当前位置:网站首页>BMINF的後訓練量化實現
BMINF的後訓練量化實現
2022-07-06 08:52:00 【cyz0202】
BMINF
- BMINF是清華大學開發的大模型推理工具,目前主要針對該團隊的CPM系列模型做推斷優化。該工具實現了內存/顯存調度優化,利用cupy/cuda實現了後訓練量化 等功能,本文記錄分析該工具的後訓練量化實現。
- 主要關注cupy操作cuda實現量化的部分,涉及量化的原理可能不會做詳細介紹,需要讀者查閱其他資料;
- BMINF團隊近期對代碼進行較多重構;我下面用的代碼示例是8個月前的,讀者想查看BMINF對應源代碼,請查看0.5版本
實現代碼分析1
量化部分的入口代碼主要是在 tools/migrate_xxx.py,這裏以 tools/migrate_cpm2.py為例;
main函數
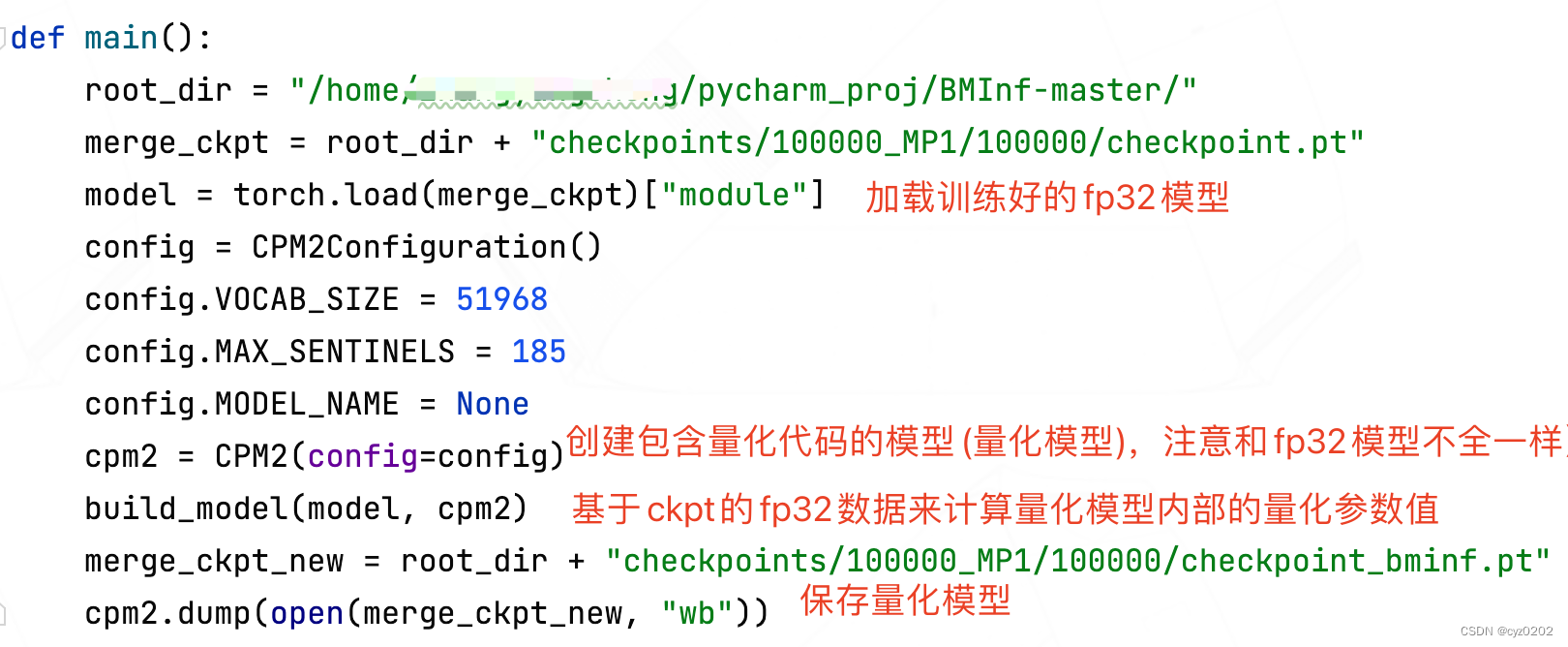
build_model函數:基於ckpt的fp32數據計算量化模型內部的量化參數值

scale_build_parameter函數:計算對稱量化的scale,並將scale和量化結果放到量化模型對應參數內(上面對應的是model.encoder_kv.w_project_kv_scale和w_project_kv)

看一下保存量化結果的model.encoder_kv.w_project_kv_scale和w_project_kv是怎麼定義的

build_encoder/decoder函數:主要調用build_block,處理每個block(layer)

build_block函數:還是複制部分module的參數和量化另一部分module的參數

小結:以上是從fp32模型將不同參數copy到量化模型對應比特置的實現;下面介紹量化模型如何使用量化參數+cupy+cuda進行計算,實現加速;
實現代碼分析2
- 以decoder使用的注意力module: partial_attetion為例進行分析(bminf/layers/attention)
- 直接上代碼了,請看注釋
class PartialAttention(Layer):
def __init__(self, dim_in, dim_qkv, num_heads, is_self_attn):
self.is_self_attn = is_self_attn # self_attn還是cross_attn
self.dim_in = dim_in
self.num_heads = num_heads
self.dim_qkv = dim_qkv
if self.is_self_attn:
self.w_project_qkv = Parameter((3, dim_qkv * num_heads, dim_in), cupy.int8) # 權重使用int8量化,這裏會接收fp32的ckpt對應參數量化後的結果
self.w_project_qkv_scale = Parameter((3, dim_qkv * num_heads, 1), cupy.float16) # scale使用fp16;值得注意的是scale是對dim_in這個維度的
else:
self.w_project_q = Parameter((dim_qkv * num_heads, dim_in), cupy.int8) # cross_attn shape有點不一樣
self.w_project_q_scale = Parameter((dim_qkv * num_heads, 1), cupy.float16)
# 輸出前再做一次linear
self.w_out = Parameter((dim_in, dim_qkv * num_heads), cupy.int8)
self.w_out_scale = Parameter((dim_in, 1), cupy.float16)
def quantize(self, allocator: Allocator, value: cupy.ndarray, axis=-1):
""" 量化函數,allocator分配顯存,value是待量化fp16/32值;axis是量化維度 注意到嵌套了一個quantize函數,這是真正幹活的 ======================================================== 以下是quantize函數的實現: def quantize(x: cupy.ndarray, out: cupy.ndarray, scale: cupy.ndarray, axis=-1): assert x.dtype == cupy.float16 or x.dtype == cupy.float32 assert x.shape == out.shape if axis < 0: axis += len(x.shape) assert scale.dtype == cupy.float16 assert scale.shape == x.shape[:axis] + (1,) + x.shape[axis + 1:] # scale on gpu 計算scale(對稱模式) quantize_scale_kernel(x, axis=axis, keepdims=True, out=scale) quantize_copy_half(x, scale, out=out) # 計算 量化結果 ======================================================== 以下是quantize_scale_kernel和quantize_copy_half/float的實現: # 返回的quantize_scale_kernel是個cuda上的函數,計算量化scale quantize_scale_kernel = create_reduction_func( # kernel指cuda上的函數,這裏就是cupy讓cuda創建相應函數(kernel) 'bms_quantize_scale', # 創建的函數的名稱 ('e->e', 'f->e', 'e->f', 'f->f'), # 指定輸入->輸出數據類型(來自numpy,如e代錶float16,f是float32) ('min_max_st<type_in0_raw>(in0)', 'my_max(a, b)', 'out0 = abs(a.value) / 127', 'min_max_st<type_in0_raw>'), # cuda將會執行的內容 None, _min_max_preamble # 如果需要用到自定義數據結構等,要在這裏寫明,如上一行min_max_st、my_max等是bminf作者自定義的,這裏沒展示出來 ) # 返回quantize_copy_half同樣是個cuda函數,該函數在cuda上計算量化值=x/scale;注意對稱量化沒有zero_point quantize_copy_half = create_ufunc( 'bms_quantize_copy_half', ('ee->b', 'fe->b', 'ff->b'), 'out0 = nearbyintf(half(in0 / in1))') # half指fp16 quantize_copy_float = create_ufunc( 'bms_quantize_copy_float', ('ee->b', 'fe->b', 'ff->b'), 'out0 = nearbyintf(float(in0 / in1))') ======================================================== """
if axis < 0:
axis += len(value.shape)
# 以下3行分配顯存給量化值、scale
nw_value = allocator.alloc_array(value.shape, cupy.int8)
scale_shape = value.shape[:axis] + (1,) + value.shape[axis + 1:]
scale = allocator.alloc_array(scale_shape, cupy.float16)
# 真正的量化函數,計算scale值存於scale中,計算量化值存於nw_value中
quantize(value, nw_value, scale, axis=axis)
return nw_value, scale # 返回量化值、scale
def forward(self,
allocator: Allocator,
curr_hidden_state: cupy.ndarray, # (batch, dim_model)
past_kv: cupy.ndarray, # (2, batch, num_heads, dim_qkv, past_kv_len)
position_bias: Optional[cupy.ndarray], # (1#batch, num_heads, past_kv_len)
past_kv_mask: cupy.ndarray, # (1#batch, past_kv_len)
decoder_length: Optional[int], # int
):
batch_size, dim_model = curr_hidden_state.shape
num_heads, dim_qkv, past_kv_len = past_kv.shape[2:]
assert past_kv.shape == (2, batch_size, num_heads, dim_qkv, past_kv_len)
assert past_kv.dtype == cupy.float16
assert num_heads == self.num_heads
assert dim_qkv == self.dim_qkv
assert curr_hidden_state.dtype == cupy.float16
if self.is_self_attn:
assert decoder_length is not None
if position_bias is not None:
assert position_bias.shape[1:] == (num_heads, past_kv_len)
assert position_bias.dtype == cupy.float16
assert past_kv_mask.shape[-1] == past_kv_len
# value->(batch, dim_model), scale->(batch, 1) 這裏是one decoder-step,所以沒有seq-len
# 對輸入做量化
value, scale = self.quantize(allocator, curr_hidden_state[:, :], axis=1)
if self.is_self_attn: # 自注意力
qkv_i32 = allocator.alloc_array((3, batch_size, self.num_heads * self.dim_qkv, 1), dtype=cupy.int32)
else:
qkv_i32 = allocator.alloc_array((batch_size, self.num_heads * self.dim_qkv, 1), dtype=cupy.int32)
if self.is_self_attn:
# 自注意力時,qkv都要進行線性變換;使用igemm讓cuda執行8bit matmul;
# 稍後展示igemm實現
igemm(
allocator,
self.w_project_qkv.value, # (3, num_head * dim_qkv, dim_model)
True, # 轉置
value[cupy.newaxis], # (1, batch_size, dim_model)
False,
qkv_i32[:, :, :, 0] # (3, batch_size, num_head * dim_qkv)
)
else:
# 交叉注意力時,對q做線性變換
igemm(
allocator,
self.w_project_q.value[cupy.newaxis], # (1, num_head * dim_qkv, dim_model)
True,
value[cupy.newaxis], # (1, batch_size, dim_model)
False,
qkv_i32[cupy.newaxis, :, :, 0] # (1, batch_size, num_head * dim_qkv)
)
# release value
del value
# convert int32 to fp16 將上述線性變換結果int32轉換為fp16
# 注意整個過程不是單一的int8或者int類型計算
assert qkv_i32._c_contiguous
qkv_f16 = allocator.alloc_array(qkv_i32.shape, dtype=cupy.float16)
if self.is_self_attn:
""" elementwise_copy_scale = create_ufunc('bms_scaled_copy', ('bee->e', 'iee->e', 'iee->f', 'iff->f'), 'out0 = in0 * in1 * in2') """
elementwise_copy_scale( # 執行反量化,得到fp16存於out裏面
qkv_i32, # (3, batch_size, num_head * dim_qkv, 1)
self.w_project_qkv_scale.value[:, cupy.newaxis, :, :], # (3, 1#batch_size, dim_qkv * num_heads, 1)
scale[cupy.newaxis, :, :, cupy.newaxis], # (1#3, batch_size, 1, 1)
out=qkv_f16
)
else:
elementwise_copy_scale(
qkv_i32, # (1, batch_size, num_head * dim_qkv, 1)
self.w_project_q_scale.value, # (dim_qkv * num_heads, 1)
scale[:, :, cupy.newaxis], # (batch_size, 1, 1)
out=qkv_f16
)
del scale
del qkv_i32
# reshape
assert qkv_f16._c_contiguous
if self.is_self_attn:
qkv = cupy.ndarray((3, batch_size, self.num_heads, self.dim_qkv), dtype=cupy.float16, memptr=qkv_f16.data)
query = qkv[0] # (batch, num_heads, dim_qkv)
past_kv[0, :, :, :, decoder_length] = qkv[1] # 存儲為曆史kv,避免後續需要重複計算
past_kv[1, :, :, :, decoder_length] = qkv[2]
del qkv
else:
query = cupy.ndarray((batch_size, self.num_heads, self.dim_qkv), dtype=cupy.float16, memptr=qkv_f16.data)
del qkv_f16
# calc attention score(fp16)
attention_score = allocator.alloc_array((batch_size, self.num_heads, past_kv_len, 1), dtype=cupy.float16)
fgemm( # 計算注意力分數是使用float-gemm計算
allocator,
query.reshape(batch_size * self.num_heads, self.dim_qkv, 1), # (batch_size * num_heads, dim_qkv, 1)
False,
past_kv[0].reshape(batch_size * self.num_heads, self.dim_qkv, past_kv_len),
# ( batch_size * num_heads, dim_qkv, past_kv_len)
True,
attention_score.reshape(batch_size * self.num_heads, past_kv_len, 1)
# (batch_size * num_heads, past_kv_len, 1)
)
# mask計算
""" mask_attention_kernel = create_ufunc( 'bms_attention_mask', ('?ff->f',), 'out0 = in0 ? in1 : in2' # 選擇器 ) """
mask_attention_kernel(
past_kv_mask[:, cupy.newaxis, :, cupy.newaxis], # (batch, 1#num_heads, past_kv_len, 1)
attention_score,
cupy.float16(-1e10),
out=attention_score # (batch_size, self.num_heads, past_kv_len, 1)
)
if position_bias is not None:
attention_score += position_bias[:, :, :, cupy.newaxis] # (1#batch, num_heads, past_kv_len, 1)
# 計算softmax float情形
temp_attn_mx = allocator.alloc_array((batch_size, self.num_heads, 1, 1), dtype=cupy.float16)
cupy.max(attention_score, axis=-2, out=temp_attn_mx, keepdims=True)
attention_score -= temp_attn_mx
cupy.exp(attention_score, out=attention_score)
cupy.sum(attention_score, axis=-2, out=temp_attn_mx, keepdims=True)
attention_score /= temp_attn_mx
del temp_attn_mx
# 計算softmax*V
out_raw = allocator.alloc_array((batch_size, self.num_heads, self.dim_qkv, 1), dtype=cupy.float16)
fgemm( # 仍然使用float gemm
allocator,
attention_score.reshape(batch_size * self.num_heads, past_kv_len, 1),
False,
past_kv[1].reshape(batch_size * self.num_heads, self.dim_qkv, past_kv_len),
False,
out_raw.reshape(batch_size * self.num_heads, self.dim_qkv, 1)
)
assert out_raw._c_contiguous
# 得到softmax(qk)*v結果
out = cupy.ndarray((batch_size, self.num_heads * self.dim_qkv), dtype=cupy.float16, memptr=out_raw.data)
del attention_score
del out_raw
# 注意力結果向量繼續量化,以便下面再做一次linear
# (batch_size, num_heads * dim_qkv, 1), (batch_size, 1, 1)
out_i8, scale = self.quantize(allocator, out, axis=1)
project_out_i32 = allocator.alloc_array((batch_size, dim_model, 1), dtype=cupy.int32)
# 輸出前再做一次linear projection(igemm)
igemm(
allocator,
self.w_out.value[cupy.newaxis], # (1, dim_in, dim_qkv * num_heads)
True,
out_i8[cupy.newaxis],
False,
project_out_i32[cupy.newaxis, :, :, 0]
)
assert project_out_i32._c_contiguous
# (batch, dim_model, 1)
project_out_f16 = allocator.alloc_array(project_out_i32.shape, dtype=cupy.float16)
# 反量化得到最終注意力結果fp16
elementwise_copy_scale(
project_out_i32,
self.w_out_scale.value, # (1#batch_size, dim_model, 1)
scale[:, :, cupy.newaxis], # (batch, 1, 1)
out=project_out_f16
)
return project_out_f16[:, :, 0] # (batch, dim_model)
- 以上代碼小結:可以看到主要是對linear做量化,其他如norm、score、softmax等都是直接在float16上計算;整個過程是int、float交替使用,量化、反量化交替使用
- igemm函數:cupy如何在cuda上執行整型矩陣相乘,就是根據cuda規範寫就行
def _igemm(allocator : Allocator, a, aT, b, bT, c, device, stream):
assert isinstance(a, cupy.ndarray)
assert isinstance(b, cupy.ndarray)
assert isinstance(c, cupy.ndarray)
assert len(a.shape) == 3 # (batch, m, k)
assert len(b.shape) == 3 # (batch, n, k)
assert len(c.shape) == 3 # (batch, n, m)
assert a._c_contiguous
assert b._c_contiguous
assert c._c_contiguous
assert a.device == device
assert b.device == device
assert c.device == device
lthandle = get_handle(device) # 為當前gpu創建handler
# 獲取batch_size
num_batch = 1
if a.shape[0] > 1 and b.shape[0] > 1:
assert a.shape[0] == b.shape[0]
num_batch = a.shape[0]
elif a.shape[0] > 1:
num_batch = a.shape[0]
else:
num_batch = b.shape[0]
# 計算stride,batch內跨樣本
if a.shape[0] == 1:
stride_a = 0
else:
stride_a = a.shape[1] * a.shape[2] # m*k
if b.shape[0] == 1:
stride_b = 0
else:
stride_b = b.shape[1] * b.shape[2] # n*k
if aT: # 需要轉置;aT一般為True
m, k1 = a.shape[1:] # a [bs,m,k1]
else:
k1, m = a.shape[1:]
if bT:
k2, n = b.shape[1:]
else: # bT一般為False
n, k2 = b.shape[1:] # b [bs,n,k]
assert k1 == k2 # a*b => k維度大小要相同
k = k1
assert c.shape == (num_batch, n, m) # c = a*b
stride_c = n * m
## compute capability: cuda版本
# Ampere >= 80
# Turing >= 75
cc = int(device.compute_capability)
v1 = ctypes.c_int(1) # 設置常量1,後續作為CUDA規範要求的系數
v0 = ctypes.c_int(0) # 設置常量0
""" # 設置a/b/c 3個矩陣的屬性(rt, m, n, ld, order, batch_count, batch_offset)=> MatrixLayout_t指針 # LayoutCache用來創建某個矩陣在顯存中的錶現形式(即layout),包括數據類型,行數、列數,batch大小,內存存儲順序(order,包括列存儲模式、行存儲模式等等)。。。 # cublasLt是加載cuda安裝目錄下cublast lib得到的; # 以下涉及cublasLt的函數,具體內容請移步bminf源代碼和cuda官方doc查看 ============================================================ class LayoutCache(HandleCache): # 代碼中layoutcache(...)會調用create,並返回指針 def create(self, rt, m, n, ld, order, batch_count, batch_offset): # 創建一個新的矩陣layout指針 ret = cublasLt.cublasLtMatrixLayout_t() # 上述指針指向新建的矩陣layout;rt-數據類型;m/n指row/col;ld-leading_dimension 列模式下是行數;checkCublasStatus根據返回狀態檢查操作是否成功 cublasLt.checkCublasStatus( cublasLt.cublasLtMatrixLayoutCreate(ret, rt, m, n, ld) ) # 設置矩陣的存儲格式屬性 cublasLt.checkCublasStatus( cublasLt.cublasLtMatrixLayoutSetAttribute(ret, cublasLt.CUBLASLT_MATRIX_LAYOUT_ORDER, ctypes.byref(ctypes.c_int32(order)), ctypes.sizeof(ctypes.c_int32)) ) # 設置矩陣的batch_count屬性(batch內樣本數量) cublasLt.checkCublasStatus( cublasLt.cublasLtMatrixLayoutSetAttribute(ret, cublasLt.CUBLASLT_MATRIX_LAYOUT_BATCH_COUNT, ctypes.byref(ctypes.c_int32(batch_count)), ctypes.sizeof(ctypes.c_int32)) ) cublasLt.checkCublasStatus( cublasLt.cublasLtMatrixLayoutSetAttribute(ret, cublasLt.CUBLASLT_MATRIX_LAYOUT_STRIDED_BATCH_OFFSET, ctypes.byref(ctypes.c_int64(batch_offset)), ctypes.sizeof(ctypes.c_int64)) ) return ret # 用完後釋放占用的顯存空間 def release(self, x): cublasLt.checkCublasStatus(cublasLt.cublasLtMatrixLayoutDestroy(x)) ============================================================ # 注意以下寫法 錶示 row=shape[2], col=shape[1],與實際相反;該處之所以這樣寫,是為了與稍早前的cuda做匹配;對於cc>=75的,還是會通過transform變換回row=shape[1], col=shape[2];見下文 """
layout_a = layout_cache(cublasLt.CUDA_R_8I, a.shape[2], a.shape[1], a.shape[2], cublasLt.CUBLASLT_ORDER_COL, a.shape[0], stride_a) # a是int8+列 存儲
layout_b = layout_cache(cublasLt.CUDA_R_8I, b.shape[2], b.shape[1], b.shape[2], cublasLt.CUBLASLT_ORDER_COL, b.shape[0], stride_b) # b是int8+列 存儲
layout_c = layout_cache(cublasLt.CUDA_R_32I, c.shape[2], c.shape[1], c.shape[2], cublasLt.CUBLASLT_ORDER_COL, c.shape[0], stride_c) # c是int32+列 存儲
if cc >= 75:
# use tensor core
trans_lda = 32 * m # leading dimension of a
if cc >= 80:
trans_ldb = 32 * round_up(n, 32) # round_up對n上取整 到 32的倍數,如28->32, 39->64
else:
trans_ldb = 32 * round_up(n, 8)
trans_ldc = 32 * m
stride_trans_a = round_up(k, 32) // 32 * trans_lda # (「k」// 32) * 32 * m >= k*m 取 比a中1個樣本 大一點的 32倍數空間,如k=40->k=64 => stride_trans_a=64*m
stride_trans_b = round_up(k, 32) // 32 * trans_ldb
stride_trans_c = round_up(n, 32) // 32 * trans_ldc
trans_a = allocator.alloc( stride_trans_a * a.shape[0] ) # 分配比a大一點的32倍數空間,注意因為是int8(1個字節),所以空間大小=元素數目
trans_b = allocator.alloc( stride_trans_b * b.shape[0] )
trans_c = allocator.alloc( ctypes.sizeof(ctypes.c_int32) * stride_trans_c * c.shape[0] ) # 注意是int32,不是int8
# 創建trans_a/b/c的layout
layout_trans_a = layout_cache(cublasLt.CUDA_R_8I, m, k, trans_lda, cublasLt.CUBLASLT_ORDER_COL32, a.shape[0], stride_trans_a)
if cc >= 80:
layout_trans_b = layout_cache(cublasLt.CUDA_R_8I, n, k, trans_ldb, cublasLt.CUBLASLT_ORDER_COL32_2R_4R4, b.shape[0], stride_trans_b) # 使用更高級的COL存儲模式
else:
layout_trans_b = layout_cache(cublasLt.CUDA_R_8I, n, k, trans_ldb, cublasLt.CUBLASLT_ORDER_COL4_4R2_8C, b.shape[0], stride_trans_b)
layout_trans_c = layout_cache(cublasLt.CUDA_R_32I, m, n, trans_ldc, cublasLt.CUBLASLT_ORDER_COL32, num_batch, stride_trans_c)
# 創建a的tranform descriptor並設置transpose屬性(類似上面layout,屬於CUDA規範要求),返回descriptor;transform主要屬性包括數據類型,是否轉置等
# 注意到使用的數據類型是INT32,是因為transform操作會讓輸入乘以某個系數(這裏指上面定義的整型v1/v0),兩者類型要匹配,所以先讓輸入從INT8->INT32,計算結束再讓INT32->INT8(見下文使用處)
transform_desc_a = transform_cache(cublasLt.CUDA_R_32I, aT)
transform_desc_b = transform_cache(cublasLt.CUDA_R_32I, not bT)
transform_desc_c = transform_cache(cublasLt.CUDA_R_32I, False)
""" # 創建CUDA函數cublasLtMatrixTransform(CUDA不能簡單通過一個a.T就讓a轉置,需要較複雜的規範) cublasLtMatrixTransform = LibFunction(lib, "cublasLtMatrixTransform", cublasLtHandle_t, cublasLtMatrixTransformDesc_t, ctypes.c_void_p, ctypes.c_void_p, cublasLtMatrixLayout_t, ctypes.c_void_p, ctypes.c_void_p, cublasLtMatrixLayout_t, ctypes.c_void_p, cublasLtMatrixLayout_t, cudaStream_t, cublasStatus_t) # cublasLtMatrixTransform() => C = alpha*transformation(A) + beta*transformation(B) 矩陣變換操作 cublasStatus_t cublasLtMatrixTransform( cublasLtHandle_t lightHandle, cublasLtMatrixTransformDesc_t transformDesc, const void *alpha, # 一般為1 const void *A, cublasLtMatrixLayout_t Adesc, const void *beta, # 一般為0,此時 C=transform(A) const void *B, cublasLtMatrixLayout_t Bdesc, void *C, cublasLtMatrixLayout_t Cdesc, cudaStream_t stream); """
cublasLt.checkCublasStatus(
cublasLt.cublasLtMatrixTransform( # 對a執行變換操作(上面定義的變換是 32I 和 aT)
lthandle, transform_desc_a,
ctypes.byref(v1), a.data.ptr, layout_a,
ctypes.byref(v0), 0, 0, # 不使用B
trans_a.ptr, layout_trans_a, stream.ptr
)
)
cublasLt.checkCublasStatus(
cublasLt.cublasLtMatrixTransform( # 對b執行變換操作(上面定義的變換是 32I 和 not bT)
lthandle, transform_desc_b,
ctypes.byref(v1), b.data.ptr, layout_b,
ctypes.byref(v0), 0, 0,
trans_b.ptr, layout_trans_b, stream.ptr
)
)
if a.shape[0] != num_batch:
layout_trans_a = layout_cache(cublasLt.CUDA_R_8I, m, k, trans_lda, cublasLt.CUBLASLT_ORDER_COL32, num_batch, 0)
if b.shape[0] != num_batch:
if cc >= 80:
layout_trans_b = layout_cache(cublasLt.CUDA_R_8I, n, k, trans_ldb, cublasLt.CUBLASLT_ORDER_COL32_2R_4R4, num_batch, 0)
else:
layout_trans_b = layout_cache(cublasLt.CUDA_R_8I, n, k, trans_ldb, cublasLt.CUBLASLT_ORDER_COL4_4R2_8C, num_batch, 0)
# 創建matmul描述子:中間數據類型,計算類型(輸入輸出類型),aT,bT
# 使用INT32保存INT8計算結果;後兩個參數錶示a/b是否轉置
matmul_desc = matmul_cache(cublasLt.CUDA_R_32I, cublasLt.CUBLAS_COMPUTE_32I, False, True)
""" # 計算 D = alpha*(A*B) + beta*(C) cublasStatus_t cublasLtMatmul( cublasLtHandle_t lightHandle, cublasLtMatmulDesc_t computeDesc, const void *alpha, const void *A, cublasLtMatrixLayout_t Adesc, const void *B, cublasLtMatrixLayout_t Bdesc, const void *beta, const void *C, cublasLtMatrixLayout_t Cdesc, void *D, cublasLtMatrixLayout_t Ddesc, const cublasLtMatmulAlgo_t *algo, void *workspace, size_t workspaceSizeInBytes, cudaStream_t stream); """
cublasLt.checkCublasStatus( cublasLt.cublasLtMatmul(
lthandle, # gpu句柄
matmul_desc,
ctypes.byref(ctypes.c_int32(1)), # alpha=1
trans_a.ptr, # a數據
layout_trans_a, # a格式
trans_b.ptr,
layout_trans_b,
ctypes.byref(ctypes.c_int32(0)), # beta=0,不加C偏置,即D = alpha*(A*B)
trans_c.ptr, # 不使用
layout_trans_c, # 不使用
trans_c.ptr, # D即C,屬於 in-place(原地替換)
layout_trans_c,
0,
0,
0,
stream.ptr
))
cublasLt.checkCublasStatus(
cublasLt.cublasLtMatrixTransform( # 根據transform_desc_c對結果C做一次transform(int32,不轉置)
lthandle, transform_desc_c,
ctypes.byref(v1), trans_c.ptr, layout_trans_c,
ctypes.byref(v0), 0, 0,
c.data.ptr, layout_c,
stream.ptr
)
)
else:
pass # 這裏與上面不同之處是 使用老版本cuda,因此省略不再贅述,感興趣的請自己去查看源代碼
總結
- 以上是針對BMINF量化實現代碼的分析,用來學習量化+cupy+cuda(具體是cublasLt)的實現;
- 代碼只實現了最簡單的對稱量化;使用cupy+cublasLt實現線性層的量化;整個過程是量化和反量化,int和float的交替使用;
- 上述過程的C++版本也是去調用cublasLt相同函數,寫法類似,感興趣的可查看NVIDIA例子-LtIgemmTensor
- 上面只涉及CUDA/cublasLt的部分應用,更多的應用可參考 CUDA官方手册;
- 難免疏漏,敬請指教
边栏推荐
- R language uses the principal function of psych package to perform principal component analysis on the specified data set. PCA performs data dimensionality reduction (input as correlation matrix), cus
- Swagger setting field required is mandatory
- UnsupportedOperationException异常
- MYSQL卸载方法与安装方法
- LeetCode:39. Combined sum
- LeetCode:34. 在排序数组中查找元素的第一个和最后一个位置
- Tcp/ip protocol
- LeetCode:剑指 Offer 03. 数组中重复的数字
- Nacos 的安装与服务的注册
- 704 binary search
猜你喜欢
项目连接数据库遇到的问题及解决
![[OC-Foundation框架]-<字符串And日期与时间>](/img/75/e20064fd0066810135771a01f54360.png)
[OC-Foundation框架]-<字符串And日期与时间>

企微服务商平台收费接口对接教程
Problems in loading and saving pytorch trained models
Computer cleaning, deleted system files
Using C language to complete a simple calculator (function pointer array and callback function)
Double pointeur en langage C - - modèle classique
Visual implementation and inspection of visdom

Export IEEE document format using latex

Detailed explanation of dynamic planning
随机推荐
To effectively improve the quality of software products, find a third-party software evaluation organization
如何正确截取字符串(例:应用报错信息截取入库操作)
UML diagram memory skills
LeetCode:剑指 Offer 03. 数组中重复的数字
数学建模2004B题(输电问题)
Deep analysis of C language data storage in memory
如何有效地进行自动化测试?
Problems encountered in connecting the database of the project and their solutions
Current situation and trend of character animation
Computer cleaning, deleted system files
使用latex导出IEEE文献格式
优秀的软件测试人员,都具备这些能力
【嵌入式】Cortex M4F DSP库
自动化测试框架有什么作用?上海专业第三方软件测试公司安利
marathon-envs项目环境配置(强化学习模仿参考动作)
深度剖析C语言数据在内存中的存储
The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
Leetcode: Sword finger offer 48 The longest substring without repeated characters
The problem and possible causes of the robot's instantaneous return to the origin of the world coordinate during rviz simulation
LeetCode:387. The first unique character in the string