当前位置:网站首页>With the implementation of MapReduce job de emphasis, a variety of output folders
With the implementation of MapReduce job de emphasis, a variety of output folders
2022-07-06 18:25:00 【Full stack programmer webmaster】
Hello everyone , I meet you again , I'm the king of the whole stack .
Summarize a problem encountered in previous work .
background : Operation and maintenance and scribe from apacheserver Pushed to the log record again and again , So here ETL Deal with ongoing heavy . There is a need for multiple folders according to the output type of the business . Easy to hang partition , Use back . There is no problem with these two requirements, and they are handled separately , One mapreduce It's over , It takes a little skill .
1、map input data , After a series of processing . When the output :
if(ttype.equals("other")){
file = (result.toString().hashCode() & 0x7FFFFFFF)%400;
}else if(ttype.equals("client")){
file = (result.toString().hashCode() & 0x7FFFFFFF)%260;
}else{
file = (result.toString().hashCode()& 0x7FFFFFFF)%60;
}
tp = new TextPair(ttype+"_"+file, result.toString());
context.write(tp, valuet);valuet It's empty. , Nothing there? .
I have three types here .other,client,wap, Respectively represent the log source platform . Output by folder according to them . result It's the whole record .
file What you get is the final output file name ,hash. Bit operation , The purpose of taking modulus is to balance the output .
map The output structure of <key,value> =(ttype+”_”+file,result.toString()) The purpose of this is : Ensure that the same records get the same key, At the same time, save the type .partition To press textPair Of left, That's it key, It ensures that all records to be written to the same output file later will go to the same reduce In go to . One reduce Can write multiple output files . However, an output file cannot come from multiple reduce, The reason is very clear . Such words are probably 400+260+60=720 Output files , The amount of data in each file is almost the same ,job Of reduce Count what I set here 240, This number, together with modulus 400,260,60 It's all based on my data , To avoid reduce Data skew . 2、reduce Method de duplication :
public void reduce(TextPair key, Iterable<Text> values, Context context) throws IOException, InterruptedException
{
rcfileCols = getRcfileCols(key.getSecond().toString().split("\001"));
context.write(key.getFirst(), rcfileCols);
}No iteration , Yes, the same key Group . Output only once . Note that there job Comparator used , It must not be FirstComparator, But the whole textpair Right comparison .( Compare first left. Compare again right) The output file format of my program is rcfile. 3、 Multi folder output :
job.setOutputFormatClass(WapApacheMutiOutputFormat.class);
public class WapApacheMutiOutputFormat extends RCFileMultipleOutputFormat<Text, BytesRefArrayWritable> {
Random r = new Random();
protected String generateFileNameForKeyValue(Text key, BytesRefArrayWritable value,
Configuration conf) {
String typedir = key.toString().split("_")[0];
return typedir+"/"+key.toString();
}
}there RCFileMultipleOutputFormat I inherited it from FileOutputFormat His writing . Mainly achieved recordWriter.
Finally output the weight removed , Sub folder data file .
The key to understanding , Mainly partition key Design .reduce principle .
Copyright notice : This article is an original blog article , Blog , Without consent , Shall not be reproduced .
Publisher : Full stack programmer stack length , Reprint please indicate the source :https://javaforall.cn/117394.html Link to the original text :https://javaforall.cn
边栏推荐
猜你喜欢
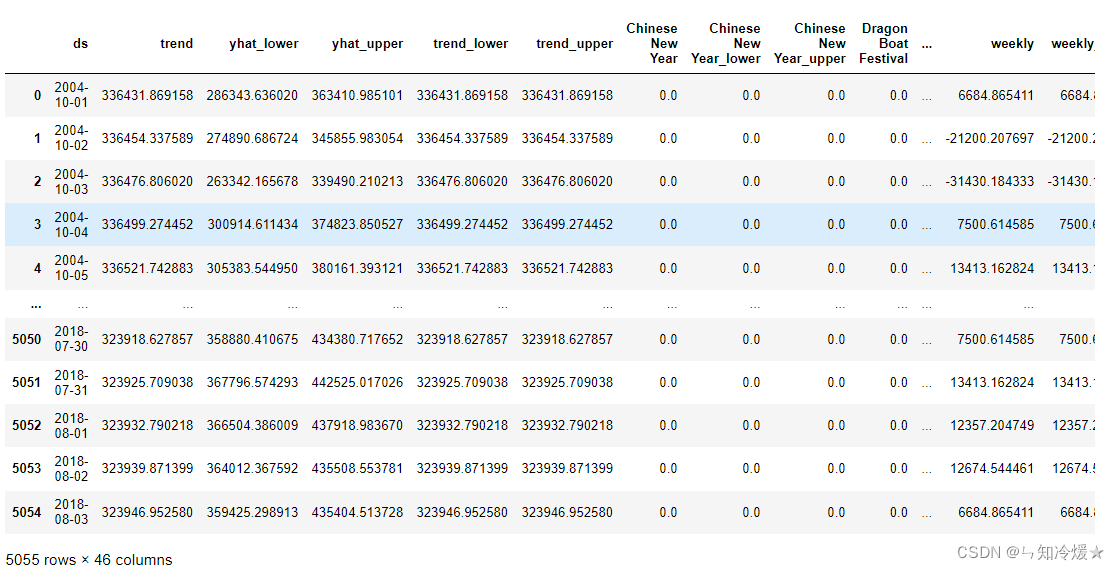
Prophet模型的简介以及案例分析

Rb157-asemi rectifier bridge RB157
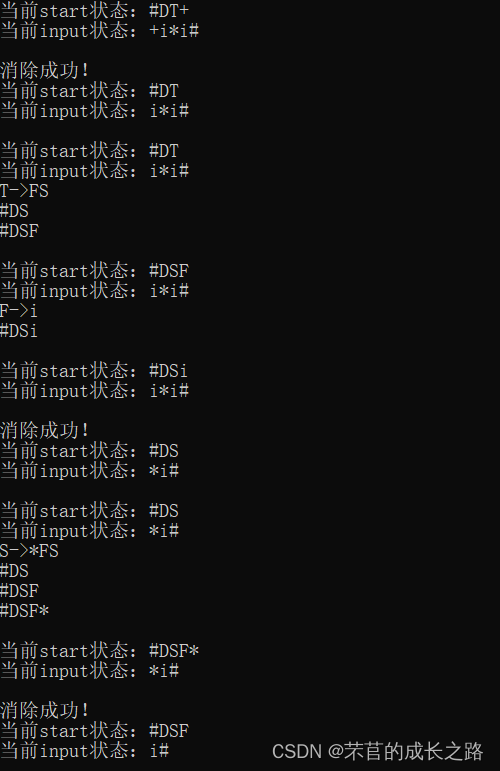
Compilation Principle -- C language implementation of prediction table

面向程序员的精品开源字体
![Jerry's updated equipment resource document [chapter]](/img/6c/17bd69b34c7b1bae32604977f6bc48.jpg)
Jerry's updated equipment resource document [chapter]
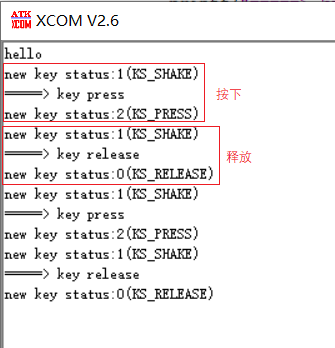
STM32 key state machine 2 - state simplification and long press function addition

Compilation principle - top-down analysis and recursive descent analysis construction (notes)

Declval of template in generic programming
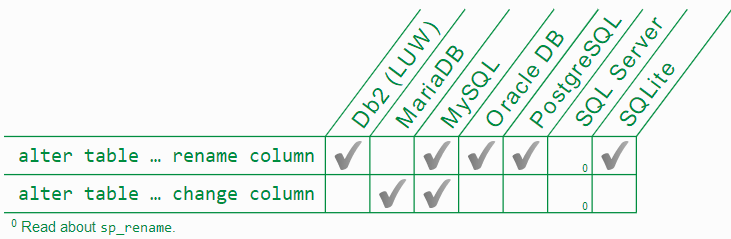
微信为什么使用 SQLite 保存聊天记录?
![[the 300th weekly match of leetcode]](/img/a7/16b491656863e2c423ff657ac6e9c5.png)
[the 300th weekly match of leetcode]
随机推荐
The difference between parallelism and concurrency
C语言高校实验室预约登记系统
Codeforces Round #803 (Div. 2)
Windows connects redis installed on Linux
Dichotomy (integer dichotomy, real dichotomy)
Recommend easy-to-use backstage management scaffolding, everyone open source
DOM简要
epoll()无论涉及wait队列分析
declval(指导函数返回值范例)
Markdown grammar - better blogging
SAP Fiori 应用索引大全工具和 SAP Fiori Tools 的使用介绍
Running the service with systemctl in the container reports an error: failed to get D-Bus connection: operation not permitted (solution)
atcoder它A Mountaineer
Interview shock 62: what are the precautions for group by?
Grafana 9.0 is officially released! It's the strongest!
徐翔妻子应莹回应“股评”:自己写的!
用友OA漏洞学习——NCFindWeb 目录遍历漏洞
Introduction and case analysis of Prophet model
Rb157-asemi rectifier bridge RB157
Cocos2d Lua 越来越小样本 内存游戏