当前位置:网站首页>[深度学习][原创]让yolov6-0.1.0支持yolov5的txt读取数据集模式
[深度学习][原创]让yolov6-0.1.0支持yolov5的txt读取数据集模式
2022-07-05 15:49:00 【FL1623863129】
美团出了一个yolov6框架目前看来很不错,由于没出来多久,有很多没有完善。今天特意训练自己的数据集发现这个框架只能是按照这个模式摆放:
custom_dataset
├── images
│ ├── train
│ │ ├── train0.jpg
│ │ └── train1.jpg
│ ├── val
│ │ ├── val0.jpg
│ │ └── val1.jpg
│ └── test
│ ├── test0.jpg
│ └── test1.jpg
└── labels
├── train
│ ├── train0.txt
│ └── train1.txt
├── val
│ ├── val0.txt
│ └── val1.txt
└── test
├── test0.txt
└── test1.txt而我更喜欢yolov5的模式,当然yolov5也是支持上面摆放模式。
images-
1.jpg
2.jpg
......
labels-
1.txt
2.txt
.......
然后把分割数据集放txt里面
train.txt
/home/fut/data/images/1.jpg
/home/fut/data/images/2.jpg
....
val.txt
/home/fut/data/images/6.jpg
/home/fut/data/images/7.jpg
....
在配置文件这么配置:
train: myproj/config/train.txt
val: myproj/config/val.txt
nc: 2
# whether it is coco dataset, only coco dataset should be set to True.
is_coco: False
# class names
names: ['dog','cat']这样就不用每次切割四个文件夹了。话不多说开始改代码,我们打开YOLOv6-0.1.0/yolov6/data/datasets.py修改
def get_imgs_labels(self, img_dir):这个函数加载模式即可。下面是这个函数修改后完整代码
def get_imgs_labels(self, img_dir):
NUM_THREADS = min(8, os.cpu_count())
if os.path.isdir(img_dir):
valid_img_record = osp.join(
osp.dirname(img_dir), "." + osp.basename(img_dir) + ".json"
)
img_paths = glob.glob(osp.join(img_dir, "*"), recursive=True)
img_paths = sorted(
p for p in img_paths if p.split(".")[-1].lower() in IMG_FORMATS
)
assert img_paths, f"No images found in {img_dir}."
else:
with open(img_dir,'r') as f:
img_paths = f.read().rstrip('\n').split('\n')
valid_img_record = os.path.dirname(img_dir)+os.sep+'.'+osp.basename(img_dir)[:-4] + ".json"
img_hash = self.get_hash(img_paths)
if osp.exists(valid_img_record):
with open(valid_img_record, "r") as f:
cache_info = json.load(f)
if "image_hash" in cache_info and cache_info["image_hash"] == img_hash:
img_info = cache_info["information"]
else:
self.check_images = True
else:
self.check_images = True
# check images
if self.check_images and self.main_process:
img_info = {}
nc, msgs = 0, [] # number corrupt, messages
LOGGER.info(
f"{self.task}: Checking formats of images with {NUM_THREADS} process(es): "
)
with Pool(NUM_THREADS) as pool:
pbar = tqdm(
pool.imap(TrainValDataset.check_image, img_paths),
total=len(img_paths),
)
for img_path, shape_per_img, nc_per_img, msg in pbar:
if nc_per_img == 0: # not corrupted
img_info[img_path] = {"shape": shape_per_img}
nc += nc_per_img
if msg:
msgs.append(msg)
pbar.desc = f"{nc} image(s) corrupted"
pbar.close()
if msgs:
LOGGER.info("\n".join(msgs))
cache_info = {"information": img_info, "image_hash": img_hash}
# save valid image paths.
with open(valid_img_record, "w") as f:
json.dump(cache_info, f)
# # check and load anns
# label_dir = osp.join(
# osp.dirname(osp.dirname(img_dir)), "coco", osp.basename(img_dir)
# )
# assert osp.exists(label_dir), f"{label_dir} is an invalid directory path!"
img_paths = list(img_info.keys())
label_dir = os.path.dirname(img_paths[0]).replace('images', 'labels')
label_paths = sorted(
osp.join(label_dir, osp.splitext(osp.basename(p))[0] + ".txt")
for p in img_paths
)
label_hash = self.get_hash(label_paths)
if "label_hash" not in cache_info or cache_info["label_hash"] != label_hash:
self.check_labels = True
if self.check_labels:
cache_info["label_hash"] = label_hash
nm, nf, ne, nc, msgs = 0, 0, 0, 0, [] # number corrupt, messages
LOGGER.info(
f"{self.task}: Checking formats of labels with {NUM_THREADS} process(es): "
)
with Pool(NUM_THREADS) as pool:
pbar = pool.imap(
TrainValDataset.check_label_files, zip(img_paths, label_paths)
)
pbar = tqdm(pbar, total=len(label_paths)) if self.main_process else pbar
for (
img_path,
labels_per_file,
nc_per_file,
nm_per_file,
nf_per_file,
ne_per_file,
msg,
) in pbar:
if nc_per_file == 0:
img_info[img_path]["labels"] = labels_per_file
else:
img_info.pop(img_path)
nc += nc_per_file
nm += nm_per_file
nf += nf_per_file
ne += ne_per_file
if msg:
msgs.append(msg)
if self.main_process:
pbar.desc = f"{nf} label(s) found, {nm} label(s) missing, {ne} label(s) empty, {nc} invalid label files"
if self.main_process:
pbar.close()
with open(valid_img_record, "w") as f:
json.dump(cache_info, f)
if msgs:
LOGGER.info("\n".join(msgs))
if nf == 0:
LOGGER.warning(
f"WARNING: No labels found in {osp.dirname(self.img_paths[0])}. "
)
if self.task.lower() == "val":
if self.data_dict.get("is_coco", False): # use original json file when evaluating on coco dataset.
assert osp.exists(self.data_dict["anno_path"]), "Eval on coco dataset must provide valid path of the annotation file in config file: data/coco.yaml"
else:
assert (
self.class_names
), "Class names is required when converting labels to coco format for evaluating."
save_dir = osp.join(osp.dirname(osp.dirname(img_dir)), "annotations")
if not osp.exists(save_dir):
os.mkdir(save_dir)
save_path = osp.join(
save_dir, "instances_" + osp.basename(img_dir) + ".json"
)
TrainValDataset.generate_coco_format_labels(
img_info, self.class_names, save_path
)
img_paths, labels = list(
zip(
*[
(
img_path,
np.array(info["labels"], dtype=np.float32)
if info["labels"]
else np.zeros((0, 5), dtype=np.float32),
)
for img_path, info in img_info.items()
]
)
)
self.img_info = img_info
LOGGER.info(
f"{self.task}: Final numbers of valid images: {len(img_paths)}/ labels: {len(labels)}. "
)
return img_paths, labels
边栏推荐
- Cs231n notes (top) - applicable to 0 Foundation
- 践行自主可控3.0,真正开创中国人自己的开源事业
- The OBD deployment mode of oceanbase Community Edition is installed locally
- vant popup+其他组件的组合使用,及避坑指南
- Query the latest record in SQL
- Quelques réflexions cognitives
- Coding devsecops helps financial enterprises run out of digital acceleration
- 迁移/home分区
- Explain in detail the functions and underlying implementation logic of the groups sets statement in SQL
- Some cognitive thinking
猜你喜欢
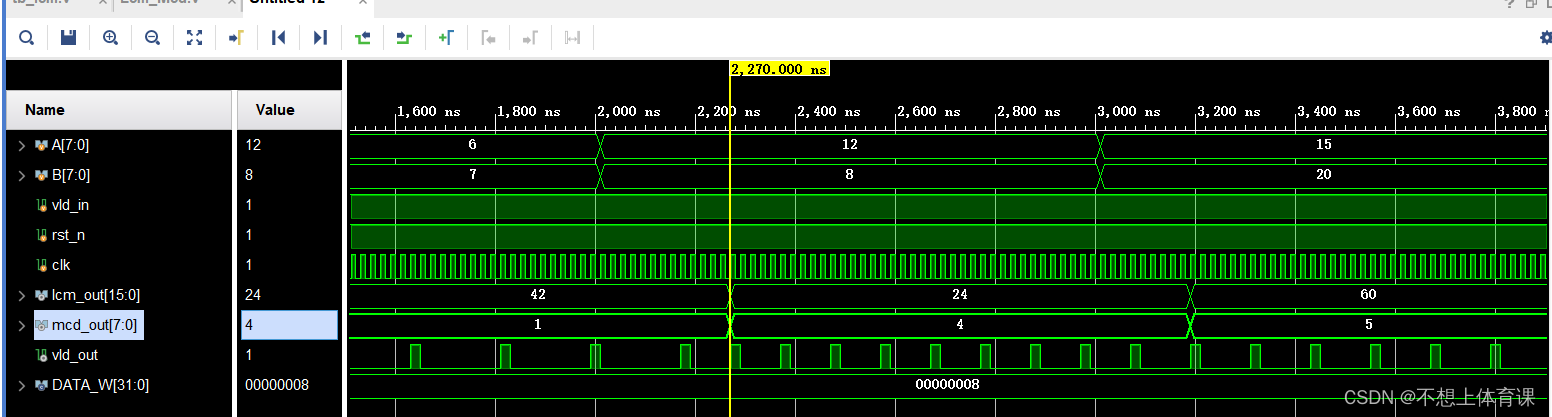
Verilog realizes the calculation of the maximum common divisor and the minimum common multiple

ES6深入—async 函数 与 Symbol 类型
Explain in detail the functions and underlying implementation logic of the groups sets statement in SQL
CISP-PTE之SQL注入(二次注入的应用)
![17. [stm32] use only three wires to drive LCD1602 LCD](/img/c6/b56c54da2553a451b526179f8b5867.png)
17. [stm32] use only three wires to drive LCD1602 LCD

视觉体验全面升级,豪威集团与英特尔Evo 3.0共同加速PC产业变革

迁移/home分区
RLock锁的使用

abstract关键字和哪些关键字会发生冲突呢

项目中批量update
随机推荐
10 minutes to help you get ZABBIX monitoring platform alarm pushed to nail group
Flet教程之 11 Row组件在水平数组中显示其子项的控件 基础入门(教程含源码)
Data Lake (XIV): spark and iceberg integrated query operation
Convert obj set to entity set
One click installation script enables rapid deployment of graylog server 4.2.10 stand-alone version
list使用Stream流进行根据元素某属性数量相加
Query the latest record in SQL
Background system sending verification code function
抽象类和接口的区别
研发效能度量指标构成及效能度量方法论
Using graylog alarm function to realize the regular work reminder of nail group robots
List de duplication and count the number
今日睡眠质量记录79分
Obj resolves to a set
【学术相关】多位博士毕业去了三四流高校,目前惨不忍睹……
通过的英特尔Evo 3.0整机认证到底有多难?忆联科技告诉你
一文带你吃透js处理树状结构数据的增删改查
HiEngine:可媲美本地的云原生内存数据库引擎
详解SQL中Groupings Sets 语句的功能和底层实现逻辑
10分钟帮你搞定Zabbix监控平台告警推送到钉钉群