当前位置:网站首页>Post training quantification of bminf
Post training quantification of bminf
2022-07-06 08:57:00 【cyz0202】
BMINF
- BMINF It is a large model reasoning tool developed by Tsinghua University , At present, it is mainly for the team CPM Series of models for inference and optimization . The tool realizes memory / Video memory scheduling optimization , utilize cupy/cuda It realizes post training quantification And so on , This paper records and analyzes the post training quantization implementation of the tool .
- Main concern cupy operation cuda Realize the quantitative part , The principles involving quantification may not be introduced in detail , Readers need to consult other materials ;
- BMINF The team has recently refactored more code ; The code example I use below is 8 Months ago , Readers want to see BMINF Corresponding source code , Please check out 0.5 edition
Implement code analysis 1
The entry code of the quantification part is mainly in tools/migrate_xxx.py, Here we use tools/migrate_cpm2.py For example ;
main function
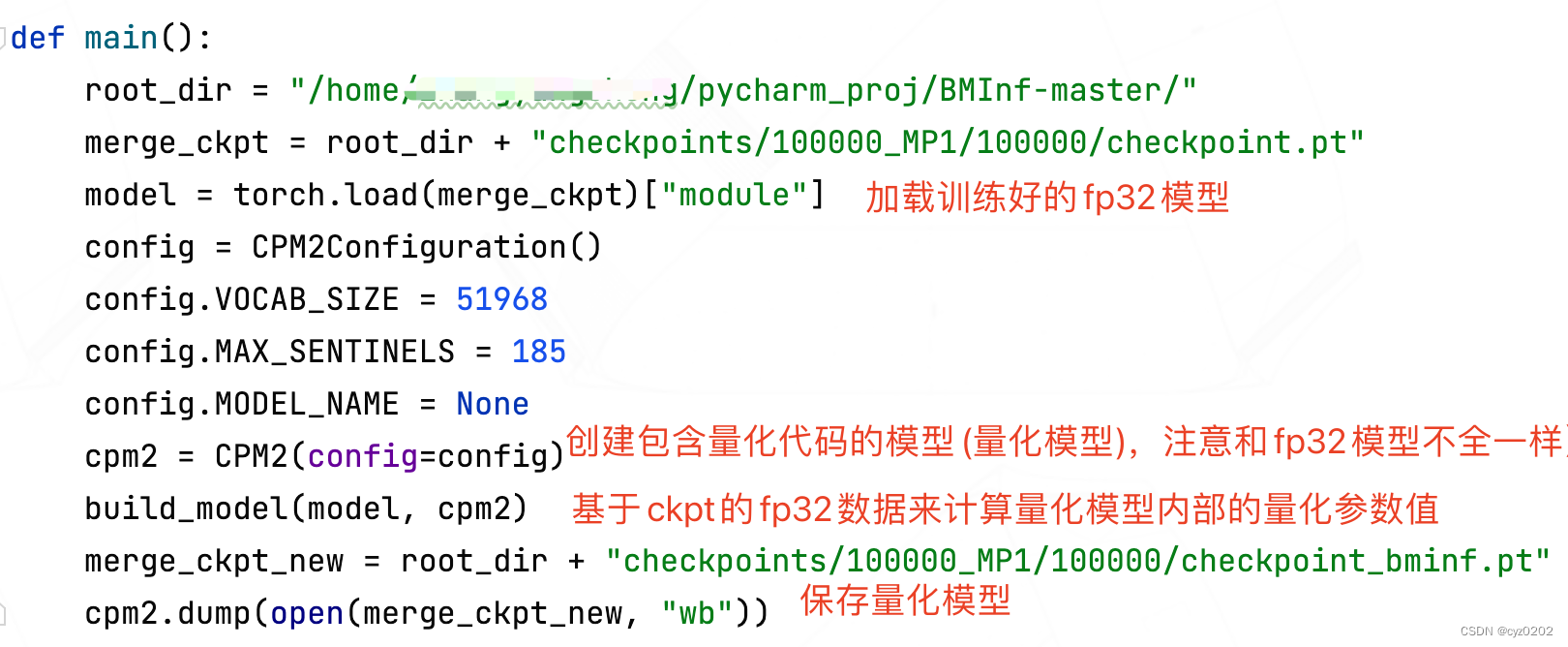
build_model function : be based on ckpt Of fp32 Calculate the quantitative parameter value inside the quantitative model

scale_build_parameter function : Calculate symmetrically quantized scale, And will scale And put the quantitative results into the corresponding parameters of the quantitative model ( It corresponds to model.encoder_kv.w_project_kv_scale and w_project_kv)

Take a look at how to save the quantitative results model.encoder_kv.w_project_kv_scale and w_project_kv How to define it

build_encoder/decoder function : Main call build_block, Deal with each block(layer)

build_block function : Or copy part module The parameters and quantification of another part module Parameters of

Summary : From fp32 The model will have different parameters copy To the realization of the corresponding position of the quantitative model ; Next, we will introduce how to use quantitative parameters in the quantitative model +cupy+cuda Calculate , Achieve acceleration ;
Implement code analysis 2
- With decoder Use attention module: partial_attetion Take an example for analysis (bminf/layers/attention)
- Go straight to the code , Please see comments
class PartialAttention(Layer):
def __init__(self, dim_in, dim_qkv, num_heads, is_self_attn):
self.is_self_attn = is_self_attn # self_attn still cross_attn
self.dim_in = dim_in
self.num_heads = num_heads
self.dim_qkv = dim_qkv
if self.is_self_attn:
self.w_project_qkv = Parameter((3, dim_qkv * num_heads, dim_in), cupy.int8) # Weight usage int8 quantitative , Here will receive fp32 Of ckpt The quantized results of corresponding parameters
self.w_project_qkv_scale = Parameter((3, dim_qkv * num_heads, 1), cupy.float16) # scale Use fp16; It is worth noting that scale It's right dim_in Of this dimension
else:
self.w_project_q = Parameter((dim_qkv * num_heads, dim_in), cupy.int8) # cross_attn shape It's a little different
self.w_project_q_scale = Parameter((dim_qkv * num_heads, 1), cupy.float16)
# Do it again before output linear
self.w_out = Parameter((dim_in, dim_qkv * num_heads), cupy.int8)
self.w_out_scale = Parameter((dim_in, 1), cupy.float16)
def quantize(self, allocator: Allocator, value: cupy.ndarray, axis=-1):
""" Quantization function ,allocator Allocate video memory ,value It is to be quantified fp16/32 value ;axis It's a quantitative dimension Notice a nested quantize function , This is real work ======================================================== Here are quantize Implementation of function : def quantize(x: cupy.ndarray, out: cupy.ndarray, scale: cupy.ndarray, axis=-1): assert x.dtype == cupy.float16 or x.dtype == cupy.float32 assert x.shape == out.shape if axis < 0: axis += len(x.shape) assert scale.dtype == cupy.float16 assert scale.shape == x.shape[:axis] + (1,) + x.shape[axis + 1:] # scale on gpu Calculation scale( Symmetry mode ) quantize_scale_kernel(x, axis=axis, keepdims=True, out=scale) quantize_copy_half(x, scale, out=out) # Calculation Quantitative results ======================================================== Here are quantize_scale_kernel and quantize_copy_half/float The implementation of the : # Back to quantize_scale_kernel It's a cuda The function on , Calculation quantification scale quantize_scale_kernel = create_reduction_func( # kernel finger cuda The function on , Here is the cupy Give Way cuda Create the corresponding function (kernel) 'bms_quantize_scale', # Name of the function created ('e->e', 'f->e', 'e->f', 'f->f'), # Specify the input -> Output data type ( come from numpy, Such as e representative float16,f yes float32) ('min_max_st<type_in0_raw>(in0)', 'my_max(a, b)', 'out0 = abs(a.value) / 127', 'min_max_st<type_in0_raw>'), # cuda What will be executed None, _min_max_preamble # If you need to use custom data structures , Write it here , Previous line min_max_st、my_max Is such as bminf Author defined , It's not shown here ) # return quantize_copy_half It's also a cuda function , The function is in cuda Calculate the quantized value on =x/scale; Note that symmetric quantization does not zero_point quantize_copy_half = create_ufunc( 'bms_quantize_copy_half', ('ee->b', 'fe->b', 'ff->b'), 'out0 = nearbyintf(half(in0 / in1))') # half finger fp16 quantize_copy_float = create_ufunc( 'bms_quantize_copy_float', ('ee->b', 'fe->b', 'ff->b'), 'out0 = nearbyintf(float(in0 / in1))') ======================================================== """
if axis < 0:
axis += len(value.shape)
# following 3 Lines allocate video memory to quantized values 、scale
nw_value = allocator.alloc_array(value.shape, cupy.int8)
scale_shape = value.shape[:axis] + (1,) + value.shape[axis + 1:]
scale = allocator.alloc_array(scale_shape, cupy.float16)
# Real quantization function , Calculation scale Value stored in scale in , The calculated quantized value is stored in nw_value in
quantize(value, nw_value, scale, axis=axis)
return nw_value, scale # Return the quantized value 、scale
def forward(self,
allocator: Allocator,
curr_hidden_state: cupy.ndarray, # (batch, dim_model)
past_kv: cupy.ndarray, # (2, batch, num_heads, dim_qkv, past_kv_len)
position_bias: Optional[cupy.ndarray], # (1#batch, num_heads, past_kv_len)
past_kv_mask: cupy.ndarray, # (1#batch, past_kv_len)
decoder_length: Optional[int], # int
):
batch_size, dim_model = curr_hidden_state.shape
num_heads, dim_qkv, past_kv_len = past_kv.shape[2:]
assert past_kv.shape == (2, batch_size, num_heads, dim_qkv, past_kv_len)
assert past_kv.dtype == cupy.float16
assert num_heads == self.num_heads
assert dim_qkv == self.dim_qkv
assert curr_hidden_state.dtype == cupy.float16
if self.is_self_attn:
assert decoder_length is not None
if position_bias is not None:
assert position_bias.shape[1:] == (num_heads, past_kv_len)
assert position_bias.dtype == cupy.float16
assert past_kv_mask.shape[-1] == past_kv_len
# value->(batch, dim_model), scale->(batch, 1) Here is one decoder-step, So there was no seq-len
# Quantify the input
value, scale = self.quantize(allocator, curr_hidden_state[:, :], axis=1)
if self.is_self_attn: # Self attention
qkv_i32 = allocator.alloc_array((3, batch_size, self.num_heads * self.dim_qkv, 1), dtype=cupy.int32)
else:
qkv_i32 = allocator.alloc_array((batch_size, self.num_heads * self.dim_qkv, 1), dtype=cupy.int32)
if self.is_self_attn:
# Self attention ,qkv Linear transformation is required ; Use igemm Give Way cuda perform 8bit matmul;
# Show later igemm Realization
igemm(
allocator,
self.w_project_qkv.value, # (3, num_head * dim_qkv, dim_model)
True, # Transposition
value[cupy.newaxis], # (1, batch_size, dim_model)
False,
qkv_i32[:, :, :, 0] # (3, batch_size, num_head * dim_qkv)
)
else:
# Cross attention , Yes q Do a linear transformation
igemm(
allocator,
self.w_project_q.value[cupy.newaxis], # (1, num_head * dim_qkv, dim_model)
True,
value[cupy.newaxis], # (1, batch_size, dim_model)
False,
qkv_i32[cupy.newaxis, :, :, 0] # (1, batch_size, num_head * dim_qkv)
)
# release value
del value
# convert int32 to fp16 The above linear transformation result int32 Convert to fp16
# Note that the whole process is not single int8 perhaps int Type calculation
assert qkv_i32._c_contiguous
qkv_f16 = allocator.alloc_array(qkv_i32.shape, dtype=cupy.float16)
if self.is_self_attn:
""" elementwise_copy_scale = create_ufunc('bms_scaled_copy', ('bee->e', 'iee->e', 'iee->f', 'iff->f'), 'out0 = in0 * in1 * in2') """
elementwise_copy_scale( # Perform inverse quantization , obtain fp16 Stored in out Inside
qkv_i32, # (3, batch_size, num_head * dim_qkv, 1)
self.w_project_qkv_scale.value[:, cupy.newaxis, :, :], # (3, 1#batch_size, dim_qkv * num_heads, 1)
scale[cupy.newaxis, :, :, cupy.newaxis], # (1#3, batch_size, 1, 1)
out=qkv_f16
)
else:
elementwise_copy_scale(
qkv_i32, # (1, batch_size, num_head * dim_qkv, 1)
self.w_project_q_scale.value, # (dim_qkv * num_heads, 1)
scale[:, :, cupy.newaxis], # (batch_size, 1, 1)
out=qkv_f16
)
del scale
del qkv_i32
# reshape
assert qkv_f16._c_contiguous
if self.is_self_attn:
qkv = cupy.ndarray((3, batch_size, self.num_heads, self.dim_qkv), dtype=cupy.float16, memptr=qkv_f16.data)
query = qkv[0] # (batch, num_heads, dim_qkv)
past_kv[0, :, :, :, decoder_length] = qkv[1] # Store as history kv, Avoid subsequent double counting
past_kv[1, :, :, :, decoder_length] = qkv[2]
del qkv
else:
query = cupy.ndarray((batch_size, self.num_heads, self.dim_qkv), dtype=cupy.float16, memptr=qkv_f16.data)
del qkv_f16
# calc attention score(fp16)
attention_score = allocator.alloc_array((batch_size, self.num_heads, past_kv_len, 1), dtype=cupy.float16)
fgemm( # Calculating the attention score is using float-gemm Calculation
allocator,
query.reshape(batch_size * self.num_heads, self.dim_qkv, 1), # (batch_size * num_heads, dim_qkv, 1)
False,
past_kv[0].reshape(batch_size * self.num_heads, self.dim_qkv, past_kv_len),
# ( batch_size * num_heads, dim_qkv, past_kv_len)
True,
attention_score.reshape(batch_size * self.num_heads, past_kv_len, 1)
# (batch_size * num_heads, past_kv_len, 1)
)
# mask Calculation
""" mask_attention_kernel = create_ufunc( 'bms_attention_mask', ('?ff->f',), 'out0 = in0 ? in1 : in2' # Selectors ) """
mask_attention_kernel(
past_kv_mask[:, cupy.newaxis, :, cupy.newaxis], # (batch, 1#num_heads, past_kv_len, 1)
attention_score,
cupy.float16(-1e10),
out=attention_score # (batch_size, self.num_heads, past_kv_len, 1)
)
if position_bias is not None:
attention_score += position_bias[:, :, :, cupy.newaxis] # (1#batch, num_heads, past_kv_len, 1)
# Calculation softmax float situation
temp_attn_mx = allocator.alloc_array((batch_size, self.num_heads, 1, 1), dtype=cupy.float16)
cupy.max(attention_score, axis=-2, out=temp_attn_mx, keepdims=True)
attention_score -= temp_attn_mx
cupy.exp(attention_score, out=attention_score)
cupy.sum(attention_score, axis=-2, out=temp_attn_mx, keepdims=True)
attention_score /= temp_attn_mx
del temp_attn_mx
# Calculation softmax*V
out_raw = allocator.alloc_array((batch_size, self.num_heads, self.dim_qkv, 1), dtype=cupy.float16)
fgemm( # Still use float gemm
allocator,
attention_score.reshape(batch_size * self.num_heads, past_kv_len, 1),
False,
past_kv[1].reshape(batch_size * self.num_heads, self.dim_qkv, past_kv_len),
False,
out_raw.reshape(batch_size * self.num_heads, self.dim_qkv, 1)
)
assert out_raw._c_contiguous
# obtain softmax(qk)*v result
out = cupy.ndarray((batch_size, self.num_heads * self.dim_qkv), dtype=cupy.float16, memptr=out_raw.data)
del attention_score
del out_raw
# The attention result vector continues to be quantified , So that we can do it again linear
# (batch_size, num_heads * dim_qkv, 1), (batch_size, 1, 1)
out_i8, scale = self.quantize(allocator, out, axis=1)
project_out_i32 = allocator.alloc_array((batch_size, dim_model, 1), dtype=cupy.int32)
# Do it again before output linear projection(igemm)
igemm(
allocator,
self.w_out.value[cupy.newaxis], # (1, dim_in, dim_qkv * num_heads)
True,
out_i8[cupy.newaxis],
False,
project_out_i32[cupy.newaxis, :, :, 0]
)
assert project_out_i32._c_contiguous
# (batch, dim_model, 1)
project_out_f16 = allocator.alloc_array(project_out_i32.shape, dtype=cupy.float16)
# Inverse quantification gets the final attention result fp16
elementwise_copy_scale(
project_out_i32,
self.w_out_scale.value, # (1#batch_size, dim_model, 1)
scale[:, :, cupy.newaxis], # (batch, 1, 1)
out=project_out_f16
)
return project_out_f16[:, :, 0] # (batch, dim_model)
- Summary of the above code : You can see that it is mainly for linear Quantify , Other such as norm、score、softmax Waiting is directly in float16 Count up ; The whole process is int、float Use alternately , quantitative 、 Inverse quantization alternates
- igemm function :cupy How to be in cuda Perform integral matrix multiplication on , It is based on cuda Just write the specification
def _igemm(allocator : Allocator, a, aT, b, bT, c, device, stream):
assert isinstance(a, cupy.ndarray)
assert isinstance(b, cupy.ndarray)
assert isinstance(c, cupy.ndarray)
assert len(a.shape) == 3 # (batch, m, k)
assert len(b.shape) == 3 # (batch, n, k)
assert len(c.shape) == 3 # (batch, n, m)
assert a._c_contiguous
assert b._c_contiguous
assert c._c_contiguous
assert a.device == device
assert b.device == device
assert c.device == device
lthandle = get_handle(device) # For the current gpu establish handler
# obtain batch_size
num_batch = 1
if a.shape[0] > 1 and b.shape[0] > 1:
assert a.shape[0] == b.shape[0]
num_batch = a.shape[0]
elif a.shape[0] > 1:
num_batch = a.shape[0]
else:
num_batch = b.shape[0]
# Calculation stride,batch Inner span sample
if a.shape[0] == 1:
stride_a = 0
else:
stride_a = a.shape[1] * a.shape[2] # m*k
if b.shape[0] == 1:
stride_b = 0
else:
stride_b = b.shape[1] * b.shape[2] # n*k
if aT: # Need to transpose ;aT It's usually True
m, k1 = a.shape[1:] # a [bs,m,k1]
else:
k1, m = a.shape[1:]
if bT:
k2, n = b.shape[1:]
else: # bT It's usually False
n, k2 = b.shape[1:] # b [bs,n,k]
assert k1 == k2 # a*b => k Dimension size should be the same
k = k1
assert c.shape == (num_batch, n, m) # c = a*b
stride_c = n * m
## compute capability: cuda edition
# Ampere >= 80
# Turing >= 75
cc = int(device.compute_capability)
v1 = ctypes.c_int(1) # Set constant 1, Follow up as CUDA Coefficient required by the specification
v0 = ctypes.c_int(0) # Set constant 0
""" # Set up a/b/c 3 Properties of matrix (rt, m, n, ld, order, batch_count, batch_offset)=> MatrixLayout_t The pointer # LayoutCache Used to create the representation of a matrix in video memory ( namely layout), Including data types , Row number 、 Number of columns ,batch size , Memory storage order (order, Including column storage mode 、 Row storage mode and so on )... # cublasLt Is load cuda Installation directory cublast lib Got ; # The following is about cublasLt Function of , For details, please move to bminf The source code and cuda official doc see ============================================================ class LayoutCache(HandleCache): # In the code layoutcache(...) Would call create, And return the pointer def create(self, rt, m, n, ld, order, batch_count, batch_offset): # Create a new matrix layout The pointer ret = cublasLt.cublasLtMatrixLayout_t() # The above pointer points to the new matrix layout;rt- data type ;m/n finger row/col;ld-leading_dimension In column mode, the number of rows ;checkCublasStatus Check whether the operation is successful according to the return status cublasLt.checkCublasStatus( cublasLt.cublasLtMatrixLayoutCreate(ret, rt, m, n, ld) ) # Set the storage format attribute of the matrix cublasLt.checkCublasStatus( cublasLt.cublasLtMatrixLayoutSetAttribute(ret, cublasLt.CUBLASLT_MATRIX_LAYOUT_ORDER, ctypes.byref(ctypes.c_int32(order)), ctypes.sizeof(ctypes.c_int32)) ) # Set the matrix batch_count attribute (batch Number of samples in ) cublasLt.checkCublasStatus( cublasLt.cublasLtMatrixLayoutSetAttribute(ret, cublasLt.CUBLASLT_MATRIX_LAYOUT_BATCH_COUNT, ctypes.byref(ctypes.c_int32(batch_count)), ctypes.sizeof(ctypes.c_int32)) ) cublasLt.checkCublasStatus( cublasLt.cublasLtMatrixLayoutSetAttribute(ret, cublasLt.CUBLASLT_MATRIX_LAYOUT_STRIDED_BATCH_OFFSET, ctypes.byref(ctypes.c_int64(batch_offset)), ctypes.sizeof(ctypes.c_int64)) ) return ret # Release the occupied video memory space after use def release(self, x): cublasLt.checkCublasStatus(cublasLt.cublasLtMatrixLayoutDestroy(x)) ============================================================ # Pay attention to the following Express row=shape[2], col=shape[1], Contrary to reality ; The reason why it is written here , It's for the sake of the earlier cuda Do the matching ; about cc>=75 Of , Will still pass transform Transform back row=shape[1], col=shape[2]; See below """
layout_a = layout_cache(cublasLt.CUDA_R_8I, a.shape[2], a.shape[1], a.shape[2], cublasLt.CUBLASLT_ORDER_COL, a.shape[0], stride_a) # a yes int8+ Column Storage
layout_b = layout_cache(cublasLt.CUDA_R_8I, b.shape[2], b.shape[1], b.shape[2], cublasLt.CUBLASLT_ORDER_COL, b.shape[0], stride_b) # b yes int8+ Column Storage
layout_c = layout_cache(cublasLt.CUDA_R_32I, c.shape[2], c.shape[1], c.shape[2], cublasLt.CUBLASLT_ORDER_COL, c.shape[0], stride_c) # c yes int32+ Column Storage
if cc >= 75:
# use tensor core
trans_lda = 32 * m # leading dimension of a
if cc >= 80:
trans_ldb = 32 * round_up(n, 32) # round_up Yes n Round up To 32 Multiple , Such as 28->32, 39->64
else:
trans_ldb = 32 * round_up(n, 8)
trans_ldc = 32 * m
stride_trans_a = round_up(k, 32) // 32 * trans_lda # (「k」// 32) * 32 * m >= k*m take Than a in 1 Samples A bigger one 32 Multiple space , Such as k=40->k=64 => stride_trans_a=64*m
stride_trans_b = round_up(k, 32) // 32 * trans_ldb
stride_trans_c = round_up(n, 32) // 32 * trans_ldc
trans_a = allocator.alloc( stride_trans_a * a.shape[0] ) # Distribution ratio a A bigger one 32 Multiple space , Pay attention, because it is int8(1 Bytes ), So the space size = The number of element
trans_b = allocator.alloc( stride_trans_b * b.shape[0] )
trans_c = allocator.alloc( ctypes.sizeof(ctypes.c_int32) * stride_trans_c * c.shape[0] ) # Note that int32, No int8
# establish trans_a/b/c Of layout
layout_trans_a = layout_cache(cublasLt.CUDA_R_8I, m, k, trans_lda, cublasLt.CUBLASLT_ORDER_COL32, a.shape[0], stride_trans_a)
if cc >= 80:
layout_trans_b = layout_cache(cublasLt.CUDA_R_8I, n, k, trans_ldb, cublasLt.CUBLASLT_ORDER_COL32_2R_4R4, b.shape[0], stride_trans_b) # Use more advanced COL Storage mode
else:
layout_trans_b = layout_cache(cublasLt.CUDA_R_8I, n, k, trans_ldb, cublasLt.CUBLASLT_ORDER_COL4_4R2_8C, b.shape[0], stride_trans_b)
layout_trans_c = layout_cache(cublasLt.CUDA_R_32I, m, n, trans_ldc, cublasLt.CUBLASLT_ORDER_COL32, num_batch, stride_trans_c)
# establish a Of tranform descriptor And set up transpose attribute ( Similar to above layout, Belong to CUDA Specification requirements ), return descriptor;transform The main attributes include data types , Whether to transpose, etc
# Notice that the data type used is INT32, Because transform The operation multiplies the input by a certain coefficient ( This refers to the integer defined above v1/v0), The two types should match , So first let the input from INT8->INT32, Let... After the calculation INT32->INT8( See below where used )
transform_desc_a = transform_cache(cublasLt.CUDA_R_32I, aT)
transform_desc_b = transform_cache(cublasLt.CUDA_R_32I, not bT)
transform_desc_c = transform_cache(cublasLt.CUDA_R_32I, False)
""" # establish CUDA function cublasLtMatrixTransform(CUDA Can't simply pass one a.T let a Transposition , More complex specifications are needed ) cublasLtMatrixTransform = LibFunction(lib, "cublasLtMatrixTransform", cublasLtHandle_t, cublasLtMatrixTransformDesc_t, ctypes.c_void_p, ctypes.c_void_p, cublasLtMatrixLayout_t, ctypes.c_void_p, ctypes.c_void_p, cublasLtMatrixLayout_t, ctypes.c_void_p, cublasLtMatrixLayout_t, cudaStream_t, cublasStatus_t) # cublasLtMatrixTransform() => C = alpha*transformation(A) + beta*transformation(B) Matrix transformation operation cublasStatus_t cublasLtMatrixTransform( cublasLtHandle_t lightHandle, cublasLtMatrixTransformDesc_t transformDesc, const void *alpha, # It's usually 1 const void *A, cublasLtMatrixLayout_t Adesc, const void *beta, # It's usually 0, here C=transform(A) const void *B, cublasLtMatrixLayout_t Bdesc, void *C, cublasLtMatrixLayout_t Cdesc, cudaStream_t stream); """
cublasLt.checkCublasStatus(
cublasLt.cublasLtMatrixTransform( # Yes a Perform the transform operation ( The transformation defined above is 32I and aT)
lthandle, transform_desc_a,
ctypes.byref(v1), a.data.ptr, layout_a,
ctypes.byref(v0), 0, 0, # Don't use B
trans_a.ptr, layout_trans_a, stream.ptr
)
)
cublasLt.checkCublasStatus(
cublasLt.cublasLtMatrixTransform( # Yes b Perform the transform operation ( The transformation defined above is 32I and not bT)
lthandle, transform_desc_b,
ctypes.byref(v1), b.data.ptr, layout_b,
ctypes.byref(v0), 0, 0,
trans_b.ptr, layout_trans_b, stream.ptr
)
)
if a.shape[0] != num_batch:
layout_trans_a = layout_cache(cublasLt.CUDA_R_8I, m, k, trans_lda, cublasLt.CUBLASLT_ORDER_COL32, num_batch, 0)
if b.shape[0] != num_batch:
if cc >= 80:
layout_trans_b = layout_cache(cublasLt.CUDA_R_8I, n, k, trans_ldb, cublasLt.CUBLASLT_ORDER_COL32_2R_4R4, num_batch, 0)
else:
layout_trans_b = layout_cache(cublasLt.CUDA_R_8I, n, k, trans_ldb, cublasLt.CUBLASLT_ORDER_COL4_4R2_8C, num_batch, 0)
# establish matmul Narrator : Intermediate data type , Calculation type ( I / O type ),aT,bT
# Use INT32 preservation INT8 The result of the calculation is ; The last two parameters represent a/b Transpose or not
matmul_desc = matmul_cache(cublasLt.CUDA_R_32I, cublasLt.CUBLAS_COMPUTE_32I, False, True)
""" # Calculation D = alpha*(A*B) + beta*(C) cublasStatus_t cublasLtMatmul( cublasLtHandle_t lightHandle, cublasLtMatmulDesc_t computeDesc, const void *alpha, const void *A, cublasLtMatrixLayout_t Adesc, const void *B, cublasLtMatrixLayout_t Bdesc, const void *beta, const void *C, cublasLtMatrixLayout_t Cdesc, void *D, cublasLtMatrixLayout_t Ddesc, const cublasLtMatmulAlgo_t *algo, void *workspace, size_t workspaceSizeInBytes, cudaStream_t stream); """
cublasLt.checkCublasStatus( cublasLt.cublasLtMatmul(
lthandle, # gpu Handle
matmul_desc,
ctypes.byref(ctypes.c_int32(1)), # alpha=1
trans_a.ptr, # a data
layout_trans_a, # a Format
trans_b.ptr,
layout_trans_b,
ctypes.byref(ctypes.c_int32(0)), # beta=0, No addition C bias , namely D = alpha*(A*B)
trans_c.ptr, # Don't use
layout_trans_c, # Don't use
trans_c.ptr, # D namely C, Belong to in-place( Replace in place )
layout_trans_c,
0,
0,
0,
stream.ptr
))
cublasLt.checkCublasStatus(
cublasLt.cublasLtMatrixTransform( # according to transform_desc_c For the result C Do it once transform(int32, No transpose )
lthandle, transform_desc_c,
ctypes.byref(v1), trans_c.ptr, layout_trans_c,
ctypes.byref(v0), 0, 0,
c.data.ptr, layout_c,
stream.ptr
)
)
else:
pass # The difference between here and above is Use old version cuda, Therefore, it is omitted and will not be repeated , If you are interested, please check the source code yourself
summary
- The above is for BMINF Quantitative analysis of implementation code , Used to learn quantification +cupy+cuda( The concrete is cublasLt) The implementation of the ;
- The code only implements the simplest symmetric quantization ; Use cupy+cublasLt Realize the quantization of linear layer ; The whole process is quantification and inverse quantification ,int and float Alternate use of ;
- Of the above process C++ Version is also called cublasLt Same function , The writing is similar to , If you are interested, please check NVIDIA Example -LtIgemmTensor
- The above only involves CUDA/cublasLt Part of the application of , For more applications, please refer to CUDA The official manual ;
- Unavoidable omissions , Please advise
边栏推荐
- Notes 01
- I-BERT
- pytorch查看张量占用内存大小
- 随手记01
- 【ROS】usb_ Cam camera calibration
- [OC]-<UI入门>--常用控件-UIButton
- [Hacker News Weekly] data visualization artifact; Top 10 Web hacker technologies; Postman supports grpc
- LeetCode:387. 字符串中的第一个唯一字符
- How to effectively conduct automated testing?
- Delay initialization and sealing classes
猜你喜欢

Simclr: comparative learning in NLP
Nacos 的安装与服务的注册
Swagger setting field required is mandatory

Improved deep embedded clustering with local structure preservation (Idec)

Fairguard game reinforcement: under the upsurge of game going to sea, game security is facing new challenges
JVM quick start
Warning in install. packages : package ‘RGtk2’ is not available for this version of R
704 binary search
【嵌入式】使用JLINK RTT打印log

LeetCode:221. 最大正方形
随机推荐
力扣每日一题(二)
LeetCode:162. 寻找峰值
Problems encountered in connecting the database of the project and their solutions
LeetCode:26. Remove duplicates from an ordered array
JVM quick start
使用标签模板解决用户恶意输入的问题
BMINF的后训练量化实现
软件压力测试常见流程有哪些?专业出具软件测试报告公司分享
LeetCode:124. Maximum path sum in binary tree
MySQL uninstallation and installation methods
Improved deep embedded clustering with local structure preservation (Idec)
注意力机制的一种卷积替代方式
ant-design的走马灯(Carousel)组件在TS(typescript)环境中调用prev以及next方法
Leetcode: Sword finger offer 48 The longest substring without repeated characters
LeetCode:836. Rectangle overlap
LeetCode:34. 在排序数组中查找元素的第一个和最后一个位置
After reading the programmer's story, I can't help covering my chest...
UnsupportedOperationException异常
Light of domestic games destroyed by cracking
Excellent software testers have these abilities