputFeature, inputOffset,
sequenceLength,i, numIterations,
(numIterations == 1),
temp);
/* 同步,等待当前block所有tid执行完毕
* 每个tid负责一个位置,所以要等待所有tid把temp填充好
* */
__syncthreads();
scalar_t out = 0; // 每个tid一个out
#pragma unroll // 循环展开
for (int j = 0; j < FS; ++j) {
/* 上面同步tid填充好temp后,就可以计算每个tid对应位置的卷积了
* 从这里可知,temp是用来填充满足filter.dot(input)的计算的
* tid=0时,下列计算展开是:
* out0 = filter[0]*temp[0]+...+filter[fs-1]*temp[fs-1]
* 注意到temp[fs-1]是输入的第一个值,非0;而temp左侧fs-1个数进行0填充了
* tid=1时,下列计算展开是:
* out1 = filter[0]*temp[1]+...+filter[fs-1]*temp[1+fs-1]
* 此时temp[fs-1]、temp[1+fs-1]有值,非0;
* 其他tid做的事相当于滑动filter窗口进行加权求和;
*/
out += filter[j] * temp[tid + j];
}
// Write output
const int outputOffset = inputOffset;
if ((outputOffset + tid) < sequenceLength) {
/*
* 注意output和input shape一样,outputFeature取决于当前block在grid的位置偏移
*
*/
outputFeature[outputOffset + tid] = out;
}
// 同步
__syncthreads();
}
}backwrad实现
以下是backward kernel的入口实现
std::vector<at::Tensor> conv_cuda_backward(
at::Tensor gradOutput,
int padding_l,
at::Tensor input,
at::Tensor filters) {
// gradWrtInput
const int minibatch = input.size(0); // batch(b)
const int numFeatures = input.size(1); // d
const int sequenceLength = input.size(2); // seq_len
const int numHeads = filters.size(0); // H
const int filterSize = filters.size(1); // k
const dim3 gradBlocks(minibatch, numFeatures); // (b, d)
const dim3 weightGradFirstpassShortBlocks(minibatch, numHeads); //(b,H)
const dim3 weightGradSecondpassBlocks(numHeads, filterSize); // (H,k)
const int numFiltersInBlock = numFeatures / numHeads; // d/H
auto gradInput = at::zeros_like(input);
auto gradFilters = at::zeros_like(filters);
at::DeviceGuard g(input.device());
auto stream = at::cuda::getCurrentCUDAStream();
switch (filterSize) {
case 3:
// 序列长度 <= 32 的情况
if (sequenceLength <= 32) {
if (padding_l == 1) {
/*
* 此处实现类似下方padding_l==2(实际使用部分),考虑空间不再展示
*/
} else if (padding_l == 2) {
AT_DISPATCH_FLOATING_TYPES_AND_HALF(input.scalar_type(), "conv_backward", ([&] {
// 计算输入梯度
conv_grad_wrt_input_kernel<3, 32, 2, scalar_t>
<<<gradBlocks, 32, 0, stream>>>(
gradOutput.data<scalar_t>(),
filters.data<scalar_t>(),
minibatch,
sequenceLength,
numFeatures,
numFiltersInBlock,
gradInput.data<scalar_t>()
);
at::Tensor tempSumGradFilters = at::zeros({minibatch, numHeads, filterSize},
input.options().dtype(at::kFloat));
// 计算权重梯度 第一轮
conv_grad_wrt_weights_firstpass_short_kernel<3, 32, 2, scalar_t>
<<<weightGradFirstpassShortBlocks, 32, 0, stream>>>(
input.data<scalar_t>(),
gradOutput.data<scalar_t>(),
minibatch,
sequenceLength,
numFeatures,
numFiltersInBlock,
numHeads,
tempSumGradFilters.data<float>()
);
// 计算权重梯度 第二轮
conv_grad_wrt_weights_secondpass_short_kernel<3, 32, scalar_t>
<<<weightGradSecondpassBlocks, 32, 0, stream>>>(
tempSumGradFilters.data<float>(),
minibatch,
numFiltersInBlock,
gradFilters.data<scalar_t>()
);
}));
} else {
std::cout << "WARNING: Unsupported padding size - skipping backward pass" << std::endl;
}
// 序列长度 > 32 的情况
} else if (padding_l == 1) {
/*类似下方代码,一般不使用,故不展示*/
} else if (padding_l == 2) {
AT_DISPATCH_FLOATING_TYPES_AND_HALF(input.scalar_type(), "conv_backward", ([&] {
conv_grad_wrt_input_kernel<3, 32, 2, scalar_t>
<<<gradBlocks, 32, 0, stream>>>(
gradOutput.data<scalar_t>(),
filters.data<scalar_t>(),
minibatch,
sequenceLength,
numFeatures,
numFiltersInBlock,
gradInput.data<scalar_t>());
at::Tensor tempSumGradFilters = at::zeros({minibatch, numFeatures, filterSize},
input.options().dtype(at::kFloat));
conv_grad_wrt_weights_firstpass_kernel<3, 32, 2, scalar_t>
<<<gradBlocks, 32, 0, stream>>>(
input.data<scalar_t>(),
gradOutput.data<scalar_t>(),
minibatch,
sequenceLength,
numFeatures,
numFiltersInBlock,
tempSumGradFilters.data<float>()
);
conv_grad_wrt_weights_secondpass_kernel<3, 32, scalar_t>
<<<weightGradSecondpassBlocks, 32, 0, stream>>>(
tempSumGradFilters.data<float>(),
minibatch,
numFiltersInBlock,
gradFilters.data<scalar_t>()
);
}));
} else {
std::cout << "WARNING: Unsupported padding size - skipping backward pass" << std::endl;
}
break;
/*
* 以下内容和上面差不多,不再展示
*/此处以 filter_size = 3,seq_len <= 32,padding_l = 2的设置讲解如何实现反向过程;
且当前只讲解 对输入的梯度求导过程(较简单);权重的后向(稍复杂)后续再继续讲解;
再展示一下输入的反向过程入口代码:
// 计算输入梯度
conv_grad_wrt_input_kernel<3, 32, 2, scalar_t>
<<<gradBlocks, 32, 0, stream>>>(
gradOutput.data<scalar_t>(),
filters.data<scalar_t>(),
minibatch,
sequenceLength,
numFeatures,
numFiltersInBlock,
gradInput.data<scalar_t>()
);conv_grad_wrt_input_kernel<3, 32, 2, scalar_t> 是输入反向函数模版赋值,分别代表filter_size & seq_bound & padding_l & data_type
<<<gradBlocks, 32, 0, stream>>> 代表 grid & block & share_memory & stream;
这里gradBlocks(见代码)是 batch_size * hidden_size;即grid由batch_size*hidden_size个blcoks组成;
32则代表1个block内线程数;结合blocks的定义,可知每个block处理一个某个序列的某层hidden数据;
0应该是不使用share memory(未确定),stream就是cuda stream;
以上和forward过程很像,实际上,此处输入的后向过程和前向过程确实很相似;
因为输入在前向过程中 干的事 就是简单地 和filter(一个滑动窗口)进行相乘累加;所以后向过程也是一个简单的相乘累加;从实现代码来看,就会显得很相似;
上述前后向过程的数学表示如下(以padding_l=fs-1为例), 和
和 是梯度
是梯度


可以发现前后向过程确实在形式上很相似;实现代码如下
template<int FS, int SB, int padding_l, typename scalar_t>
__global__
void conv_grad_wrt_input_kernel(
const scalar_t *input, // gradOutput
const scalar_t *filters,
int minibatch,
int sequenceLength,
int numFeatures,
int numFiltersInBlock,
scalar_t *output) {
// 对输入的求导与前向过程很相似
const int tid = threadIdx.x;
const int batchIdx = blockIdx.x;
const int featureIdx = blockIdx.y;
const int filterIdx = featureIdx / numFiltersInBlock;
const int IOOffset = numFeatures * sequenceLength * batchIdx + featureIdx * sequenceLength;
const scalar_t *inputFeature = &input[IOOffset];
scalar_t *outputFeature = &output[IOOffset];
const scalar_t *inputFilter = &filters[filterIdx * FS];
assert(blockDim.x == SB);
scalar_t filter[FS];
/* 唯一的不同是反向加载filter(filter翻转):此处由梯度推导公式可得
* 想象一下一个滑动窗口向右移动,窗口的不同权重会经过同一个位置的输入,相乘并累加得到不同位置的输出
*/
#pragma unroll
for (int i = 0; i < FS; ++i) {
filter[i] = inputFilter[FS - i - 1]; // inputFilter[i]
}
__shared__ scalar_t temp[SB + FS];
// FS-(paddling_l+1)作为填充,paddling=FS-1时padding=0
const int padding = FS - padding_l - 1;
zeroSharedMem<FS, SB, padding>(temp);
__syncthreads();
const int numIterations = divUp<int, int>(sequenceLength, SB);
for (int i = 0; i < numIterations; ++i) {
// Read input into shared memory
const int inputOffset = i * SB;
load_input_to_shared<FS, SB, padding>(inputFeature, inputOffset, sequenceLength,
i, numIterations, false, temp);
__syncthreads();
scalar_t out = 0;
#pragma unroll
for (int j = 0; j < FS; ++j) {
out += filter[j] * temp[tid + j];
}
// Write output
const int outputOffset = inputOffset;
if ((outputOffset + tid) < sequenceLength) { // 限制tid
outputFeature[outputOffset + tid] = out;
}
__syncthreads();
}
}TODO:权重的反向过程稍复杂,暂且不讲;
总结
- 以上介绍了自定义卷积算子的CUDA实现;
- 介绍了前向过程和部分后向过程的实现,仅供参考;
- 总体上CUDA实现自定义算子有一定的套路;关键点是 kernel的设计,即如何在前后向过程中,充分利用好grid、block进行并行计算以达到最大的加速;这点很重要
- 水平有限,欢迎指正
边栏推荐
- 可变长参数
- LeetCode:221. 最大正方形
- The harm of game unpacking and the importance of resource encryption
- What is the role of automated testing frameworks? Shanghai professional third-party software testing company Amway
- 数学建模2004B题(输电问题)
- The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
- [sword finger offer] serialized binary tree
- Intel Distiller工具包-量化实现1
- 角色动画(Character Animation)的现状与趋势
- 有效提高软件产品质量,就找第三方软件测评机构
猜你喜欢
ROS compilation calls the third-party dynamic library (xxx.so)
Screenshot in win10 system, win+prtsc save location
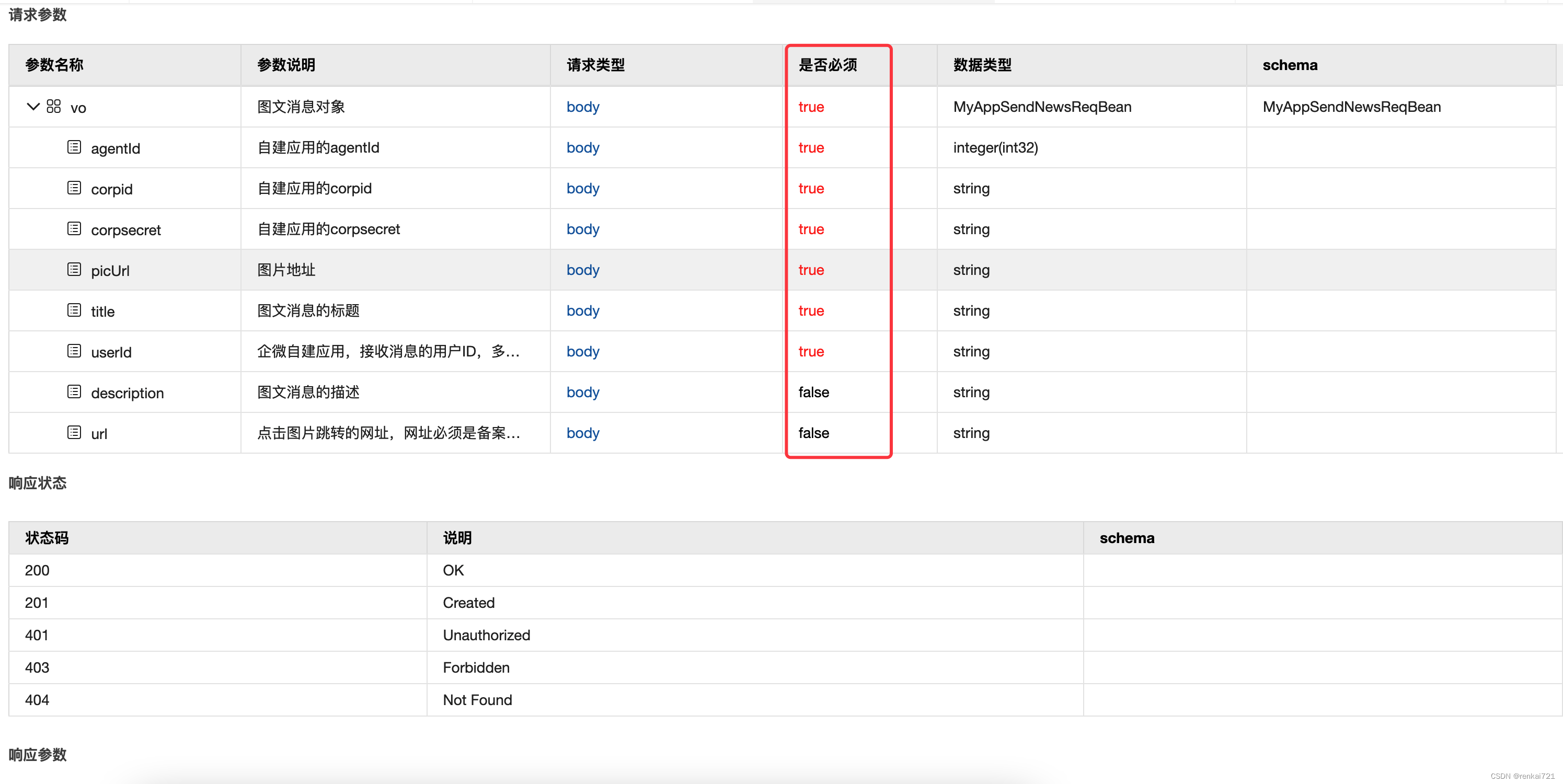
Swagger setting field required is mandatory
Target detection - pytorch uses mobilenet series (V1, V2, V3) to build yolov4 target detection platform
The harm of game unpacking and the importance of resource encryption

Intel Distiller工具包-量化实现2
SAP ui5 date type sap ui. model. type. Analysis of the parsing format of date
![[OC]-<UI入门>--常用控件-提示对话框 And 等待提示器(圈)](/img/af/a44c2845c254e4f48abde013344c2b.png)
[OC]-<UI入门>--常用控件-提示对话框 And 等待提示器(圈)

LeetCode:221. 最大正方形
![[MySQL] limit implements paging](/img/94/2e84a3878e10636460aa0fe0adef67.jpg)
[MySQL] limit implements paging
随机推荐
[OC]-<UI入门>--常用控件-UIButton
Cesium draw points, lines, and faces
TDengine 社区问题双周精选 | 第三期
可变长参数
SAP ui5 date type sap ui. model. type. Analysis of the parsing format of date
opencv+dlib实现给蒙娜丽莎“配”眼镜
poi追加写EXCEL文件
Detailed explanation of heap sorting
Super efficient! The secret of swagger Yapi
The problem and possible causes of the robot's instantaneous return to the origin of the world coordinate during rviz simulation
Unsupported operation exception
Computer graduation design PHP Zhiduo online learning platform
如何有效地进行自动化测试?
Swagger setting field required is mandatory
Marathon envs project environment configuration (strengthen learning and imitate reference actions)
Philosophical enlightenment from single point to distributed
Problems encountered in connecting the database of the project and their solutions
Pytorch view tensor memory size
LeetCode:498. Diagonal traversal
Hutool gracefully parses URL links and obtains parameters