当前位置:网站首页>[deep learning] [original] let yolov6-0.1.0 support the txt reading dataset mode of yolov5
[deep learning] [original] let yolov6-0.1.0 support the txt reading dataset mode of yolov5
2022-07-05 16:29:00 【FL1623863129】
Meituan gave a yolov6 The framework looks very good at present , Because I didn't come out for long , Many are not perfect . Today, I specially trained my data set and found that this framework can only be placed according to this pattern :
custom_dataset
├── images
│ ├── train
│ │ ├── train0.jpg
│ │ └── train1.jpg
│ ├── val
│ │ ├── val0.jpg
│ │ └── val1.jpg
│ └── test
│ ├── test0.jpg
│ └── test1.jpg
└── labels
├── train
│ ├── train0.txt
│ └── train1.txt
├── val
│ ├── val0.txt
│ └── val1.txt
└── test
├── test0.txt
└── test1.txtAnd I prefer yolov5 The pattern of , Of course yolov5 It also supports the above placement mode .
images-
1.jpg
2.jpg
......
labels-
1.txt
2.txt
.......
Then put the split data set txt Inside
train.txt
/home/fut/data/images/1.jpg
/home/fut/data/images/2.jpg
....
val.txt
/home/fut/data/images/6.jpg
/home/fut/data/images/7.jpg
....
Configure in the configuration file :
train: myproj/config/train.txt
val: myproj/config/val.txt
nc: 2
# whether it is coco dataset, only coco dataset should be set to True.
is_coco: False
# class names
names: ['dog','cat']So you don't have to cut four folders at a time . Don't talk much, start changing the code , We turn on YOLOv6-0.1.0/yolov6/data/datasets.py modify
def get_imgs_labels(self, img_dir): This function loads the mode . Here is the modified complete code of this function
def get_imgs_labels(self, img_dir):
NUM_THREADS = min(8, os.cpu_count())
if os.path.isdir(img_dir):
valid_img_record = osp.join(
osp.dirname(img_dir), "." + osp.basename(img_dir) + ".json"
)
img_paths = glob.glob(osp.join(img_dir, "*"), recursive=True)
img_paths = sorted(
p for p in img_paths if p.split(".")[-1].lower() in IMG_FORMATS
)
assert img_paths, f"No images found in {img_dir}."
else:
with open(img_dir,'r') as f:
img_paths = f.read().rstrip('\n').split('\n')
valid_img_record = os.path.dirname(img_dir)+os.sep+'.'+osp.basename(img_dir)[:-4] + ".json"
img_hash = self.get_hash(img_paths)
if osp.exists(valid_img_record):
with open(valid_img_record, "r") as f:
cache_info = json.load(f)
if "image_hash" in cache_info and cache_info["image_hash"] == img_hash:
img_info = cache_info["information"]
else:
self.check_images = True
else:
self.check_images = True
# check images
if self.check_images and self.main_process:
img_info = {}
nc, msgs = 0, [] # number corrupt, messages
LOGGER.info(
f"{self.task}: Checking formats of images with {NUM_THREADS} process(es): "
)
with Pool(NUM_THREADS) as pool:
pbar = tqdm(
pool.imap(TrainValDataset.check_image, img_paths),
total=len(img_paths),
)
for img_path, shape_per_img, nc_per_img, msg in pbar:
if nc_per_img == 0: # not corrupted
img_info[img_path] = {"shape": shape_per_img}
nc += nc_per_img
if msg:
msgs.append(msg)
pbar.desc = f"{nc} image(s) corrupted"
pbar.close()
if msgs:
LOGGER.info("\n".join(msgs))
cache_info = {"information": img_info, "image_hash": img_hash}
# save valid image paths.
with open(valid_img_record, "w") as f:
json.dump(cache_info, f)
# # check and load anns
# label_dir = osp.join(
# osp.dirname(osp.dirname(img_dir)), "coco", osp.basename(img_dir)
# )
# assert osp.exists(label_dir), f"{label_dir} is an invalid directory path!"
img_paths = list(img_info.keys())
label_dir = os.path.dirname(img_paths[0]).replace('images', 'labels')
label_paths = sorted(
osp.join(label_dir, osp.splitext(osp.basename(p))[0] + ".txt")
for p in img_paths
)
label_hash = self.get_hash(label_paths)
if "label_hash" not in cache_info or cache_info["label_hash"] != label_hash:
self.check_labels = True
if self.check_labels:
cache_info["label_hash"] = label_hash
nm, nf, ne, nc, msgs = 0, 0, 0, 0, [] # number corrupt, messages
LOGGER.info(
f"{self.task}: Checking formats of labels with {NUM_THREADS} process(es): "
)
with Pool(NUM_THREADS) as pool:
pbar = pool.imap(
TrainValDataset.check_label_files, zip(img_paths, label_paths)
)
pbar = tqdm(pbar, total=len(label_paths)) if self.main_process else pbar
for (
img_path,
labels_per_file,
nc_per_file,
nm_per_file,
nf_per_file,
ne_per_file,
msg,
) in pbar:
if nc_per_file == 0:
img_info[img_path]["labels"] = labels_per_file
else:
img_info.pop(img_path)
nc += nc_per_file
nm += nm_per_file
nf += nf_per_file
ne += ne_per_file
if msg:
msgs.append(msg)
if self.main_process:
pbar.desc = f"{nf} label(s) found, {nm} label(s) missing, {ne} label(s) empty, {nc} invalid label files"
if self.main_process:
pbar.close()
with open(valid_img_record, "w") as f:
json.dump(cache_info, f)
if msgs:
LOGGER.info("\n".join(msgs))
if nf == 0:
LOGGER.warning(
f"WARNING: No labels found in {osp.dirname(self.img_paths[0])}. "
)
if self.task.lower() == "val":
if self.data_dict.get("is_coco", False): # use original json file when evaluating on coco dataset.
assert osp.exists(self.data_dict["anno_path"]), "Eval on coco dataset must provide valid path of the annotation file in config file: data/coco.yaml"
else:
assert (
self.class_names
), "Class names is required when converting labels to coco format for evaluating."
save_dir = osp.join(osp.dirname(osp.dirname(img_dir)), "annotations")
if not osp.exists(save_dir):
os.mkdir(save_dir)
save_path = osp.join(
save_dir, "instances_" + osp.basename(img_dir) + ".json"
)
TrainValDataset.generate_coco_format_labels(
img_info, self.class_names, save_path
)
img_paths, labels = list(
zip(
*[
(
img_path,
np.array(info["labels"], dtype=np.float32)
if info["labels"]
else np.zeros((0, 5), dtype=np.float32),
)
for img_path, info in img_info.items()
]
)
)
self.img_info = img_info
LOGGER.info(
f"{self.task}: Final numbers of valid images: {len(img_paths)}/ labels: {len(labels)}. "
)
return img_paths, labels
边栏推荐
- 不敢买的思考
- ES6 drill down - Async functions and symbol types
- 详解SQL中Groupings Sets 语句的功能和底层实现逻辑
- Find the root of the following equation by chord cutting method, f (x) =x^3-5x^2+16x-80=0
- 给自己打打气
- obj集合转为实体集合
- Enterprise backup software Veritas NetBackup (NBU) 8.1.1 installation and deployment of server
- 单商户 V4.4,初心未变,实力依旧!
- Obj resolves to a set
- [vulnerability warning] cve-2022-26134 conflict Remote Code Execution Vulnerability POC verification and repair process
猜你喜欢

Reduce the cost by 40%! Container practice of redis multi tenant cluster
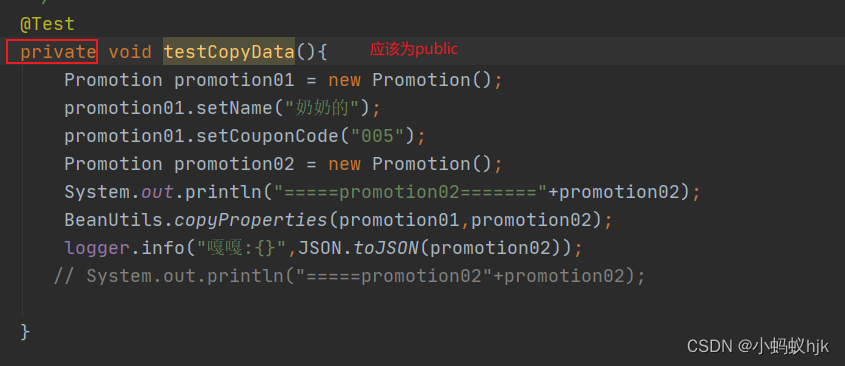
写单元测试的时候犯的错
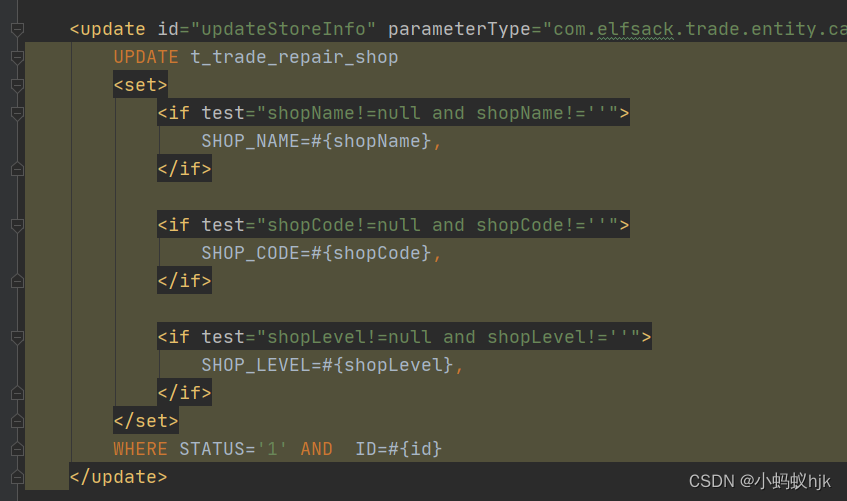
sql中set标签的使用
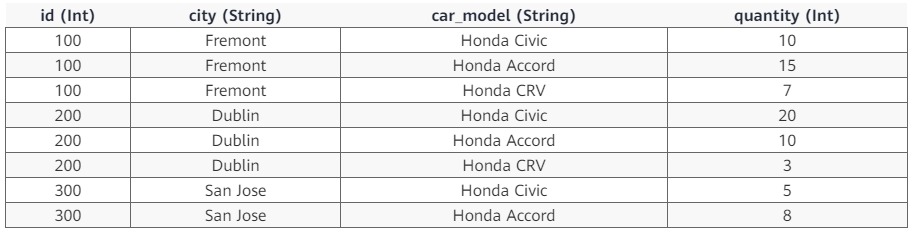
Explain in detail the functions and underlying implementation logic of the groups sets statement in SQL
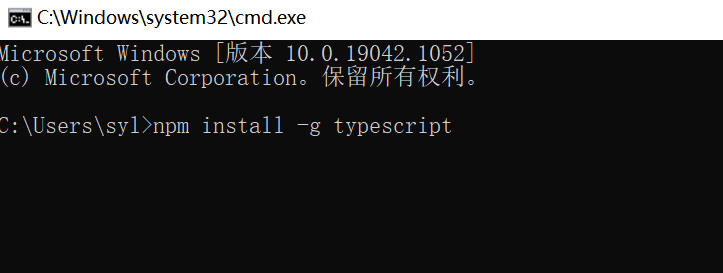
"21 days proficient in typescript-3" - install and build a typescript development environment md

Cs231n notes (top) - applicable to 0 Foundation
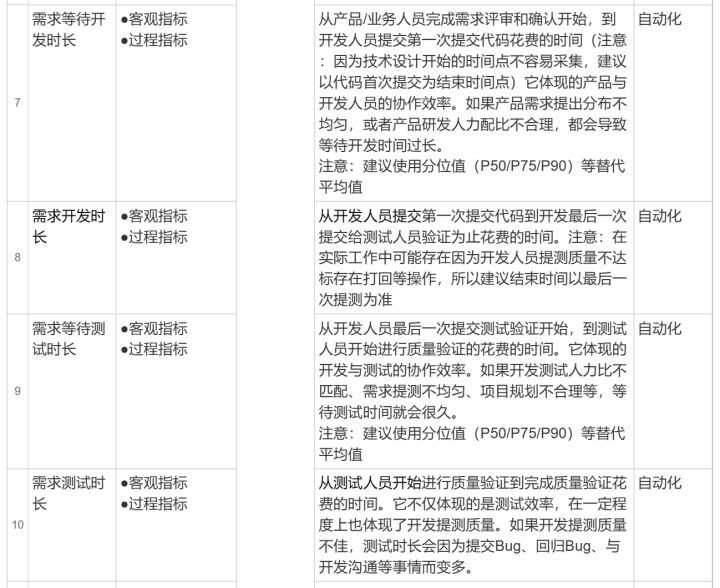
Research and development efficiency measurement index composition and efficiency measurement methodology

迁移/home分区

abstract关键字和哪些关键字会发生冲突呢
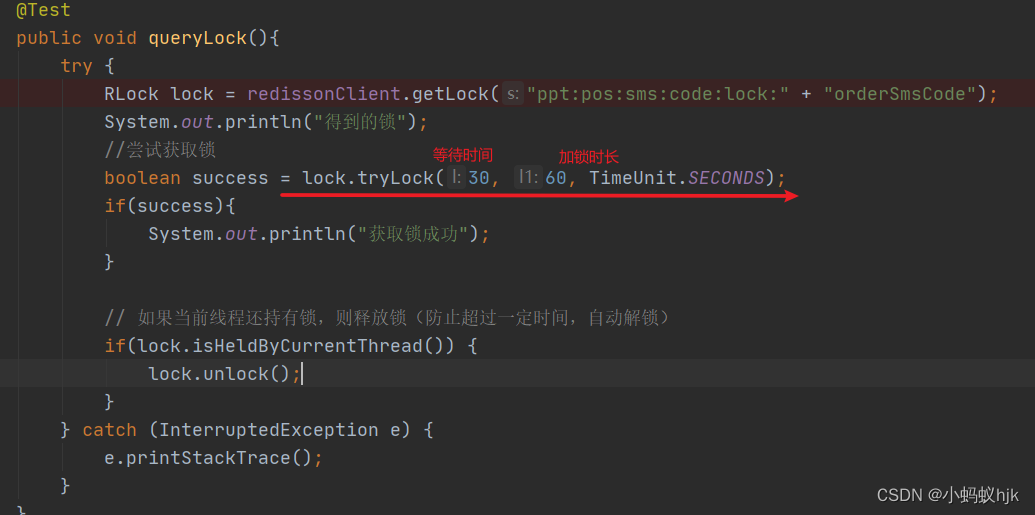
Use of RLOCK lock
随机推荐
Mongodb getting started Tutorial Part 04 mongodb client
Batch update in the project
"21 days proficient in typescript-3" - install and build a typescript development environment md
Record a 'very strange' troubleshooting process of cloud security group rules
Enterprise backup software Veritas NetBackup (NBU) 8.1.1 installation and deployment of server
vant popup+其他组件的组合使用,及避坑指南
漫画:什么是MapReduce?
Pspnet | semantic segmentation and scene analysis
Desci: is decentralized science the new trend of Web3.0?
Apple 已弃用 NavigationView,使用 NavigationStack 和 NavigationSplitView 实现 SwiftUI 导航
Win11如何给应用换图标?Win11给应用换图标的方法
Solve the Hanoi Tower problem [modified version]
《21天精通TypeScript-3》-安装搭建TypeScript开发环境.md
Coding devsecops helps financial enterprises run out of digital acceleration
践行自主可控3.0,真正开创中国人自己的开源事业
Single merchant v4.4 has the same original intention and strength!
ES6深入—ES6 Generator 函数
有序链表集合求交集 方法 总结
obj集合转为实体集合
Research and development efficiency measurement index composition and efficiency measurement methodology