当前位置:网站首页>Intel distiller Toolkit - Quantitative implementation 3
Intel distiller Toolkit - Quantitative implementation 3
2022-07-06 08:57:00 【cyz0202】
This series of articles
Intel Distiller tool kit - Quantitative realization 1
Intel Distiller tool kit - Quantitative realization 2
Intel Distiller tool kit - Quantitative realization 3
review
- The above article introduces Distiller And Quantizer Base class , Post training quantizer ; Base classes define important variables , Such as replacement_factory(dict, Used to record to be quantified module Corresponding wrapper); In addition, the quantitative process is defined , Include Preprocessing (BN Fold , Activate optimization, etc )、 Quantization module replacement 、 post-processing And other main steps ; The post training quantizer realizes the function of post training quantization based on the base class ;
- This article continues to introduce inheritance from Quantizer Subclass quantizer of , Include
- PostTrainLinearQuantizer( above )
- QuantAwareTrainRangeLinearQuantizer( this paper )
- PACTQuantizer( follow-up )
- NCFQuantAwareTrainQuantizer( follow-up )
- There are many codes in this article , Because I can't post them all , Some places are not clear , Please also refer to the source code ;
QuantAwareTrainRangeLinearQuantizer
- Quantization perception training quantizer ; Insert the quantification process into the model code , Train the model ; This process makes the model parameters fit the quantization process , So the effect of the final model It's generally better than The post training quantitative model is better ;
- QuantAwareTrainRangeLinearQuantizer The class definition of is as follows : It can be seen that the definition of post training quantizer is much simpler ;

- Constructors : Check and default settings are all in the front ; The core is in the red box Yes Parameters 、 Activation value Set up Quantitative perception The way ;
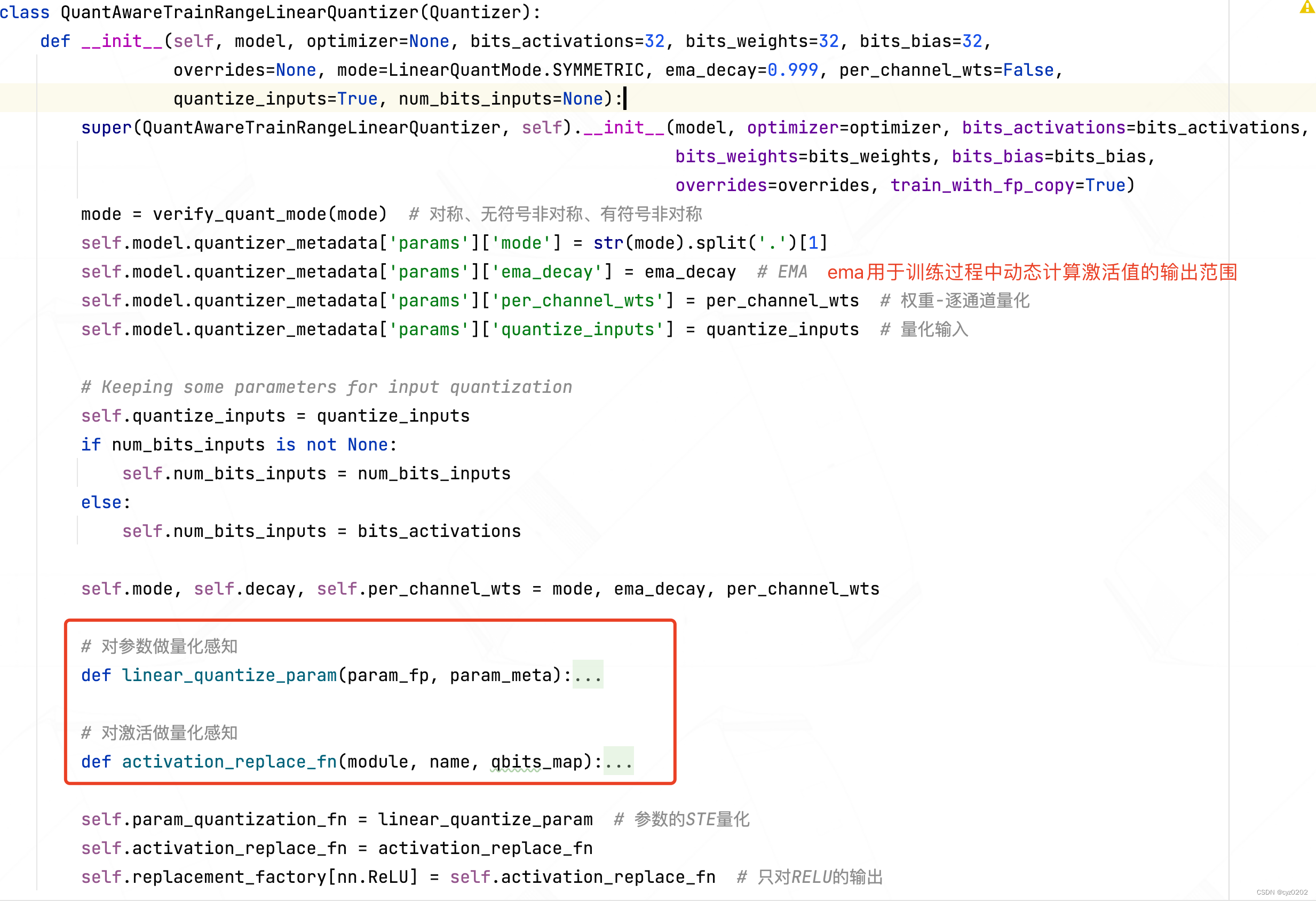
- activation_replace_fn: This is the realization of quantitative perception of activation value , And the quantitative use of the previous post training Module replacement equally , I.e. return to a wrapper, Here is FakeQuantizationWrapper
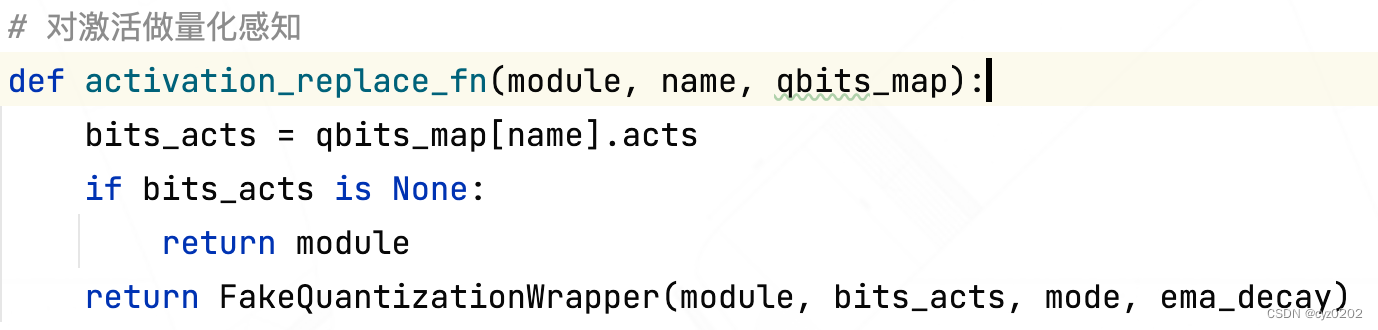
- FakeQuantizationWrapper: The definition is as follows ,forward Input in the first pass through the original module Calculation ( Get the original activation output ), Then output ( next module The input of ) Do pseudo quantification (fake_q);
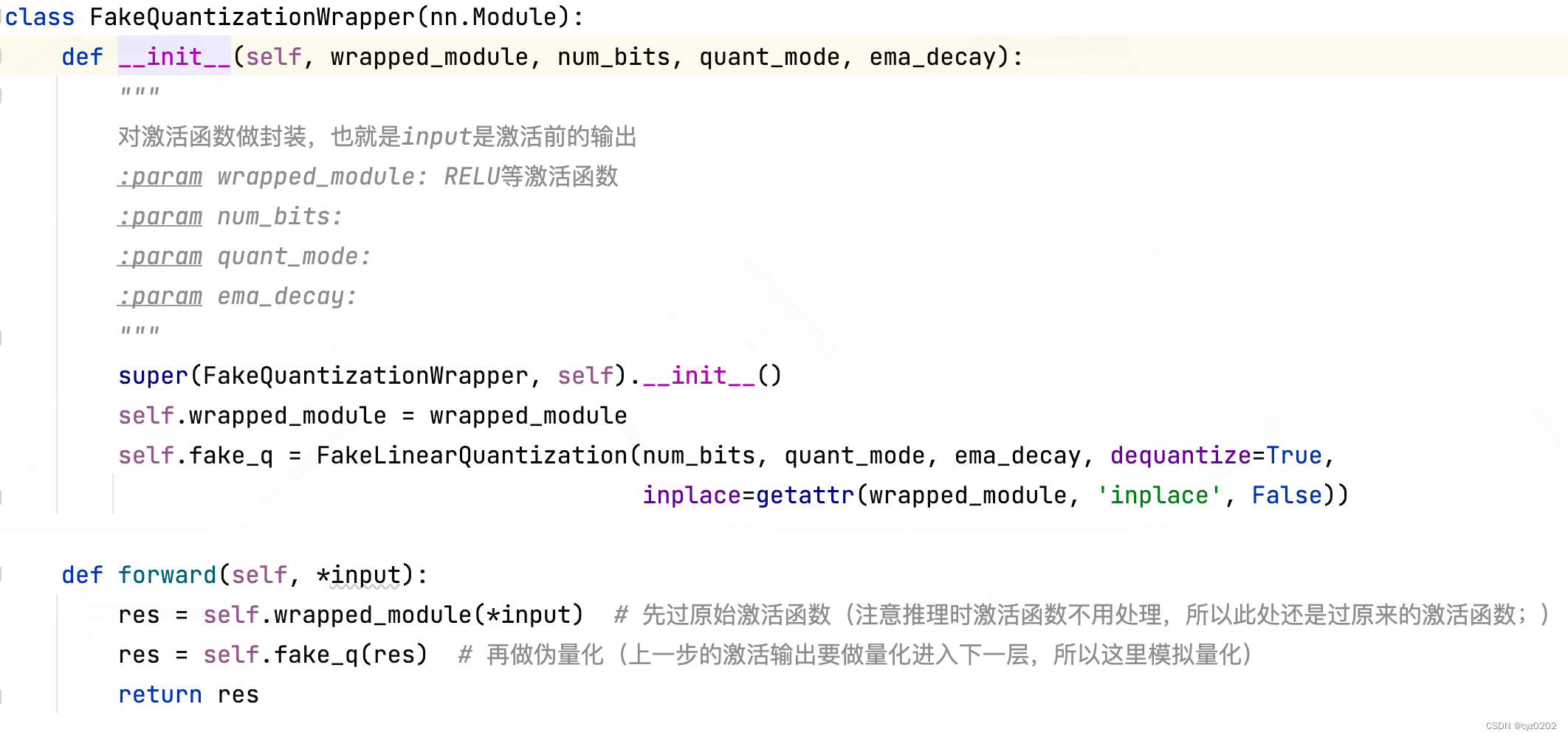
- FakeLinearQuantization: The definition is as follows , The module What I do is Pseudo quantize the input ; Details include The training process is determined Activate the range of values and update scale、zp(infer Then directly use the last of the training process scale、zp); Use LinearQuantizeSTE(straight-through-estimator) Realize pseudo quantization ;
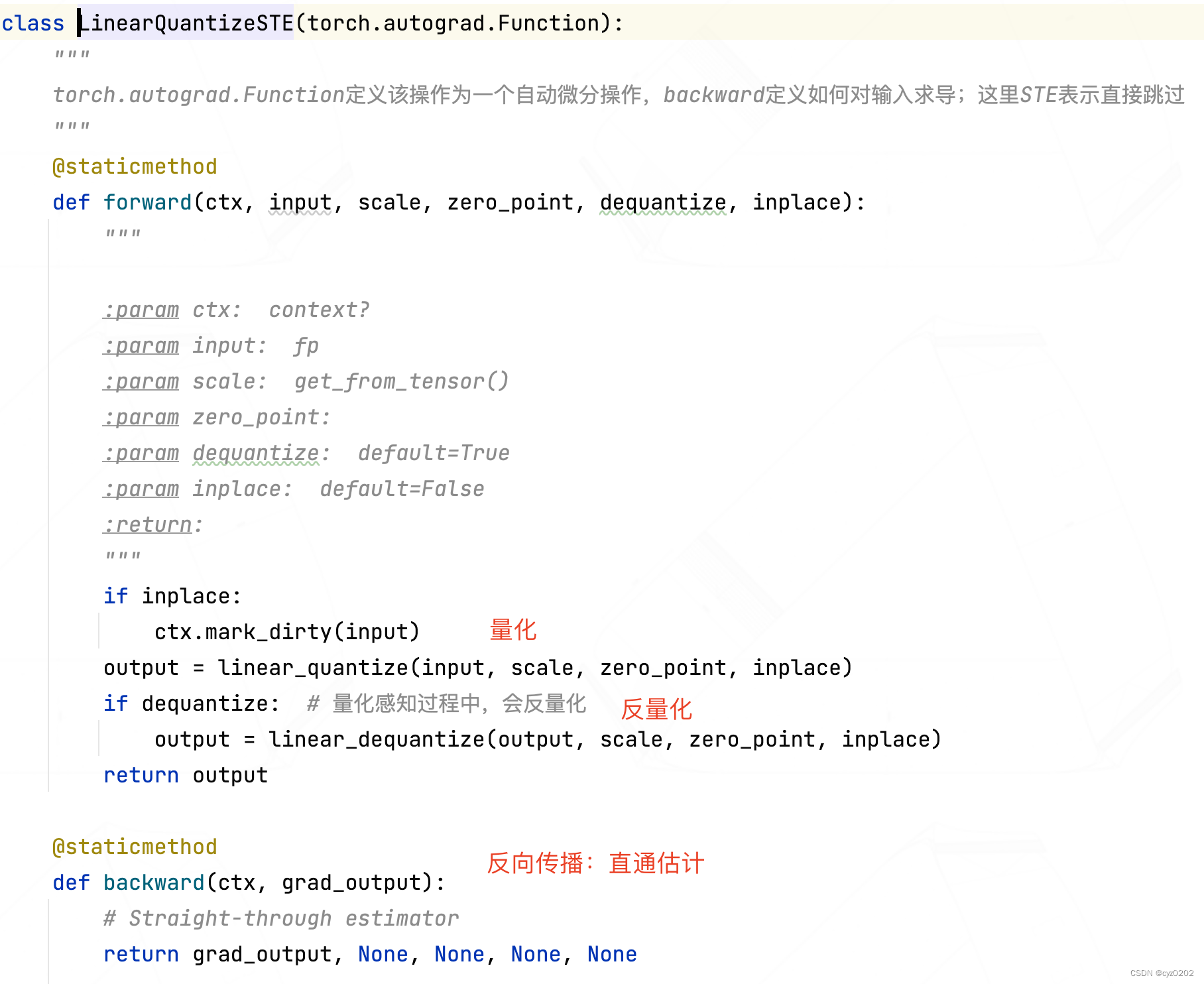
class FakeLinearQuantization(nn.Module): def __init__(self, num_bits=8, mode=LinearQuantMode.SYMMETRIC, ema_decay=0.999, dequantize=True, inplace=False): """ :param num_bits: :param mode: :param ema_decay: The activation value range uses EMA Tracking :param dequantize: :param inplace: """ super(FakeLinearQuantization, self).__init__() self.num_bits = num_bits self.mode = mode self.dequantize = dequantize self.inplace = inplace # We track activations ranges with exponential moving average, as proposed by Jacob et al., 2017 # https://arxiv.org/abs/1712.05877( The activation value range uses EMA Tracking ) # We perform bias correction on the EMA, so we keep both unbiased and biased values and the iterations count # For a simple discussion of this see here: # https://www.coursera.org/lecture/deep-neural-network/bias-correction-in-exponentially-weighted-averages-XjuhD self.register_buffer('ema_decay', torch.tensor(ema_decay)) # Set up buffer,buffer For nonparametric storage , Will be stored in model state_dict self.register_buffer('tracked_min_biased', torch.zeros(1)) self.register_buffer('tracked_min', torch.zeros(1)) # Save unbiased values self.register_buffer('tracked_max_biased', torch.zeros(1)) # Save biased values self.register_buffer('tracked_max', torch.zeros(1)) self.register_buffer('iter_count', torch.zeros(1)) # Save iterations self.register_buffer('scale', torch.ones(1)) self.register_buffer('zero_point', torch.zeros(1)) def forward(self, input): # We update the tracked stats only in training # # Due to the way DataParallel works, we perform all updates in-place so the "main" device retains # its updates. (see https://pytorch.org/docs/stable/nn.html#dataparallel) # However, as it is now, the in-place update of iter_count causes an error when doing # back-prop with multiple GPUs, claiming a variable required for gradient calculation has been modified # in-place. Not clear why, since it's not used in any calculations that keep a gradient. # It works fine with a single GPU. TODO: Debug... if self.training: # Receipts should be collected during training with torch.no_grad(): current_min, current_max = get_tensor_min_max(input) # input Is the output value of the activation function self.iter_count += 1 # The biased value is the normal weighted value , The unbiased value is Biased value /(1-decay**step) self.tracked_min_biased.data, self.tracked_min.data = update_ema(self.tracked_min_biased.data, current_min, self.ema_decay, self.iter_count) self.tracked_max_biased.data, self.tracked_max.data = update_ema(self.tracked_max_biased.data, current_max, self.ema_decay, self.iter_count) if self.mode == LinearQuantMode.SYMMETRIC: max_abs = max(abs(self.tracked_min), abs(self.tracked_max)) actual_min, actual_max = -max_abs, max_abs if self.training: # The range value of the activation value is EMA Recalculate after update scale and zp self.scale.data, self.zero_point.data = symmetric_linear_quantization_params(self.num_bits, max_abs) else: actual_min, actual_max = self.tracked_min, self.tracked_max signed = self.mode == LinearQuantMode.ASYMMETRIC_SIGNED if self.training: # The range value of the activation value is EMA Recalculate after update scale and zp self.scale.data, self.zero_point.data = asymmetric_linear_quantization_params(self.num_bits, self.tracked_min, self.tracked_max, signed=signed) input = clamp(input, actual_min.item(), actual_max.item(), False) # Perform quantification 、 Inverse quantization operation , And the process does not require additional gradients input = LinearQuantizeSTE.apply(input, self.scale, self.zero_point, self.dequantize, False) return input - LinearQuantizeSTE: This is the core of pseudo quantization , The definition is as follows ; It is defined as torch.autograd.Function, Specifies how to back propagate (STE The way )
- Next, let's look at the implementation of quantitative perception of parameters (linear_quantize_param), Use it directly LinearQuantizeSTE

- notes :distiller Although the quantization perception training quantizer defines how Do quantitative perception training for parameters , But it doesn't use , It's a little strange. ;
summary
- This paper introduces distiller Quantizer base class Quantizer A subclass of :PostTrainLinearQuantizer;
- The core part is Activation value 、 Parameter value Realization of quantitative perception training ; The realization of quantitative perception of activation value still adopts wrapper The way , Parameters are used directly STE; Specific details include FakeQuantizationWrapper、FakeLinearQuantization、LinearQuantizeSTE;
边栏推荐
- BMINF的后训练量化实现
- [today in history] February 13: the father of transistors was born The 20th anniversary of net; Agile software development manifesto was born
- Promise 在uniapp的简单使用
- Navicat premium create MySQL create stored procedure
- KDD 2022 paper collection (under continuous update)
- BN折叠及其量化
- LeetCode:剑指 Offer 04. 二维数组中的查找
- 数字人主播618手语带货,便捷2780万名听障人士
- LeetCode:836. Rectangle overlap
- TP-LINK 企业路由器 PPTP 配置
猜你喜欢
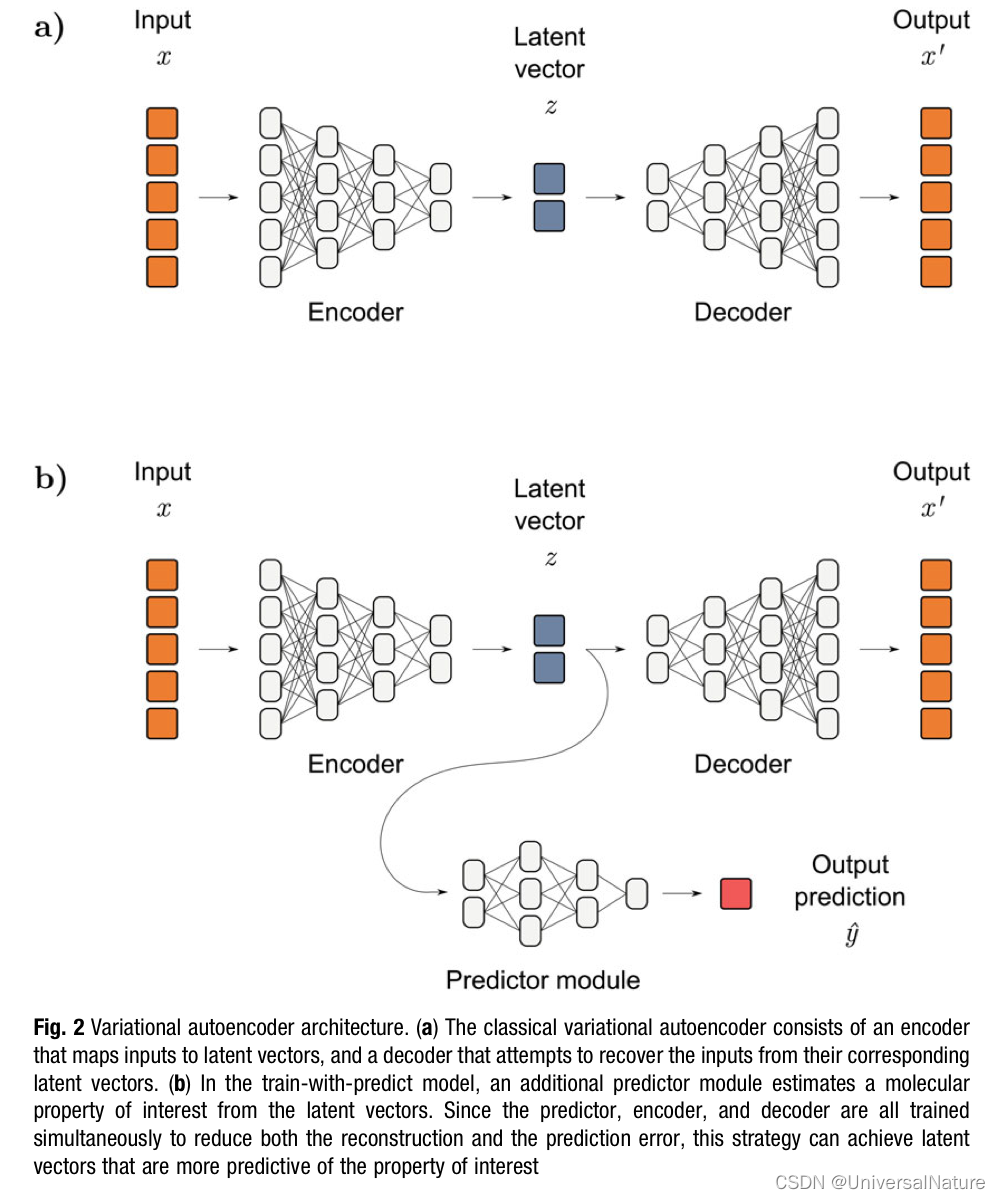
Chapter 1 :Application of Artificial intelligence in Drug Design:Opportunity and Challenges
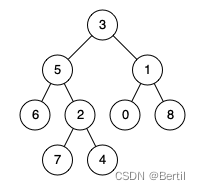
LeetCode:236. The nearest common ancestor of binary tree
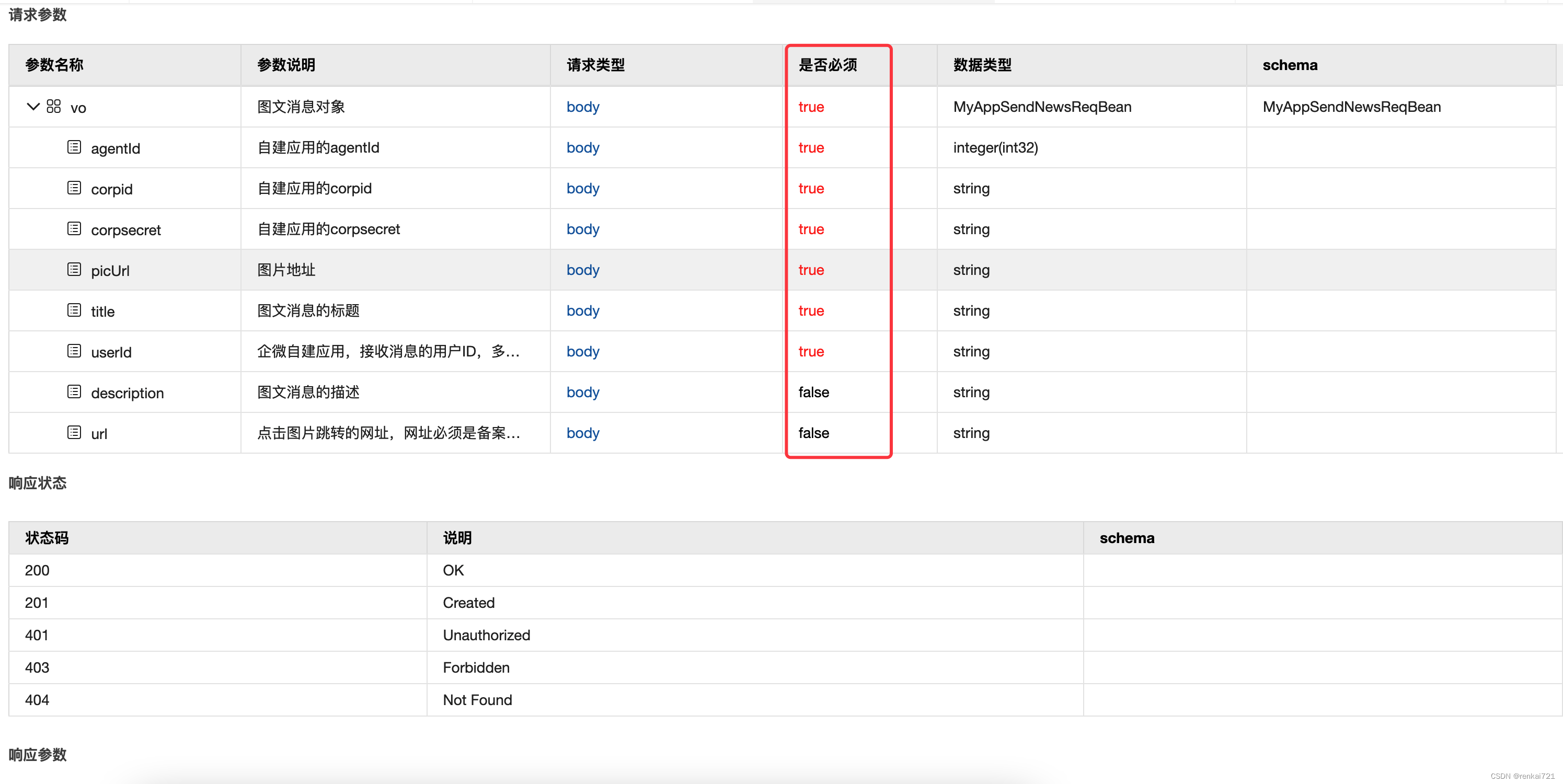
Swagger setting field required is mandatory
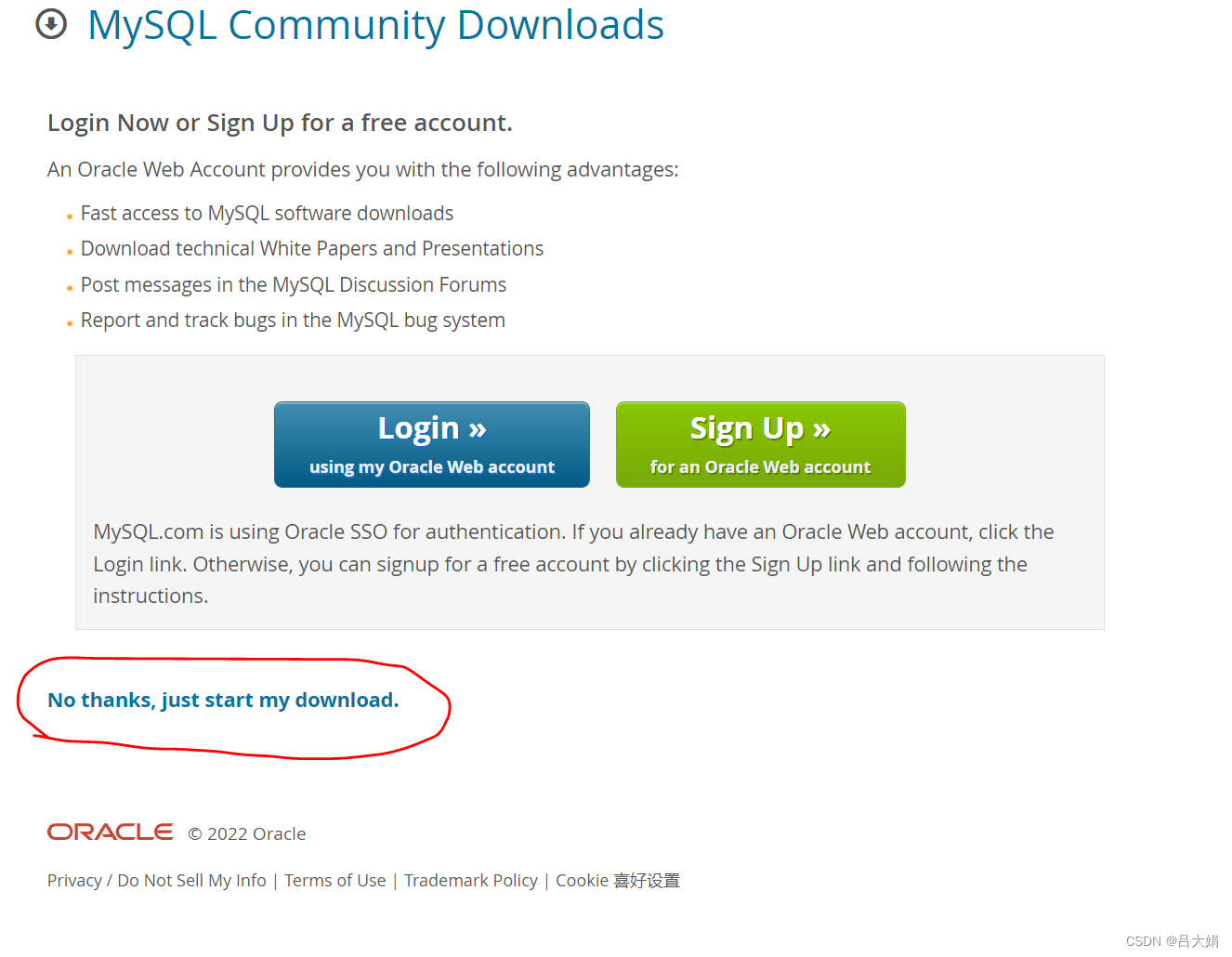
MySQL uninstallation and installation methods

Ijcai2022 collection of papers (continuously updated)
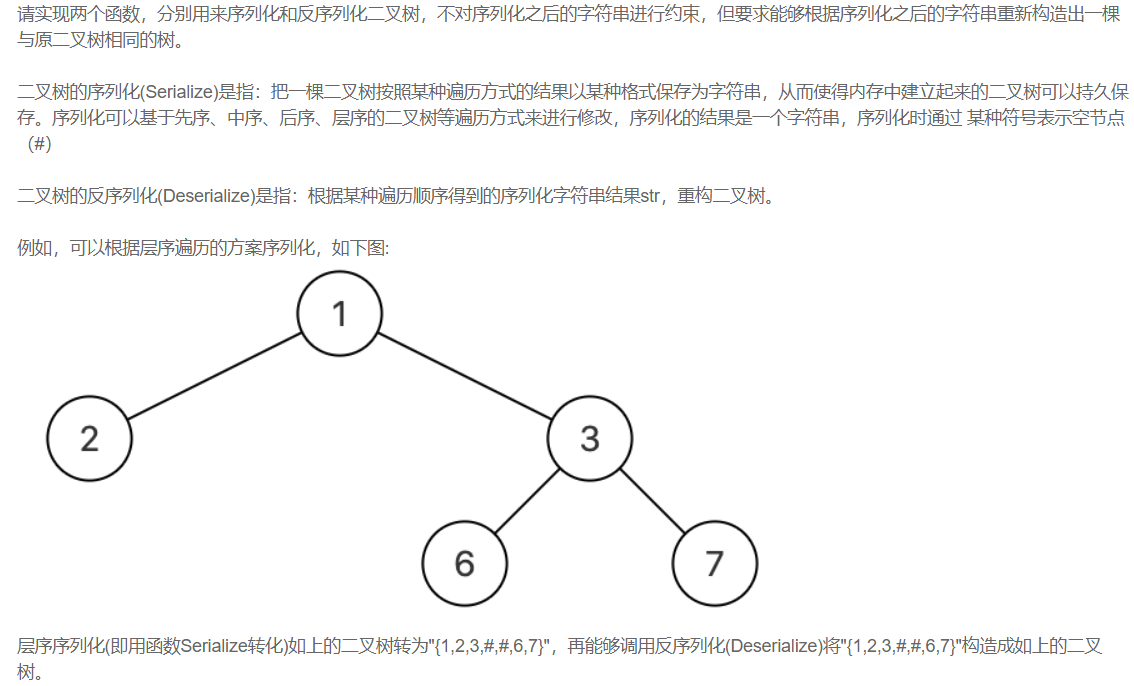
【剑指offer】序列化二叉树
多元聚类分析
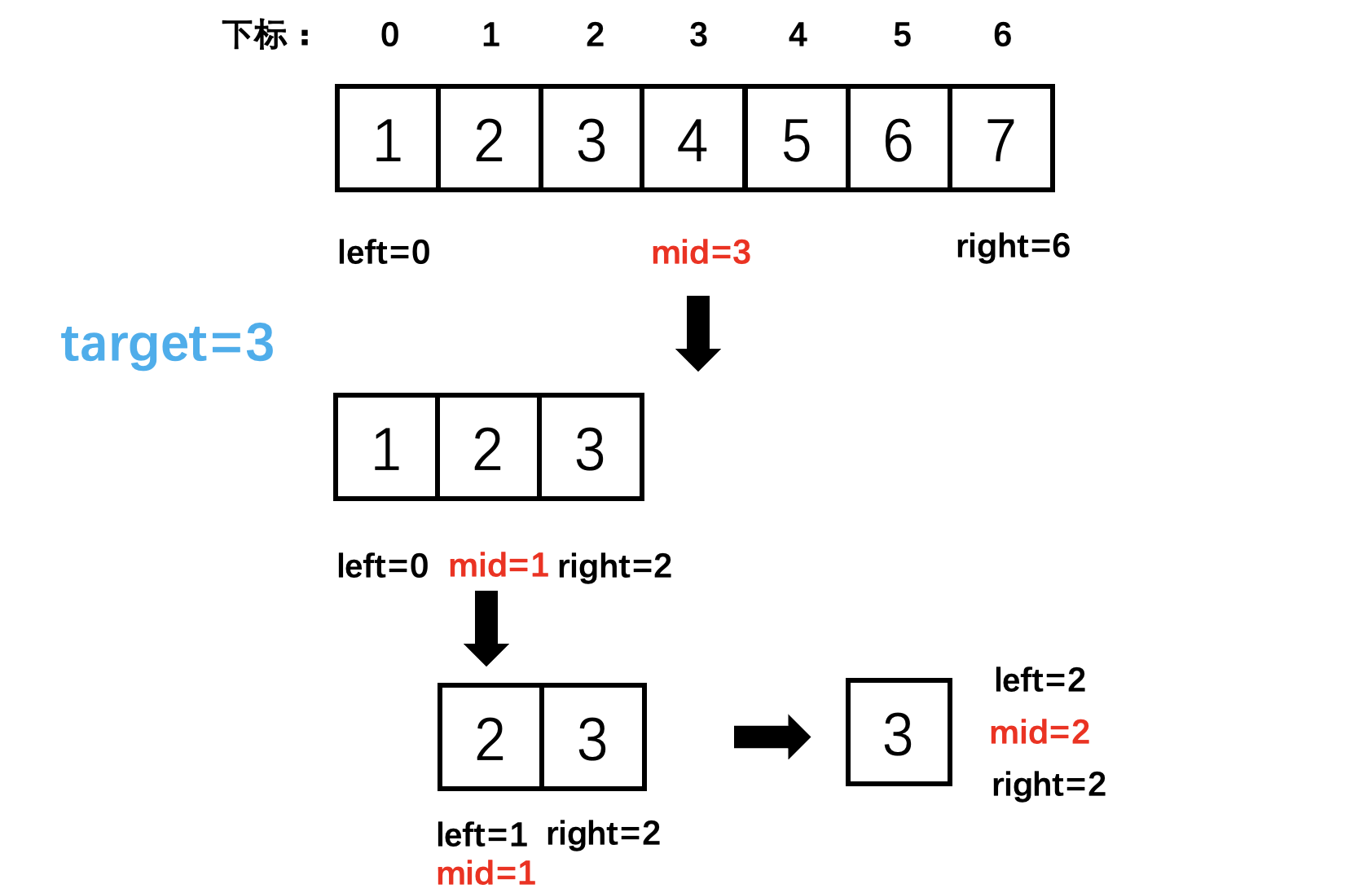
704 binary search
Warning in install. packages : package ‘RGtk2’ is not available for this version of R

SimCLR:NLP中的对比学习
随机推荐
Leetcode: Jianzhi offer 04 Search in two-dimensional array
Leetcode: Sword finger offer 42 Maximum sum of continuous subarrays
Improved deep embedded clustering with local structure preservation (Idec)
LeetCode:221. Largest Square
[Hacker News Weekly] data visualization artifact; Top 10 Web hacker technologies; Postman supports grpc
[text generation] recommended in the collection of papers - Stanford researchers introduce time control methods to make long text generation more smooth
Esp8266-rtos IOT development
Show slave status \ read in G_ Master_ Log_ POS and relay_ Log_ The (size) relationship of POS
LeetCode:41. Missing first positive number
LeetCode:394. String decoding
Advanced Computer Network Review(5)——COPE
【嵌入式】使用JLINK RTT打印log
LeetCode:剑指 Offer 48. 最长不含重复字符的子字符串
LeetCode:673. Number of longest increasing subsequences
[OC]-<UI入门>--常用控件-UIButton
Mongodb installation and basic operation
Advance Computer Network Review(1)——FatTree
Compétences en mémoire des graphiques UML
Advanced Computer Network Review(3)——BBR
如何正确截取字符串(例:应用报错信息截取入库操作)