当前位置:网站首页>【深度学习】语义分割:论文阅读(NeurIPS 2021)MaskFormer: per-pixel classification is not all you need
【深度学习】语义分割:论文阅读(NeurIPS 2021)MaskFormer: per-pixel classification is not all you need
2022-07-06 09:02:00 【sky_柘】
目录
详情
论文:Per-Pixel Classification is Not All You Need for Semantic Segmentation / MaskFormer
代码:代码
官方-代码
笔记:
作者笔记说明
【论文笔记】MaskFormer: Per-Pixel Classification is Not All You Need for Semantic Segmentation
总结思路清晰-简洁
【MaskFormer】Per-Pixel Classification is Not All You Needfor Semantic Segmentation
简洁明了
视频讲解:
论文简析 Per-Pixel Classification is Not All You Need
知识补充
语义分割
对图像中的每个像素打上类别标签,如下图,把图像分为人(红色)、树木(深绿)、草地(浅绿)、天空(蓝色)标签。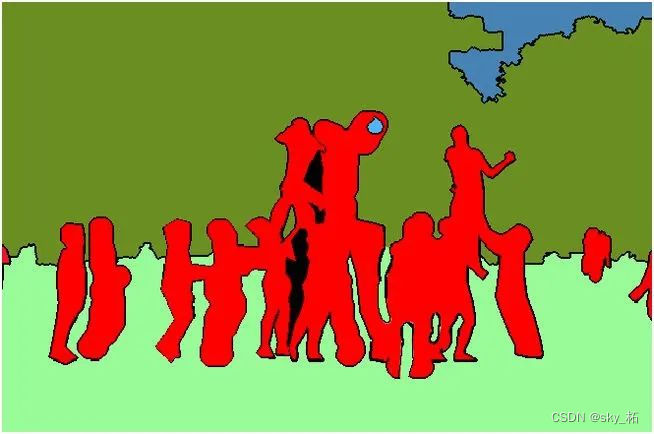
实例分割
实例分割综述总结综合整理版
目标检测和语义分割的结合,在图像中将目标检测出来(目标检测),然后对对图像中的每个像素打上类别标签进行分类(语义分割)。
对比上图、下图,如以人(person)为目标,语义分割不区分属于相同类别的不同实例(所有人都标为红色),实例分割区分同类的不同实例(使用不同颜色区分不同的人)。
目的是将输入图像中的目标检测出来,并且对目标的每个像素分配类别标签.
能够对前景语义类别相同的不同实例进行区分,这是它与语义分割的最大区别.相比语义分割,
基本流程
实例分割模型一般由三部分组成: 图像输入、 实例分割处理、分割结果输出.
- 图像输入后, 模型一 般使用 VGGNet、ResNet 等骨干网络提取图像特 征,
- 然后通过实例分割模型进行处理.
- 模型中可以 先通过目标检测判定目标实例的位置和类别, 然后 在所选定区域位置进行分割,
- 或者先执行语义分割 任务, 再区分不同的实例, 最后输出实例分割结果。
主要技术路线
实例分割的研究长期以来都有着两条线,
分别是自下而上的基于语义分割的方法和自上而下的基于检测的方法,这两种方法都属于两阶段的方法。
自上而下的实例分割方法
思路是:
首先通过目标检测的方法找出实例所在的区域(bounding box),
再在检测框内进行语义分割,每个分割结果都作为一个不同的实例输出。
通常先检测后分割,如FCIS, Mask-RCNN, PANet, Mask Scoring R-CNN;
自上而下的密集实例分割的开山鼻祖是DeepMask,它通过滑动窗口的方法,在每个空间区域上都预测一个mask proposal。这个方法存在以下三个缺点:
- mask与特征的联系(局部一致性)丢失了,如DeepMask中使用全连接网络去提取mask
- 特征的提取表示是冗余的, 如DeepMask对每个前景特征都会去提取一次mask
- 下采样(使用步长大于1的卷积)导致的位置信息丢失
自下而上的实例分割方法
将每个实例看成一个类别;然后按照聚类的思路,最大类间距,最小类内距,对每个像素做embedding,最后做grouping分出不同的instance。Grouping的方法:一般bottom-up效果差于top-down;
思路是:首先进行像素级别的语义分割,再通过聚类、度量学习等手段区分不同的实例。这种方法虽然保持了更好的低层特征(细节信息和位置信息),但也存在以下缺点:
- 对密集分割的质量要求很高,会导致非最优的分割
- 泛化能力较差,无法应对类别多的复杂场景
- 后处理方法繁琐
单阶段实例分割(Single Shot Instance Segmentation),这方面工作其实也是受到了单阶段目标检测研究的影响,因此也有两种思路,一种是受one-stage, anchor-based 检测模型如YOLO,RetinaNet启发,代表作有YOLACT和SOLO;一种是受anchor-free检测模型如 FCOS 启发,代表作有PolarMask和AdaptIS。
掩膜 Mask
【掩膜】
掩膜,通俗地讲就是一个遮挡板,喷漆,或者雕刻或者喷漆的时候,会用一个特定形状的遮板放在被修改的材料上,按照挡板的形状就可以很贴合地得到最后你想要的图案。掩膜就是这么个东西。
【二元掩膜】
binary Mask 叫做二元掩膜,什么意思呢。因为在图像处理的时候,计算机识别图像是将图像当作一个矩阵,你要把一个遮挡板放在一个图像上进行操作,图像矩阵和另外一个“遮挡板”矩阵进行乘积运算,从而得到你想要的结果。举例来说: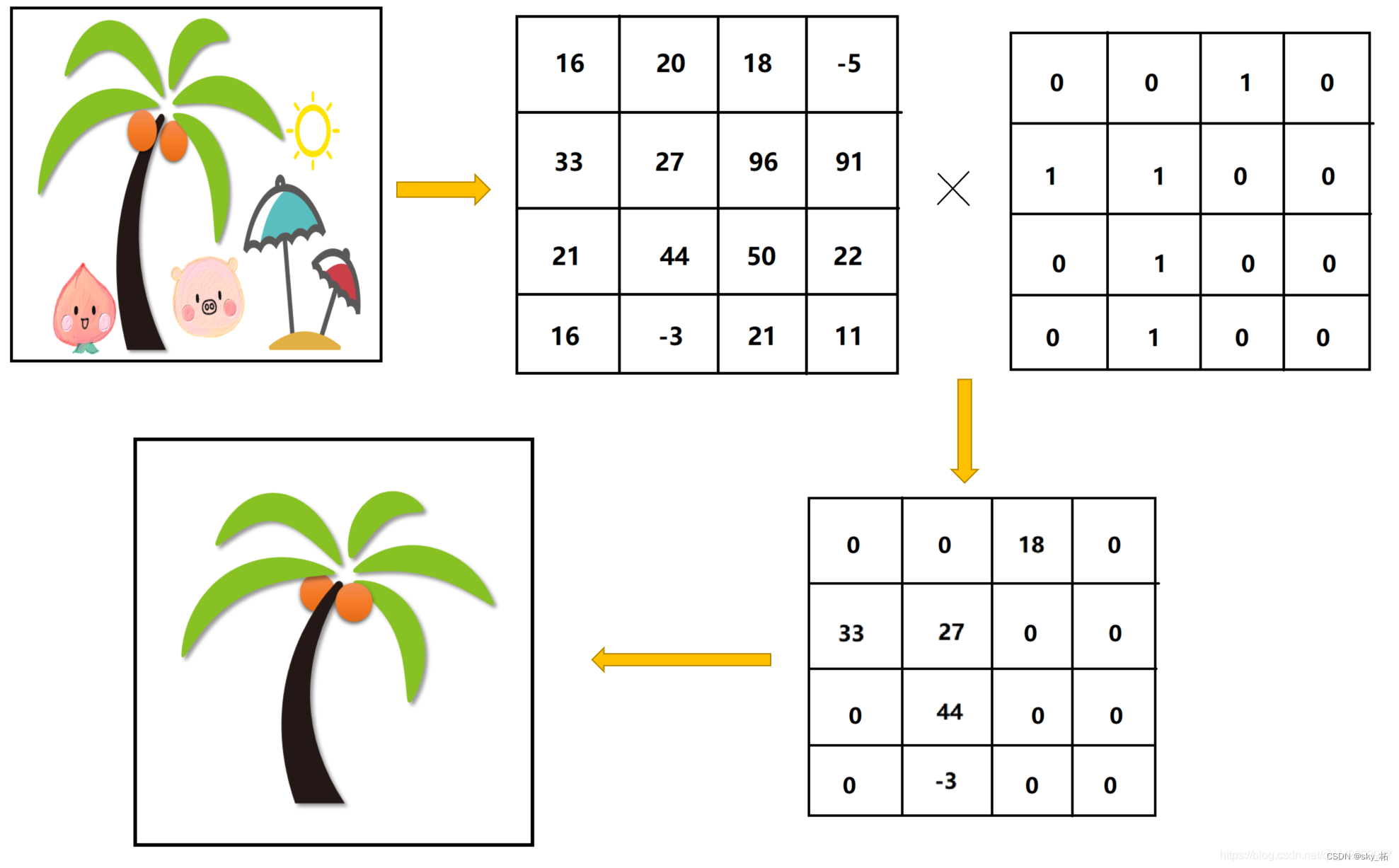
图中可以看出,经过掩膜处理之后,其他的部分都被“掩膜”中的0值过滤掉了,剩余的部分就是想要的部分。
yolov5目标检测神经网络——损失函数计算原理
用选定的图像、图形或物体,对处理的图像(全部或局部)进行遮挡,来控制图像处理的区域或处理过程。
数字图像处理中**,掩模为二维矩阵数组**,有时也用多值图像,
图像掩模主要用于:
①提取感兴趣区,用预先制作的感兴趣区掩模与待处理图像相乘,得到感兴趣区图像,感兴趣区内图像值保持不变,而区外图像值都为0。
②屏蔽作用,用掩模对图像上某些区域作屏蔽,使其不参加处理或不参加处理参数的计算,或仅对屏蔽区作处理或统计。
③结构特征提取,用相似性变量或图像匹配方法检测和提取图像中与掩模相似的结构特征。
④特殊形状图像的制作。
什么是mask掩码?
神经网络对一张图像分割成的8080网格预测了38080个预测框,那么每个预测框都存在检测目标吗?
显然不是。
所以在训练时首先需要根据标签作初步判断,哪些预测框里面很可能存在目标?
mask掩码为这样的一个38080的bool型矩阵:38080个bool值与380*80个预测框一一对应,根据标签信息和一定规则判断每个预测框内是否存在目标,如果存在则将mask矩阵中对应位置的值设置为true,否则设置为false。
mask掩码有什么用?
神经网络对8080网格的每个格子都预测三个矩形框,因此输出了380*80个预测框,每个预测框的预测信息包括矩形框信息、置信度、分类概率。实际上,并非所有预测框都需要计算所有类别的损失函数值,而是根据mask矩阵来决定:
仅mask矩阵中对应位置为true的预测框,需要计算矩形框损失;
仅mask矩阵中对应位置为true的预测框,需要计算分类损失;
所有预测框都需要计算置信度损失,但是mask为true的预测框与mask为false的预测框的置信度标签值不一样。
【masks其实就是每个像素都要标定这个像素属不属于一个物体,bounding box是比较粗略的】
mask classification
是在图像上先生成N个binary mask,再去predict每个binary mask的类别(binary mask里面的所有foreground pixel我们都认为是这个类别,就像mask rcnn一样)。
semantic segmentation和panoptic segmentation用的ground truth不一样。
semantic segmentation里面每一个类别是一个binary mask,panoptic segmentation里每一个instance是一个binary mask。
DeepMask
整体来讲,给定一个image patch作为输入,DeepMask会输出一个与类别无关的mask和一个相关的score,
估计这个patch完全包含一个物体的概率。它最大的特点是不依赖于边缘、超像素或者其他任何形式的low-level分割,是首个直接从原始图像数据学习产生分割候选的工作。
还有一个与其他分割工作巨大的不同是,DeepMask输出的是segmentation masks而不是bounding box。
【masks其实就是每个像素都要标定这个像素属不属于一个物体,bounding box是比较粗略的】
Max-Deeplab
将全景分割建模成了Mask的集合,已经统一了前景和背景的表示方式,在他们的论文中,每类的背景(也就是语义分割)已经被表示为Mask并且与分类分离了。
在Max-Deeplab中,一张图会有N(最后为100)个query,每个query对应一个Mask和一个C分类结果,然后通过C分类的得分,将不符合要求的mask弃置,达到定长预测变成变长结果的效果,从而完成全景分割。
动机
语义分割
现在的方法通常将语义分割制定为per-pixel classification任务
- 自从Fully Convolution Networks (FCNs)问世以来,语义分割问题就被默认当做一个像素分类问题来解决了(Figure 1 左边图)。像素分类极大的简化了语义分割,把它从一个分割(segmentation,或者是pixel grouping)的问题变成了一个分类(classification,或者是recognition)的问题。不可否认,这种简化是相当聪明的,
- 但是从另一方面来看,也限制了人们的想象空间
像素分类限制:
把语义分割真的当做一个“分割”问题来看的话,会发现“像素分类”本身有很多limitations。
其中最大的问题就是它永远只能输出固定个数的segmentation masks(这个固定的个数等于数据集定义的类别数),
所以“像素分类”很难解决实例分割这样更难的问题
实例分割
而实例分割则使用mask classification来处理。
反观实例分割,一直以来都是被以Mask R-CNN为代表的基于mask classification的方法来解决的(Figure 1 右边图)。
Mask classification
Mask classification和per-pixel classification最大的不同在于:
mask classification里面的每一个binary mask都只需要一个global的类别(而不是每个像素都需要类别)。
每一个binary mask预测一个类别(而不是每个pixel一个类别)
我们认为mask classification是一种更general的分割方法,并且mask classification一度在FCN之前“霸榜”过Pascal VOC semantic segmentation challenge (O2P, R-CNN, SDS等基于mask proposal的方法)。但是因为更简单的FCN的出现,大家放弃了mask classification这条路。
提出疑问:
是不是可以都用mask分类来简化语义分割和实例分割的范式呢?
是否mask分类能够在语义分割任务上表现比per-pixel分类的方法更好呢?
本文作者的观点是:mask classification完全可以通用,即可以使用完全相同的模型、损失和训练程序以统一的方式解决语义和实例级别的分割任务。
因此,作者提出了MaskFormer,能够将现有的per-pixel分类的模型转换为mask分类的模型。
预测一组二进制掩码,每个掩码都与一个单个全局类标签预测相关联。简化了语义分割和全景分割任务,当类的数量很大时,MaskFormer比逐像素分类表现得更好。
Related Works
如何评价FAIR提出的MaskFormer,在语义分割ADE20K上达到SOTA:55.6 mIoU? - 陀飞轮的回答 - 知乎
https://www.zhihu.com/question/472122951/answer/1997405212
maskformer将语义分割看出是类别预测与mask预测两个子任务,类别预测和mask预测只要一一对应起来就可以解语义分割任务了
max deeplab提出概念,预测cls+mask分支,然后二分图匹配算loss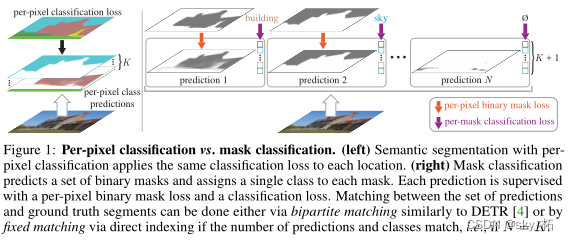
左边的图中表示了 基于每个位置用相同的分类损失的像素分类的语义分割,
右边的图中表示基于掩码分类预测一组二值掩码,并为每个掩码分配一个类。
本文方法,不是只输出 K 个类别二值分类图,而是提前设定一个较大值,同时与分类图一同预测的还有一个预测类别,这个类别可以为空,即该二值分类图没有用。
因此损失函数由两个组成,一个是预测分类图与真值图的损失,另一个是预测类别的交叉熵损失
实际上,因为每个预测分类图的类别可能随着不同图片而发生改变,因此在进行损失之前还会先进行一个类别匹配,匹配成本为: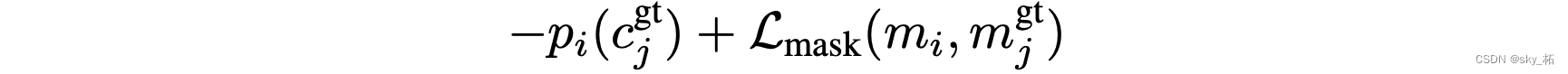
Per-pixel classification formulation
per-pixel的分类:
把分割任务看做是对每一个像素点都进行一次分类的任务,
对于一张H x W 的图片,基于像素分类算法目标是预测每个像素点被分成K个类别中的某一类的概率分布
即: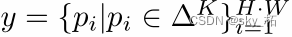
K为数据集中类别的数量,真实label为: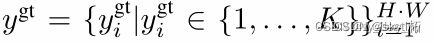
由于是一个分类任务,所以per-pixel的损失函数其实就是每个像素点的cross-entropy损失函数的和,也就是下面的公式: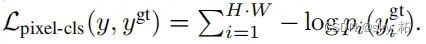
Mask classification formulation
如上图(右)所示,mask分类的模型将分割任务转换成了两个步骤,
- 1.将图像划分成N个不同的区域,用binary mask表示(这一步只是划分出了不同类别的区域,但并没有做分类 )
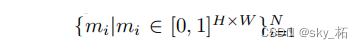
- 2.对每个区域作为一个整体,划分到K个类别中,注意,允许多个区域划分成相同类别,使得该算法能应用到语义和实例级分割任务中。(这一步就是将不同区域分为不同的类 )。
为了对掩码进行分类,期望的输出z为一组N个概率掩码对: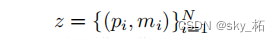
掩码分类允许多个掩码预测具有相同的关联类,使其适用于语义和实例分割任务。
对语义分割来说,
- 如果预测的区域数量 N 与类别标签的数量 K 相匹配,那么简单的固定匹配是可能的。因此,第 i 个预测与具有类别标签 i 的真实区域相匹配,
- 如果预测区域i的类别在真实label中不存在,则与背景匹配。
- 在实验中,发现基于二分匹配的分配比固定匹配效果好。
最终模型的损失函数
第一步中分割任务的损失函数 Lmask+第二步中分类任务的损失函数,
可以表示成下面的公式: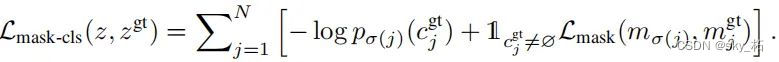
MaskFormer
核心贡献呢是
原来做语义分割是根据每个像素的embeding,独立的预测像素是属于哪个类别
maskformer呢是把我们的feature拿出来扔到transformer decoder里,decoder呢根据每个类别,产生embeding,embeding做mask,做分类,mask embeding出来和像素embeding做乘积,得出来这个类别的形状,同时呢根据decoder产生的embeding可以直接把claddification这个类别属于什么类,推测出来。拿这样子的就告别了我们在每个像素的feature上做prediction。
过程:
MaskFormer提出将全景分割看成是mask分类任务。通过transformer decoder和MLP得到N个mask embedding和N个cls pred。另一个分支通过pixel decoder得到per-pixel embedding,然后将mask embedding和per-pixel embedding相乘得到N个mask prediction,最后cls pred和mask pred相乘,丢弃没有目标的mask,得到最终预测结果。
整体结构分为:
针对整幅图像素的解码器,针对提前预定 N 个数量分割图的 Transformer,之后两者进行整合,可参考下图: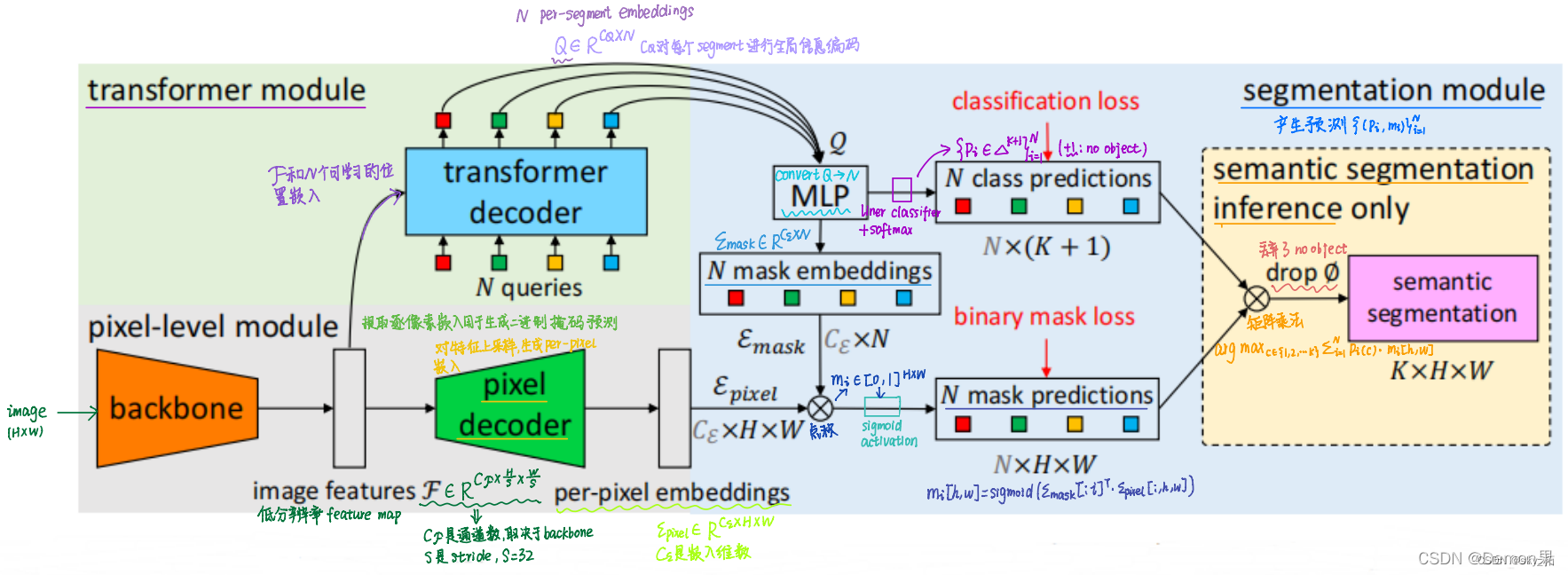
C 为通道数,下面绿色的像素解码器针对的是 H*W,而上面 Transformer 解码器针对的是 N 个分割图。
Transformer 输出后通过一个 MLP 使两者通道数保持一致,然后通过点积来预测每张分割图: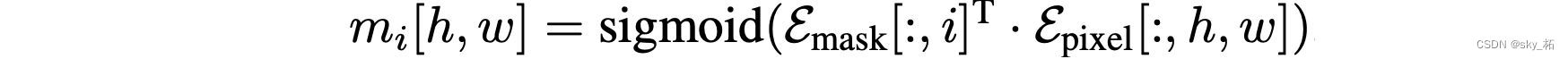
分类端则通过另一个 MLP 将 Transformer 解码器的输出映射成 K + 1 个类别,其中包含一个空类别。
最后整合部分则先去掉这些空类别,然后每个像素点会根据最高的类别置信度和分割图置信度来进行分类: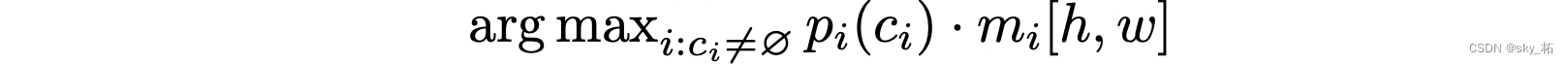
主要可以分为三个部分:
1)pixel-level module:
用于提取图像特征的backbone和用于生成per-pixel嵌入的像素级解码器,
来提取每个像素embedding(灰色背景部分)
2)transformer module:
使用堆叠的Transformer解码器层
用来计算N个segment的embedding(绿色背景部分)
3)segmentation module:
根据上面的per-pixel embedding和per-segment embedding,生成预测结果。(蓝色背景部分)
Pixel-level module
首先用backbone对图片的H和W进行压缩,通道维度进行提升,提取视觉特征,这一部分和正常CNN提取特征类似。
然后用一个pixel Decoder将长宽重新转换为H和W。
输入H×W的图像,
- backbone生成低分辨率图像特征图F(CH/SW/S);
- 像素解码器逐步对特征进行上采样到CHW大小,以生成per-pixel embeding Epixel。
任何基于per-pixel分类的分割模型都适合像素级模块设计,MaskFormer可以将此类模型无缝转换为Mask分类,本文中使用的backbone为ResNet backbones和Swin-Transformer backbones。
像素解码器基于流行的 FPN 架构的轻量级像素解码器。
在 FPN 之后,对解码器中的低分辨率特征图进行 2× 上采样,并将其与来自主干的相应分辨率的投影特征图(投影是为了与特征图维度匹配,通过1×1 卷积层+GroupNorm实现)相加。
接下来,通过一个额外的 3×3 卷积层+GN+ReLU将串联特征融合。
重复这个过程,直到获得最终特征图。
最后,应用单个 1×1 卷积层来获得peri-pixel嵌入。
Transformer module
使用标准的 Transformer 解码器 来计算图像特征F 和 N 个可学习的位置embedding(即query)
其输出是 N 个分割embedding编码成每个分割的全局信息 MaskFormer预测。
本文使用 6 个 Transformer 解码器层和 100 个查询,并且在每个解码器之后应用 DETR 相同的损失。
在实验中,作者观察到 MaskFormer 在使用单个解码器层进行语义分割也相当有竞争力,但在实例分割中多个层对于从最终预测中删除重复项是必要的。
Segmentation module
在sofmax之后使用线性分类器,在每个分割embedding上,以产生每个分割的类别概率预测。
对于mask的预测,将per-segment embedding通过一个两层的MLP转换成了N个mask embedding。
接着,将mask embedding和per-pixel embedding进行了点乘,
后面接上了sigmoid激活函数,来获得最后mask的预测结果。
掩膜分类推理
分割推理:
将图像按像素对每个像素值划分到N个类别中的某一类,
划分的方式:
先将每个像素计算N个类别的预测概率,
然后用argmax函数求N个可能性的最大值,即此像素的分类类别。
对语义分割来说,共享的几个分割块类别标签可以合并,
对实例分割来说,这些分割块的标签不合并即可。
每个像素的预测概率计算: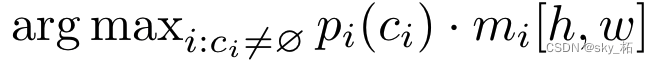
语义推理
语义推理通过简单的矩阵乘法完成。作者发现,对概率-掩码对进行**边缘化(marginalization)**相较于通用推理策略中将像素硬性分配给的概率掩码对能产生更好的结果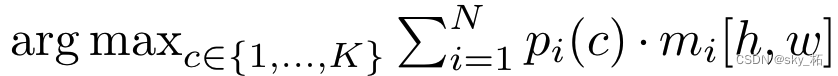
argmax 不包括“无对象”类别(∅),因为标准语义分割要求每个输出像素取一个标签。注意,此策略返回per-pixel类别概率。然而,我们观察到直接最大化per-pixel类可能性(likelihood)会导致性能不佳。
实验-语义分割
对于ADE20K数据集,如果没有特别说明,我们使用的裁剪大小为512 × 512,批大小为16,并训练所有模型160k次。对于ADE20K- full数据集,我们使用与ADE20K相同的设置,除了我们为200k迭代训练所有模型。
在ADE20K val上进行150个类别的语义分割。基于掩码分类的MaskFormer优于最佳逐像素分类方法,同时使用更少的参数和更少的计算。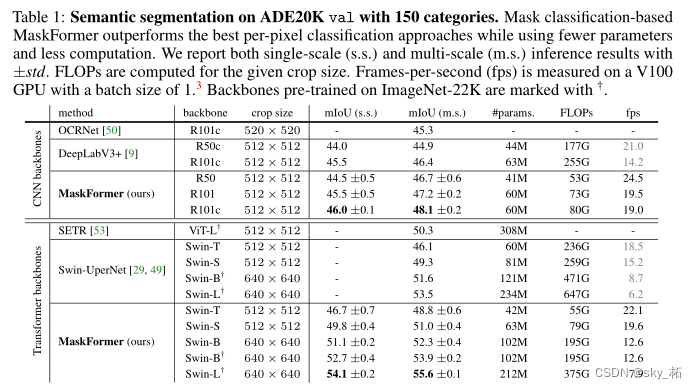
MaskFormer对比4个语义分割数据集上的逐像素分类基线。当类的数量更多时,MaskFormer改进会更大。我们使用ResNet-50骨干网,报告单尺度mIoU和PQSt,用于ADE20K, COCO-Stuff和ADE20K- full,而对于更高分辨率的城市景观,我们使用以下更深的ResNet-101骨干网[8,9]。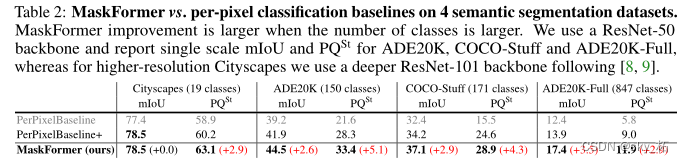
在150个类别的ADE20K测试上进行语义分割。MaskFormer在所有三个指标上都优于以前的最先进的方法:像素精度(P . a .), mIoU,以及最终测试分数(P.A.和mIoU的平均)。我们在[29]后的ImageNet-22K预训练检查点和ADE20K训练集上训练我们的模型,并使用多尺度推理。
视频笔记
论文简析 Per-Pixel Classification is Not All You Need
先划分,也不知道划分的什么东西,但是这个区域属于这个物件;然后再看每个区域属于什么东西
所以其区别于每个像素做一个分类的问题,那本文只需要关注每个instance,也就是我们划分出来的每个物件,它是哪一类就可以了。
当我们确定了物件类别之后呢,只需要把这个物件包含的所有像素刷成这个类别,就完成了。
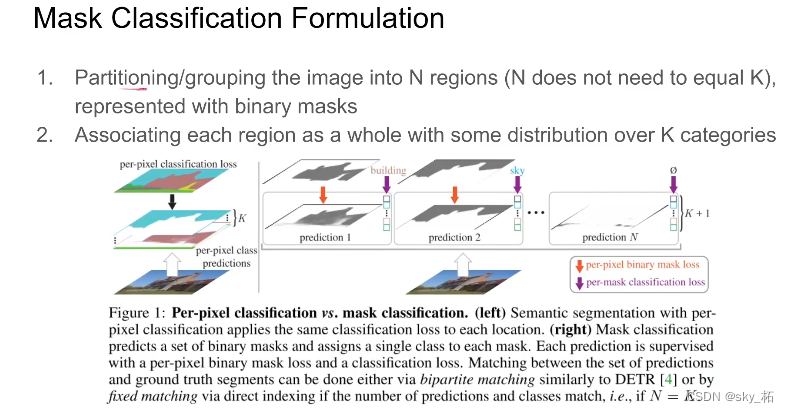
- 首先,把图像分成n个区域,n不一定等于k,k是数据集中所有可能物件的类别,一般n大于k。
- 一般情况下,用binary mask 也就是非1即0的mask,来表达物件。有了这些mask之后呢,我们在区分每个mask对应的区域,是哪个类别。
这里作者有直观的演示。
- 传统的pixel,对于每个像素中的分类来说,每个像素的vector,k类,属于每一类的概率。
- 本文中,先把它分成n个区域,每个区域代表一个物件,还会包含一个空的区域,表示没有什么东西。有了n个区域之后呢,根据区域整个的feature做分类,它会包含形状信息,会比pre pixel提供更多的信息,来构建更加准确的分类。
这个就是本文核心的思想。
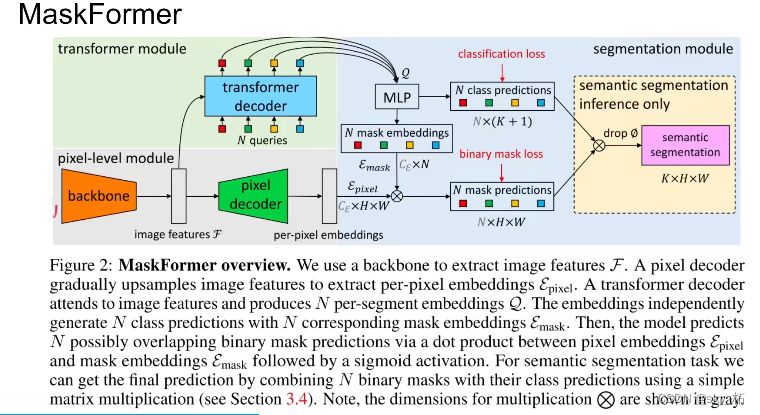
作者围绕这个思路,是是怎么构建模型的。
- 首先一张图片进来,送到backbone里边提些feature,backbone呢比如说resnet,swintransformer
- 有了feature之后呢,我们扔到transformer decoder里边,经过edcode,mlp之后呢,提出的是n个不同的区域的,用representation做prediction,k表示数据集中包含的所有类的数量,+1是因为万一n里边啥都没有呢,加一类空集,那这个是做prediction的head。
- 此外,要完善mask,怎样把E vector重新填充成H x W的图像呢,直接乘上pixel decoder的输出,就得到了n张H x W的图像,每张图像都是binary mask,表示这个区域,哪个属于这个区域,哪个不是,这样做了预测。
- 最后把这两项结合起来,就可以输出一个常规的语义分割的结果。
-n个queries是全零的vector
双向匹配
n个区域,n个mask
边栏推荐
- 为拿 Offer,“闭关修炼,相信努力必成大器
- QML type: locale, date
- Global and Chinese market of metallized flexible packaging 2022-2028: Research Report on technology, participants, trends, market size and share
- Pytest之收集用例规则与运行指定用例
- Redis之cluster集群
- 解决小文件处过多
- Seven layer network architecture
- O & M, let go of monitoring - let go of yourself
- Five layer network architecture
- 面渣逆袭:Redis连环五十二问,图文详解,这下面试稳了
猜你喜欢

Redis core configuration

Once you change the test steps, write all the code. Why not try yaml to realize data-driven?
QDialog

Intel distiller Toolkit - Quantitative implementation 2
基于WEB的网上购物系统的设计与实现(附:源码 论文 sql文件)

Pytest参数化你不知道的一些使用技巧 /你不知道的pytest

Redis之连接redis服务命令

The five basic data structures of redis are in-depth and application scenarios
Master slave replication of redis
![[three storage methods of graph] just use adjacency matrix to go out](/img/79/337ee452d12ad477e6b7cb6b359027.png)
[three storage methods of graph] just use adjacency matrix to go out
随机推荐
Global and Chinese markets for hardware based encryption 2022-2028: Research Report on technology, participants, trends, market size and share
Advance Computer Network Review(1)——FatTree
Nacos installation and service registration
Intel distiller Toolkit - Quantitative implementation 3
In order to get an offer, "I believe that hard work will make great achievements
基于B/S的网上零食销售系统的设计与实现(附:源码 论文 Sql文件)
Workflow - activiti7 environment setup
go-redis之初始化連接
Kratos战神微服务框架(二)
Heap (priority queue) topic
Leetcode:608 树节点
运维,放过监控-也放过自己吧
What is an R-value reference and what is the difference between it and an l-value?
Withdrawal of wechat applet (enterprise payment to change)
Reids之删除策略
Opencv+dlib realizes "matching" glasses for Mona Lisa
Mapreduce实例(八):Map端join
Kratos ares microservice framework (III)
I-BERT
Mapreduce实例(五):二次排序