当前位置:网站首页>Multivariate cluster analysis
Multivariate cluster analysis
2022-07-06 09:04:00 【Also far away】
One 、 Code
import pandas as pd
from pandas import DataFrame
from sklearn.cluster import KMeans
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
# Read the file
datafile = u'student-mat.xlsx' # File location ,u To prevent the path from having Chinese names , There is no , It can be omitted
outfile = 'stu.xlsx'
data = pd.read_excel(datafile) # datafile yes excel file , So use read_excel, If it is csv For documents read_csv
d = DataFrame(data)
# clustering
n = 5 # Coalescence 5 Class data
mod = KMeans(n_clusters=n)
mod.fit_predict(d) # y_pred Represents the result of clustering
# Coalescence 5 Class data , Count the amount of data under each cluster , And find their center
r1 = pd.Series(mod.labels_).value_counts() # How many samples are there under each class
r2 = pd.DataFrame(mod.cluster_centers_) # center
r = pd.concat([r2, r1], axis=1)
r.columns = list(d.columns) + [u' Number of categories ']
# Mark each piece of data with which category it is divided
r = pd.concat([d, pd.Series(mod.labels_, index=d.index)], axis=1)
r.columns = list(d.columns) + [u' Clustering categories ']
print(r)
r.to_excel(outfile) # If you need to save to local , Just write this column
# Visualization process
ts = TSNE()
ts.fit_transform(r)
ts = pd.DataFrame(ts.embedding_, index=r.index)
a = ts[r[u' Clustering categories '] == 0]
plt.plot(a[0], a[1], 'r.')
a = ts[r[u' Clustering categories '] == 1]
plt.plot(a[0], a[1], 'go')
a = ts[r[u' Clustering categories '] == 2]
plt.plot(a[0], a[1], 'g*')
a = ts[r[u' Clustering categories '] == 3]
plt.plot(a[0], a[1], 'b.')
a = ts[r[u' Clustering categories '] == 4]
plt.plot(a[0], a[1], 'b*')
plt.show()
Two 、 result

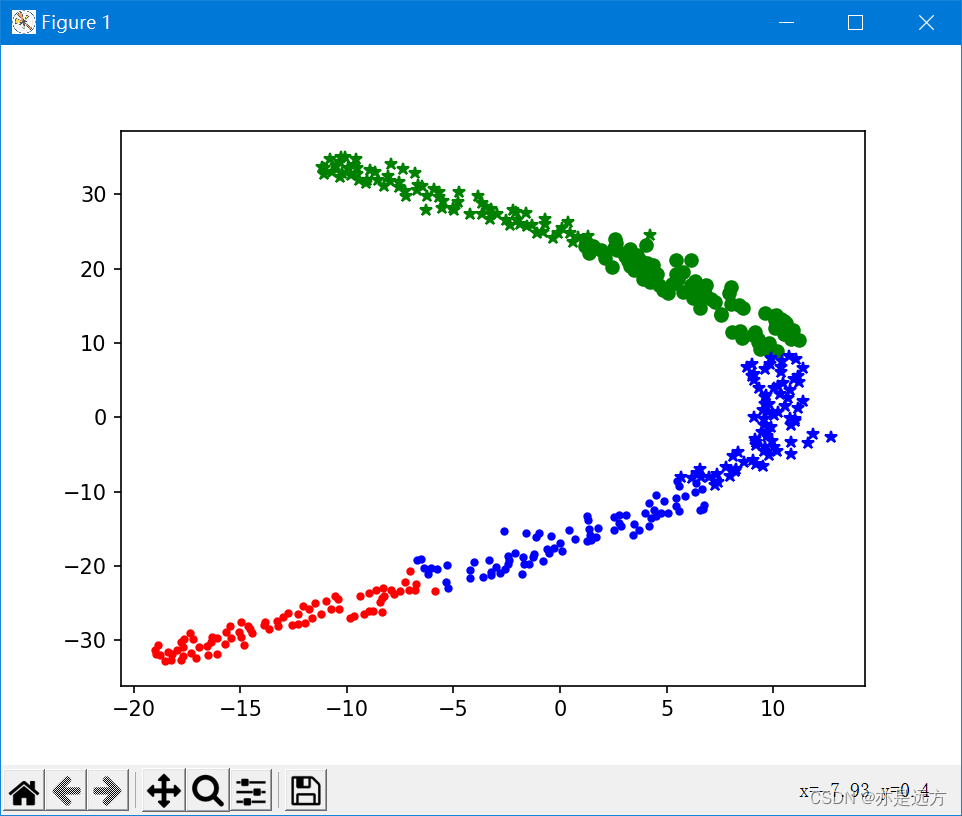
3、 ... and 、 Data sets
边栏推荐
猜你喜欢

![[MySQL] multi table query](/img/eb/9d54df9a5c6aef44e35c7a63b286a6.jpg)





随机推荐
vb. Net changes with the window, scales the size of the control and maintains its relative position
LeetCode:673. Number of longest increasing subsequences
Once you change the test steps, write all the code. Why not try yaml to realize data-driven?
如何正确截取字符串(例:应用报错信息截取入库操作)
UML图记忆技巧
Leetcode: Jianzhi offer 03 Duplicate numbers in array
Navicat premium create MySQL create stored procedure
[sword finger offer] serialized binary tree
BN folding and its quantification
LeetCode:剑指 Offer 48. 最长不含重复字符的子字符串
Variable length parameter
一改测试步骤代码就全写 为什么不试试用 Yaml实现数据驱动?
[MySQL] limit implements paging
Advance Computer Network Review(1)——FatTree
The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
UML圖記憶技巧
The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
LeetCode:39. Combined sum
【文本生成】论文合集推荐丨 斯坦福研究者引入时间控制方法 长文本生成更流畅
Leetcode: Sword finger offer 42 Maximum sum of continuous subarrays