当前位置:网站首页>mycat的主从关系 垂直分库 水平分表 以及mycat分片联表查询的配置详解(mysql5.7系列)
mycat的主从关系 垂直分库 水平分表 以及mycat分片联表查询的配置详解(mysql5.7系列)
2022-07-31 02:30:00 【倾心*】
主从关系
准备三台不同ip的虚拟机
(第一批)主从关系的配置
主192.168.47.131 配置/etc/my.cnf,在【mysqld】下配置
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
接着在这儿配置
server-id=1
log-bin=/var/lib/mysql/mysqlbin
read-only=0
binlog-ignore-db=mysql从192.168.47.132 配置/etc/my.cnf,在【mysqld】下配置,主从关系的id不一致(切记)
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
接着在这儿配置
server-id=2
log-bin=/var/lib/mysql/mysqlbin设置读写分离balance=3,将读请求writehost对应的标签readhost上,数据库从表与主表的数据不一致,springboot会读到从表的数据 因为从表是读操作
在主终端查看主节点状态
mysql> show master status;
+-----------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-----------------+----------+--------------+------------------+-------------------+
| mysqlbin.000003 | 2168 | | mysql | |
+-----------------+----------+--------------+------------------+-------------------+在从终端设置主从关系
mysql> change master to master_host= '192.168.47.131', master_user='root', master_password='123456', master_log_file='mysqlbin.000003', master_log_pos=2168;
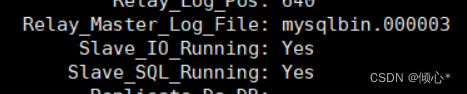
Query OK, 0 rows affected, 8 warnings (0.00 sec)运行show slave status\G;
可看到yes yes 必须是这两项 否则主从没有配置起来
常用命令
开启主从关系 start slave;
关闭主从关系 stop slave;
重置主节点 reset master;
查看主从关系的状态 show slave status\G;
垂直分库的配置
为了避免虚拟机过多 停掉主从关系 stop slave;
(第一批)垂直分库的配置
scehma.xml

<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- schema定义逻辑库的标签 name:逻辑库的名称 dataNode:表示逻辑库关联的节点名称 -->
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1">
<table name="customer" dataNode="dn2"></table>
</schema>
<!-- dataNode:定义节点 name:节点名称必须和上面schema的dataNode值保持一致 dataNode:关联的主机名
database:关联的实际数据库名称
-->
<dataNode name="dn1" dataHost="host1" database="my_order" />
<dataNode name="dn2" dataHost="host2" database="my_consumer" />
<!-- name:数据主机的名称 -->
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<!-- 按照心跳机制来判断真实的数据库是否正常运行-->
<heartbeat>select user()</heartbeat>
<!-- 配置主节点的信息 -->
<writeHost host="hostM1" url="192.168.47.131:3306" user="root"
password="123456">
</writeHost>
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="3"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<!-- 按照心跳机制来判断真实的数据库是否正常运行-->
<heartbeat>select user()</heartbeat>
<!-- 配置主节点的信息 -->
<writeHost host="hostM1" url="192.168.47.132:3306" user="root"
password="123456">
</writeHost>
</dataHost>
</mycat:schema>测试垂直分库
mysql> use TESTDB;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show databases;
+----------+
| DATABASE |
+----------+
| TESTDB |
+----------+
1 row in set (0.00 sec)
mysql> CREATE TABLE customer(
-> id INT AUTO_INCREMENT,
-> NAME VARCHAR(200),
-> PRIMARY KEY(id)
-> );
Query OK, 0 rows affected (0.08 sec)
mysql> CREATE TABLE orders(
-> id INT AUTO_INCREMENT,
-> order_type INT,
-> customer_id INT,
-> amount DECIMAL(10,2),
-> PRIMARY KEY(id)
-> );
Query OK, 0 rows affected (0.01 sec)
mysql> CREATE TABLE orders_detail(
-> id INT AUTO_INCREMENT,
-> detail VARCHAR(2000),
-> order_id INT,
-> PRIMARY KEY(id)
-> );
Query OK, 0 rows affected (0.02 sec)
mysql> CREATE TABLE dict_order_type(
-> id INT AUTO_INCREMENT,
-> order_type VARCHAR(200),
-> PRIMARY KEY(id)
-> );
Query OK, 0 rows affected (0.01 sec)
mysql> select *from customer;
Empty set (0.05 sec)
mysql> select *from orders;
Empty set (0.00 sec) 分表完成 在不同的数据库中
垂直具体配置详解

水平分库
mysql中单表的储存条数是有限制的 最大达到10000条 那么如何在10000条之后继续延续表中的数据呢 使用mycat进行水平分表 当一个表中的条数有限时 可以在其他数据库延续相同数据字段表的条数 进行水平拆分假如表中的数据有10000条 那么进行水平拆分时另一个数据库中的表就有5000条 这就是水平拆分
总节点数(有多少个数据库)数对客户id取余 余数为0在一个表 余数为1在另一个表
在schema.xml中配置

在rule.xml文件中配置
<tableRule name="mod_rule">
<rule>
#以customer_id最为水平拆表的标准
<columns>customer_id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule><function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">2</property>
#此处count=2是根据当前的业务量决定可以变化
</function>想要水平拆分表中数据 本数据库要创建与被拆分表的相同字段的表
不能进行没有字段的插入语句,否则会报错
mysql> INSERT INTO orders VALUES (1,101,100,100100);
ERROR 1064 (HY000): partition table, insert must provide ColumnList正确操作
[[email protected] ~]# mysql -umycat -p123456 -P 8066 -h192.168.47.133
mysql> use TESTDB;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> SHOW TABLES;
+--------------------+
| Tables_in_my_order |
+--------------------+
| customer |
| orders |
| dict_order_type |
| orders_detail |
+--------------------+
4 rows in set (0.01 sec)
mysql> INSERT INTO orders(id,order_type,customer_id,amount) VALUES (1,101,100,100100);
(id,order_type,customer_id,amount) VALUES(4,101,101,103000);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(5,102,101,100400);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(6,102,100,100020);Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO orders(id,order_type,customer_id,amount) VALUES(2,101,100,100300);
Query OK, 1 row affected (0.02 sec)
mysql> INSERT INTO orders(id,order_type,customer_id,amount) VALUES(3,101,101,120000);
Query OK, 1 row affected (0.01 sec)
mysql> INSERT INTO orders(id,order_type,customer_id,amount) VALUES(4,101,101,103000);
Query OK, 1 row affected (0.01 sec)
mysql> INSERT INTO orders(id,order_type,customer_id,amount) VALUES(5,102,101,100400);
Query OK, 1 row affected (0.01 sec)
mysql> INSERT INTO orders(id,order_type,customer_id,amount) VALUES(6,102,100,100020);
Query OK, 1 row affected (0.01 sec)最终结果customer_id 100对2取余为0 在一数据库表 101对2取余为1在另一个数据库表
显然 1 2 6 余数为0 3 4 5 余数为1
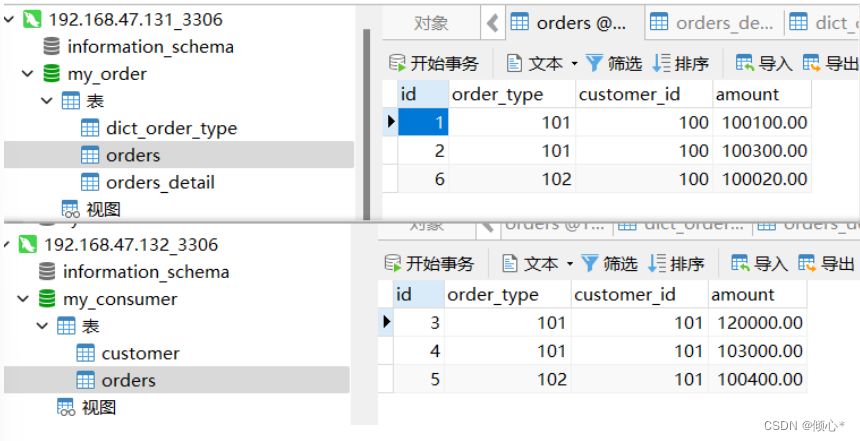
水平分表完成
mycat分片join进行联表查询
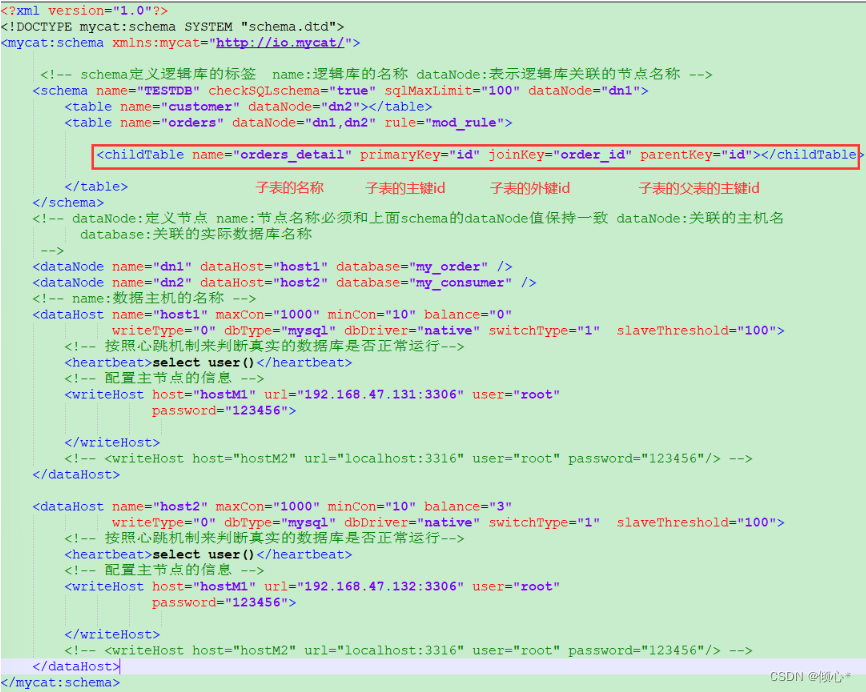
orders已经进行分表操作了 那么和它关联的order_detail订单详情表如何进行join查询 此时也要对orders_detail进行分片操作 想要关联查询 有外键的是子表 主表没有外键
子表的记录与所关联父表的记录放在同一个数据分片上
分片也就是关联表的配置
在schema.xml文件中,具体配置如下
验证时在my_consumer数据库中添加订单详情表
#订单详细表 rows:600万
CREATE TABLE orders_detail(
id INT AUTO_INCREMENT,
detail VARCHAR(2000),
order_id INT,
PRIMARY KEY(id)
);重启mycat 进入mycat终端测试
进入mycat安装目录的bin下 ./mycat console
mysql> use TESTDB;(切记 不要忘记切换数据库 这个非常容易出错 数据库不对 就连接不上 操作不了)
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
#进行插入数据(订单详情)
mysql> INSERT INTO orders_detail(id,detail,order_id) values(61,'detail61',1);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO orders_detail(id,detail,order_id) VALUES(62,'detail62',2);
Query OK, 1 row affected (0.06 sec)
mysql> INSERT INTO orders_detail(id,detail,order_id) VALUES(63,'detail63',3);
Query OK, 1 row affected (0.06 sec)
mysql> INSERT INTO orders_detail(id,detail,order_id) VALUES(64,'detail64',4);
Query OK, 1 row affected (0.06 sec)
mysql> INSERT INTO orders_detail(id,detail,order_id) VALUES(65,'detail65',5);
Query OK, 1 row affected (0.05 sec)
mysql> INSERT INTO orders_detail(id,detail,order_id) VALUES(66,'detail66',6);
Query OK, 1 row affected (0.06 sec)
#进行联表查询 可以看到查询成功 在订单表中可以看到订单详情
mysql> select * from orders as o inner join orders_detail as od on o.id=od.order_id;
;
+----+------------+-------------+-----------+----+----------+----------+
| id | order_type | customer_id | amount | id | detail | order_id |
+----+------------+-------------+-----------+----+----------+----------+
| 1 | 101 | 100 | 100100.00 | 61 | detail61 | 1 |
| 2 | 101 | 100 | 100300.00 | 62 | detail62 | 2 |
| 6 | 102 | 100 | 100020.00 | 66 | detail66 | 6 |
| 3 | 101 | 101 | 120000.00 | 63 | detail63 | 3 |
| 4 | 101 | 101 | 103000.00 | 64 | detail64 | 4 |
| 5 | 102 | 101 | 100400.00 | 65 | detail65 | 5 |
+----+------------+-------------+-----------+----+----------+----------+
6 rows in set (0.02 sec)
联表查询结果
mysql> select o.*,od.detail from orders o inner join orders_detail od on o.id=od.order_id;
+----+------------+-------------+-----------+----------+
| id | order_type | customer_id | amount | detail |
+----+------------+-------------+-----------+----------+
| 3 | 101 | 101 | 120000.00 | detail63 |
| 4 | 101 | 101 | 103000.00 | detail64 |
| 5 | 102 | 101 | 100400.00 | detail65 |
| 1 | 101 | 100 | 100100.00 | detail61 |
| 2 | 101 | 100 | 100300.00 | detail62 |
| 6 | 102 | 100 | 100020.00 | detail66 |
+----+------------+-------------+-----------+----------+
6 rows in set (0.01 sec)分片完成 联表查询完成 完美 说明一下mycat不支持mysql8.0.28 本人亲自踩坑 建议实验mysql5.7系列版本
提供建表语句
#客户表 rows:20万
CREATE TABLE customer(
id INT AUTO_INCREMENT,
NAME VARCHAR(200),
PRIMARY KEY(id)
);
#订单表 rows:600万
CREATE TABLE orders(
id INT AUTO_INCREMENT,
order_type INT,
customer_id INT,
amount DECIMAL(10,2),
PRIMARY KEY(id)
);
#订单详细表 rows:600万
CREATE TABLE orders_detail(
id INT AUTO_INCREMENT,
detail VARCHAR(2000),
order_id INT,
PRIMARY KEY(id)
);
#订单状态字典表 rows:20
CREATE TABLE dict_order_type(
id INT AUTO_INCREMENT,
order_type VARCHAR(200),
PRIMARY KEY(id)
);边栏推荐
- CorelDRAW2022精简亚太新增功能详细介绍
- Installation, start and stop of redis7 under Linux
- Teach you how to configure Jenkins automated email notifications
- Face detection based on opencv
- 跨专业考研难度大?“上岸”成功率低?这份实用攻略请收下!
- My first understanding of MySql, and the basic syntax of DDL and DML and DQL in sql statements
- 【银行系列第一期】中国人民银行
- Static routing + PAT + static NAT (explanation + experiment)
- Path and the largest
- Real-time image acquisition based on FPGA
猜你喜欢
mmdetection训练一个模型相关命令
FPGA-based vending machine
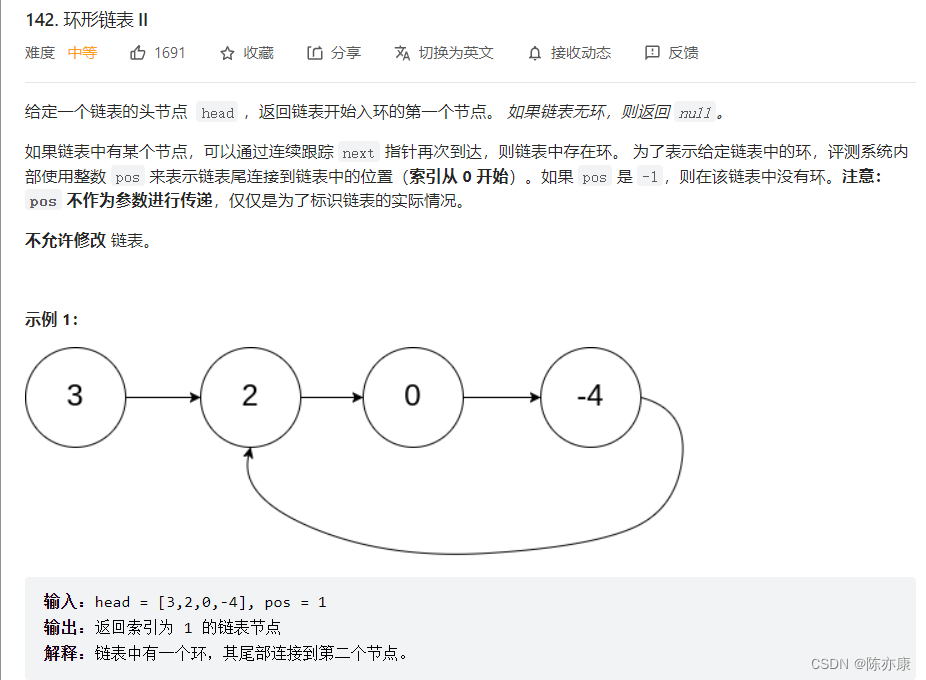
数学解决——环形链表问题

leetcode-399: division evaluation

STM32CUBEMX开发GD32F303(11)----ADC在DMA模式下扫描多个通道
Mathematics to solve the problem - circular linked list

Tower of Hanoi problem
Classic linked list OJ strong training problem - fast and slow double pointer efficient solution
Software testing basic interface testing - getting started with Jmeter, you should pay attention to these things
Installation, start and stop of redis7 under Linux
随机推荐
To write good test cases, you must first learn test design
[1154] How to convert string to datetime
leetcode-952: Calculate max component size by common factor
String为什么不可变?
Refuse to work overtime, a productivity tool set developed by programmers
Classic linked list OJ strong training problem - fast and slow double pointer efficient solution
Intranet Infiltration - Privilege Escalation
What are the project management tools like MS Project
First acquaintance with C language -- array
Maximum area of solar panel od js
Inner monologue from a female test engineer...
mysql index
StringJoiner详解
关于 mysql8.0数据库中主键位id,使用replace插入id为0时,实际id插入后自增导致数据重复插入 的解决方法
Face detection based on opencv
基于FPGA的图像实时采集
12 pictures take you to fully understand service current limit, circuit breaker, downgrade, and avalanche
Layer 2 broadcast storm (cause + judgment + solution)
f.grid_sample
AtCoder Beginner Contest 261 部分题解