当前位置:网站首页>SimCLR:NLP中的对比学习
SimCLR:NLP中的对比学习
2022-07-06 08:53:00 【InfoQ】
论文简介
- 诸神黄昏时代的对比学习
- “军备竞赛”时期的对比学习
- 使用预训练好的 Bert 直接获得句子向量,可以是 CLS 位的向量,也可以是不同 token 向量的平均值。
- Bert-flow^[On the Sentence Embeddings from Pre-trained Language Models],主要是利用流模型校正 Bert 的向量。
- Bert-whitening^[Whitening Sentence Representations for Better Semantics and Faster Retrieval],用预训练 Bert 获得所有句子的向量,得到句子向量矩阵,然后通过一个线性变换把句子向量矩阵变为一个均值 0,协方差矩阵为单位阵的矩阵。
- Sentence-Bert (SBERT)^[Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks],通过 Bert 的孪生网络获得两个句子的向量,进行有监督学习,SBERT 的结构如下图所示。

什么是dropout
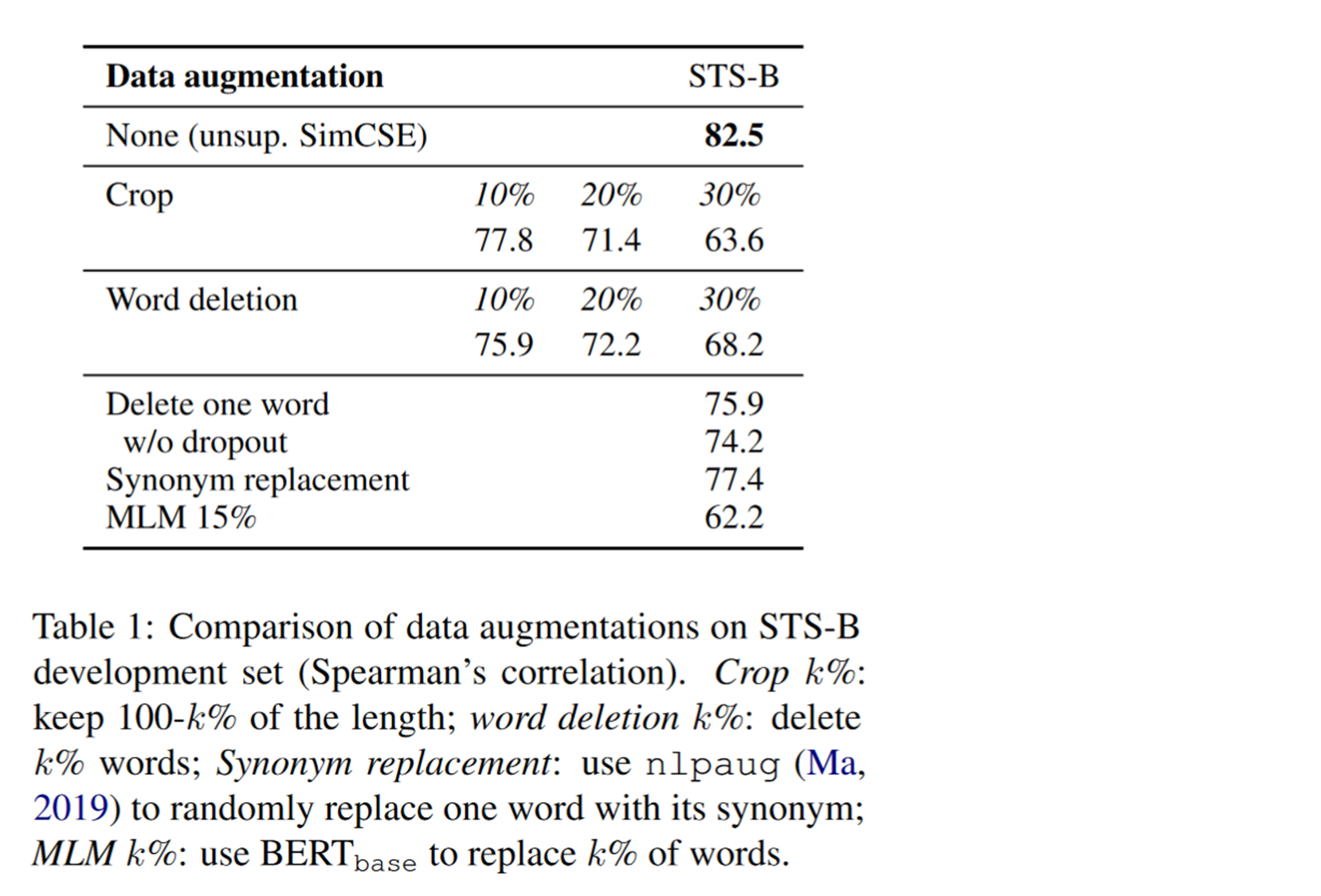
dropout和其他数据增强方法进行比较
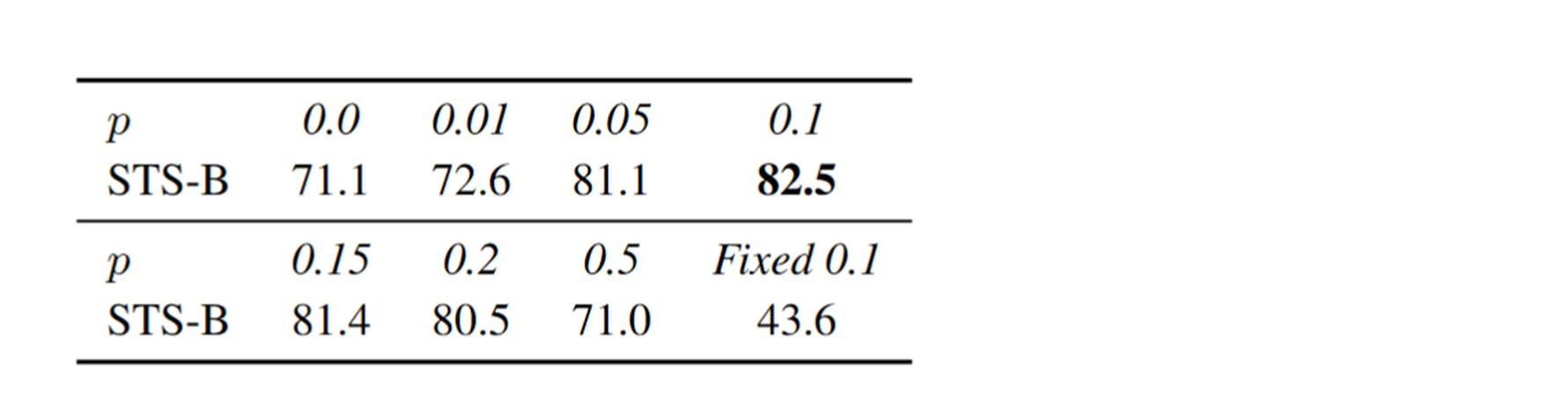
不同的dropout rate
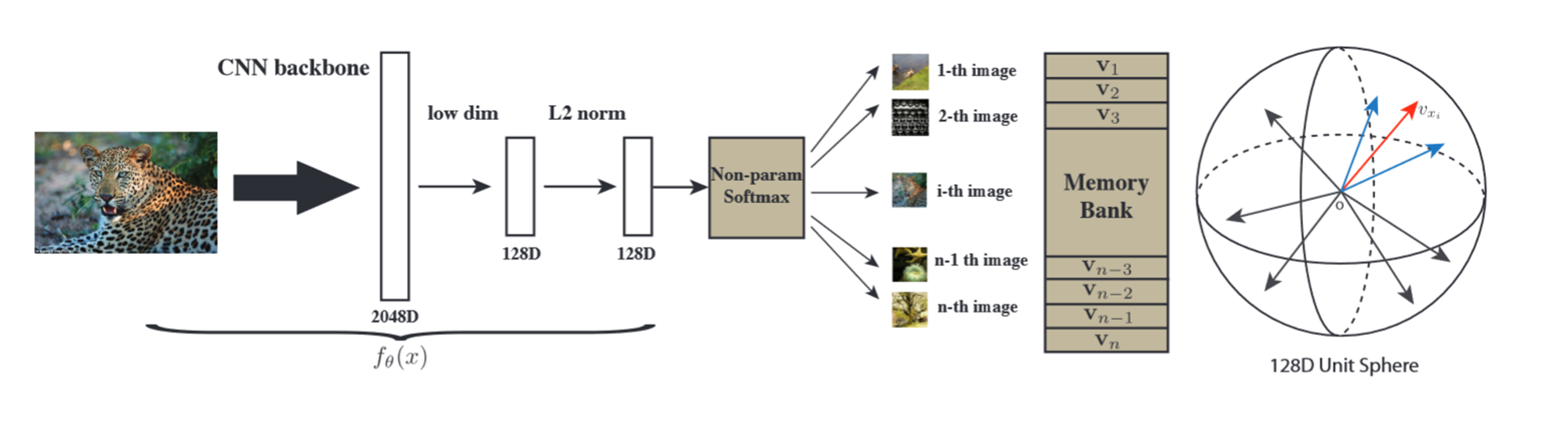
对比学习评价指标
- alignment 计算所有正样本对之间的距离,如果 alignment 越小,则正样本的向量越接近,对比学习效果越好,计算公式如下:$$
- uniformity 表示所有句子向量分布的均匀程度,越小表示向量分布越均匀,对比学习效果越好,计算公式如下:$$\ell_{\text {uniform }} \triangleq \log \quad \mathbb{E}{x, y \stackrel{i . i . d .}{\sim} p{\text {data }}} e^{-2|f(x)-f(y)|^{2}}$$
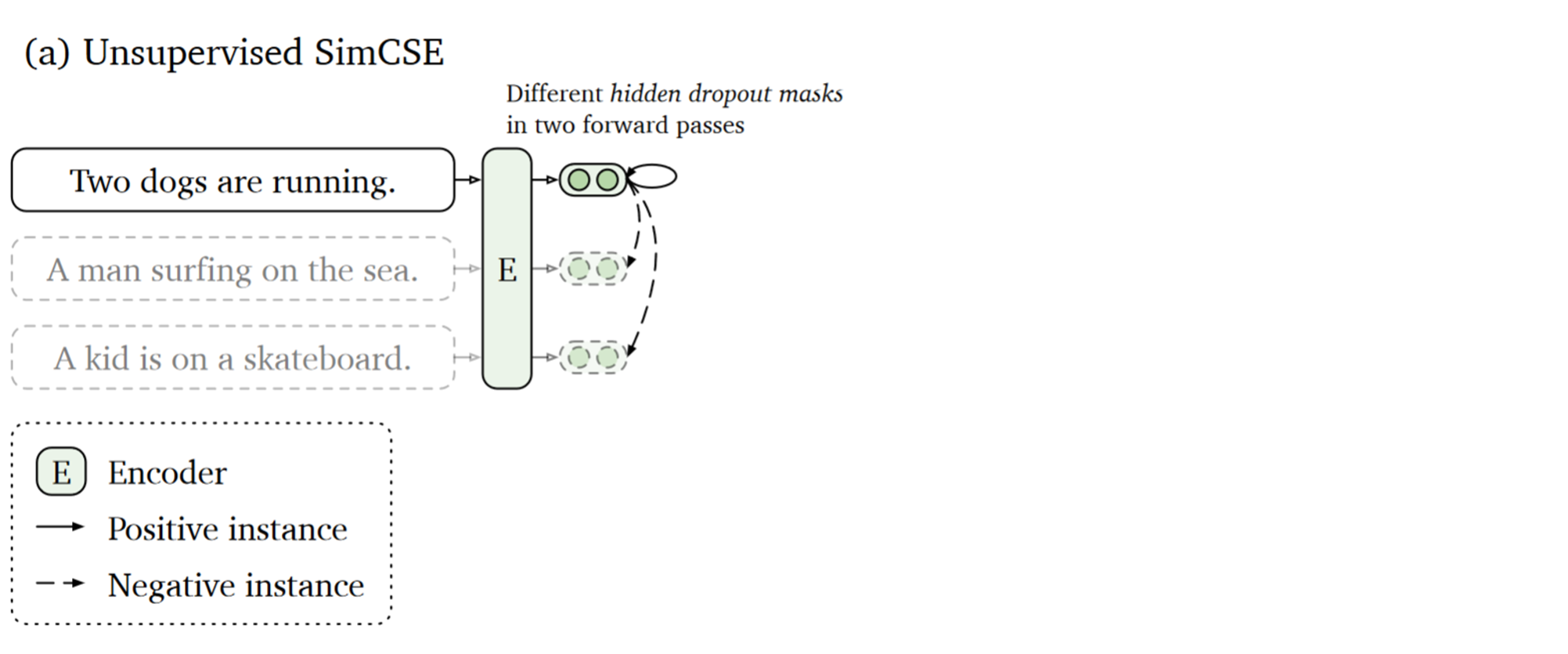
无监督
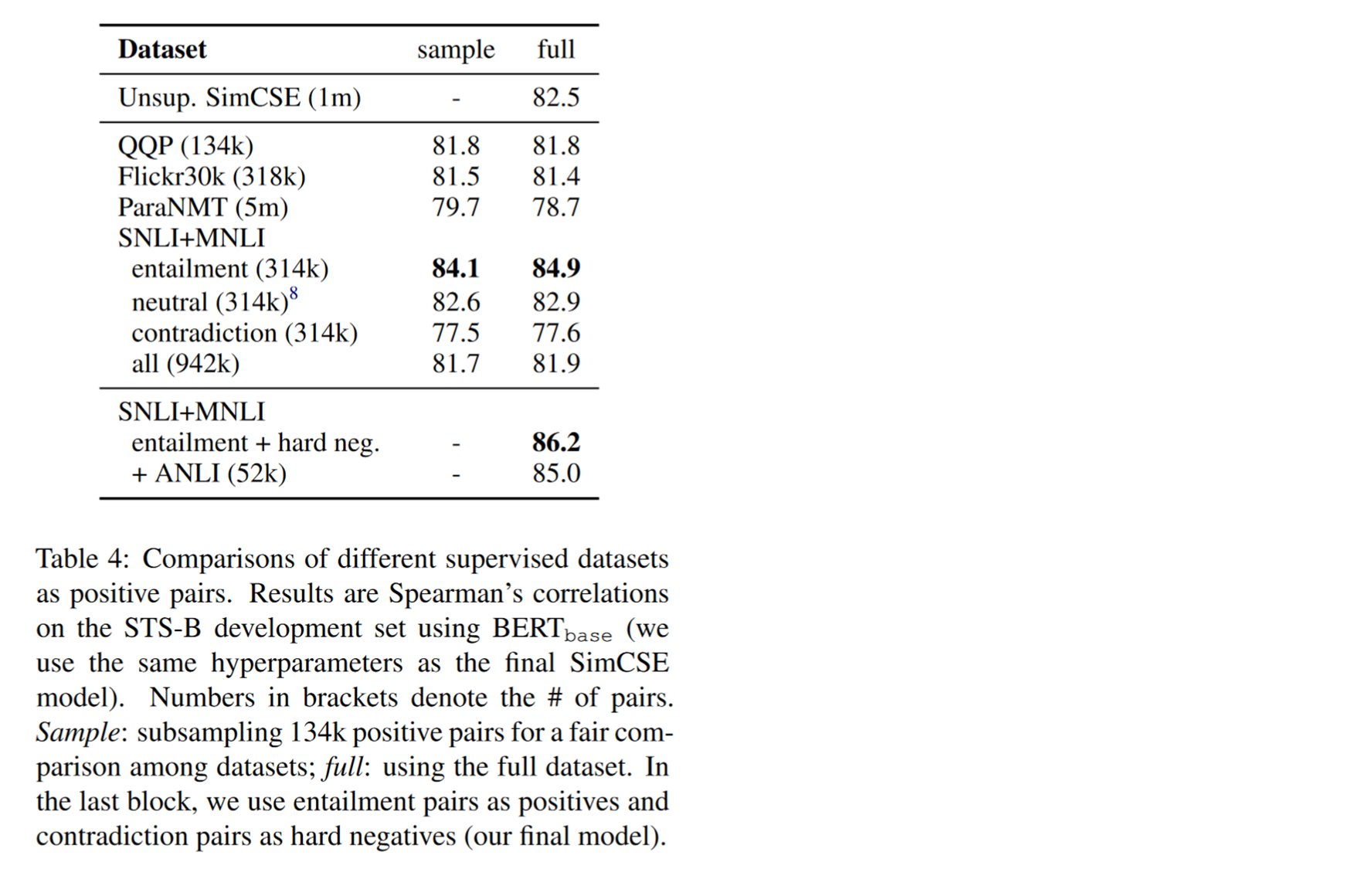
有监督

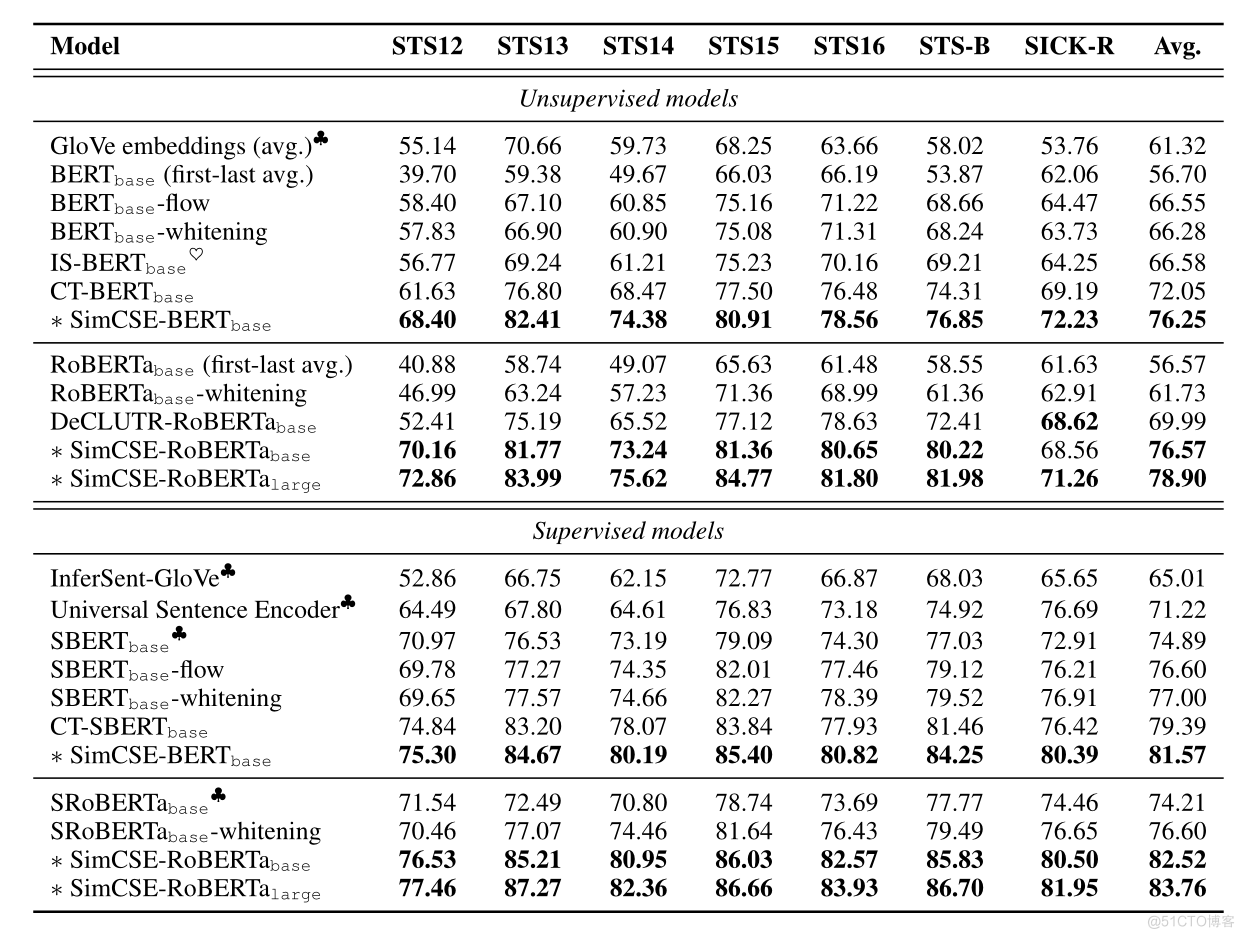
结果
代码实践
pip install simcse
SimCSE("在这里填写不同版本")from simcse import SimCSE
model = SimCSE("princeton-nlp/sup-simcse-bert-base-uncased")
embeddings = model.encode("A woman is reading.")

sentences_a = ['A woman is reading.', 'A man is playing a guitar.']
sentences_b = ['He plays guitar.', 'A woman is making a photo.']
similarities = model.similarity(sentences_a, sentences_b)
similarities1 = model.similarity('A woman is reading.', 'A man is playing a guitar.')
similarities2 = model.similarity('He plays guitar.', 'A man is playing a guitar.')

sentences = ['A woman is reading.', 'A man is playing a guitar.']
model.build_index(sentences)
results = model.search("He plays guitar.")
similarities2 = model.similarity('He plays guitar.', 'A man is playing a guitar.')He plays guitar.A man is playing a guitar.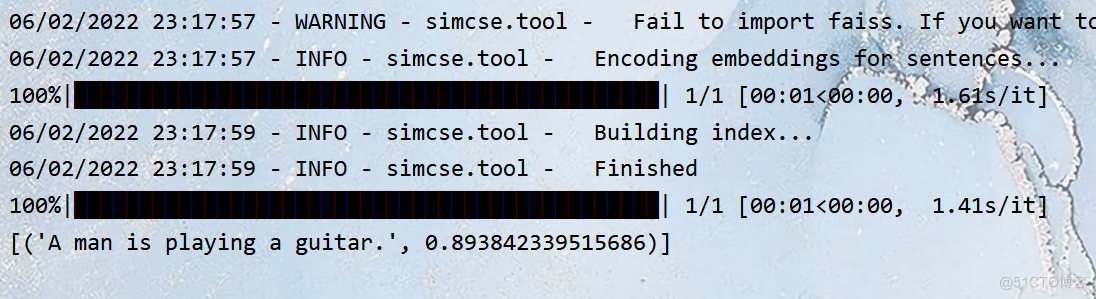
边栏推荐
- Mongodb installation and basic operation
- [MySQL] limit implements paging
- What are the common processes of software stress testing? Professional software test reports issued by companies to share
- LeetCode:34. 在排序数组中查找元素的第一个和最后一个位置
- PC easy to use essential software (used)
- Bitwise logical operator
- LeetCode:剑指 Offer 42. 连续子数组的最大和
- [OC-Foundation框架]--<Copy对象复制>
- I-BERT
- The harm of game unpacking and the importance of resource encryption
猜你喜欢
After reading the programmer's story, I can't help covering my chest...
vb. Net changes with the window, scales the size of the control and maintains its relative position
Simple use of promise in uniapp
![[OC-Foundation框架]---【集合数组】](/img/b5/5e49ab9d026c60816f90f0c47b2ad8.png)
[OC-Foundation框架]---【集合数组】
TP-LINK 企业路由器 PPTP 配置

Roguelike game into crack the hardest hit areas, how to break the bureau?

LeetCode:221. Largest Square
Indentation of tabs and spaces when writing programs for sublime text
Problems in loading and saving pytorch trained models

Using pkgbuild:: find in R language_ Rtools check whether rtools is available and use sys The which function checks whether make exists, installs it if not, and binds R and rtools with the writelines
随机推荐
Computer cleaning, deleted system files
Cesium draw points, lines, and faces
Fairguard game reinforcement: under the upsurge of game going to sea, game security is facing new challenges
Navicat Premium 创建MySql 创建存储过程
R language uses the principal function of psych package to perform principal component analysis on the specified data set. PCA performs data dimensionality reduction (input as correlation matrix), cus
Excellent software testers have these abilities
LeetCode:39. 组合总和
Unsupported operation exception
Simple use of promise in uniapp
How to conduct interface test? What are the precautions? Nanny level interpretation
Niuke winter vacation training 6 maze 2
Philosophical enlightenment from single point to distributed
ROS compilation calls the third-party dynamic library (xxx.so)
PC easy to use essential software (used)
@Jsonbackreference and @jsonmanagedreference (solve infinite recursion caused by bidirectional references in objects)
[MySQL] multi table query
JVM quick start
UnsupportedOperationException异常
Current situation and trend of character animation
项目连接数据库遇到的问题及解决