当前位置:网站首页>data2vec! New milestone of unified mode
data2vec! New milestone of unified mode
2022-07-03 04:29:00 【kaiyuan_ sjtu】

writing | ZenMoore
Ed | Xiaoyi
Let me give you an example of the most successful self-monitoring model , Especially for you NLPer, I'm sure to sacrifice without hesitation BERT. Think that year BERT Hit a man named MLM (Masked Language Model) Snap your fingers , Directly became NLP Thanos .
Visual world 、 The voice industry heard the sound , It's all on BERT Visualization of 、 Voice transformation .
Visual world , With patch Or pixel analogy NLP Of token; Phonetic circle , Although you can't find it directly token An alternative , But it can be specially done quantification Hard build token.
however , Think about such a problem : Why are these images or voice modes self supervised , I have to share NLP Taste ?
Need to know , Although there are biological studies that show , When human beings are learning visually , Will use a mechanism similar to language learning , however , such learning biases It is not necessarily possible to generalize to other modes .
So is there any way , can Unify the self supervised representation learning of different modes , No longer imitate MLM do MIM (Masked Image Modelling)、MAM (Masked Audio Modelling)?
yesterday ,Meta AI ( primary Facebook) Release the latest self supervised learning framework Data2Vec, Immediately throughout AI Circle crazy screen swiping . This job may herald —— A new era of multimodality , Coming soon .
This article will give you a brief explanation , This AI Today's headlines , What has been done .
Paper title :
Data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language
Author of the paper :
Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli
Meta AI, SambaNova
Thesis link :
https://ai.facebook.com/research/data2vec-a-general-framework-for-self-supervised-learning-in-speech-vision-and-language
Model algorithm
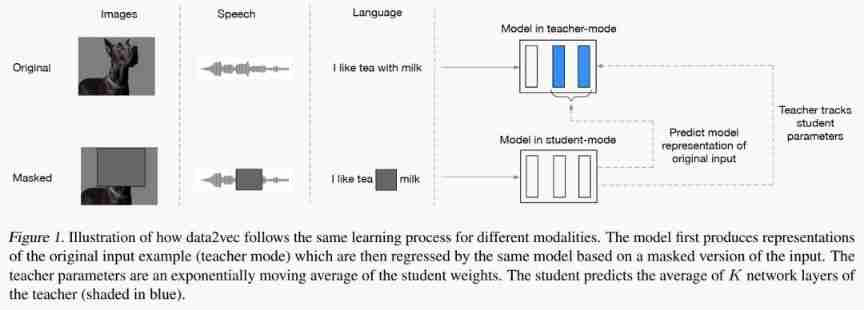
code 、 Mask
First , For three different modes : Text 、 Images 、 voice , Adopt different encoding methods and mask methods .
Mode specific encoding :
Text mode : token embedding
Image mode : Reference resources ViT[1, 2], With image patch In units of , After a linear transformation (linear transformation)
Voice mode : Use multilayer one-dimensional convolution pairs waveform Encoding [3].
Mode specific mask mode :
Text mode : Yes token Mask
Image mode :block-wise masking strategy [2]
Voice mode : For voice mode , Adjacent audio clips are highly correlated , So you need to span of latent speech representation Mask [3]
The mask is obtained after training MASK embedding token, Not simply MASK token, See the reasons below .
Student : model training
after , stay student-mode in , according to masked input For mask position Express To make predictions . It should be noted that , What the model predicts here is not the mask position ( Such as text token, pixel/patch, speech span), It is The representation of mask position after model coding . Because this expression has passed Attention/FFN Wait for a series of module processing , Naturally Modal independent , More Than This , It's still Successive (continuous), Encoded a wealth of Context semantics (contextualized).
If the input space is compared to the physical world , Space is compared to spiritual space . that , The author is equivalent to directly in “ Spiritual space ” Imagine the covered part of (mask), There is quite a way “ Flowers in my dream ” The feeling of . Last time I saw this “ Dream general ” The algorithm of , still Hinton Old man's Sleep-Wake[4].
In particular , The training objectives are as follows smooth L1 loss:
among , For the use of teacher model Built training target; by student model At the moment Output ; It's a superscript , Used to adjust L1 Lost smoothness .
Teacher : Data construction
Last , There's another problem , Since it becomes the mask of the representation instead of the original input , So how to get the training data ?
This is it. teacher-mode The magic effect of . And student-mode The difference is ,teacher-mode The input of is no longer masked input, It is original input, such , The mask position is for teacher It is visible , Naturally, we can get the representation corresponding to the mask position , And this means , Namely student-mode Of training target.
Of course , In order to ensure “ Teachers and students ” Consistency of the two models , Of the two Parameters are shared . in addition , In order to make Teacher The parameter update of is faster , The author adopts an exponential moving average (EMA):.
among , yes Teacher Parameters of , yes Student Parameters of , Similar to the learning rate , Is also a with scheduler Parameters of .
In particular ,training target So build ( Step by step ):
find student-mode Input is mask Dropped time-step
Calculation teacher network Last K layer transformer block Output :
normalization :
Average : , namely training target.
For the normalization of the third step : Voice mode is instance normalization Text and image modes are parameter-less layer normalization
Representation Collapse
In the experiment , The author also encountered Representation Collapse The problem of : The output of the model is very similar for all mask fragments representation.
There are many solutions to this ~ For this article , There are several situations :
Learning rate is too high or its warmup Too short : Solve by adjusting parameters
The exponential moving average is too slow : Or adjust parameters
For adjacency target Modes with strong correlation or modes with long mask fragments ( For example, voice mode ): Set up variance Penalty item [5], Or normalization [6], The effect of normalization is better .
And for targets Less relevant modes, such as NLP/CV etc. ,momentum tracking It's enough .
Comparison with similar work
And others NLP Comparison of self-monitoring algorithms :
and BERT Different , What this paper predicts is not discrete token, It is continuous/contextualized representation.
benefits 1: target No predefined ( For example, there is a predefined vocabulary ), target set Also infinite ( Because it's continuous ), Therefore, the model can better adapt to specific inputs
benefits 2: Consider more contextual information
And others CV Comparison of self-monitoring algorithms :
And BYOL[6]/DINO[7] etc. : This article adds a mask prediction task , And it is the regression of multiple layers ( The parameter K)
And BEiT[2]/MAE[8] Wait for the algorithm of masked prediction task : This paper deals with latent representation To make predictions
And others Speech Comparison of self-monitoring algorithms :
And Wav2vec2.0[3]/HuBERT[9] etc. : Other work generally requires additional prediction speech Discrete element in ( Or joint learning or interactive learning ), This article does not need such quantification.
Comparison with multimodal pre training :
The focus of this paper is not on multimodal tasks or multimodal training , But how to unify the self-regulated learning objectives of different modes .
experimental result
Computer vision
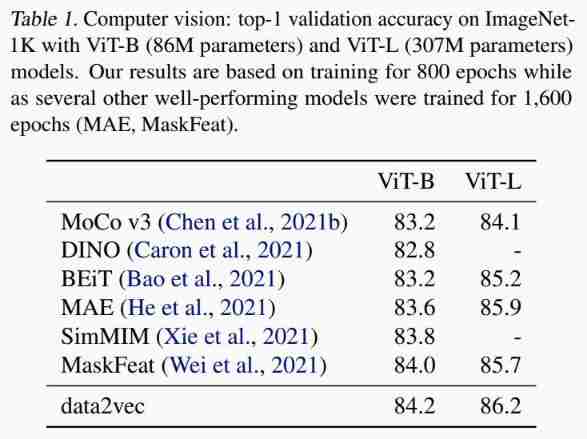
Experiment task :Image Classification
The experimental conclusion : It can be seen that the work of this paper has been significantly improved
voice
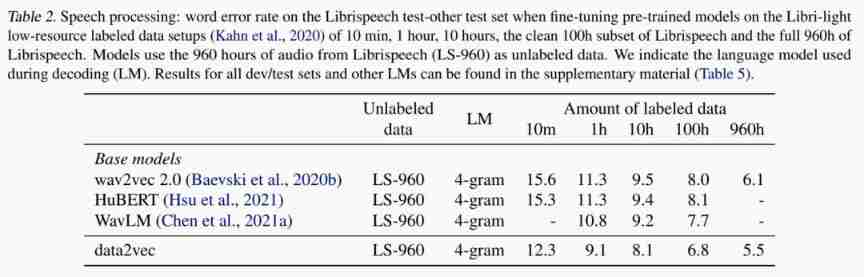
Experiment task :Automatic Speech Recognition
The experimental conclusion : The improvement is obvious
Natural Language Processing

wav2vec 2.0 masking : masking span of four tokens[3]
Experiment task :GLUE
experimental result : The author only compares 19 Two of the year baseline, It shows that the improvement effect on text mode is still limited , But this score is also very good
Ablation 1 : layer-averaged targets
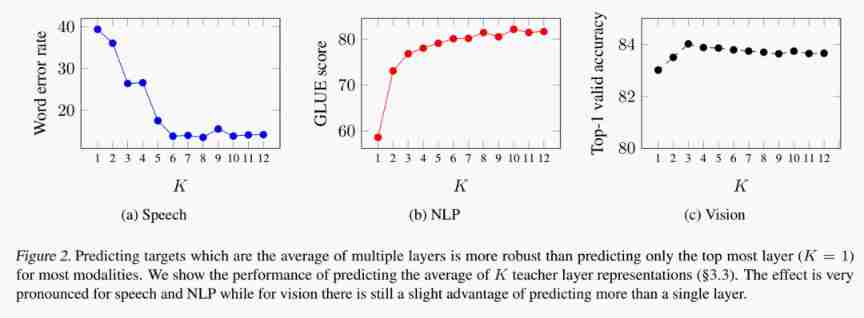
It's also with BYOL[6]/DINO[7] A big difference between other models : Regression of multiple layers
As can be seen from the chart , Rather than just using top layer, Average multilayer output to build target It's very effective !
Ablation 2 : Use Transformer Which floor of the building ?

Experiment based on speech mode , Discover the use of FFN Layer output is the most effective , Using the output of the self attention module is basically useless . reason : Self attention module before residual connection , Got feature With great deviation (bias).
At the end
Maybe , Self supervised representation learning for mask prediction in representation space rather than input space , It is an important direction of self-monitoring in the future !
however , The authors also point out that Data2Vec A major limitation of : The encoding method and mask method are still modality-specific Of . Can I use something similar to Perceiver[10] The way is directly in raw data Operation on top ? Or is it really necessary to unify all modes encoder Well ?
I still remember that there was such a share in the group of authors selling cute houses , yes Yoshua Bengio Wait in EMNLP'20 The article [11], It defines NLP Five stages of development :

Beyond all doubt , Multimodal fervor marks that we are entering the third stage : Multimodal era .
Data2Vec Use... Cleverly “ Flowers in my dream ” The way , Let us see the powerful power of self supervision , It also makes us realize that the great cause of modal unity is at hand ! Maybe , current Data2Vec, Just a gem that cannot exert its full power , It's like Word2Vec equally , But I believe that in the near future , from Data2Vec set out , You can see the unified multimodal mieba , It's like BERT like that ! The rain is coming , The wind filled the building !
Communicate together
I want to learn and progress with you !『NewBeeNLP』 At present, many communication groups in different directions have been established ( machine learning / Deep learning / natural language processing / Search recommendations / Figure network / Interview communication / etc. ), Quota co., LTD. , Quickly add the wechat below to join the discussion and exchange !( Pay attention to it o want Notes Can pass )

[1] An image is worth 16x16 words: Transformers for image recognition at scale.
https://arxiv.org/abs/2010.11929[2] Beit: BERT pre-training of image transformers.
https://arxiv.org/abs/2106.08254[3] Baevski, A., Zhou, Y., Mohamed, A., and Auli, M. wav2vec 2.0: A framework for self-supervised learning of speech representations. In Proc. of NeurIPS, 2020b
[4] The wake-sleep algorithm for unsupervised neural networks
https://www.cs.toronto.edu/~hinton/csc2535/readings/ws.pdf[5] Vicreg: Varianceinvariance-covariance regularization for self-supervised learning.
https://arxiv.org/abs/2105.04906[6] Bootstrap your own latent: A new approach to self-supervised learning
https://arxiv.org/abs/2006.07733[7] Emerging Properties in Self-Supervised Vision Transformers
https://arxiv.org/abs/2104.14294[8] Masked Autoencoders Are Scalable Vision Learners
https://arxiv.org/abs/2111.06377[9] HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units
https://arxiv.org/abs/2106.07447[10] Perceiver: General Perception with Iterative Attention
https://arxiv.org/abs/2103.03206[11] Experience Grounds Language
https://arxiv.org/abs/2004.10151

边栏推荐
- How to process the current cell with a custom formula in conditional format- How to address the current cell in conditional format custom formula?
- What functions need to be set after the mall system is built
- Priv app permission exception
- The latest activation free version of Omni toolbox
- [fairseq] error: typeerror:_ broadcast_ coalesced(): incompatible function arguments
- [set theory] set identities (idempotent law | exchange law | combination law | distribution rate | De Morgan law | absorption rate | zero law | identity | exclusion law | contradiction law | complemen
- Prefix and (continuously updated)
- FuncS sh file not found when using the benchmarksql tool to test kingbases
- Competitive product analysis and writing
- Ffmpeg tanscoding transcoding
猜你喜欢
vulnhub HA: Natraj

2022 t elevator repair simulation examination question bank and t elevator repair simulation examination question bank

When using the benchmarksql tool to test the concurrency of kingbasees, there are sub threads that are not closed in time after the main process is killed successfully
![[dynamic programming] subsequence problem](/img/d8/020ae959ef53ce097d3a81a0d2d63a.jpg)
[dynamic programming] subsequence problem
![[nlp] - brief introduction to the latest work of spark neural network](/img/65/35ae0137f4030bdb2b0ab9acd85e16.png)
[nlp] - brief introduction to the latest work of spark neural network

跨境电商多商户系统怎么选

FISCO bcos zero knowledge proof Fiat Shamir instance source code
Arthas watch grabs a field / attribute of the input parameter
GFS分布式文件系统(光是遇见已经很美好了)

Joint search set: the number of points in connected blocks (the number of points in a set)
随机推荐
Human resource management system based on JSP
Kingbasees plug-in KDB of Jincang database_ database_ link
[set theory] binary relationship (special relationship type | empty relationship | identity relationship | global relationship | divisive relationship | size relationship)
Which Bluetooth headset is cost-effective? Four Bluetooth headsets with high cost performance are recommended
2022-02-12 (338. Bit count)
Bugku CTF daily question baby_ flag. txt
[Thesis Writing] how to write the overall design of JSP tourism network
How to choose cross-border e-commerce multi merchant system
[set theory] set identities (idempotent law | exchange law | combination law | distribution rate | De Morgan law | absorption rate | zero law | identity | exclusion law | contradiction law | complemen
MySQL field userid comma separated save by userid query
MC Layer Target
一名外包仔的2022年中总结
arthas watch 抓取入参的某个字段/属性
[pat (basic level) practice] - [simple simulation] 1063 calculate the spectral radius
IPhone x forgot the boot password
MongoDB 慢查询语句优化分析策略
[NLP]—sparse neural network最新工作简述
Preliminary cognition of C language pointer
Daily question - ugly number
JS realizes lazy loading of pictures