当前位置:网站首页>Selenium+pytest automated test framework practice (Part 2)
Selenium+pytest automated test framework practice (Part 2)
2022-07-06 09:00:00 【Automated test seventh uncle】
Preface
This article continues from the previous article .
One 、 Simple learning element positioning
In daily work , I've seen a lot of right clicking directly in the browser Copy Xpath Students who copy elements . The element expression thus obtained is placed in webdriver Running in the middle is often not stable enough , Some minor changes like the front end , Will cause the element to be unable to locate NoSuchElementException Report errors .
Therefore, in practical work and study, we should strengthen our element positioning ability , Use as much as possible xpath and CSS selector This relatively stable positioning Syntax . because CSS selector Your grammar is hard to understand , It's very unfriendly to new people , And compared to xpath Some positioning syntax is missing . So we choose xpath Carry out our element positioning Syntax .
1.1xpath
1.1.1 Rule of grammar
xpath Is a door in XML The language in which information is found in a document .
expression | Introduce | remarks |
/ | The root node | Absolute path |
// | All children of the current node | Relative paths |
* | Of all node elements | |
@ | Prefix of attribute name | @class @id |
*[1] | [] Subscript operator | |
[] | [ ] Predicate expression | //input[@id='kw'] |
Following-sibling | Siblings after the current node | |
preceding-sibling | The sibling before the current node | |
parent | The parent node of the current node |
1.1.2 Positioning tools
- chropath advantage : This is a Chrome Browser test location plug-in , Be similar to firepath, I tried it out. The overall feeling is very good . He is very friendly to Xiaobai . shortcoming : Installing this plug-in requires FQ.
- Katalon The script recorded by the recording tool will also contain information about locating elements
- Write it yourself —— I recommend this advantage : The way I recommend , Because when proficient to a certain extent , It will be more intuitive to write , And when there are problems running automated tests , Can quickly locate . shortcoming : It needs to be xpath and CSS selector Grammar accumulation , It's not easy to get started .
Two 、 Manage page elements
The test address selected for this article is Baidu homepage , So the corresponding elements are also Baidu home page .
There is a directory in the project framework design page_element It is specially used to store the files of locating elements .
Through the comparison of various configuration files , What I choose here is YAML File format . It's easy to read , Good interaction .
We are page_element Create a new one in search.yaml file .
Search box : "id==kw"
The candidate : "css==.bdsug-overflow"
Search for candidates : "css==#form div li"
Search button : "id==su"The element location file is created , Next, we need to read this file .
stay common Create... In the directory readelement.py file .
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import os
import yaml
from config.conf import cm
class Element(object):
""" Get elements """
def __init__(self, name):
self.file_name = '%s.yaml' % name
self.element_path = os.path.join(cm.ELEMENT_PATH, self.file_name)
if not os.path.exists(self.element_path):
raise FileNotFoundError("%s file does not exist !" % self.element_path)
with open(self.element_path, encoding='utf-8') as f:
self.data = yaml.safe_load(f)
def __getitem__(self, item):
""" get attribute """
data = self.data.get(item)
if data:
name, value = data.split('==')
return name, value
raise ArithmeticError("{} Keyword does not exist in :{}".format(self.file_name, item))
if __name__ == '__main__':
search = Element('search')
print(search[' Search box '])
By special means __getitem__ Implementation calls any property , Read yaml The value in .
In this way, we realize the storage and calling of positioning elements .
But there is a problem , How can we make sure that every element we write doesn't go wrong , Human error is inevitable , But we can run the review of files through code . At present, not all problems can be found .
So we write a document , stay script Create a script in the script file directory inspect.py file , For all elements yaml Document review .
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import os
import yaml
from config.conf import cm
from utils.times import running_time
@running_time
def inspect_element():
""" Check that all elements are correct
You can only do a simple check
"""
for files in os.listdir(cm.ELEMENT_PATH):
_path = os.path.join(cm.ELEMENT_PATH, files)
with open(_path, encoding='utf-8') as f:
data = yaml.safe_load(f)
for k in data.values():
try:
pattern, value = k.split('==')
except ValueError:
raise Exception(" There is no... In the element expression `==`")
if pattern not in cm.LOCATE_MODE:
raise Exception('%s Medium element 【%s】 No type specified ' % (_path, k))
elif pattern == 'xpath':
assert '//' in value,\
'%s Medium element 【%s】xpath Type does not match value ' % (_path, k)
elif pattern == 'css':
assert '//' not in value, \
'%s Medium element 【%s]css Type does not match value ' % (_path, k)
else:
assert value, '%s Medium element 【%s】 Type does not match value ' % (_path, k)
if __name__ == '__main__':
inspect_element()
Execute the document :
Check element done! when 0.002 second !You can see , In a very short time , We'll just fill in YAML The document was reviewed .
Now the basic components we need have been roughly completed .
Next, we will take the most important step , encapsulation selenium.
3、 ... and 、 encapsulation Selenium Base class
In the factory model, we write this :
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
driver.find_element_by_xpath("//input[@id='kw']").send_keys('selenium')
driver.find_element_by_xpath("//input[@id='su']").click()
time.sleep(5)
driver.quit()
Very straightforward , Simple , And clear .
establish driver object , Open Baidu web page , Search for selenium, Click on the search , Then stay 5 second , View results , Finally, close the browser .
Then why should we package selenium How about the method . First of all, we use the more primitive method mentioned above , Basically not suitable for doing UI Automated testing , Because in UI The actual operation of the interface is far more complex , Maybe because of the Internet , Or control reason , Our elements haven't been shown yet , Click or enter . So we need to encapsulate selenium Method , Through built-in explicit wait or certain conditional statements , To build a stable method . And put selenium Methods are encapsulated , It is conducive to normal code maintenance .
We are page directories creating webpage.py file .
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
"""
selenium Base class
This document contains selenium Encapsulation method of base class
"""
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException
from config.conf import cm
from utils.times import sleep
from utils.logger import log
class WebPage(object):
"""selenium Base class """
def __init__(self, driver):
# self.driver = webdriver.Chrome()
self.driver = driver
self.timeout = 20
self.wait = WebDriverWait(self.driver, self.timeout)
def get_url(self, url):
""" Open the URL and verify """
self.driver.maximize_window()
self.driver.set_page_load_timeout(60)
try:
self.driver.get(url)
self.driver.implicitly_wait(10)
log.info(" Open the web page :%s" % url)
except TimeoutException:
raise TimeoutException(" open %s Timeout, please check the network or URL server " % url)
@staticmethod
def element_locator(func, locator):
""" Element locator """
name, value = locator
return func(cm.LOCATE_MODE[name], value)
def find_element(self, locator):
""" Look for a single element """
return WebPage.element_locator(lambda *args: self.wait.until(
EC.presence_of_element_located(args)), locator)
def find_elements(self, locator):
""" Find multiple identical elements """
return WebPage.element_locator(lambda *args: self.wait.until(
EC.presence_of_all_elements_located(args)), locator)
def elements_num(self, locator):
""" Get the number of the same elements """
number = len(self.find_elements(locator))
log.info(" The same elements :{}".format((locator, number)))
return number
def input_text(self, locator, txt):
""" Input ( Clear... Before entering )"""
sleep(0.5)
ele = self.find_element(locator)
ele.clear()
ele.send_keys(txt)
log.info(" Input text :{}".format(txt))
def is_click(self, locator):
""" Click on """
self.find_element(locator).click()
sleep()
log.info(" Click on the element :{}".format(locator))
def element_text(self, locator):
""" Get current text"""
_text = self.find_element(locator).text
log.info(" Get text :{}".format(_text))
return _text
@property
def get_source(self):
""" Get the page source code """
return self.driver.page_source
def refresh(self):
""" Refresh the page F5"""
self.driver.refresh()
self.driver.implicitly_wait(30)
In the file, we use explicit wait for selenium Of click,send_keys Other methods , We did a second encapsulation . Improve the success rate of operation .
All right, we're done POM About half of the model . Next, let's go to the page object .
Four 、 Create page objects
stay page_object Create one in the directory searchpage.py file .
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
from page.webpage import WebPage, sleep
from common.readelement import Element
search = Element('search')
class SearchPage(WebPage):
""" Search class """
def input_search(self, content):
""" Enter search """
self.input_text(search[' Search box '], txt=content)
sleep()
@property
def imagine(self):
""" Search Lenovo """
return [x.text for x in self.find_elements(search[' The candidate '])]
def click_search(self):
""" Click on the search """
self.is_click(search[' Search button '])In this document, we are interested in , Enter search keywords , Click on the search , Search Lenovo , It was packaged .
And configured comments .
At ordinary times, we should form the habit of writing notes , Because after a while , No comment , The code is hard to read .
Well, our page object is now complete . Now let's start writing test cases . Before we start the test, let's get familiar with pytest The test framework .
5、 ... and 、 Simple understanding Pytest
open pytest The official website of the framework .
# content of test_sample.py
def inc(x):
return x + 1
def test_answer():
assert inc(3) == 5I don't think the official tutorial is suitable for introductory reading , And there is no Chinese version . If you need a tutorial, you can find it by yourself .
5.1pytest.ini
pytest Configuration files in the project , It can be done to pytest Perform global control of operations during execution .
Create a new directory at the project root pytest.ini file .
[pytest]
addopts = --html=report.html --self-contained-html
addopts Specify other parameter descriptions during execution :--html=report/report.html --self-contained-html Generate pytest-html Styled report -s Output the mode information in our use case -q Test quietly -v You can output more detailed execution information of use cases , For example, the file where the use case is located and the name of the use case
6、 ... and 、 Write test cases
We will use pytest Write test cases .
stay TestCase Create... In the directory test_search.py file .
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import re
import pytest
from utils.logger import log
from common.readconfig import ini
from page_object.searchpage import SearchPage
class TestSearch:
@pytest.fixture(scope='function', autouse=True)
def open_baidu(self, drivers):
""" Open the baidu """
search = SearchPage(drivers)
search.get_url(ini.url)
def test_001(self, drivers):
""" Search for """
search = SearchPage(drivers)
search.input_search("selenium")
search.click_search()
result = re.search(r'selenium', search.get_source)
log.info(result)
assert result
def test_002(self, drivers):
""" Test search candidates """
search = SearchPage(drivers)
search.input_search("selenium")
log.info(list(search.imagine))
assert all(["selenium" in i for i in search.imagine])
if __name__ == '__main__':
pytest.main(['TestCase/test_search.py'])
We'll write it when we use it .
- pytest.fixture This implements and unittest Of setup,teardown The same pre start , Rear cleaning decorator .
- The first test case :
- We achieved in Baidu selenium keyword , And click the search button , And in the search results , Using regular search results page source code , The returned quantity is greater than 10 We think that through .
- Second test case :
- We did , Search for selenium, Then assert whether all the results in the search candidates have selenium keyword .
Finally, we write a statement to execute the startup below .
At this time, we should enter the execution , But there is a problem , We haven't put driver Pass on .
7、 ... and 、conftest.py
Let's create a new one in the root of the project conftest.py file .
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import pytest
from py.xml import html
from selenium import webdriver
driver = None
@pytest.fixture(scope='session', autouse=True)
def drivers(request):
global driver
if driver is None:
driver = webdriver.Chrome()
driver.maximize_window()
def fn():
driver.quit()
request.addfinalizer(fn)
return driver
@pytest.hookimpl(hookwrapper=True)
def pytest_runtest_makereport(item):
"""
When the test fails , Automatic screenshot , Show to html In the report
:param item:
"""
pytest_html = item.config.pluginmanager.getplugin('html')
outcome = yield
report = outcome.get_result()
report.description = str(item.function.__doc__)
extra = getattr(report, 'extra', [])
if report.when == 'call' or report.when == "setup":
xfail = hasattr(report, 'wasxfail')
if (report.skipped and xfail) or (report.failed and not xfail):
file_name = report.nodeid.replace("::", "_") + ".png"
screen_img = _capture_screenshot()
if file_name:
html = '<div><img src="data:image/png;base64,%s" alt="screenshot" style="width:1024px;height:768px;" ' \
'onclick="window.open(this.src)" align="right"/></div>' % screen_img
extra.append(pytest_html.extras.html(html))
report.extra = extra
def pytest_html_results_table_header(cells):
cells.insert(1, html.th(' Use case name '))
cells.insert(2, html.th('Test_nodeid'))
cells.pop(2)
def pytest_html_results_table_row(report, cells):
cells.insert(1, html.td(report.description))
cells.insert(2, html.td(report.nodeid))
cells.pop(2)
def pytest_html_results_table_html(report, data):
if report.passed:
del data[:]
data.append(html.div(' The passed use case does not capture the log output .', class_='empty log'))
def _capture_screenshot():
'''
The screenshot is saved as base64
:return:
'''
return driver.get_screenshot_as_base64()
conftest.py The test framework pytest Glue file , It uses fixture Methods , Encapsulate and deliver driver.
8、 ... and 、 Execute use cases
Above, we have completed the whole framework and test cases .
We go to the home directory of the current project and execute the command :
pytestCommand line output :
Test session starts (platform: win32, Python 3.7.7, pytest 5.3.2, pytest-sugar 0.9.2)
cachedir: .pytest_cache
metadata: {'Python': '3.7.7', 'Platform': 'Windows-10-10.0.18362-SP0', 'Packages': {'pytest': '5.3.2', 'py': '1.8.0', 'pluggy': '0.13.1'}, 'Plugins': {'forked': '1.1.3', 'html': '2.0.1', 'metadata': '1.8.0', 'ordering': '0.6', 'rerunfailures': '8.0', 'sugar': '0.9.2', 'xdist': '1.31.0'}, 'JAVA_HOME': 'D:\\Program Files\\Java\\jdk1.8.0_131'}
rootdir: C:\Users\hoou\PycharmProjects\web-demotest, inifile: pytest.ini
plugins: forked-1.1.3, html-2.0.1, metadata-1.8.0, ordering-0.6, rerunfailures-8.0, sugar-0.9.2, xdist-1.31.0
collecting ...
DevTools listening on ws://127.0.0.1:10351/devtools/browser/78bef34d-b94c-4087-b724-34fb6b2ef6d1
TestCase\test_search.py::TestSearch.test_001 * 50% █████
TestCase\test_search.py::TestSearch.test_002 * 100% ██████████
------------------------------- generated html file: file://C:\Users\hoou\PycharmProjects\web-demotest\report\report.html --------------------------------
Results (12.90s):
2 passed
You can see that two use cases have been executed successfully .
Project report A... Is generated in the directory report.html file .
This is the generated test report file .
Nine 、 Send E-mail
When the project is completed , You need to send it to yourself or someone else's email to check the results .
Send our email module .
stay utils Create a new send_mail.py file
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import zmail
from config.conf import cm
def send_report():
""" Send report """
with open(cm.REPORT_FILE, encoding='utf-8') as f:
content_html = f.read()
try:
mail = {
'from': '[email protected]',
'subject': ' The latest test report email ',
'content_html': content_html,
'attachments': [cm.REPORT_FILE, ]
}
server = zmail.server(*cm.EMAIL_INFO.values())
server.send_mail(cm.ADDRESSEE, mail)
print(" Test email sent successfully !")
except Exception as e:
print("Error: Unable to send mail ,{}!", format(e))
if __name__ == "__main__":
''' Please go to config/conf.py File settings QQ Email account number and password '''
send_report()
Execute the document :
Test email sent successfully !You can see that the test report email has been sent successfully . Open the mailbox .


Successfully received the email .
This demo Even if the project is completed as a whole ; Isn't it interesting , I have a great sense of achievement at the moment of sending email .
summary
Through this article , You must have been right about pytest+selenium The framework has an overall cognition , On the road of automated testing, another step has been taken . If you like, you can like collection comments and pay attention , Pay attention to the different surprises I give you every day .

边栏推荐
- Computer graduation design PHP Zhiduo online learning platform
- 【文本生成】论文合集推荐丨 斯坦福研究者引入时间控制方法 长文本生成更流畅
- Alibaba cloud server mining virus solution (practiced)
- 一改测试步骤代码就全写 为什么不试试用 Yaml实现数据驱动?
- LeetCode:162. 寻找峰值
- SAP ui5 date type sap ui. model. type. Analysis of the parsing format of date
- BN折叠及其量化
- Compétences en mémoire des graphiques UML
- Leetcode: Jianzhi offer 03 Duplicate numbers in array
- Variable length parameter
猜你喜欢
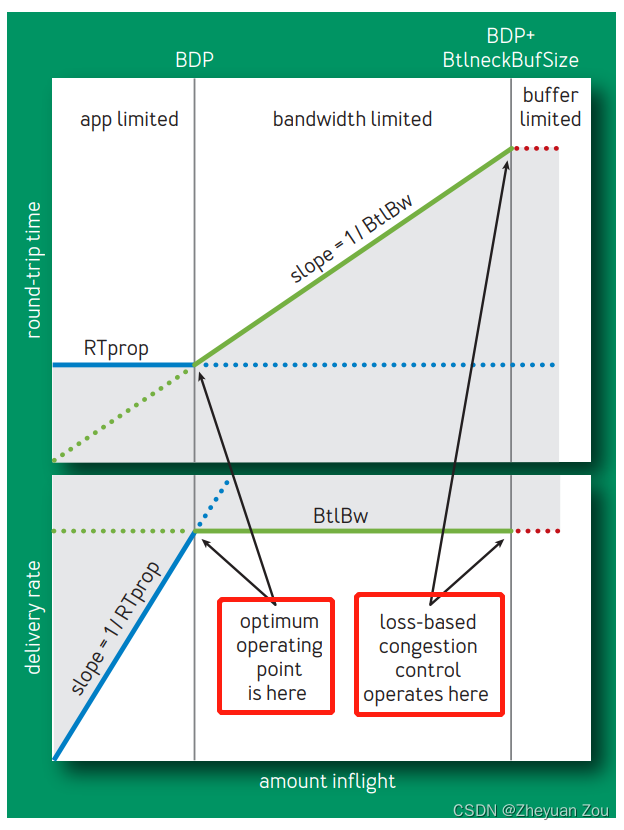
Advanced Computer Network Review(3)——BBR
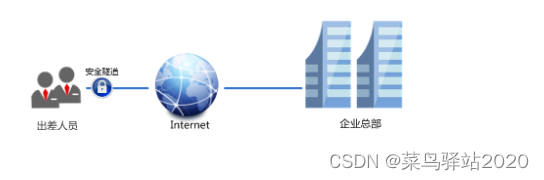
TP-LINK enterprise router PPTP configuration
数学建模2004B题(输电问题)
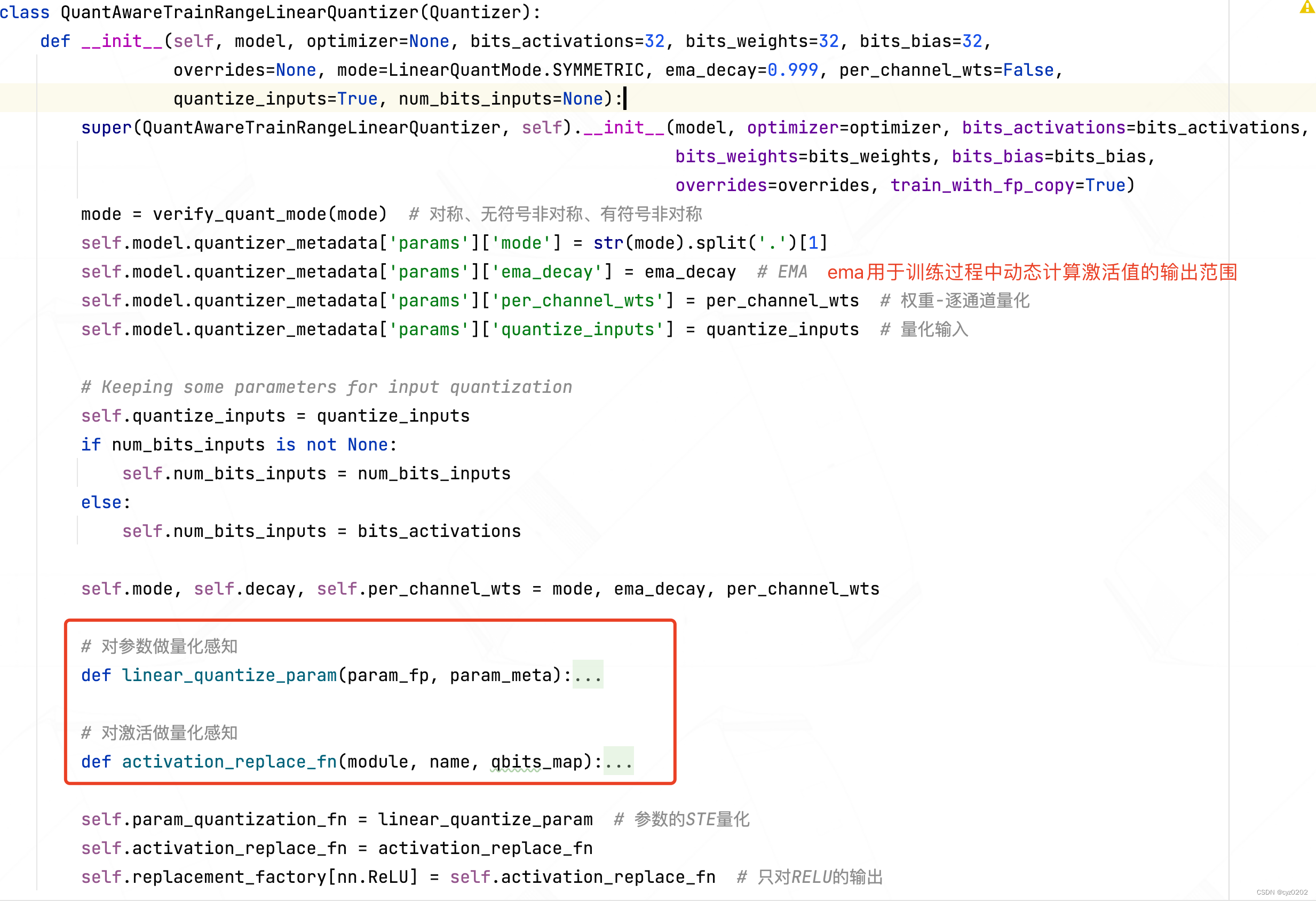
Intel Distiller工具包-量化实现3

Intel distiller Toolkit - Quantitative implementation 1
vb.net 随窗口改变,缩放控件大小以及保持相对位置
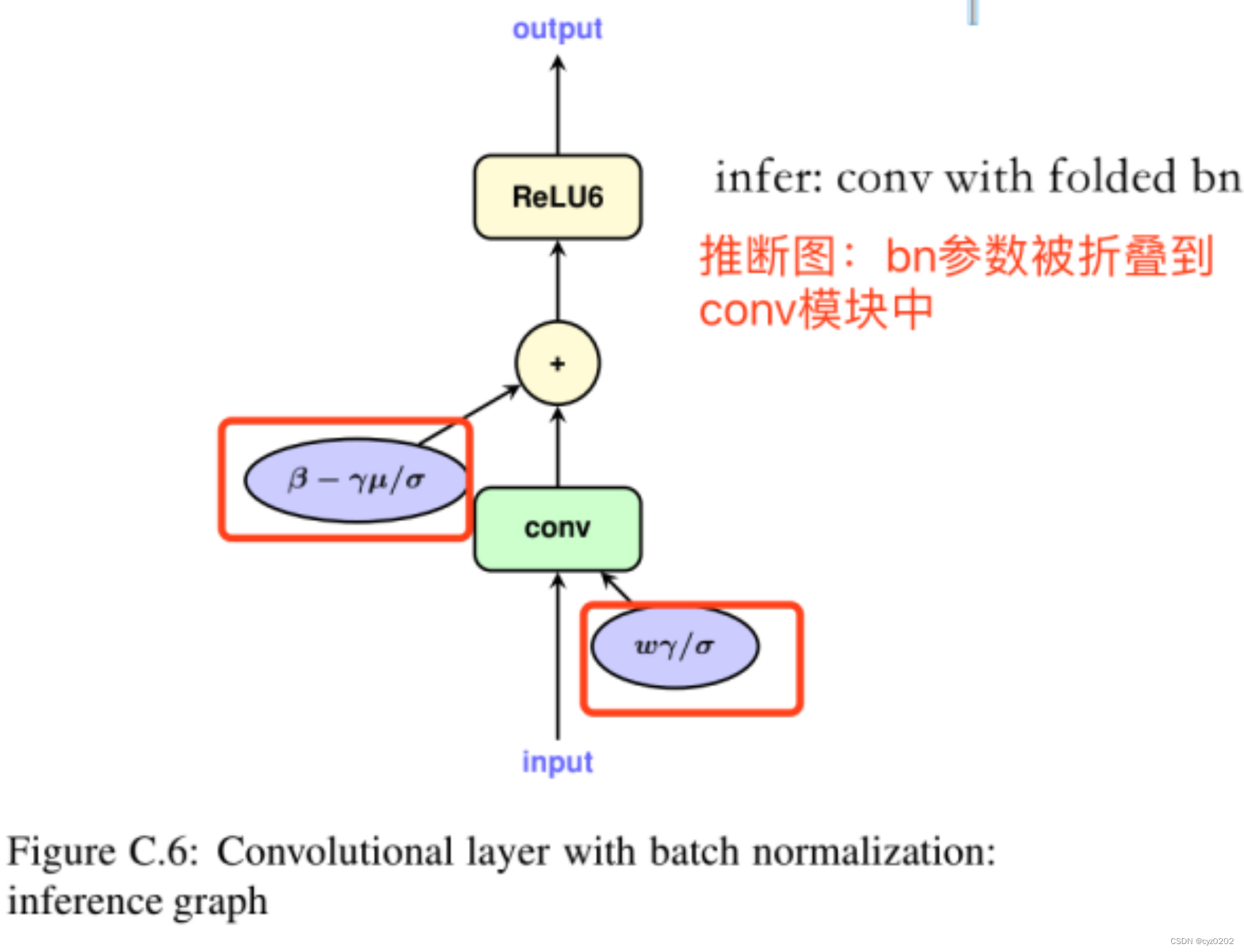
BN folding and its quantification
Warning in install. packages : package ‘RGtk2’ is not available for this version of R
![[OC-Foundation框架]--<Copy对象复制>](/img/62/c04eb2736c2184d8826271781ac7e3.png)
[OC-Foundation框架]--<Copy对象复制>
![[text generation] recommended in the collection of papers - Stanford researchers introduce time control methods to make long text generation more smooth](/img/10/c0545cb34621ad4c6fdb5d26b495ee.jpg)
[text generation] recommended in the collection of papers - Stanford researchers introduce time control methods to make long text generation more smooth
随机推荐
Leetcode: Jianzhi offer 03 Duplicate numbers in array
Navicat Premium 创建MySql 创建存储过程
可变长参数
LeetCode:剑指 Offer 03. 数组中重复的数字
Li Kou daily question 1 (2)
LeetCode:221. 最大正方形
Digital people anchor 618 sign language with goods, convenient for 27.8 million people with hearing impairment
Mise en œuvre de la quantification post - formation du bminf
[OC-Foundation框架]--<Copy对象复制>
Improved deep embedded clustering with local structure preservation (Idec)
Using pkgbuild:: find in R language_ Rtools check whether rtools is available and use sys The which function checks whether make exists, installs it if not, and binds R and rtools with the writelines
LeetCode:236. 二叉树的最近公共祖先
Intel Distiller工具包-量化实现2
【嵌入式】使用JLINK RTT打印log
Advance Computer Network Review(1)——FatTree
Pytorch view tensor memory size
Implement window blocking on QWidget
Leetcode刷题题解2.1.1
【嵌入式】Cortex M4F DSP库
[embedded] cortex m4f DSP Library