当前位置:网站首页>[NLP]—sparse neural network最新工作简述
[NLP]—sparse neural network最新工作简述
2022-07-03 04:06:00 【Muasci】
前言
ICLR 2019 best paper《THE LOTTERY TICKET HYPOTHESIS: FINDING SPARSE, TRAINABLE NEURAL NETWORKS》提出了彩票假设(lottery ticket hypothesis):“dense, randomly-initialized, feed-forward networks contain subnetworks (winning tickets) that—when trained in isolationreach test accuracy comparable to the original network in a similar number of iterations.”
而笔者在[文献阅读] Sparsity in Deep Learning: Pruning and growth for efficient inference and training in NN也(稀烂地)记录了这方面的工作。
本文打算进一步简述这方面最新的工作。另外,按照“when to sparsify”,这方面工作可被分为:Sparsify after training、Sparsify during training、Sparse training,而笔者更为关注后两者(因为是end2end的),所以本文(可能)会更加关注这两个子类别的工作。
《THE LOTTERY TICKET HYPOTHESIS: FINDING SPARSE, TRAINABLE NEURAL NETWORKS》ICLR 19

步骤:
- 初始化完全连接的神经网络θ,并确定裁剪率p
- 训练一定步数,得到θ1
- 从θ1中根据参数权重的数量级大小,裁剪掉p的数量级小的权重,并将剩下的权重重置成原来的初始化权重
- 继续训练
代码:
- tf:https://github.com/google-research/lottery-ticket-hypothesis
- pt:https://github.com/rahulvigneswaran/Lottery-Ticket-Hypothesis-in-Pytorch
《Rigging the Lottery: Making All Tickets Winners》ICML 20

步骤:
- 初始化神经网络,并预先进行裁剪。预先裁剪的方式考虑:
- uniform:每一层的稀疏率相同;
- 其它方式:层中参数越多,稀疏程度越高,使得不同层剩下的参数量总体均衡;
- 在训练过程中,每ΔT步,更新稀疏参数的分布。考虑drop和grow两种更新操作:
- drop:裁剪掉一定比例的数量级小的权重
- grow:从被裁剪的权重中,恢复相同比例梯度数量级大的权重
- drop\grow比例的变化策略:
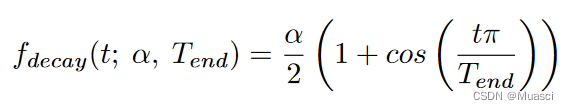
其中,α是初始的更新比例,一般设为0.3。
特点:
- 端到端
- 支持grow
代码:
- tf:https://github.com/google-research/rigl
- pt:https://github.com/varun19299/rigl-reproducibility
《Do We Actually Need Dense Over-Parameterization? In-Time Over-Parameterization in Sparse Training》ICML 21
提出了In-Time Over-Parameterization指标: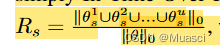
认为,在可靠的探索的前提下,上述指标越高,也就是模型在训练过程中探索了更多的参数,最终的性能越好。
所以训练步骤应该和《Rigging the Lottery: Making All Tickets Winners》类似,不过具体使用的Sparse Evolutionary Training (SET)——《A. Scalable training of artificial neural networks with adaptive sparse connectivity inspired by network science》,它的grow是随机的。这样选择是因为:
SET activates new weights in a random fashion which naturally considers all possible parameters to explore. It also helps to avoid the dense over-parameterization bias introduced by the gradient-based methods e.g., The Rigged Lottery (RigL) (Evci et al., 2020a) and Sparse Networks from Scratch (SNFS) (Dettmers & Zettlemoyer, 2019), as the latter utilize dense gradients in the backward pass to explore new weights
特点:
- 探索度
代码:https://github.com/Shiweiliuiiiiiii/In-Time-Over-Parameterization
《EFFECTIVE MODEL SPARSIFICATION BY SCHEDULED GROW-AND-PRUNE METHODS》ICLR 2022
做法:
CYCLIC GAP:

- 把模型分成k份,每一份(?)都按照r的比例随机稀疏化。
- 初始时,把其中一份变为稠密
- 持续k步,步间隔为T个epoch。每一步将稠密的那一份稀疏化(magnitude-based),把那一份的下一份变为稠密。
- k步以后,将剩下的那一份稠密的稀疏化,然后微调。
PARALLEL GAP:k份,k节点,每一份在不同节点上都是稠密的。
特点:
- 扩大了探索空间
- 做了wmt14 de-en translation的实验
代码:https://github.com/Shiweiliuiiiiiii/In-Time-Over-Parameterization
《Learning to Win Lottery Tickets in BERT Transfer via Task-agnostic Mask Training》 NAACL 2022
做法:
特点:
- mask可训练,而非magnitude-based
- Task-Agnostic Mask Training(接下来不妨看看task-specific的?)
代码:https://github.com/llyx97/TAMT
《How fine can fine-tuning be? Learning efficient language models》AISTATS 2020
方法:
- L0-close fine-tuning:通过预实验,发现某些层、某些模块,在下游任务上finetune之后,其参数和原先的预训练参数差别不大,于是将其排除在本文提出的这种finetune过程中
- Sparsification as fine-tuning:为每一个task训练一个0\1mask
特点:
- 训练mask,来达到finetune pretrained model的效果
代码:无
但是有https://github.com/llyx97/TAMT这里面也有关于mask-training的代码,可以参考?
边栏推荐
- JS实现图片懒加载
- Causal AI, a new paradigm for industrial upgrading of the next generation of credible AI?
- 树莓派如何连接WiFi
- golang xxx. Go code template
- Is it better to speculate in the short term or the medium and long term? Comparative analysis of differences
- MySQL timestampdiff interval
- CVPR 2022 | 大连理工提出自校准照明框架,用于现实场景的微光图像增强
- CVPR 2022 | Dalian Institute of technology proposes a self calibration lighting framework for low light level image enhancement of real scenes
- [brush questions] find the number pair distance with the smallest K
- Half of 2022 is over, so we must hurry up
猜你喜欢

深潜Kotlin协程(十九):Flow 概述

IPv6 transition technology-6to4 manual tunnel configuration experiment -- Kuige of Shangwen network

Bisher - based on SSM pet adoption center
Deep dive kotlin synergy (19): flow overview

『期末复习』16/32位微处理器(8086)基本寄存器

The time has come for the domestic PC system to complete the closed loop and replace the American software and hardware system

第十届中国云计算大会·中国站:展望未来十年科技走向
![[brush questions] connected with rainwater (one dimension)](/img/21/318fcb444b17be887562f4a9c1fac2.png)
[brush questions] connected with rainwater (one dimension)

Appium automated testing framework
Basic MySQL operations
随机推荐
Causal AI, a new paradigm for industrial upgrading of the next generation of credible AI?
MySQL create table
In Net 6 project using startup cs
Without sxid, suid & sgid will be in danger- Shangwen network xUP Nange
golang xxx. Go code template
QSAR model establishment script based on pytoch and rdkit
Taking two column waterfall flow as an example, how should we build an array of each column
C language hashtable/hashset library summary
记一次 .NET 差旅管理后台 CPU 爆高分析
Wechat applet + Alibaba IOT platform + Hezhou air724ug built with server version system analysis
Ffmpeg download and installation tutorial and introduction
Introduction to eth
2022 tea master (primary) examination questions and tea master (primary) examination question bank
[Apple Photo Album push] IMessage group anchor local push
What can learning pytorch do?
Error c2694 "void logger:: log (nvinfer1:: ilogger:: severity, const char *)": rewrite the restrictive exception specification of virtual functions than base class virtual member functions
【刷题篇】接雨水(一维)
Interface embedded in golang struct
国产PC系统完成闭环,替代美国软硬件体系的时刻已经到来
Dynamic programming: Longest palindrome substring and subsequence