当前位置:网站首页>Once you change the test steps, write all the code. Why not try yaml to realize data-driven?
Once you change the test steps, write all the code. Why not try yaml to realize data-driven?
2022-07-06 09:01:00 【Automated test seventh uncle】
Preface
Same idea and “UI Automated testing framework ” Medium “ Data driven test steps ” identical , The data-driven of the test steps in the interface is to set the parameters of the interface ( such as method、url、param etc. ) Package to yaml Manage in file . When the test steps change , It just needs to be modified yaml The configuration in the file is OK .
Data driven is the change of data, which drives the execution of automatic test , Finally, it causes the test results to change . Simply speaking , It's the application of parameterization . Test cases with small amount of data can use code parameterization to realize data-driven , In case of large amount of data, it is recommended to use a structured file ( for example yaml,json etc. ) To store data , Then read the data in the test case .

Still used @pytest.mark.parametrize Decorator to parameterize , Use parameterization to realize data-driven .
Through parameterization , Judge separately id by 2,3 Department of parentid by 1:
import pytest
class TestDepartment:
department = Department()
@pytest.mark.parametrize("id", [2, 3])
def test_department_list(self, id):
r = self.department.list(id)
assert self.department.jsonpath(expr="$..parentid")[0] == 1
The above code first uses @pytest.mark.parametrize Decorator , Two sets of data were transmitted , The test results show that two test cases have been executed , Instead of a test case . That is to say pytest Two corresponding test cases will be automatically generated from the two sets of test data and executed , Generate two test results .
When the amount of test data is large , Consider storing data in structured files . Read out the data in the required format in the code from the file , Pass to the test case to execute . This actual battle is based on YAML demonstrate .YAML To structure using dynamic fields , It's data centric , Than excel、csv、Json、XML More suitable for data-driven .
Store the two sets of data parameterized above in yaml In file , Create a data/department_list.yml file , The code is as follows :
-2
-3The code above defines one yaml Format data file department_list.yml, A list is defined in the file , There are two data in the list , Finally, this data format is generated :[1,2]. Transform the parameterized data in the test case into from department_list.yml File read , The code is as follows :
class TestDepartment:
department = Department()
@pytest.mark.parametrize("id", \
yaml.safe_load(open("../data/department_list.yml")))
def test_department_list(self, id):
r = self.department.list(id)
assert self.department.jsonpath(expr="$..parentid")[0] == 1
The above code , Just use yaml.safe_load() Method , Read department_list.yml The data in the file , Pass in to the use case respectively test_department_list() Method to complete the verification of input and result .
In practice , For environment switching and configuration , For maintenance purposes , It is not usually done in hard coded form . stay “ Interface testing in multiple environments ” It has been introduced in the chapter , How to use environment switching as a configurable option . This chapter will reconstruct this part , Use the data-driven method to complete the configuration of multiple environments .
according to “ Interface testing in multiple environments ” chapter , Change the environment configuration section in this chapter to data-driven mode
The code is as follows :
# hold host It is amended as follows ip, And add host header
env={
"docker.testing-studio.com": {
"dev": "127.0.0.1",
"test": "1.1.1.2"
},
"default": "dev"
}
data["url"]=str(data["url"]).replace(
"docker.testing-studio.com",
env["docker.testing-studio.com"][env["default"]]
)
data["headers"]["Host"]="docker.testing-studio.com"
Still in yaml For example , Put all the environment configuration information into env.yml In file . If you are afraid of making mistakes , You can use it first yaml.safe_dump(env) take dict The code of the format is converted to yaml.
As shown below , Printed , Is the successful conversion yaml Format configuration information :
def test_send(self):
env={
"docker.testing-studio.com": {
"dev": "127.0.0.1",
"test": "1.1.1.2"
},
"default": "dev"
}
yaml2 = yaml.safe_dump(env)
print("")
print(yaml2)
Paste the printed content into env.yml In file : env.yml
docker.testing-studio.com:
dev: "127.0.0.1"
test: "1.1.1.2"
level: 4
default:
"dev"
Slightly modify the code in the environment preparation , hold env Variables from a typical dict Change it to , Use yaml.safe_load Read env.yml:
# hold host It is amended as follows ip, And add host header
env = yaml.safe_load(open("./env.yml"))
data["url"] = str(data["url"]).\
replace("docker.testing-studio.com",
env["docker.testing-studio.com"][env["default"]])
data["headers"]["Host"] = "docker.testing-studio.com"
In this way , You can use a data-driven approach , By modifying the env.yml File to directly modify the configuration information
summary
That's all for today's article , Favorite friends can like collections and pay attention

边栏推荐
- KDD 2022论文合集(持续更新中)
- BN折叠及其量化
- CSP first week of question brushing
- 在QWidget上实现窗口阻塞
- Using pkgbuild:: find in R language_ Rtools check whether rtools is available and use sys The which function checks whether make exists, installs it if not, and binds R and rtools with the writelines
- The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
- Simclr: comparative learning in NLP
- 【文本生成】论文合集推荐丨 斯坦福研究者引入时间控制方法 长文本生成更流畅
- 随手记01
- Show slave status \ read in G_ Master_ Log_ POS and relay_ Log_ The (size) relationship of POS
猜你喜欢

opencv+dlib实现给蒙娜丽莎“配”眼镜
Using C language to complete a simple calculator (function pointer array and callback function)
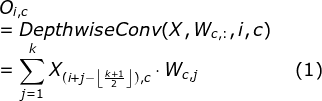
注意力机制的一种卷积替代方式
Problems encountered in connecting the database of the project and their solutions
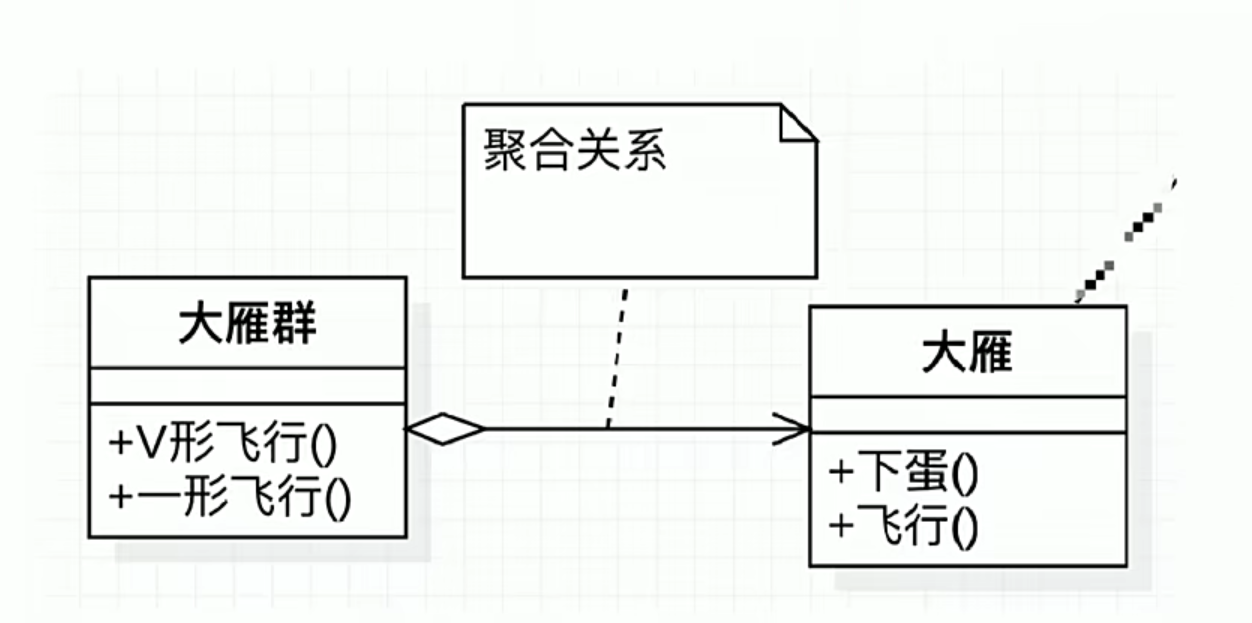
UML图记忆技巧
![[OC foundation framework] - [set array]](/img/b5/5e49ab9d026c60816f90f0c47b2ad8.png)
[OC foundation framework] - [set array]

Post training quantification of bminf

Improved deep embedded clustering with local structure preservation (Idec)

Using pkgbuild:: find in R language_ Rtools check whether rtools is available and use sys The which function checks whether make exists, installs it if not, and binds R and rtools with the writelines

ESP8266-RTOS物联网开发
随机推荐
Unsupported operation exception
LeetCode:剑指 Offer 03. 数组中重复的数字
LeetCode:39. 组合总和
多元聚类分析
I-BERT
Computer graduation design PHP Zhiduo online learning platform
[embedded] print log using JLINK RTT
Export IEEE document format using latex
Compétences en mémoire des graphiques UML
可变长参数
广州推进儿童友好城市建设,将探索学校周边200米设安全区域
[OC foundation framework] - string and date and time >
Simple use of promise in uniapp
超高效!Swagger-Yapi的秘密
After reading the programmer's story, I can't help covering my chest...
Ijcai2022 collection of papers (continuously updated)
What is an R-value reference and what is the difference between it and an l-value?
UML diagram memory skills
MYSQL卸载方法与安装方法
LeetCode:498. 对角线遍历