当前位置:网站首页>Skip table: principle introduction, advantages and disadvantages of skiplist
Skip table: principle introduction, advantages and disadvantages of skiplist
2022-07-03 05:15:00 【A wild man about to succeed】
skiplist Introduce
There is no strict correspondence between the number of nodes in the two adjacent linked lists , It's a random number of layers for each node (level). such as , It's a random number of nodes 3, Then chain it into the first 1 Layer to tier 3 In the list of three layers . To express clearly , The following figure shows how to form a step-by-step insertion operation skiplist The process of :

If we look for 23

skiplist Performance analysis of the algorithm
skiplist Each insertion is independent , According to the following algorithm ( because random() Random generation of )
The process of calculating random numbers while performing insert operations , It's a critical process , It's right skiplist The statistical characteristics of have a very important impact . This is not an ordinary random number with uniform distribution , Its calculation process is as follows :
First , Every node must have a node 1 Layer pointer ( Every node is in the 1 In the chain of layers ).
If a node has a node i layer (i>=1) The pointer ( That is, the node is already in the 1 Layer to tier i In the layer list ), So it has a number (i+1) The probability of layer pointer is p.
The maximum number of layers of a node is not allowed to exceed a maximum value , Write it down as MaxLevel.
The pseudo code for calculating the number of random layers is shown below :
randomLevel() level := 1 // random() Return to one [0...1) The random number while random() < p and level < MaxLevel do level := level + 1 return level
randomLevel() There are two parameters in the pseudo code of , One is p, One is MaxLevel. stay Redis Of skiplist In the implementation , The values of these two parameters are :
p = 1/4 MaxLevel = 32
Spatial complexity
In this part , Let's briefly analyze skiplist Time complexity and space complexity , So that for skiplist There is an intuitive understanding of the performance of . If you're not particularly paranoid about algorithm performance analysis , So you can skip this section for the time being .
Let's first calculate the average number of pointers per node ( Probability expectation ). The number of pointers a node contains , Equivalent to the extra space cost of this algorithm (overhead), Can be used to measure spatial complexity .
According to the front randomLevel() Pseudo code of , It's easy for us to see , The higher the number of nodes generated , The lower the probability . The quantitative analysis is as follows :
The number of node layers shall be at least 1. But more than 1 The number of node layers of , Satisfy a probability distribution .
The number of node layers is exactly equal to 1 The probability of is 1-p.
The number of node layers is greater than or equal to 2 The probability of is p, And the number of nodes is exactly equal to 2 The probability of is p(1-p).
The number of node layers is greater than or equal to 3 The probability of is p^2, And the number of nodes is exactly equal to 3 The probability of is p^2(1-p).
The number of node layers is greater than or equal to 4 The probability of is p^3, And the number of nodes is exactly equal to 4 The probability of is p^3(1-p).
......
therefore , Average number of layers of a node ( That is, the average number of pointers contained ), The calculation is as follows :

Now it's easy to figure out :
When p=1/2 when , The average number of pointers per node is 2;
When p=1/4 when , The average number of pointers per node is 1.33. This is also Redis Inside skiplist Implementation overhead in space .
Time complexity
Now let's say that from one level to i The node of x set out , You need to climb up to the left k layer . Now we have two possibilities :
If node x There is No (i+1) Layer pointer , So we need to move up . In this case, the probability is p.
If node x No first (i+1) Layer pointer , So we need to go left . In this case, the probability is (1-p).
These two situations are shown in the figure below :

use C(k) It means to climb up k The average search path length of each level ( Probability expectation ), that :
C(0)=0 C(k)=(1-p)×( In the picture above b The search length of ) + p×( In the picture above c The search length of )
Plug in , Get one The difference equation And simplify :
C(k)=(1-p)(C(k)+1) + p(C(k-1)+1) C(k)=1/p+C(k-1) C(k)=k/p
The result means that , Every time we climb 1 A hierarchy , Need to go on the search path 1/p Step . And the total number of layers we need to climb is equal to the whole number of layers skiplist The total number of floors -1.
So next we need to analyze when skiplist There is n When there are nodes , Its total number of floors Probability mean How much is the . This problem is intuitively easy to understand . According to the number of layers of nodes, the random algorithm , Easy to come by :
The first 1 The layer list is fixed with n Nodes ;
The first 2 On average, there are n*p Nodes ;
The first 3 On average, there are n*p^2 Nodes ;
...
therefore , From 1 Floor to top , The average number of nodes in each layer of linked list is an exponential decreasing sequence of equal proportion . Easy to calculate , The average of the total number of layers is log1/pn, The average number of nodes at the highest level is 1/p.
Sum up , In a rough calculation , The average search length is approximately equal to :
C(log1/pn-1)=(log1/pn-1)/p
namely , The average time complexity is zero O(log n).
skiplist Balanced tree 、 Hash table comparison
skiplist And various balance trees ( Such as AVL、 A red-black tree, etc ) The elements of are arranged in order , And the hash table is not ordered . therefore , You can only do a single... On a hash table key Lookup , It's not suitable to do range search . So called range search , This refers to finding all nodes whose size is between two specified values .
When doing range finding , Balance the tree ratio skiplist The operation should be complicated . On the balance tree , After we find the small value of the specified range , We also need to continue to search for other nodes with no more than a large value in the order of traversal . If the balance tree is not modified to some extent , The middle order traversal here is not easy to achieve . And in the skiplist It's very easy to do range lookup on , Just after finding the small value , Right. 1 Layer list can be traversed in several steps .
The insertion and deletion of the balance tree may Adjust the subtree , Complex logic , and skiplist The insertion and deletion of only need to modify the fingers of adjacent nodes The needle , Simple and fast operation .
In terms of memory usage ,skiplist More flexible than a balanced tree . Generally speaking , Each node of the balance tree contains 2 A pointer to the ( Point to the left and right subtrees respectively ), and skiplist Each node contains an average of 1/(1-p), It depends on the parameters p Size . If image Redis The realization is the same in , take p=1/4, So the average node contains 1.33 A pointer to the , Better than a balanced tree .
Find a single key,skiplist And the time complexity of the balance tree is O(log n), It's about the same ; and The hash table keeps a low hash value collision probability Under the premise of , Find time complexity near O(1), Higher performance some . So we usually use all kinds of Map or dictionary structure , Most of them are based on hash table .
Compare the difficulty of algorithm implementation ,skiplist It's much simpler than a balanced tree .
Redis Why skiplist Instead of a balance tree ?
In front of us, we are concerned about skiplist And the balance tree 、 Hash table comparison , In fact, it is not difficult to see Redis Use in skiplist The reason why we don't need a balanced tree . Now let's see , For this question ,Redis The author of @antirez How do you say it :
There are a few reasons:
\1) They are not very memory intensive. It's up to you basically. Changing parameters about the probability of a node to have a given number of levels will make then less memory intensive than btrees.
\2) A sorted set is often target of many ZRANGE or ZREVRANGE operations, that is, traversing the skip list as a linked list. With this operation the cache locality of skip lists is at least as good as with other kind of balanced trees.
\3) They are simpler to implement, debug, and so forth. For instance thanks to the skip list simplicity I received a patch (already in Redis master) with augmented skip lists implementing ZRANK in O(log(N)). It required little changes to the code.
边栏推荐
- cookie session jwt
- Webrtc protocol introduction -- an article to understand ice, stun, NAT, turn
- Go practice -- closures in golang (anonymous functions, closures)
- [develop wechat applet local storage with uni app]
- [set theory] relationship properties (symmetry | symmetry examples | symmetry related theorems | antisymmetry | antisymmetry examples | antisymmetry theorems)
- Appium 1.22. L'Inspecteur appium après la version X doit être installé séparément
- Differences among bio, NiO and AIO
- Maximum continuous sub segment sum (dynamic programming, recursive, recursive)
- Objects. Requirenonnull method description
- Redis 击穿穿透雪崩
猜你喜欢
Audio Focus Series: write a demo to understand audio focus and audiomananger
appium1.22.x 版本後的 appium inspector 需單獨安裝
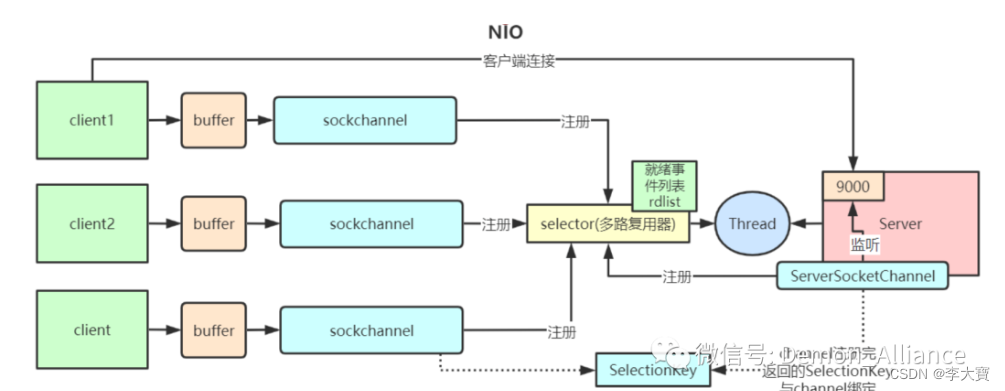
BIO、NIO、AIO区别
Why is go language particularly popular in China
Without 50W bride price, my girlfriend was forcibly dragged away. What should I do

Botu uses peek and poke for IO mapping
![[set theory] relation properties (reflexivity | reflexivity theorem | reflexivity | reflexivity theorem | example)](/img/2a/362f3b0491f721d89336d4f468c9dd.jpg)
[set theory] relation properties (reflexivity | reflexivity theorem | reflexivity | reflexivity theorem | example)
![[practical project] autonomous web server](/img/99/892e600b7203c63bad02adb683c8f2.png)
[practical project] autonomous web server
Source insight garbled code solution

Introduction to deep learning (II) -- univariate linear regression
随机推荐
Web APIs exclusivity
My first Smartphone
Webapidom get page elements
Why is go language particularly popular in China
Review the configuration of vscode to develop golang
Source insight garbled code solution
Compile and decompile GCC common instructions
Webrtc native M96 version opening trip -- a reading code download and compilation (Ninja GN depot_tools)
联想R7000显卡的拆卸与安装
[set theory] relationship properties (common relationship properties | relationship properties examples | relationship operation properties)
Messy change of mouse style in win system
JS scope
1099 build a binary search tree (30 points)
Force GCC to compile 32-bit programs on 64 bit platform
编译GCC遇到的“pthread.h” not found问题
Huawei personally ended up developing 5g RF chips, breaking the monopoly of Japan and the United States
[set theory] relation properties (transitivity | transitivity examples | transitivity related theorems)
Ueditor, FCKeditor, kindeditor editor vulnerability
The consumption of Internet of things users is only 76 cents, and the price has become the biggest obstacle to the promotion of 5g industrial interconnection
Common interview questions of microservice