当前位置:网站首页>Complementary knowledge of auto encoder
Complementary knowledge of auto encoder
2022-07-04 12:24:00 【hello_ JeremyWang】
1. Yes Auto-Encoder Ask for more
stay Pytorch actual combat _ Image dimensionality reduction and clustering in , I have briefly introduced Auto-Encoder Principle . For the simplest Auto-Encoder, Our requirement is to minimize reconstruction loss, That is, the restored image or article should be as close as possible to the original image or article .
But beyond that , Can we talk about Auto-Encoder Put forward more requirements ? The answer is yes , Let's take a look :
- Not just reduce reconstruction loss
- Get more acceptable embedding
1.1 Demand one
Request a request that we not only reduce reconstruction loss, And ask us to get embedding Can represent our original pictures or words ( It's like writing wheel eyes represents the yuzhibo family ). How can we make the machine do this ?
From the bottom PPT It can be seen that , We need to build another classifier Discriminator To measure embedding How well it fits the original picture . The specific process is , We set the parameter to θ \theta θ Of Encoder Compress the picture , And compress the obtained embedding and Put pictures together Discriminator To classify , from Discriminator To determine whether the two fit . For each θ \theta θ Come on , We all adjust Discriminator Parameters of ϕ \phi ϕ To make Discriminator The training error is as small as possible , We define this error as L D ∗ L_D^{*} LD∗. Finally, we should adjust the parameters θ \theta θ bring L D ∗ L_D^{*} LD∗ As small as possible .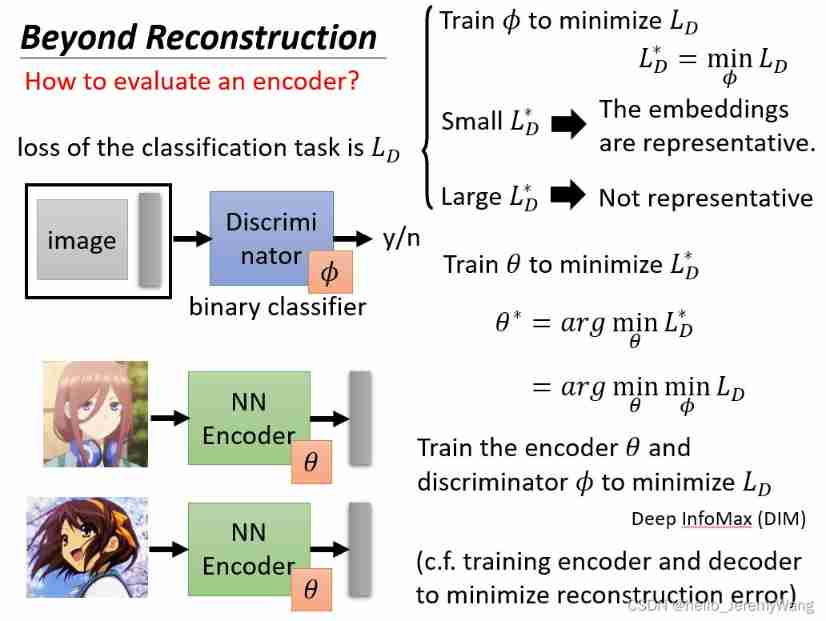
1.2 Requirement 2
Claim 2 requires us to get embedding More explanatory . Usually we get embedding It looks like a mess , Just like below PPT The picture in the upper right corner is the same . We want to know embedding What information does each part represent . As shown in the figure below , In speech training , What we got embedding It may contain the information of the speaker ( Such as : Pronunciation habits and so on ) And the information in the discourse itself , We want to separate them .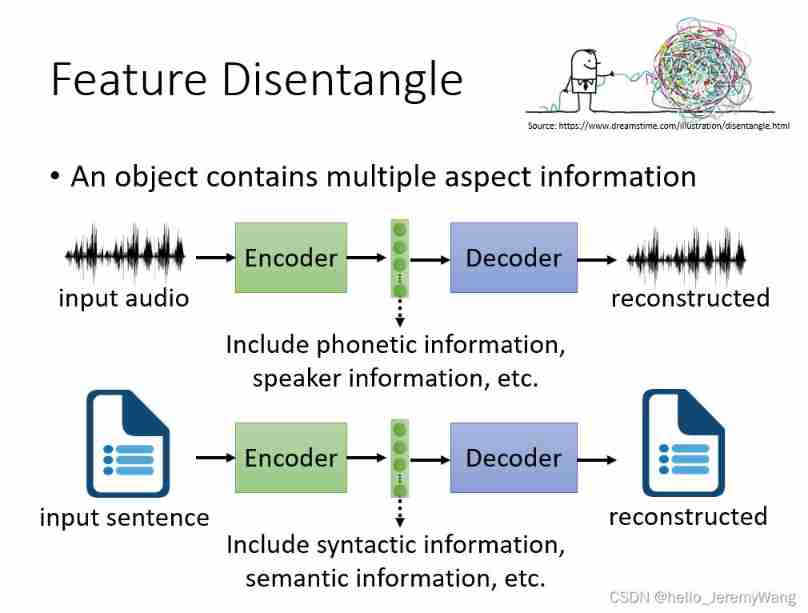
How to do it specifically ? A simple and natural idea is , We train two Encoder, One of them is specially used to extract the information of the speech itself , The other is used to extract the information of the speaker . What's the use ? For example, we can combine the information of another speaker with the information of the discourse itself , Realize the effect of changing sound .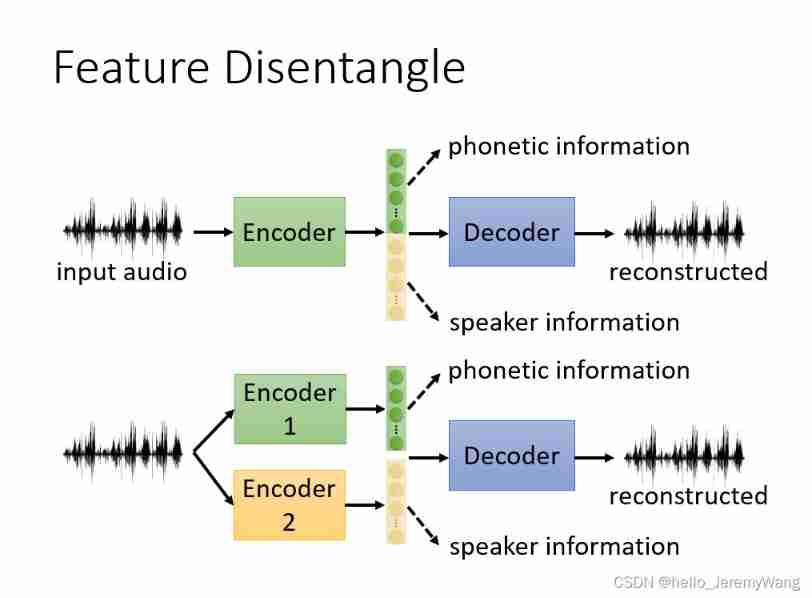
How to train? There are Encoder Well ? One way is reverse training . Similarly, we create a binary Discriminator, This Discriminator The function of is to eat the part that represents the information of the discourse itself embedding, And decide who said it . If our Encoder Be able to cheat Discriminator, He couldn't tell who said it , That explains this part embedding The information of the speaker is no longer contained in .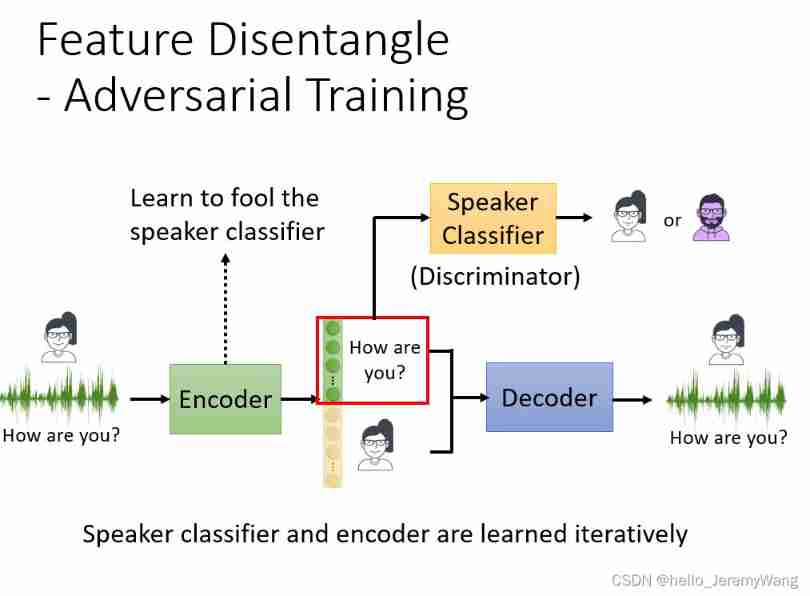
边栏推荐
- Decrypt the advantages of low code and unlock efficient application development
- Common tips
- MPLS experiment
- Snowflake won the 2021 annual database
- Azure solution: how can third-party tools call azure blob storage to store data?
- Hongke case study on storm impact in coastal areas of North Carolina using lidar
- JD home programmers delete databases and run away. Talk about binlog, the killer of MySQL data backup
- [Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 7
- World document to picture
- Supercomputing simulation research has determined a safe and effective carbon capture and storage route
猜你喜欢
![Entitas learning [iv] other common knowledge points](/img/1c/f899f4600fef07ce39189e16afc44a.jpg)
Entitas learning [iv] other common knowledge points
Reptile learning 3 (winter vacation learning)
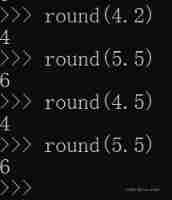
Global function Encyclopedia
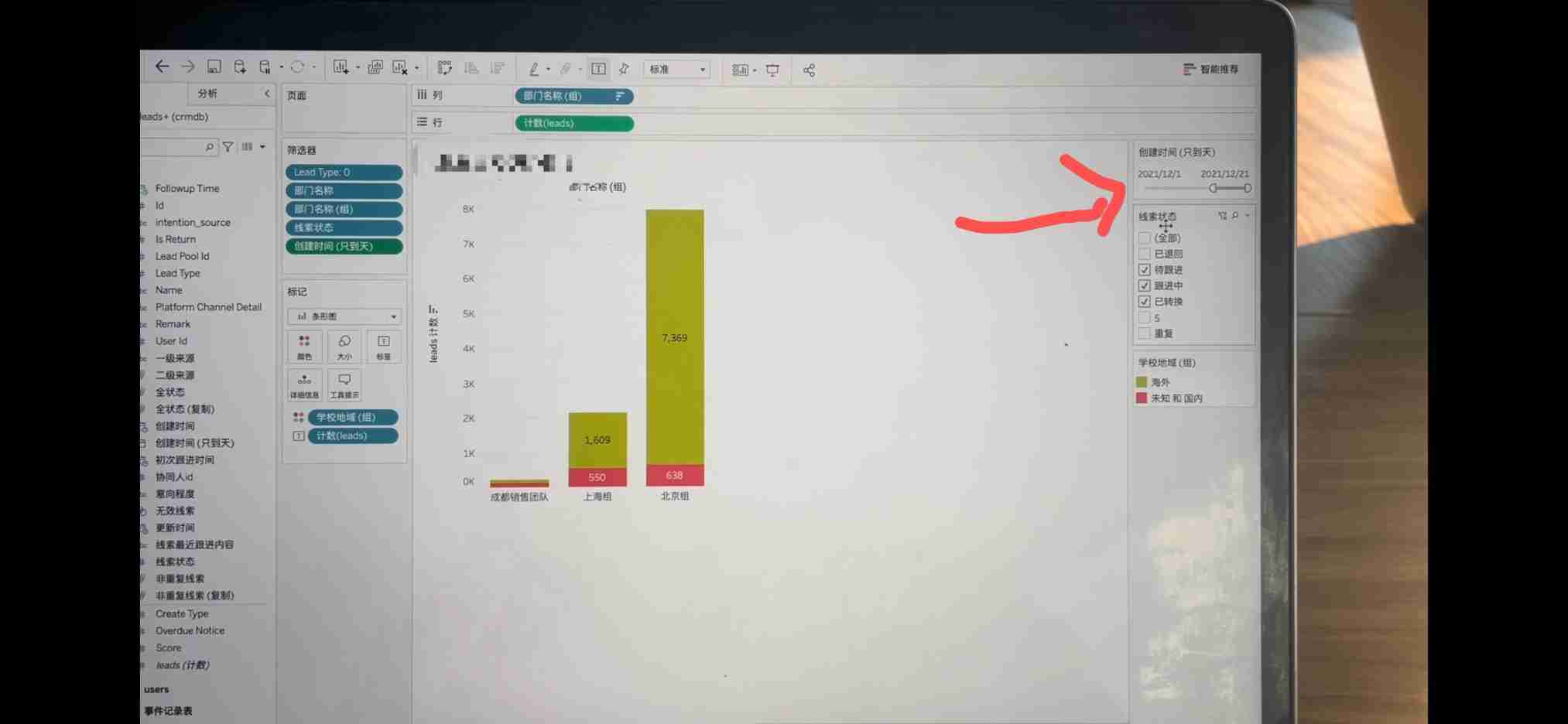
Tableau makes data summary after linking the database, and summary exceptions occasionally occur.
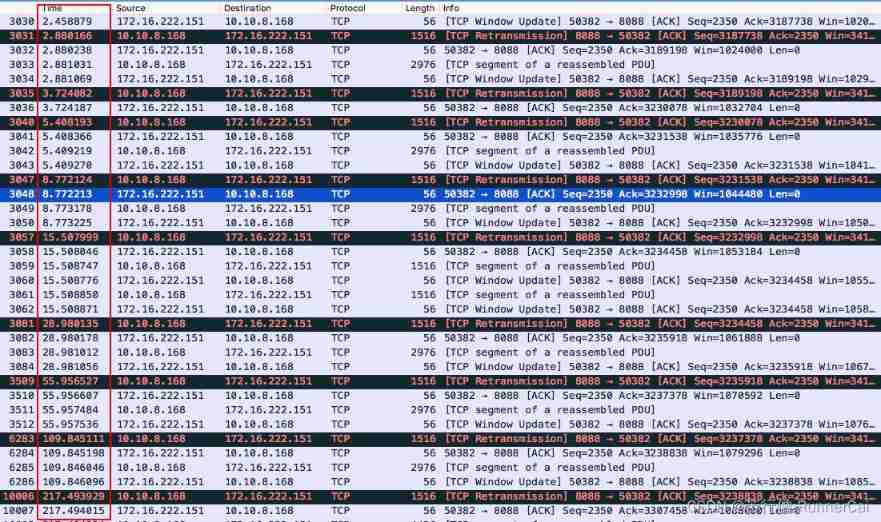
TCP fast retransmission sack mechanism

Hongke case study on storm impact in coastal areas of North Carolina using lidar
![[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 15](/img/72/0fe9cb032339d5f1ccf6f6c24edc57.jpg)
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 15
Alibaba cloud server connection intranet operation
Ternsort model integration summary
(August 10, 2021) web crawler learning - Chinese University ranking directed crawler
随机推荐
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 19
Number and math classes
Possible to restore a backup of SQL Server 2014 on SQL Server 2012?
2018 meisai modeling summary +latex standard meisai template sharing
priority_ queue
8.8.1-PointersOnC-20220214
Using terminal connection in different modes of virtual machine
LxC shared directory permission configuration
template<typename MAP, typename LIST, typename First, typename ... Keytypes > recursive call with indefinite parameters - beauty of Pan China
(2021-08-20) web crawler learning 2
. Does net 4 have a built-in JSON serializer / deserializer- Does . NET 4 have a built-in JSON serializer/deserializer?
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 10
Star leap plan | new projects are continuously being recruited! MSR Asia MSR Redmond joint research program invites you to apply!
[the way of programmer training] - 2 Perfect number calculation
Iframe to only show a certain part of the page
os. Path built-in module
Here, the DDS tutorial you want | first experience of fastdds - source code compilation & Installation & Testing
Entitas learning [3] multi context system
Ternsort model integration summary
22 API design practices