当前位置:网站首页>go语言的字符串类型、常量类型和容器类型
go语言的字符串类型、常量类型和容器类型
2022-07-07 16:15:00 【march of Time】
go中的数据类型: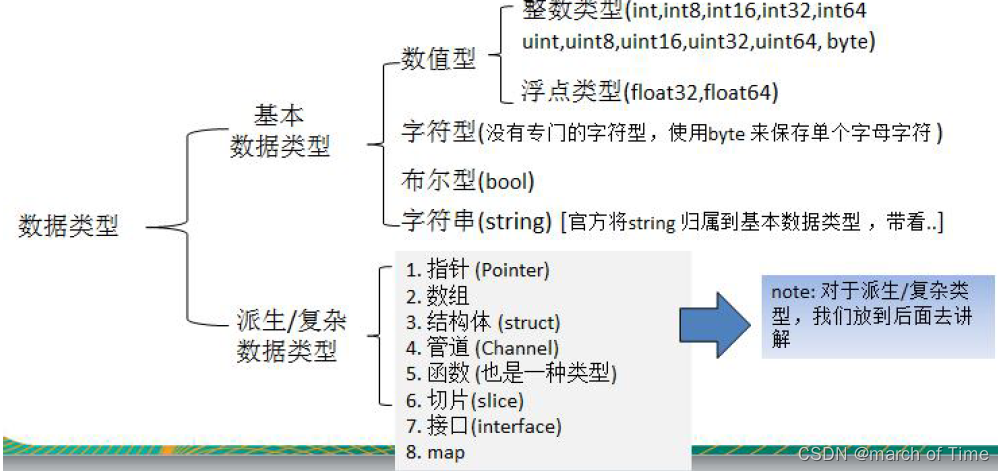
字符类型
Golang 中没有专门的字符类型,如果要存储单个字符(字母),一般使用byte 来保存。
字符串就是一串固定长度的字符连接起来的字符序列。Go 的字符串是由单个字节连接起来的。也就是说对于传统的字符串是由字符组成的,而Go 的字符串不同,它是由字节组成的。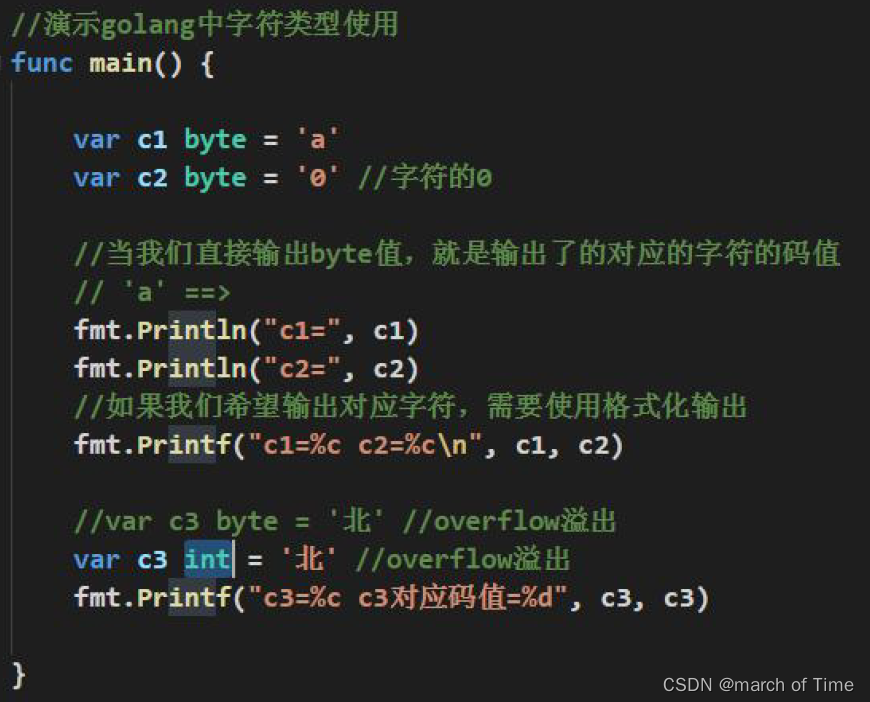
- 如果我们保存的字符在ASCII 表的,比如[0-1, a-z,A-Z…]直接可以保存到byte
- 如果我们保存的字符对应码值大于255,这时我们可以考虑使用int 类型保存
- 如果我们需要按照字符的方式输出,这时我们需要格式化输出,即fmt.Printf(“%c”, c1)…
在Go 中,字符的本质是一个整数,直接输出时,是该字符对应的UTF-8 编码的码值
字符串类型
- 字符串就是一串固定长度的字符连接起来的字符序列。Go 的字符串是由单个字节连接起来的。Go语言的字符串的字节使用UTF-8 编码标识Unicode 文本
- 字符串一旦赋值了,字符串就不能修改了:在Go 中字符串是不可变的。

- 字符串的两种表示形式
(1) 双引号, 会识别转义字符
(2) 反引号,以字符串的原生形式输出,包括换行和特殊字符,可以实现防止攻击、输出源代码等效果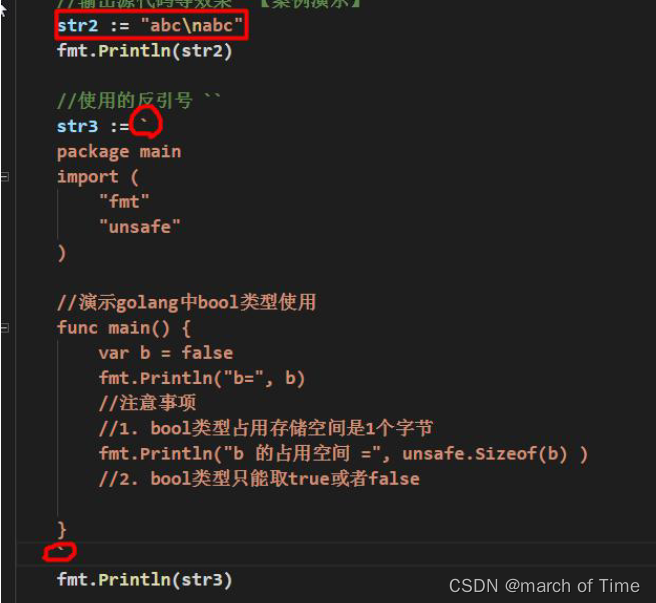
ASCII字符串和Unicode字符串
·ASCII字符串长度使用len()函数。
·Unicode字符串长度使用utf8.RuneCountInString()函数。如果希望按习惯上的字符个数来计算,就需要使用Go语言中UTF-8包提供的RuneCountInString()函数,统计Uncode字符数量。
1.遍历每一个ASCII字符 遍历ASCII字符使用for的数值循环进行遍历,直接取每个字符串的下标获取ASCII字符,如下面的例子所示。
theme := "狙击 start"
for i := 0; i < len(theme); i++ {
fmt.Printf("ascii: %c %d\n", theme[i], theme[i])
}
代码输出如下:
ascii: ? 231
ascii: 139
ascii: 153
ascii: ? 229
ascii: 135
ascii: ? 187
ascii: 32
ascii: s 115
ascii: t 116
ascii: a 97
ascii: r 114
ascii: t 116
这种模式下取到的汉字“惨不忍睹”。由于没有使用Unicode,汉字被显示为乱码。
2.按Unicode字符遍历字符串 同样的内容:
theme := "狙击 start"
for _, s := range theme {
fmt.Printf("Unicode: %c %d\n", s, s)
}
程序输出如下:
Unicode: 狙 29401
Unicode: 击 20987
Unicode: 32
Unicode: s 115
Unicode: t 116
Unicode: a 97
Unicode: r 114
Unicode: t 116
可以看到,这次汉字可以正常输出了。 总结:
·ASCII字符串遍历直接使用下标。
·Unicode字符串遍历用for range。
获取字符串的某一段字符获取字符串的某一段字符是开发中常见的操作。我们一般将字符串中的某一段字符称做:“子串”,英文对应substring。 下面例子中使用strings.Index()函数在字符串中搜索另外一个子串,代码如下:
tracer := "死神来了,死神bye bye"
comma := strings.Index(tracer, ",")
pos := strings.Index(tracer[comma:], "死神")
fmt.Println(comma, pos, tracer[comma+pos:])
程序输出如下: 12 3 死神bye bye
代码说明如下:
·第2行尝试在tracer的字符串中搜索中文的逗号,返回的位置存在comma变量中,类型是int,表示从tracer字符串开始的ASCII码位置。 strings.Index()函数并没有像其他语言一样,提供一个从某偏移开始搜索的功能。不过我们可以对字符串进行切片操作来实现这个逻辑。
·第4行中,tracer[comma:]从tracer的comma位置开始到tracer字符串的结尾构造一个子字符串,返回给string.Index()进行再索引。得到的pos是相对于tracer[comma:]的结果。 comma逗号的位置是12,而pos是相对位置,值为3。我们为了获得第二个死神的位置,也就是逗号后面的字符串,就必须让comma加上pos的相对偏移,计算出15的偏移,然后再通过切片tracer[comma+pos:]计算出最终的子串,获得最终的结果:“死神bye bye”。
总结: 字符串索引比较常用的有如下几种方法。
·strings.Index:正向搜索子字符串。
·strings.LastIndex:反向搜索子字符串。 ·搜索的起始位置可以通过切片偏移制作。
修改字符串
Go语言的字符串无法直接修改每一个字符元素,只能通过重新构造新的字符串并赋值给原来的字符串变量实现。请参考下面的代码:
angel := "Heros never die"
angleBytes := []byte(angel)
for i := 5; i <= 10; i++ {
angleBytes[i] = ' '
}
fmt.Println(string(angleBytes))
在完成了对[]byte操作后,在第9行,使用string()将[]byte转为字符串时,重新创造了一个新的字符串。
总结:
·Go语言的字符串是不可变的。
·修改字符串时,可以将字符串转换为[]byte进行修改。
·[]byte和string可以通过强制类型转换互转。
2.6.5 连接字符串
连接字符串这么简单,还需要学吗?确实,Go语言和大多数其他语言一样,使用“+”对字符串进行连接操作,非常直观。 但问题来了,好的事物并非完美,简单的东西未必高效。除了加号连接字符串,Go语言中也有类似于StringBuilder的机制来进行高效的字符串连接,例如:
import (
"bytes"
"fmt"
)
func main() {
hammer :="吃我一锤"
stick:="死吧"
var stringBuilder bytes.Buffer
stringBuilder.WriteString(hammer)
stringBuilder.WriteString(stick)
fmt.Print(stringBuilder.String())
}
bytes.Buffer是可以缓冲并可以往里面写入各种字节数组的。字符串也是一种字节数组,使用WriteString()方法进行写入。 将需要连接的字符串,通过调用WriteString()方法,写入stringBuilder中,然后再通过stringBuilder.String()方法将缓冲转换为字符串。
格式化
格式化在逻辑中非常常用。使用格式化函数,要注意写法: fmt.Sprintf(格式化样式,参数列表…)
·格式化样式:字符串形式,格式化动词以%开头。
在Go语言中,格式化的命名延续C语言风格:
var progress = 2
var target = 8
// 两参数格式化
title := fmt.Sprintf("已采集%d个药草,还需要%d个完成任务", progress, target)
fmt.Println(title)
pi := 3.14159
// 按数值本身的格式输出
variant := fmt.Sprintf("%v %v %v", "月球基地", pi, true)
fmt.Println(variant)
// 匿名结构体声明,并赋予初值
profile := &struct {
Name string
HP int
}{
Name: "rat",
HP: 150,
}
fmt.Printf("使用'%%+v' %+v\n", profile)
fmt.Printf("使用'%%#v' %#v\n", profile)
fmt.Printf("使用'%%T' %T\n", profile)
代码输出如下: 已采集2个药草,还需要8个完成任务
“月球基地” 3.14159 true
使用’%+v’ &{Name:rat HP:150}
使用’%#v’ &struct { Name string; HP int }{Name:“rat”, HP:150}
使用’%T’ *struct { Name string; HP int }C语言中,使用%d代表整型参数
常量
相对于变量,常量是恒定不变的值,例如圆周率。 可以在编译时,对常量表达式进行计算求值,并在运行期使用该计算结果,计算结果无法被修改。 常量表示起来非常简单,如下面的代码:
const pi = 3.141592
const e = 2.718281
常量的声明和变量声明非常类似,只是把var换成了const。 多个变量可以一起声明,类似的,常量也是可以多个一起声明的,如下面的代码:
const (
pi = 3.141592
e = 2.718281
)
常量因为在编译期确定,所以可以用于数组声明,如下面的代码: const size = 4
var arr [size]int
容器类型
变量在一定程度上能满足函数及代码要求。如果编写一些复杂算法、结构和逻辑,就需要更复杂的类型来实现。这类复杂类型一般情况下具有各种形式的存储和处理数据的功能,将它们称为“容器”。 在很多语言里,容器是以标准库的方式提供,你可以随时查看这些标准库的代码,了解如何创建,删除,维护内存。 提示: ·C语言没有提供容器封装,开发者需要自己根据性能需求进行封装,或者使用第三方提供的容器。 ·C++语言的容器通过标准库提供,如vector对应数组,list对应双链表,map对应映射等。本章将以实用为目的,详细介绍数组、切片、映射,以及列表的增加、删除、修改和遍历的使用方法。本章既可以作为教程,也可以作为字典,以方便开发者日常的查询和应用。
1.数组
数组是一段固定长度的连续内存区域。 在Go语言中,数组从声明时就确定,使用时可以修改数组成员,但是数组大小不可变化。
提示:C语言和Go语言中的数组概念完全一致。C语言的数组也是一段固定长度的内存区域,数组的大小在声明时固定下来。
声明数组
数组的写法如下:
var 数组变量名 [元素数量]T
var team[2]string
team[0]="hammmer"
team[1]="solider"
或者:
var team = [3]string{
"hammer","solider","mum"}
但一般情况下,这个过程可以交给编译器,让编译器在编译时,根据元素个数确定数组大小。
var team = [...]string{
"hammer", "soldier", "mum"}
“…”表示让编译器确定数组大小。上面例子中,编译器会自动为这个数组设置元素个数为3。
使用For循环遍历:
for k, v := range team {
fmt.Println(k, v)
}
//k是索引,v是元素值
2.切片(slice)
——动态分配大小的连续空间
Go语言切片的内部结构包含地址、大小和容量。切片一般用于快速地操作一块数据集合。如果将数据集合比作切糕的话,切片就是你要的“那一块”。切的过程包含从哪里开始(这个就是切片的地址)及切多大(这个就是切片的大小)
切片默认指向一段连续内存区域,可以是数组,也可以是切片本身。 从连续内存区域生成切片是常见的操作,格式如下:
slice [开始位置:结束位置]
·slice表示目标切片对象。
·开始位置对应目标切片对象的索引。
·结束位置对应目标切片的结束索引。 从数组生成切片,代码如下:
var a = [3]int{
1, 2, 3}
fmt.Println(a, a[1:2])
·取出的元素数量为:结束位置-开始位置。
·取出元素不包含结束位置对应的索引,切片最后一个元素使用slice[len(slice)]获取。
·当缺省开始位置时,表示从连续区域开头到结束位置。
·当缺省结束位置时,表示从开始位置到整个连续区域末尾。
·两者同时缺省时,与切片本身等效。
·两者同时为0时,等效于空切片,一般用于切片复位。 ·根据索引位置取切片slice元素值时,取值范围是(0~len(slice)-1),超界会报运行时错误。生成切片时,结束位置可以填写len(slice)但不会报错。
从指定范围中生成切片
切片和数组密不可分。如果将数组理解为一栋办公楼,那么切片就是把不同的连续楼层出租给使用者。出租的过程需要选择开始楼层和结束楼层,这个过程就会生成切片。示例代码如下:
var light[30]int
for i:=0;i<30;i++{
light[i]=i+1;
}
fmt.Print(light[2:5])
fmt.Print(light[:10])
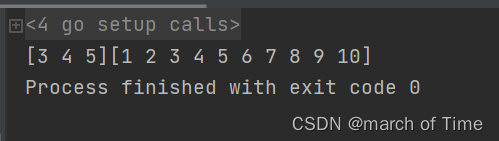
表示原有的切片:
a := []int{
1, 2, 3}
fmt.Println(a[:])
a是一个拥有3个元素的切片。将a切片使用a[:]进行操作后,得到的切片与a切片一致
把切片的开始和结束位置都设为0时,生成的切片将变空,代码如下:
a := []int{
1, 2, 3}
fmt.Println(a[0:0])
声明切片
每一种类型都可以拥有其切片类型,表示多个类型元素的连续集合。因此切片类型也可以被声明。切片类型声明格式如下:var name []T
·name表示切片类型的变量名。
·T表示切片类型对应的元素类型。
下面代码展示了切片声明的使用过程。
// 声明字符串切片
var strList []string
// 声明整型切片
var numList []int
// 声明一个空切片
var numListEmpty = []int{
}
// 输出3个切片
fmt.Println(strList, numList, numListEmpty)
// 输出3个切片大小
fmt.Println(len(strList), len(numList), len(numListEmpty))
// 切片判定空的结果
fmt.Println(strList == nil)
fmt.Println(numList == nil)
fmt.Println(numListEmpty == nil)
使用make()函数构造切片
如果需要动态地创建一个切片,可以使用make()内建函数,格式如下:
make( []T, size, cap )
·T:切片的元素类型。
·size:就是为这个类型分配多少个元素。
·cap:预分配的元素数量,这个值设定后不影响size,只是能提前分配空间,降低多次分配空间造成的性能问题。
示例如下:
a := make([]int, 2)
b := make([]int, 2, 10)
fmt.Println(a, b)
fmt.Println(len(a), len(b))
[0 0] [0 0]
2 2
a和b均是预分配2个元素的切片,只是b的内部存储空间已经分配了10个,但实际使用了2个元素。 容量不会影响当前的元素个数,因此a和b取len都是2。
使用append()函数为切片添加元素
Go语言的内建函数append()可以为切片动态添加元素。每个切片会指向一片内存空间,这片空间能容纳一定数量的元素。当空间不能容纳足够多的元素时,切片就会进行“扩容”。“扩容”操作往往发生在append()函数调用时。
var numbers []int
for i := 0; i < 10; i++ {
numbers = append(numbers, i)
fmt.Printf("len: %d cap: %d pointer: %p\n", len(numbers), cap(numbers), numbers)
}
append()函数除了添加一个元素外,也可以一次性添加很多元素。
01 var car []string
02
03 // 添加1个元素
04 car = append(car, "OldDriver")
05
06 // 添加多个元素
07 car = append(car, "Ice", "Sniper", "Monk")
08
09 // 添加切片
10 team := []string{
"Pig", "Flyingcake", "Chicken"}
11 car = append(car, team...)
12
·第11行,在team后面加上了“…”,表示将team整个添加到car的后面。
复制切片:
使用Go语言内建的copy()函数,可以迅速地将一个切片的数据复制到另外一个切片空间中,copy()函数
copy( destSlice, srcSlice []T) int
·srcSlice为数据来源切片。
·destSlice为复制的目标。目标切片必须分配过空间且足够承载复制的元素个数。来源和目标的类型一致,copy的返回值表示实际发生复制的元素个数。,
// 设置元素数量为1000
const elementCount = 1000
// 预分配足够多的元素切片
srcData := make([]int, elementCount)
// 将切片赋值
for i := 0; i < elementCount; i++ {
srcData[i] = i
}
// 引用切片数据
refData := srcData
// 预分配足够多的元素切片
copyData := make([]int, elementCount)
// 将数据拷贝到新的切片空间中
copy(copyData, srcData)
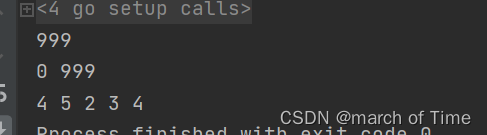
// 修改原数据的第一个元素
srcData[0] = 999
// 打印引用切片的第一个元素
fmt.Println(refData[0])
// 打印拷贝切片的第一个和最后元素
fmt.Println(copyData[0], copyData[elementCount-1])
// 拷贝原数据从4到6(不包含)
copy(copyData, srcData[4:6])
for i := 0; i < 5; i++ {
fmt.Printf("%d ", copyData[i])
}
3.map
Go语言提供的映射关系容器为map。map使用散列表(hash)实现。散列表可以简单描述为一个数组(俗称“桶”),数组的每个元素是一个列表。根据散列函数获得每个元素的特征值,将特征值作为映射的键。如果特征值重复,表示元素发生碰撞。碰撞的元素将被放在同一个特征值的列表中进行保存。散列表查找复杂度为O(1),和数组一致。最坏的情况为O(n),n为元素总数。散列需要尽量避免元素碰撞以提高查找效率,这样就需要对“桶”进行扩容,每次扩容,元素需要重新放入桶中,较为耗时。
01 scene := make(map[string]int)
02
03 scene["route"] = 66
04
05 fmt.Println(scene["route"])
06
07 v := scene["route2"]
08 fmt.Println(v)
代码输出如下:
66
0
代码说明如下: ·第1行map是一个内部实现的类型,使用时,需要手动使用make创建。如果不创建使用map类型,会触发宕机错误。 ·第3行向map中加入映射关系。写法与使用数组一样,key可以使用除函数以外的任意类型。 ·第5行查找map中的值。 ·第7行中,尝试查找一个不存在的键,那么返回的将是ValueType的默认值。 某些情况下,需要明确知道查询中某个键是否在map中存在,可以使用一种特殊的写法来实现,看下面的代码:
v, ok := scene[“route”]
在默认获取键值的基础上,多取了一个变量ok,可以判断键route是否存在于map中。
使用delete()内建函数从map中删除一组键值对,delete()函数的格式如下: delete(map, 键)
scene := make(map[string]int)
// 准备map数据
scene["route"] = 66
scene["brazil"] = 4
scene["china"] = 960
delete(scene, "brazil")
for k, v := range scene {
fmt.Println(k, v)
}
能够在并发环境中使用的map——sync.Map Go语言中的map在并发情况下,只读是线程安全的,同时读写线程不安全。 下面来看下并发情况下读写map时会出现的问题,代码如下:
// 创建一个int到int的映射
m := make(map[int]int)
// 开启一段并发代码
go func() {
// 不停地对map进行写入
for {
m[1] = 1
}
}()
// 开启一段并发代码
go func() {
// 不停地对map进行读取
for {
_ = m[1]
}
}()
// 无限循环,让并发程序在后台执行
for {
}
运行时输出提示:并发的map读写。也就是说使用了两个并发函数不断地对map进行读和写而发生了竞态问题。map内部会对这种并发操作进行检查并提前发现。 需要并发读写时,一般的做法是加锁,但这样性能并不高。Go语言在1.9版本中提供了一种效率较高的并发安全的sync.Map。sync.Map和map不同,不是以语言原生形态提供,而是在sync包下的特殊结构。
sync.Map有以下特性: ·无须初始化,直接声明即可。 ·sync.Map不能使用map的方式进行取值和设置等操作,而是使用sync.Map的方法进行调用。Store表示存储,Load表示获取,Delete表示删除。
·使用Range配合一个回调函数进行遍历操作,通过回调函数返回内部遍历出来的值。Range参数中的回调函数的返回值功能是:需要继续迭代遍历时,返回true;终止迭代遍历时,返回false。
02
03 import (
04 "fmt"
05 "sync"
06 )
07
08 func main() {
09
10 var scene sync.Map
11
12 // 将键值对保存到sync.Map
13 scene.Store("greece", 97)
14 scene.Store("london", 100)
15 scene.Store("egypt", 200)
16
17 // 从sync.Map中根据键取值
18 fmt.Println(scene.Load("london"))
19
20 // 根据键删除对应的键值对
21 scene.Delete("london")
22
23 // 遍历所有sync.Map中的键值对
24 scene.Range(func(k, v interface{
}) bool {
25
26 fmt.Println("iterate:", k, v)
27 return true
28 })
29
30 }
·第10行,声明scene,类型为sync.Map。注意,sync.Map不能使用make创建。 ·第13~15行,将一系列键值对保存到sync.Map中,sync.Map将键和值以interface{}类型进行保存。
·第18行,提供一个sync.Map的键给scene.Load()方法后将查询到键对应的值返回。 ·第21行,sync.Map的Delete可以使用指定的键将对应的键值对删除。
·第24行,Range()方法可以遍历sync.Map,遍历需要提供一个匿名函数,参数为k、v,类型为interface{},每次Range()在遍历一个元素时,都会调用这个匿名函数把结果返回。
sync.Map没有提供获取map数量的方法,替代方法是获取时遍历自行计算数量。sync.Map为了保证并发安全有一些性能损失,因此在非并发情况下,使用map相比使用sync.Map会有更好的性能。
列表
列表是一种非连续存储的容器,由多个节点组成,节点通过一些变量记录彼此之间的关系。列表有多种实现方法,如单链表、双链表等。 列表的原理可以这样理解:假设A、B、C三个人都有电话号码,如果A把号码告诉给B,B把号码告诉给C,这个过程就建立了一个单链表结构
list的初始化有两种方法:New和声明。两种方法的初始化效果都是一致的。 1.通过container/list包的New方法初始化list
变量名 := list.New()
2.通过声明初始化
list var 变量名 list.List
列表与切片和map不同的是,列表并没有具体元素类型的限制。因此,列表的元素可以是任意类型。这既带来遍历,也会引来一些问题。给一个列表放入了非期望类型的值,在取出值后,将interface{}转换为期望类型时将会发生宕机。
例子:
l := list.New()
// 尾部添加
l.PushBack("canon")
// 头部添加
l.PushFront(67)
// 尾部添加后保存元素句柄
element := l.PushBack("fist")
// 在“fist”之后添加”high”
l.InsertAfter("high", element)
// 在“fist”之前添加”noon”
l.InsertBefore("noon", element)
// 使用
l.Remove(element)
边栏推荐
- Yearning-SQL审核平台
- 3分钟学会制作动态折线图!
- Taffydb open source JS database
- debian10编译安装mysql
- Supplementary instructions to relevant rules of online competition
- 现在网上期货开户安全吗?国内有多少家正规的期货公司?
- PHP面试题 foreach($arr as &$value)与foreach($arr as $value)的用法
- Personal best practice demo sharing of enum + validation
- How to clean when win11 C disk is full? Win11 method of cleaning C disk
- Performance test process and plan
猜你喜欢
Introduction of common API for socket programming and code implementation of socket, select, poll, epoll high concurrency server model

Discuss | what preparations should be made before ar application is launched?
swiper左右切换滑块插件
手撕Nacos源码(先撕客户端源码)
Discuss | frankly, why is it difficult to implement industrial AR applications?
In depth understanding of USB communication protocol

通过 Play Integrity API 的 nonce 字段提高应用安全性

用存储过程、定时器、触发器来解决数据分析问题
How to clean when win11 C disk is full? Win11 method of cleaning C disk

【蓝桥杯集训100题】scratch从小到大排序 蓝桥杯scratch比赛专项预测编程题 集训模拟练习题第17题
随机推荐
测试3个月,成功入职 “字节”,我的面试心得总结
备份阿里云实例-oss-browser
The report of the state of world food security and nutrition was released: the number of hungry people in the world increased to 828million in 2021
[trusted computing] Lesson 11: TPM password resource management (III) NV index and PCR
[PaddleSeg源码阅读] PaddleSeg Validation 中添加 Boundary IoU的计算(1)——val.py文件细节提示
[trusted computing] Lesson 12: TPM authorization and conversation
基于百度飞浆平台(EasyDL)设计的人脸识别考勤系统
仿今日头条APP顶部点击可居中导航
Main work of digital transformation
YARN Capacity Scheduler容量调度器(超详细解读)
【4500字归纳总结】一名软件测试工程师需要掌握的技能大全
Youth experience and career development
[trusted computing] Lesson 13: TPM extended authorization and key management
Performance test process and plan
Hash, bitmap and bloom filter for mass data De duplication
nest.js入门之 database
SD_DATA_RECEIVE_SHIFT_REGISTER
zdog. JS rocket turn animation JS special effects
Chapter 2 build CRM project development environment (database design)
socket編程之常用api介紹與socket、select、poll、epoll高並發服務器模型代碼實現