当前位置:网站首页>运维,放过监控-也放过自己吧
运维,放过监控-也放过自己吧
2022-07-06 09:00:00 【java领域】
根据多年和运维打交道的经历,我发现,运维常常让监控变得无效。。。
1.我的监控故事
我做过两年多的运维工作,后面就转做运维平台开发了,也一步步看着监控系统越来越没用。
1.1 有用的监控
当我做运维要负责oncall时,我一直认为监控系统做的还可以,并不是因为做了太多事情,而是因为运维的业务还是单体应用,也没有太多的监控需要加。
记得那会公司还是用Nagios(估计新人已经没多少人知道了),不过监控的维护工作着实费劲。后面我就开始研究zabbix,最大的好处就是它可以discovery&自动添加监控。后面我又搭了一套ELK,把业务日志都收集到一起,监控就齐活了。 由于没有添加太多告警,那会的每个告警基本都得处理,最常见的问题就是百度来爬数据,我有一套屡试不爽的处理流程: 1.看指标:如果是xx业务的负载高, 有90%的概率是爬虫导致的 2.看日志:在kibana上看访问记录,找出topx的IP段 3.封访问:用iptables封掉
这就是我唯一一段的运维监控经历。由于业务简单、监控原始反而让我感觉告警是有用的。
1.2 无用的仪表盘
1.2.1 疯狂自动化
当我转运维开发后,我发现运维对监控的需求也变了。因为自动化能力的提升,各种开源的监控系统逐步完善,运维就开始在平台里面拼命的加各种自动化的需求,对于监控系统就是自动的给业务绑定各种监控模板、告警模板、grafana仪表盘
结果也可想而知,由于告警实在太多,运维直接屏蔽了公司的告警短信。大部分情况下都是靠业务侧发现问题,运维再介入排查。
1.2.2 好看而没用的仪表盘
由于收集的指标数据实在太多,为了可以给业务侧输出,运维就搞起了grafana仪表盘。不过由于grafana仪表盘上的指标实在太多,页面还会经常卡住,业务研发看着一个页面上几十个指标,也不知道哪个有用,最终还是得来找运维。

为了方便研发查看日志,运维也搞了ELK,将各种日志全部收集进去,然后将kibana丢给了业务研发。结果也可想而知,除了少数几个爱折腾的,kibana上的dashboard也没有太多人看。
我一直相信运维的初衷都是好的,但从结果上来看,嗨的只有运维,毕竟运维很少看自己做的仪表盘。。
1.3 没有质变
随着google sre概念的兴起,运维似乎是找到了最后一根稻草,毕竟这是google的运维方法论。于是,运维又开始同研发制定各种SLO、SLI指标,依据4个黄金指标(延迟、流量、错误和饱和度)来继续自丰富自己的告警库,并制定P0、P1、P2等各种告警分级,试图改变当前困境。

但是由于业务架构微服务化,并且采用敏捷开发的模式,实际上业务的迭代速度非常快。大部分sre本身并不是做开发出身,同时严重的配比不足(研发和运维比例),导致各种指标随着时间快速失效。其结果就是告警依旧没用,每次复盘就是再加一条告警,当然这条告警也几乎不会被触发。
这就是我经历的监控故事,你有哪些故事呢?
2.对监控的偏见
在对这些失败的监控经验的总结过程中,我发现两个本质的问题:
一直试图通过归纳过去发生的单个问题,来预测未来可能发生的普遍问题,并忽略未来在时空上复杂的变化一直专注于优化传统的探针模型(使用脚本测试,检查恢复并且报警)、图形化趋势展示、报警模型, 并不断提升相关流程的自动化
上述问题只代表我当前对监控的认知,并不知道对错,也没有答案。下面则是我对监控系统当前建设的一些偏见。
2.1 人工智能还是人机交互
喝着咖啡做运维
前同事令我印象最深刻的就是这句话了。说完这句话的半年后,他就开始研究AIOPS了,又过了半年他就离职了,组里也再没人提AIOPS了。大部分运维对AIOPS最大的需求可能就是根因分析了,不过这就像是一座大山立在AIOPS的门外,大部分运维团队连爬的勇气也没有。
我一直没想明白一个问题:
运维自己都不一定能排查出问题原因,为什么会指望机器能实现这个事情。
人和机器相比,机器更擅长于做海量数据的分析,而人则更擅长做决策。所以相比aiops我认为人机交互可能更靠谱一些:
机器对海量数据进行全面分析,由运维对分析结果进行人脑决策
不过感觉这事也并不容易,因为现在的sre痴迷开发的程度已经顾不上做这些事情了。决策本身也需要对数据有一定的敏感性。
2.2 监控要专注能力建设
在过去的监控系统建设中,大家一般喜欢按照架构做垂直切分,可能长这个样子:

我认为产生这种分层的主要原因是:组织架构(康威定律)和职责分离。在这种分层下,运维通常就只负责下面两层,对于上层问题的处理,可能定位到某个具体的URL就结束了,剩下的就是研发的事情了。
如果要解决当前这个困境,我认为应该摒弃过去按照职责进行系统建设的方式,比如做个基础监控系统、网络监控系统、业务监控系统,而是转向围绕业务价值分阶段进行能力建设,比如基础的数据采集、传输、分析、存储、展示等能力。转型成为提供海量数据收集和中央化规则计算、统一分析和报警能力的现代化监控系统【google sre】在能力建设过程中,平台团队应该以真实需求为目标,搭建最小可用平台(Thinnesr Viable Platform, TVP),并在团队中分享最佳实践和主动赋能用户,逐步成就卓越用户。同时要避免分享的都是没落地的方法论,毕竟大家都很忙。
2.3 尝试变的有效
当处理问题时,就会发现公司的监控系统比知道的多,运维、研发、DBA、redis等每个部门都有自己的监控系统和仪表盘,出问题时,每个人看的都是自己部门搞的监控。为了能够建立统一的视角,有能力的公司又会倒腾出统一监控这种东西:从不同的系统里面获取各种数据,统一进行汇总分析存储,最终统一监控又会带来数据实时性、准确性、存储成本、海量数据处理等新的问题,而且这事一时半会也搞不定。

不过这事真的有意义嘛?对于这种基础的数据的采集、分析和存储其实已经有很多商业化的方案,为什么会觉得自己几个人的小团队,配合一堆开源软件,可以做的比一个几十人的专业团队做的更好呢,而且这事离业务那么远,除了能让自己的kpi更好看,可能也并没有带来什么别的改变。
随着造的轮子越多,也慢慢发现自己变的越无效,一直在基础问题上徘徊。通常越基础的问题,解决方案也越通用,同时解决这类问题的ROI也越低,所做的工作也越无效。也不要过分强调自己场景的特殊性,除非只是想搞一些虚荣指标,而不解决本质问题。 那什么是有效的呢?我认为核心就是:
关注用户、关注业务,放弃过去通过经验的归纳来解决普遍问题,尝试利用数据分析的人机交互聚焦于核心业务,并通过AI/自动化处理支撑业务和通用业务
不过这事很难,好在我不做监控。。。
3.展望

去年有一个跟监控相关的很火的方向:可观测性。我对可观测性并没有太多的实践,不过在跟朋友聊可观测性时发现一些问题,这里更多的是想写下自己的困惑:
1.可观测性解决什么问题
每当聊可观测性时,我就发现大家一致认为可观测性可以解决所有的问题,就好比一把屠龙刀,所过之处寸草不生。可你要是详细问问用可观测性做了什么的时候,就会有点时光倒流的感觉,又回到各种仪表盘,满屏指标的时代。你有可观测性的故事嘛?
2.数据收集全面开花
可观测性技术发展速度感觉非常快,相关开源项目也越来越多,不过在数据收集上有个令我诧异的问题:有一天别人跟我说,可以在生产环境收集profiling做可观测性定位业务代码问题。诧异的点并不是技术实现,而是在于什么样的业务需要这种级别的可观测性,这种可观测性面向的用户又是谁,要解决的问题是什么?你有答案嘛?
3.新瓶装旧酒
如果你跟同事介绍可观测性由metric、log、tracing三部分组成的时候,很容易被老运维diss,他会告诉你我们现在都已经有了,只是不太好用,丰富下就可以了,这没什么新技术,不过是新瓶装旧酒而已。这时候我通常就会提出google之前发的关于<<有意义的可用性>>里面提到的问题,如何衡量用户级别的有意义的可用性,虽然我也没有答案,不过我只想启发下对问题的思考。你是怎么理解这个问题的呢?
小伙伴们有兴趣想了解内容和更多相关学习资料的请点赞收藏+评论转发+关注我,后面会有很多干货。我有一些面试题、架构、设计类资料可以说是程序员面试必备!所有资料都整理到网盘了,需要的话欢迎下载!私信我回复【666】即可免费获取
边栏推荐
- [OC-Foundation框架]-<字符串And日期与时间>
- Pytest parameterization some tips you don't know / pytest you don't know
- Redis之发布订阅
- Mise en œuvre de la quantification post - formation du bminf
- Global and Chinese markets for small seed seeders 2022-2028: Research Report on technology, participants, trends, market size and share
- Blue Bridge Cup_ Single chip microcomputer_ Measure the frequency of 555
- [OC foundation framework] - [set array]
- Using label template to solve the problem of malicious input by users
- QML control type: menu
- [oc]- < getting started with UI> -- common controls uibutton
猜你喜欢
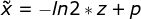
I-BERT

Digital people anchor 618 sign language with goods, convenient for 27.8 million people with hearing impairment

Different data-driven code executes the same test scenario
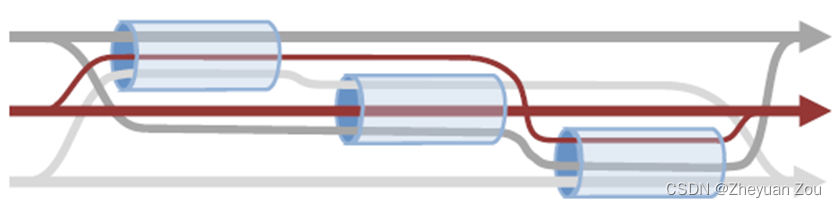
Advanced Computer Network Review(4)——Congestion Control of MPTCP

Advance Computer Network Review(1)——FatTree
自定义卷积注意力算子的CUDA实现
Servlet learning diary 8 - servlet life cycle and thread safety
【图的三大存储方式】只会用邻接矩阵就out了
基于B/S的影视创作论坛的设计与实现(附:源码 论文 sql文件 项目部署教程)
![[text generation] recommended in the collection of papers - Stanford researchers introduce time control methods to make long text generation more smooth](/img/10/c0545cb34621ad4c6fdb5d26b495ee.jpg)
[text generation] recommended in the collection of papers - Stanford researchers introduce time control methods to make long text generation more smooth
随机推荐
How to intercept the string correctly (for example, intercepting the stock in operation by applying the error information)
Pytest参数化你不知道的一些使用技巧 /你不知道的pytest
Redis geospatial
Redis之性能指标、监控方式
Pytest's collection use case rules and running specified use cases
CUDA realizes focal_ loss
I-BERT
Blue Bridge Cup_ Single chip microcomputer_ Measure the frequency of 555
Leetcode problem solving 2.1.1
Appears when importing MySQL
LeetCode:162. Looking for peak
一篇文章带你了解-selenium工作原理详解
Leetcode刷题题解2.1.1
Parameterization of postman
Intel distiller Toolkit - Quantitative implementation 3
LeetCode:26. Remove duplicates from an ordered array
LeetCode:836. Rectangle overlap
Redis之cluster集群
BN折叠及其量化
CUDA实现focal_loss