当前位置:网站首页>CUDA realizes focal_ loss
CUDA realizes focal_ loss
2022-07-06 08:56:00 【cyz0202】
Reference from :mmdetection Source code reading :cuda Expanding focal loss - You know
Readers need a general understanding of CUDA Programming and loss function principle ; This article does not give a detailed introduction
CUDA Realize accelerated writing ( tricks )
The pictures are from the above references ( Invasion and deletion ), The red text is my annotation ;
That may still be vague , I'll explain it in detail ;
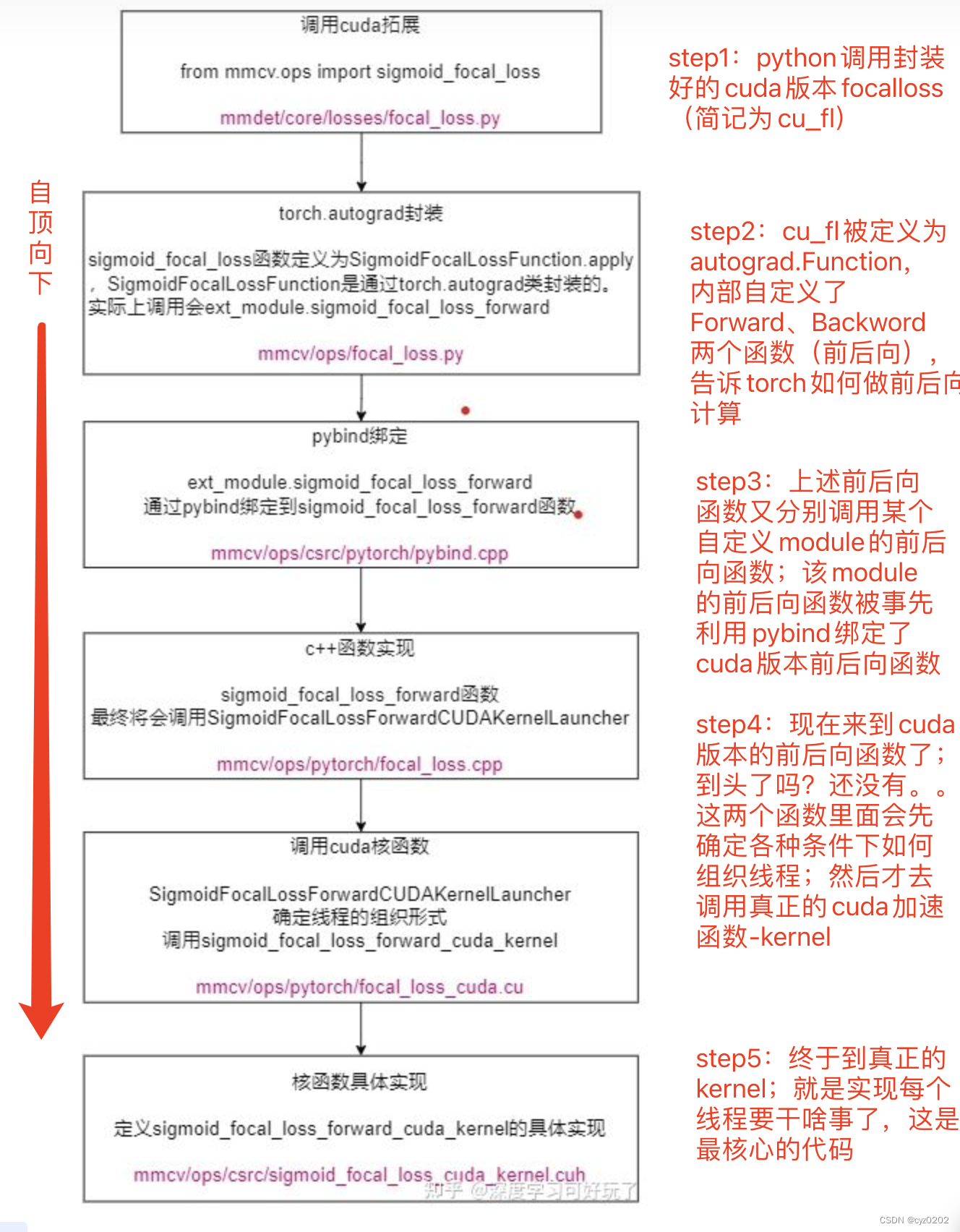
Instance to explain :focal_loss cuda Realization
notes : The code content of this section is from the beginning reference article
step1:python End calls ( The source code in mmdetection tool kit )
- Notice the call _sigmoid_focal_loss( namely sigmoid_focal_loss), This function is essentially right cuda Version of focal_loss Encapsulation of implementation , Let's introduce ;
from mmcv.ops import sigmoid_focal_loss as _sigmoid_focal_loss
# sigmoid_focal_loss In fact, that is SigmoidFocalLossFunction Of forward Method
class FocalLoss(nn.module):
def forward(self,
pred, # tensor(num_total_anchors, num_classes)
target, # tensor(num_total_anchors, )
):
if if torch.cuda.is_available() and pred.is_cuda:
loss = _sigmoid_focal_loss(pred.contiguous(), target.contiguous(), gamma,alpha, None, 'none')
# Be careful to go through contiguous Ensure continuous memory storage ! In this way cuda If the kernel function accesses continuous memory, there will be no error
return lossstep2:autograd.Function Use , Used to specify the forward and backward calculation method ( Why? : We use it cuda Defines an operator , After encapsulation, you need to use autograd Give Way torch Know how to do forward and backward calculation )
- You can see the inheritance Function; Used ext_module( From the next step python-cuda binding ); Used Function.apply()
class SigmoidFocalLossFunction(Function):
@staticmethod
def forward(ctx,
input,
target,
gamma=2.0,
alpha=0.25,
weight=None,
reduction='mean'):
# Storage reduction_dict、gamma wait until ctx, For reverse transmission backward call
ctx.reduction_dict = {'none': 0, 'mean': 1, 'sum': 2}
assert reduction in ctx.reduction_dict.keys()
ctx.gamma = float(gamma)
ctx.alpha = float(alpha)
ctx.reduction = ctx.reduction_dict[reduction]
output = input.new_zeros(input.size()) # open up output Space
# Call the real cuda expand : here ext_module Is used to bind cuda Version of the code
ext_module.sigmoid_focal_loss_forward(input, target, weight, output, gamma=ctx.gamma, alpha=ctx.alpha)
if ctx.reduction == ctx.reduction_dict['mean']:
output = output.sum() / input.size(0)
elif ctx.reduction == ctx.reduction_dict['sum']:
output = output.sum()
ctx.save_for_backward(input, target, weight) # Save variables for reverse calculation
return output
@staticmethod
@once_differentiable
def backward(ctx, grad_output):
input, target, weight = ctx.saved_tensors
grad_input = input.new_zeros(input.size())
# Call the real cuda expand
ext_module.sigmoid_focal_loss_backward(input, target,weight, grad_input, gamma=ctx.gamma, alpha=ctx.alpha)
grad_input *= grad_output
if ctx.reduction == ctx.reduction_dict['mean']:
grad_input /= input.size(0)
return grad_input, None, None, None, None, None
# Definition sigmoid_focal_loss by SigmoidFocalLossFunction.apply,apply Method will call forward
sigmoid_focal_loss = SigmoidFocalLossFunction.applystep3: Use pybind binding python-cuda(c++), To call python Of module To call cuda Function of ;
- This process takes place in c++ Defined in the file ;
- TORCH_EXTENSION_NAME It will correspond to a name you specify , For the above code is ext_module( It can also be called Zhang Sanli Si , This is usually in setup.py Specified in the );
- m Express module,def The first parameter of is the name (name), The second parameter is to be bound c++/cuda function , Here is the ext_module.sigmoid_focal_loss_forward. Bound to the At present c++ File defined sigmoid_focal_loss_forward function ; This function really involves CUDA Accelerated functions ; Let's introduce ;
- def The other parameters of are the parameters of the correlation function , It does not affect the understanding here , Do not go into
sigmoid_focal_loss_forwardThe function will be calledSigmoidFocalLossForwardCUDAKernelLauncherfunction ; See below
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("sigmoid_focal_loss_forward", &sigmoid_focal_loss_forward,
"sigmoid_focal_loss_forward ", py::arg("input"), py::arg("target"),
py::arg("weight"), py::arg("output"), py::arg("gamma"),
py::arg("alpha"));
}
# Empathy sigmoid_focal_loss_backward A little step4:SigmoidFocalLossForwardCUDAKernelLauncher, Set according to various conditions CUDA The organization of threads and other basic settings ( It can be understood as preparing the environment ), Then call the real one. CUDA kernel Calculate the core part ( Here is the focal_loss The calculation of , Really working )
- Launcher This name is more vivid , But readers are elsewhere You may not see Launcher This way of writing , Because this is not a rule ; But there must be related functions to realize this part of the function ;
- Here are c++ Code :
- Get the relevant parameters and make some basic judgments ; Also set the thread organization , Namely <<<a, b>>> Internal a,b
- When the environment is ready , You can call kernel 了 ;
- AT_DISPATCH_FLOATING_TYPES_AND_HALF Is a macro with parameters , The thing to do is to put the first parameter ( data type ) Pass it on to the back scalar_t, And then execute [&]() Anonymous function in brackets ( Namely kernel 了 )
- It was also noted that Tensor Provides
.data_ptr<scalar_t>()Template member function , Will return tensor The first address of continuous storage , And convert toscalar_t *Pointer type of . We know tensor What is really stored in memory is One dimensional continuous array !tensor(B,C,H,W) What is really stored in memory is long B*C*H*W Continuous array of ;data_ptr() What is returned is the first address of this continuous array ;void SigmoidFocalLossForwardCUDAKernelLauncher(Tensor input, Tensor target, Tensor weight, Tensor output, const float gamma, const float alpha) { // input by tensor(num_total_anchors, num_classes) // output by tensor(num_total_anchors, num_classes) // target by tensor(num_total_anchors, ),0 ~ num_class-1 Indicates the category corresponding to the positive sample ,num_class Values represent negative samples and ignored samples int output_size = output.numel(); // be equal to num_total_anchors*num_classes int num_classes = input.size(1); AT_ASSERTM(target.max().item<long>() <= (long)num_classes, "target label should smaller or equal than num classes"); at::cuda::CUDAGuard device_guard(input.device()); cudaStream_t stream = at::cuda::getCurrentCUDAStream(); AT_DISPATCH_FLOATING_TYPES_AND_HALF( input.scalar_type(), "sigmoid_focal_loss_forward_cuda_kernel", [&] { sigmoid_focal_loss_forward_cuda_kernel<scalar_t> //sigmoid_focal_loss_forward_cuda_kernel yes cuda Kernel function , Is defined as a template function , adopt <scalar_t> Determine the data type <<<GET_BLOCKS(output_size), THREADS_PER_BLOCK, 0, stream>>>( output_size, input.data_ptr<scalar_t>(), target.data_ptr<int64_t>(), weight.data_ptr<scalar_t>(), output.data_ptr<scalar_t>(), gamma, alpha, num_classes); }); AT_CUDA_CHECK(cudaGetLastError()); } //backward A little // Here are CUDA Calculate the thread organization that needs to be set , For unfamiliar ones, please refer to CUDA Programming #define THREADS_PER_BLOCK 1024、128、512 inline int GET_BLOCKS(const int N) { int optimal_block_num = (N + THREADS_PER_BLOCK - 1) / THREADS_PER_BLOCK; int max_block_num = 65000; return min(optimal_block_num, max_block_num); } // Get the opened thread block x dimension , bring blockDim.x * gridDim.x To be equal to N
step5:kernel Realization
- This is the real work ; At this time, you have to understand focal_loss Calculation method of , Just know how to write ;( In fact, the above definition <<<a,b>>> Inside a、b When parameters are , We should consider how to write this part )
- First deduce focal_loss Well , The process is as follows

- The next step is to realize ,kernel The content of represents what each thread should do ; Here we need to calculate loss, And it is classified loss; say concretely , Input includes
- pred, It's a tensor,shape by [num_total_anchors, num_classes];
- as well as target, Also a tensor,shape by [num_total_anchors];
- There may be weight, Represents the loss weight of each category ( Some categories are not important , Just give a small weight , In this way, even if the prediction loss is large , Finally, because the weight is small, it has little effect on the average loss )
- This multi classification is usually implemented loss, Namely softmax;mmdetection It uses sigmoid+focal_loss; Is the use sigmoid Yes num_classes All categories inside calculate losses , combination focal_loss( Positive and negative classes add different weights ), Finally, do synthesis ( For example, take the average to get the average loss );
- With the above ideas , We know how to design CUDA Multithreaded computing for ( It's design. kernel 了 );
- Since we should treat everyone anchor Of num_classes Calculate losses for each category ( At this time, a total of N=num_total_anchors*num_classes This multiple loss ), Then let them all calculate in parallel ;
- So we need num_total_anchors*num_classes So many threads ; This is the top <<<a,b>>> in a Of GET_BLOCK Parameter set to output_size= num_total_anchors*num_classes Why ; Of course CUDA There are not so many threads that can be used at the same time , No problem , Set up another CUDA The number of bus routes in the range , The remaining workload makes these threads execute circularly ; This is the top GET_BLOCK What to do , Please see below
- CUDA It is required to set the thread block size ( General name THREADS_PER_BLOCK) And the number of thread blocks ( General name BLOCKS or BLOCK_NUM or BLOCKS_PER_GRID); Usually, the product of the two is slightly larger than the total number of tasks ( For example, the number of losses to be calculated above N); however CUDA Not so many threads , So you have to control the size of the two constants , For example, above GET_BLOCK In the last setting max Control the number of thread blocks ;
- Now there is THREADS_PER_BLOCK*BLOCKS_PER_GRID So many threads , It can be understood that they will be in CUDA Internal parallel execution , Each thread calculates a loss , The remaining losses are executed by the previous thread loop ;
- According to the introduction of the above steps and the above focal_loss Derivation of forward and backward calculation , We can write the following kernel, A few notes :
- CUDA_1D_KERNEL_LOOP(i, n) It is a macro with parameters , Used to define a loop , The thread mentioned above is not enough to loop
- i yes CUDA Automatically calculate the total of the current thread index,n Is the total number of tasks calculated above ( Quantity of all losses to be calculated , namely output_size)
- therefore index Used to locate which loss the current thread should calculate ; Notice the previous mention , multidimensional tensor It actually exists in one-dimensional form in memory , therefore kernel The parameter of is in the form of pointer ; Use at this time input[index] Then we found the corresponding position ; Then we can calculate the current number anchor( In this paper, n) And the anchor What kind of losses are there ;
- The next calculation is based on the above focal_loss Forward and backward derivation formula of ; The whole is relatively simple
- Pay attention to backward calculation (backward function ), The number of parallel threads can be compared with forward calculation forward Dissimilarity , But the calculation method is the same as forward To coordinate ( For example, calculate for each position loss It is necessary to calculate for each position grad)
- The code is as follows
#define CUDA_1D_KERNEL_LOOP(i, n) \ for (int i = blockIdx.x * blockDim.x + threadIdx.x; i < n; \ i += blockDim.x * gridDim.x) // blockDim.x * gridDim.x Is the total number of threads currently opened template <typename T> __global__ void sigmoid_focal_loss_forward_cuda_kernel( const int nthreads, const T* input, const int64_t* target, const T* weight, T* output, const T gamma, const T alpha, const int num_classes) { // nthreads Namely outputsize, be equal to num_total_anchors*num_classes // const T* Namely tensor The first address of continuous memory // input The continuous memory length of is num_total_anchors*num_classes,target The continuous memory length of is num_total_anchors. CUDA_1D_KERNEL_LOOP(index, nthreads) { // index be equal to blockIdx.x * blockDim.x + threadIdx.x, Thread index // because index It's corresponding to tensor(num_total_anchors,num_classes) An element of int n = index / num_classes; // therefore n Is the corresponding of this element anchor int c = index % num_classes; // therefore c Is the corresponding of this element class int64_t t = target[n]; // get anchor n Of target label T flag_p = (t == c); // Indicates a positive sample T flag_n = (t != c); // Negative sample // p = sigmoid(x) = 1. / 1. + expf(-x) T p = (T)1. / ((T)1. + expf(-input[index])); // (1 - p)**gamma * log(p) Positive sample focal loss The weight T term_p = pow(((T)1. - p), gamma) * log(max(p, (T)FLT_MIN)); // p**gamma * log(1 - p) Negative sample focal loss The weight T term_n = pow(p, gamma) * log(max((T)1. - p, (T)FLT_MIN)); output[index] = (T)0.; // The calculation results are put in output tensor in output[index] += -flag_p * alpha * term_p; output[index] += -flag_n * ((T)1. - alpha) * term_n; if (weight != NULL) { output[index] *= weight[t]; } } } // Empathy , Back propagation template <typename T> __global__ void sigmoid_focal_loss_backward_cuda_kernel( const int nthreads, const T* input, const int64_t* target, const T* weight, T* grad_input, const T gamma, const T alpha, const int num_classes) { CUDA_1D_KERNEL_LOOP(index, nthreads) { int n = index / num_classes; int c = index % num_classes; int64_t t = target[n]; T flag_p = (t == c); T flag_n = (t != c); // p = sigmoid(x) = 1. / 1. + expf(-x) T p = (T)1. / ((T)1. + exp(-input[index])); // (1 - p)**gamma * (1 - p - gamma*p*log(p)) T term_p = pow(((T)1. - p), gamma) * ((T)1. - p - (gamma * p * log(max(p, (T)FLT_MIN)))); // p**gamma * (gamma * (1 - p) * log(1 - p) - p) T term_n = pow(p, gamma) * (gamma * ((T)1. - p) * log(max((T)1. - p, (T)FLT_MIN)) - p); grad_input[index] = (T)0.; grad_input[index] += -flag_p * alpha * term_p; grad_input[index] += -flag_n * ((T)1. - alpha) * term_n; if (weight != NULL) { grad_input[index] *= weight[t]; } } }
- CUDA_1D_KERNEL_LOOP(i, n) It is a macro with parameters , Used to define a loop , The thread mentioned above is not enough to loop
summary
- So that's the introduction mmdetection Medium focal_loss Operator's CUDA Realization ;
- Operator implementation has a relatively fixed process , From top to bottom are :
- Python call autograd Function
- Above autograd Define forward and backward algorithms
- The forward and backward algorithm above refers to Python Used to bind c++ Functional module
- Above module There are forward and backward functions mapped to c++ Forward and backward functions of
- c++ Preparation environment for forward and backward functions of ( The most important thing is the thread organization ) And call CUDA kernel
- kernel Definition CUDA How to implement specific operators ( As above focal_loss)
- The difficulty lies in how to achieve the final kernel; Specific tasks should be decomposed into What multiple threads can do in parallel , Only then can it be realized kernel;
- TODO: Other more complex operators CUDA Realization
边栏推荐
- 广州推进儿童友好城市建设,将探索学校周边200米设安全区域
- Current situation and trend of character animation
- [NVIDIA development board] FAQ (updated from time to time)
- What is an R-value reference and what is the difference between it and an l-value?
- Roguelike game into crack the hardest hit areas, how to break the bureau?
- Niuke winter vacation training 6 maze 2
- Excellent software testers have these abilities
- Intel Distiller工具包-量化实现1
- 704 binary search
- [sword finger offer] serialized binary tree
猜你喜欢
Problems in loading and saving pytorch trained models
MySQL uninstallation and installation methods

LeetCode:221. 最大正方形
704 binary search
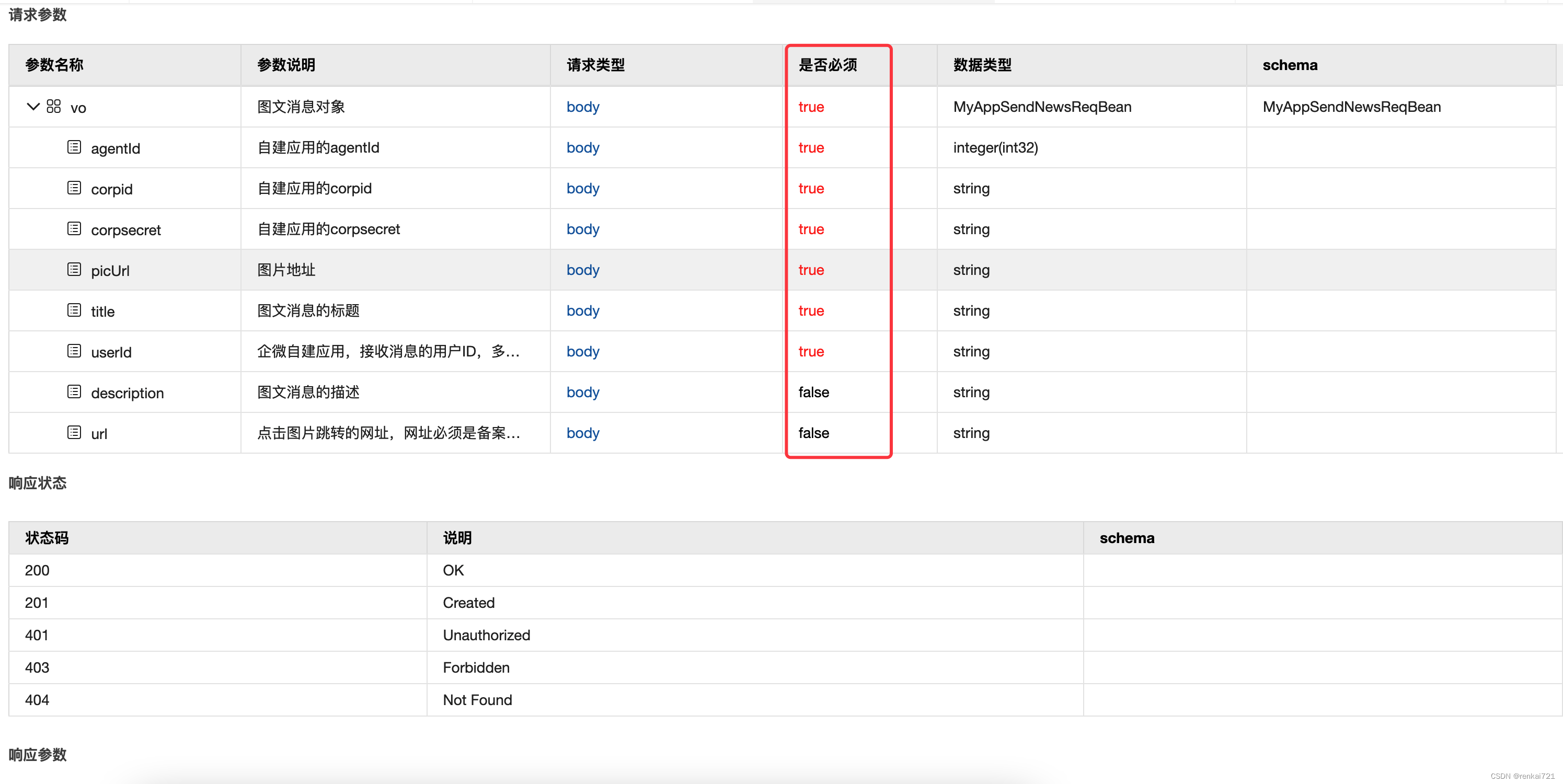
Swagger setting field required is mandatory
vb. Net changes with the window, scales the size of the control and maintains its relative position
![[MySQL] multi table query](/img/eb/9d54df9a5c6aef44e35c7a63b286a6.jpg)
[MySQL] multi table query

BMINF的後訓練量化實現
CUDA实现focal_loss

使用latex导出IEEE文献格式
随机推荐
Compétences en mémoire des graphiques UML
ROS compilation calls the third-party dynamic library (xxx.so)
Excellent software testers have these abilities
UML圖記憶技巧
注意力机制的一种卷积替代方式
[today in history] February 13: the father of transistors was born The 20th anniversary of net; Agile software development manifesto was born
Bitwise logical operator
[Hacker News Weekly] data visualization artifact; Top 10 Web hacker technologies; Postman supports grpc
MongoDB 的安装和基本操作
可变长参数
自动化测试框架有什么作用?上海专业第三方软件测试公司安利
【嵌入式】使用JLINK RTT打印log
MySQL uninstallation and installation methods
What is the role of automated testing frameworks? Shanghai professional third-party software testing company Amway
【ROS】usb_ Cam camera calibration
IJCAI2022论文合集(持续更新中)
Booking of tourism products in Gansu quadrupled: "green horse" became popular, and one room of B & B around Gansu museum was hard to find
R language uses the principal function of psych package to perform principal component analysis on the specified data set. PCA performs data dimensionality reduction (input as correlation matrix), cus
LeetCode:221. Largest Square
Simple use of promise in uniapp