当前位置:网站首页>【吴恩达笔记】机器学习基础
【吴恩达笔记】机器学习基础
2022-06-24 19:25:00 【zzu菜】
机器学习基础
什么是机器学习?
一个程序被认为能从经验E中学习,解决任务T,达到性能度量值P,当且仅当,有了经验E后,经过P评判,程序在处理T时的性能有所提升。
我认为经验E 就是程序上万次的自我练习的经验而任务T 就是下棋。性能度量值P呢,就是它在与一些新的对手比赛时,赢得比赛的概率。
Supervised Learning有监督学习

有监督学习:数据集中不仅仅有特征feature-X,还有标签target-Y
我们以后会讲一个算法,叫支持向量机,里面有一个巧妙的数学技巧,能让计算机处理无限多个特征。
Unsupervised Learning无监督学习

无监督学习:数据集中仅仅有特征feature
聚类算法:分离不同距离的音频,区分邮箱是否为垃圾邮箱等等
[W,s,v] = svd((repmat(sum(x.*x,1),size(x,1),1).*x)*x');
自监督学习
解释一: 自监督学习让我们能够没有大规模标注数据也能获得优质的表征,反而我们可以使用大量的未标注数据并且优化预定义的 pretext 任务。然后我们可以使用这些特性来学习缺乏数据的新任务。
解释二: self-supervised learning 是无监督学习里面的一种,主要是希望能够学习到一种通用的特征表达用于下游任务。其主要的方式就是通过自己监督自己,比如把一段话里面的几个单词去掉,用他的上下文去预测缺失的单词,或者将图片的一些部分去掉,依赖其周围的信息去预测缺失的 patch。
作用:
从无标签数据中学习到有用的信息, 以用于后续任务.
自监督任务(也称为 pretext 任务)要求我们考虑监督损失函数。然而,我们通常不关心该任务最终的性能。实际上,我们只对学习到的中间表征感兴趣,我们期望这些表征可以涵盖良好的语义或结构上的意义,并且能够有益于各种下游的实际任务。
Linear Regression with One Variable单一变量的线性回归
单变量线性回归:
- 一种可能的表达方式为: h θ ( x ) = θ 0 + θ 1 x h_\theta \left( x \right)=\theta_{0} + \theta_{1}x hθ(x)=θ0+θ1x,因为只含有一个特征/输入变量,因此这样的问题叫作单变量线性回归问题。
售卖房子:已经知道之前售卖的价格,根据之前的数据集预测自己朋友房子可以出售的价格。
Training Set(训练集)如下:

m m m 代表训练集中实例的数量
x x x 代表特征/输入变量
y y y 代表目标变量/输出变量
( x , y ) \left( x,y \right) (x,y) 代表训练集中的实例
( x ( i ) , y ( i ) ) ({ {x}^{(i)}},{ {y}^{(i)}}) (x(i),y(i)) 代表第 i i i 个观察实例

h h h 代表学习算法的解决方案或函数也称为假设(hypothesis)
Cost Function代价函数
代价函数也被称作平方误差函数,有时也被称为平方误差代价函数。我们之所以要求出误差的平方和,是因为误差平方代价函数,对于大多数问题,特别是回归问题,都是一个合理的选择。还有其他的代价函数也能很好地发挥作用,但是平方误差代价函数可能是解决回归问题最常用的手段了。
代价函数使得我们 h θ ( x ) = θ 0 + θ 1 x h_\theta \left( x \right)=\theta_{0} + \theta_{1}x hθ(x)=θ0+θ1x 更好的选择参数**parameters ** θ 0 θ 1 \theta_{0}\theta_{1} θ0θ1,以便最可能的直线和数据相互拟合。

我们的目标便是选择出可以使得建模误差的平方和能够最小的模型参数。
- 即使得代价函数 J ( θ 0 , θ 1 ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 J \left( \theta_0, \theta_1 \right) = \frac{1}{2m}\sum\limits_{i=1}^m \left( h_{\theta}(x^{(i)})-y^{(i)} \right)^{2} J(θ0,θ1)=2m1i=1∑m(hθ(x(i))−y(i))2最小。
θ 0 \theta_{0} θ0和 θ 1 \theta_{1} θ1 和 J ( θ 0 , θ 1 ) J(\theta_{0}, \theta_{1}) J(θ0,θ1)关系的可视化

目前求得全局最小的代价函数,进行简化 θ 0 = 0 \theta_{0}=0 θ0=0

对 θ 1 \theta_{1} θ1不断进行赋值求解得对应的 J ( θ 1 ) J(\theta_{1}) J(θ1),得到 J ( θ 1 ) J(\theta_{1}) J(θ1)和 θ 1 \theta_{1} θ1关系

等高线图:对应的 θ 0 = 360 \theta_{0}=360 θ0=360, θ 1 = 0 \theta_{1}=0 θ1=0,对应在等高线图中的位置

Gradient Descent梯度下降
梯度下降:用来求解代价函数 J ( θ 0 , θ 1 ) J(\theta_{0}, \theta_{1}) J(θ0,θ1)最小值时的 θ 0 \theta_{0} θ0, θ 1 \theta_{1} θ1
梯度下降背后的思想是:开始时我们随机选择一个参数的组合 ( θ 0 , θ 1 , . . . . . . , θ n ) \left( {\theta_{0}},{\theta_{1}},......,{\theta_{n}} \right) (θ0,θ1,......,θn),计算代价函数,然后我们寻找下一个能让代价函数值下降最多的参数组合。我们持续这么做直到找到一个局部最小值(local minimum),因为我们并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是全局最小值(global minimum),选择不同的初始参数组合,可能会找到不同的局部最小值。

梯度下降算法

- a a a是学习率(learning rate),它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大,在批量梯度下降中,我们每一次都同时让所有的参数减去学习速率乘以代价函数的导数。

- 右边是正确的,全部值算出之后在赋值,左边是错误的
梯度下降算法如下:
θ j : = θ j − α ∂ ∂ θ j J ( θ ) {\theta_{j}}:={\theta_{j}}-\alpha \frac{\partial }{\partial {\theta_{j}}}J\left(\theta \right) θj:=θj−α∂θj∂J(θ)
描述:对$\theta 赋 值 , 使 得 赋值,使得 赋值,使得J\left( \theta \right) 按 梯 度 下 降 最 快 方 向 进 行 , 一 直 迭 代 下 去 , 最 终 得 到 局 部 最 小 值 。 其 中 按梯度下降最快方向进行,一直迭代下去,最终得到局部最小值。其中 按梯度下降最快方向进行,一直迭代下去,最终得到局部最小值。其中a$是学习率(learning rate),它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大。

如果只考虑 θ 1 \theta_{1} θ1, θ 0 = 0 \theta_{0}=0 θ0=0时, α ∂ ∂ θ 1 J ( θ ) \alpha \frac{\partial }{\partial {\theta_{1}}}J\left(\theta \right) α∂θ1∂J(θ),前面是学习率,后面是代价函数 J ( θ ) J\left( \theta \right) J(θ)关于 θ 1 \theta_{1} θ1的导数。
代价函数 J ( θ 1 ) J\left( \theta_{1} \right) J(θ1)和 θ 1 \theta_{1} θ1的图像,
如果学习率太小,会迭代较多的次数
如果学习率过大,可能会跨过局部最小值,来回震荡偏离局部最小值点。
将梯度下降和代价函数结合,并将其应用于具体的拟合直线的线性回归算法里。
梯度下降算法和线性回归算法如下图:

对我们之前的线性回归问题运用梯度下降法,关键在于求出代价函数的导数,即:
∂ ∂ θ j J ( θ 0 , θ 1 ) = ∂ ∂ θ j 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 \frac{\partial }{\partial { {\theta }_{j}}}J({ {\theta }_{0}},{ {\theta }_{1}})=\frac{\partial }{\partial { {\theta }_{j}}}\frac{1}{2m}{ {\sum\limits_{i=1}^{m}{\left( { {h}_{\theta }}({ {x}^{(i)}})-{ {y}^{(i)}} \right)}}^{2}} ∂θj∂J(θ0,θ1)=∂θj∂2m1i=1∑m(hθ(x(i))−y(i))2
j = 0 j=0 j=0 时: ∂ ∂ θ 0 J ( θ 0 , θ 1 ) = 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) \frac{\partial }{\partial { {\theta }_{0}}}J({ {\theta }_{0}},{ {\theta }_{1}})=\frac{1}{m}{ {\sum\limits_{i=1}^{m}{\left( { {h}_{\theta }}({ {x}^{(i)}})-{ {y}^{(i)}} \right)}}} ∂θ0∂J(θ0,θ1)=m1i=1∑m(hθ(x(i))−y(i))
j = 1 j=1 j=1 时: ∂ ∂ θ 1 J ( θ 0 , θ 1 ) = 1 m ∑ i = 1 m ( ( h θ ( x ( i ) ) − y ( i ) ) ⋅ x ( i ) ) \frac{\partial }{\partial { {\theta }_{1}}}J({ {\theta }_{0}},{ {\theta }_{1}})=\frac{1}{m}\sum\limits_{i=1}^{m}{\left( \left( { {h}_{\theta }}({ {x}^{(i)}})-{ {y}^{(i)}} \right)\cdot { {x}^{(i)}} \right)} ∂θ1∂J(θ0,θ1)=m1i=1∑m((hθ(x(i))−y(i))⋅x(i))
则算法改写成:
Repeat {
θ 0 : = θ 0 − a 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) {\theta_{0}}:={\theta_{0}}-a\frac{1}{m}\sum\limits_{i=1}^{m}{ \left({ {h}_{\theta }}({ {x}^{(i)}})-{ {y}^{(i)}} \right)} θ0:=θ0−am1i=1∑m(hθ(x(i))−y(i))
θ 1 : = θ 1 − a 1 m ∑ i = 1 m ( ( h θ ( x ( i ) ) − y ( i ) ) ⋅ x ( i ) ) {\theta_{1}}:={\theta_{1}}-a\frac{1}{m}\sum\limits_{i=1}^{m}{\left( \left({ {h}_{\theta }}({ {x}^{(i)}})-{ {y}^{(i)}} \right)\cdot { {x}^{(i)}} \right)} θ1:=θ1−am1i=1∑m((hθ(x(i))−y(i))⋅x(i))
**}
推导过程参考https://zhuanlan.zhihu.com/p/328261042

批量梯度下降,每次梯度下降都会使用到所有的训练集
总结
1. 假设函数(Hypothesis)
用一线性函数拟合样本数据集,可以简单定义为如下:

其中
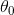
和

为参数。
2. 代价函数(Cost Function)
衡量一个假设函数的“损失”,又称作“平方和误差函数”(Square Error Function),给出如下定义:

相当于,对所有样本的假设值与真实值之差的平方再求总和,再除以样本数量m,得到平均的“损失”。我们的任务是求出
和
使得这个“损失”最小。
3. 梯度下降(Gradient Descent)
梯度:某一函数在该点处的方向导数沿该方向取得最大值,即在该点变化率(斜率)最大。
梯度下降:使得自变量

沿着使

下降最快的方向移动,尽快取得
的最小值,给出如下定义:

吴恩达的课程中我了解到,梯度下降是需要所有自变量同时“下降”的,所以,我们可以转化为分别对

和

求偏导数,即固定
将
作为变量进行求导,反之对
一样。
我们了解代价函数是

,其中
,那么,我们根据复合函数的求导原则,dx/dy=(*du/dy)*∗(dx/du),即转化为:

最后得到课程中的结果:


边栏推荐
- OSI and tcp/ip model
- Logical backup: mysqldump vs physical backup: xtrabackup
- Rewrite, maplocal and maplocal operations of Charles
- Tso hardware sharding is a header copy problem
- Unity关于本地坐标和世界坐标之间的转换
- Wireshark packet capturing skills summarized by myself
- leetcode_1365
- socket(2)
- XTransfer技术新人进阶秘诀:不可错过的宝藏Mentor
- Alibaba cloud lightweight servers open designated ports
猜你喜欢

Advanced secret of xtransfer technology newcomers: the treasure you can't miss mentor

Blender's simple skills - array, rotation, array and curve

Memcached comprehensive analysis – 5 Memcached applications and compatible programs

Tdengine can read and write through dataX

Pattern recognition - 1 Bayesian decision theory_ P1

Transport layer UDP & TCP

Fuzhou business office of Fujian development and Reform Commission visited the health department of Yurun university to guide and inspect the work

VSCode无网环境快速迁移开发环境(VIP典藏版)

Bld3 getting started UI

(待补充)GAMES101作业7提高-实现微表面模型你需要了解的知识
随机推荐
Analysis of tcpdump packet capturing kernel code
Role of wait function
Golang reflection operation collation
Dynamic routing protocol rip, OSPF
Visit Amazon memorydb and build your own redis memory database
Three more days
Blender's simple skills - array, rotation, array and curve
About transform InverseTransformPoint, transform. InverseTransofrmDirection
VSCode无网环境快速迁移开发环境(VIP典藏版)
A field in the database is of JSON type and stores ["1", "2", "3"]
memcached全面剖析–2. 理解memcached的內存存儲
Unity关于本地坐标和世界坐标之间的转换
Address mapping of virtual memory paging mechanism
Functional analysis of ebpf sockops
Analysis of BBR congestion control state machine
Implementing DNS requester with C language
Foundations of Cryptography
123. the best time to buy and sell shares III
Station B takes goods to learn from New Oriental
HCIA assessment