当前位置:网站首页>小红书自研KV存储架构如何实现万亿量级存储与跨云多活
小红书自研KV存储架构如何实现万亿量级存储与跨云多活
2022-07-05 10:25:00 【InfoQ】

- Redis集群主要适用于缓存场景,开启AOF数据实时落盘对性能有比较大的影响,同时每个节点需要额外挂载云盘用于存储AOF。在集群节点和存储容量受限的情况下,单节点的数据量设置过大会导致故障后节点数据的failover时间太长,单节点数据量设置小会导致gossip协议在稳定性高要求下节点个数受限,同时考虑突发流量的压力,Redis集群在部署上需要做一些空间预留,带来成本高的问题。
- HBase作为一款生态完善的NoSQL存储系统,在高QPS下也产生了诸多的性能和稳定性问题,如:Zookeeper压力大时稳定性难以保障(节点探活,服务注册等都依赖 Zookeeper);HBase的数据文件和WAL日志文件直接写HDFS,节点故障后,重放HDFS上的WAL速度慢;Java GC会导致Zookeeper误杀RegionServer,同时产生毛刺;Major Compaction 会导致I/O飙升,产生长尾效应;受限HDFS的复杂性,黑盒运维对工程师来说比较困难;在小红书的业务实战中,百万QPS下HBase延时不太理想,核心数据用大内存机型兜住,也引发成本高的问题。

2.1. 高QPS和低延时读取特性
- 写入带宽达到数十GB/s,要求实时写入性能和读取性能都很高。
- 数据量很大,要求读取时延低。可以接受故障场景下少量数据丢失。
- 模型数据存储服务。记录过去一段时间用户训练模型数据,对P99时延要求非常高,数据量在几十TB。
- 去重存储服务。数据量在几十TB,P99<10ms, P999<20ms。
- 风控数据存储服务。QPS目前达到千万级别,P999 < 30ms。
2.2. 低成本的缓存特性
- 兼容Redis协议,性能比Redis慢一些,但资源成本降低50%+。
- 广告的关键词存储和反作弊业务,解决大数据量、低QPS的存储模型。
2.3. NoSQL存储特性
- 支持数据多版本,列存行取等特性,比HBase成本减少30%+,P99时延提升6倍。
- 支持KKV级别的TTL。
- 强一致:目前RedKV1.0采用的主从双副本,数据写入成功,可以通过配置同步模式来保障2副本写成功,读主写主保障强一致。对于写性能要求高的场景,可以打开异步写,写主成功则返回,依赖增量同步从节点数据。
- 风控服务。实时查询对P999要求极高,千万QPS下HBase已经不能满足性能需求,时延抖动比较大。
- 画像存储服务。数据的维度多,字段读取的业务方多,对时延要求敏感。

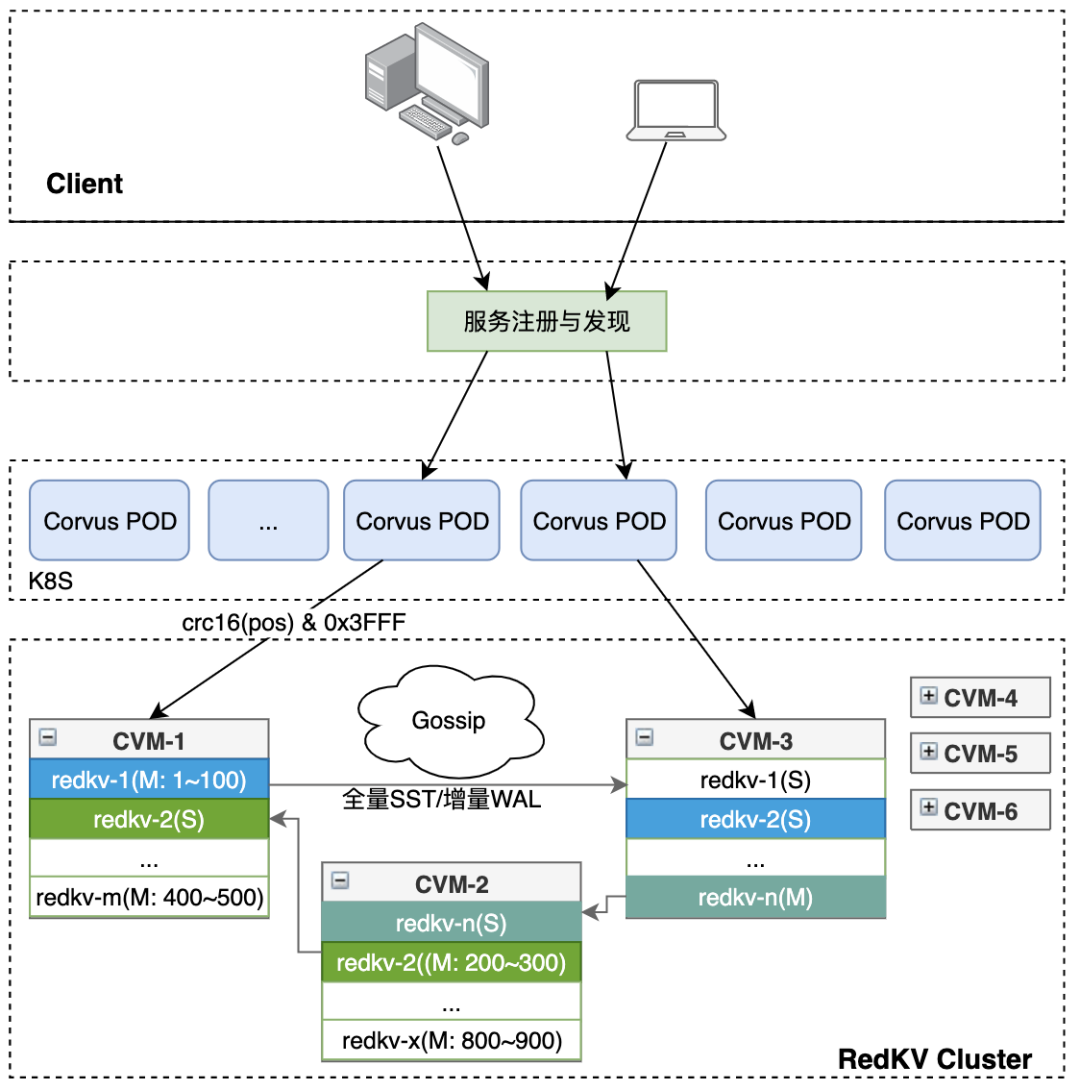
3.1. Client接入层
3.2. Proxy
- Proxy限流
- 数据在线压缩
- 线程模型优化
- backup-read优化长尾
- 大key检测
3.2.1. Proxy限流
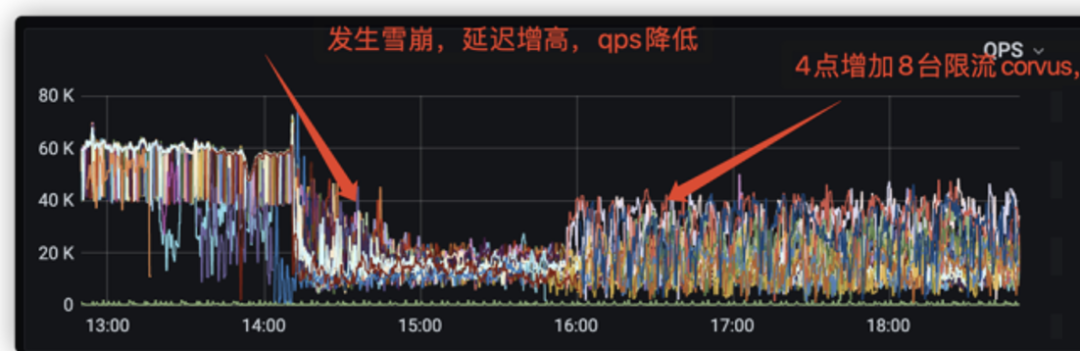
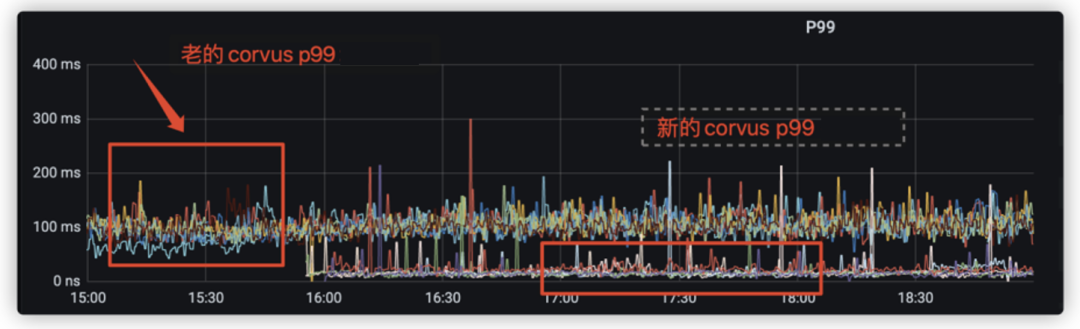
3.2.2. 数据在线压缩
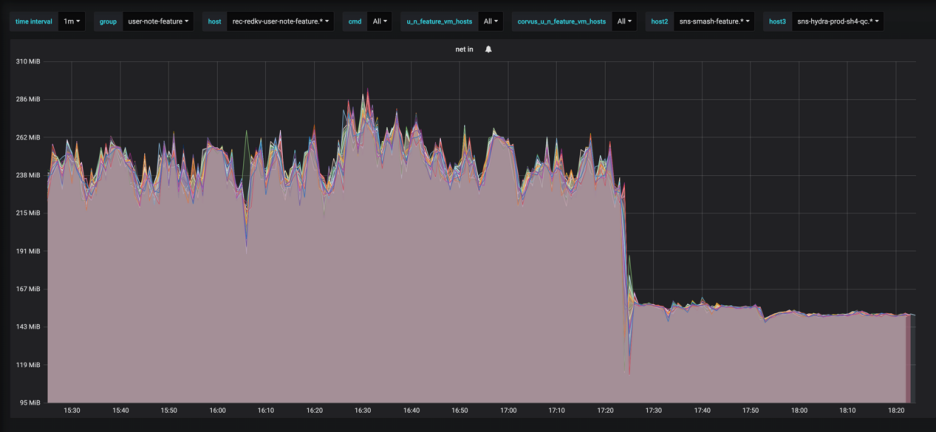
3.2.3. 线程模型的优化
3.2.4. backup-read优化长尾
- 检查节点的状态和过去的延时
- 选择2个节点中状态好的那个节点发送请求
- 计算P99时延,超过P95时延则向另外一个节点发送一定数目的backup read请求数
- 两个请求中任意一个请求返回成功则成功,如果超时则继续重试
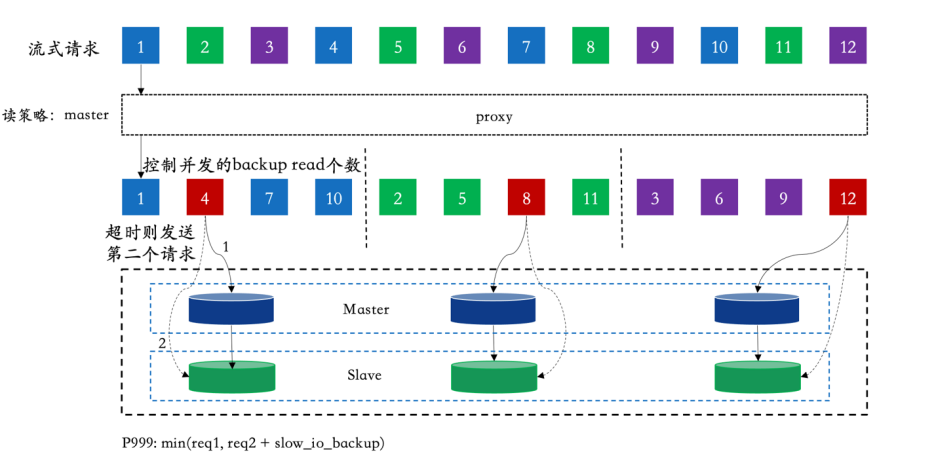
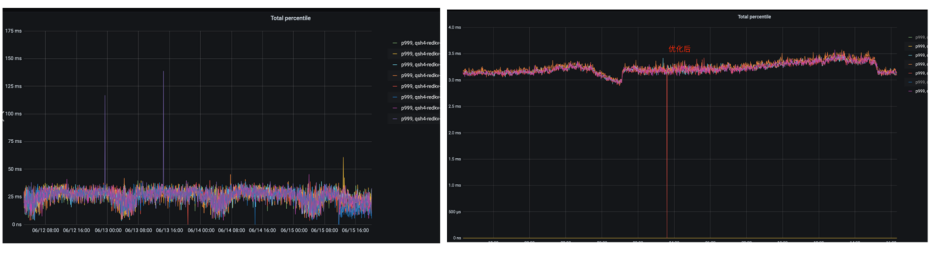
3.2.5. 大Key检测
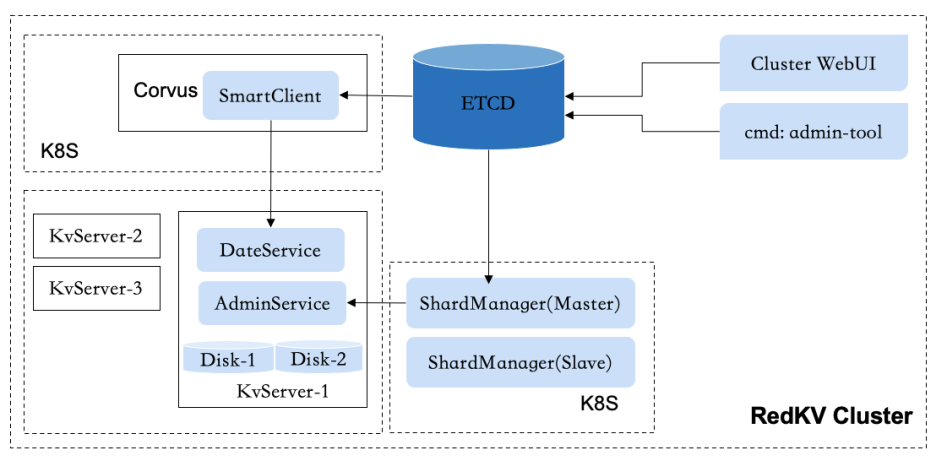
3.3. RedKV Cluster
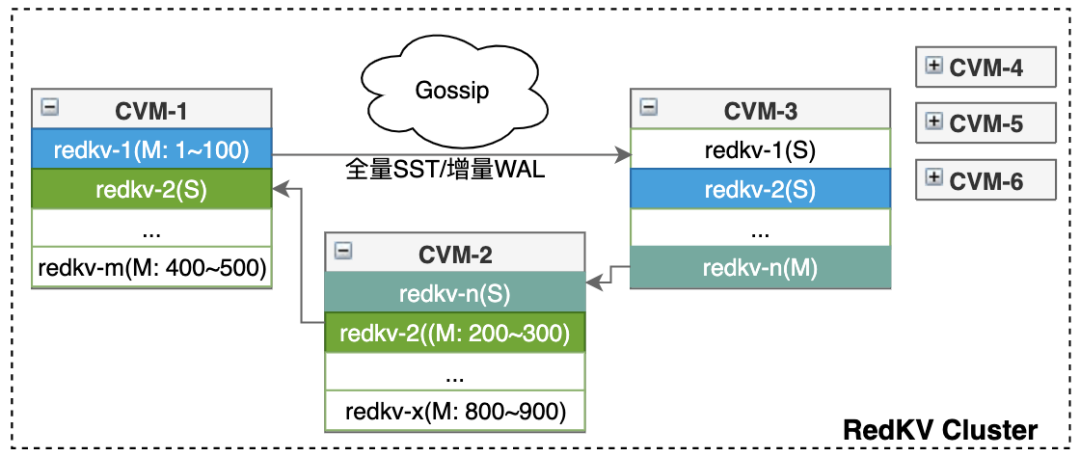
3.3.1. Gossip优化
- 探测时间优化:Redis Gossip协议正常情况下会每隔100ms随机选取一个节点发送ping包,并更新节点的ping_sent值为发送ping包时间。如果集群很大,节点数很多,那么故障节点被ping到的概率就会变小,最多超过node_timeout/2时间给故障节点发送ping包。这样就会导致节点发生故障时,集群中正常节点不能第一时间ping到故障节点,从而无法立刻感知到故障节点发生了故障。为了减少这部分时间,当集群中有节点超过2s没有收到故障节点发送的pong报文时,就立马通知其他节点去ping故障节点。这样可以把节点故障到正常节点给故障节点发送ping的时间控制在2s左右。
- 判定PFAIL时间优化:Gossip 协议现有实现方式是超过node_timeout(通常为15s)时间没有收到pong报文,就将节点状态置为pfail。本次优化将这个时间设置为3s(可配置),如果24小时内(可配置)首次超过3s没有收到pong报文,就将节点置为pfail状态。如果24小时内频繁出现,那可能是网络抖动造成,还走原来的路径等待node_timeout。
- 减少PFAIL到FAIL的判定时间:只有一个节点收到集群1/2的节点的PFAIL信息的时候,才会将故障节点判定为FAIL状态。而PFAIL这个信息是通过Gossip协议交互的,最久需要1/2 node_timeout才会通知到其他节点。因此为了加速PFAIL到FAIL的状态,所有的节点按照统一的规则选出一个种子节点,PFAIL信息除了随机发送一个节点意外,还会通知这个种子节点。这样种子节点能在最快的时间学习到集群所有节点的PFAIL信息,从而将故障节点标记为FAIL状态广播到集群。
3.3.2. RedKV Server
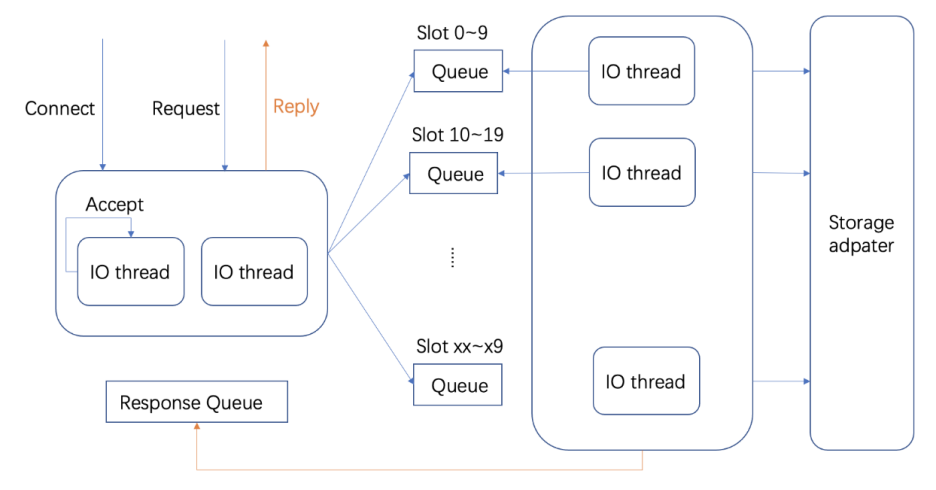
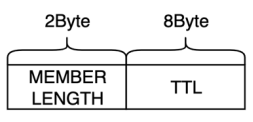
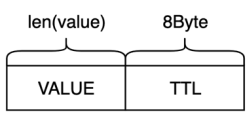
3.3.3. 数据存储



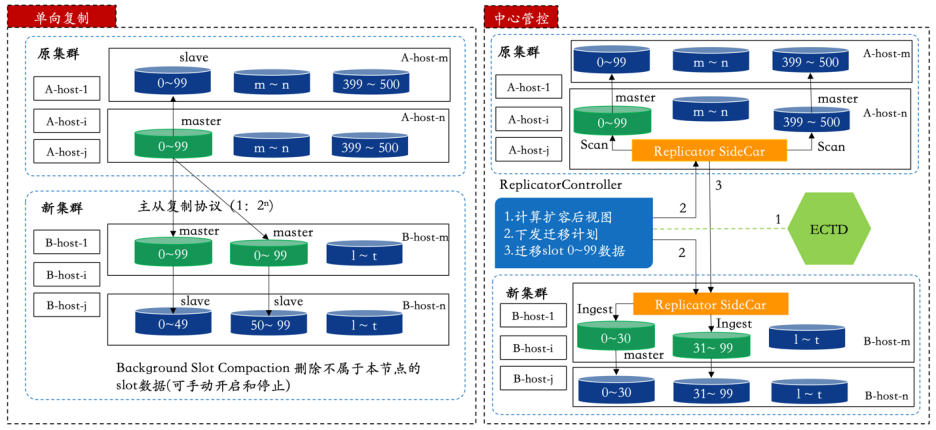
4.1. 数据复制
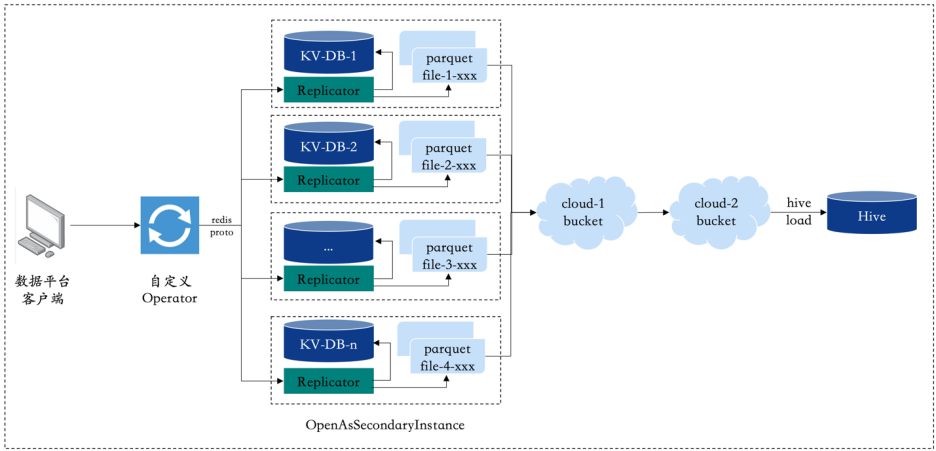
4.2. 数据批量导入
- 批量导入:如小红书的笔记数据,一般需要小时级别甚至天级别的更新,所以业务需要有快捷的批量导入功能。
- 快速更新:特征数据的特点就是数据量特别大,以笔记为例,全量笔记在TB 级别数据量。如果通过 Jedis SDK 写入,那么存储集群需要支持百万QPS的机器资源。当下小红书数据平台支持业务把数据从hive通过工作流直接导入RedKV,一般是每天凌晨开始写数据,等到晚高峰时大量读取。这种方法实践下来,经常导致 RedKV集群的集群内存OOM,影响稳定性。
- 性能及稳定:数据在导入的过程中不能影响读的性能
- 自定义获取集群视图和数据编码的UDTF,支持RedKV1.0的数据格式
- 将原先的抽数据,编码,分片和排序整合成一个HiveOperator,执行完成后按指定的OutputFormat输出SST文件到一个指定S3目录
- 通过Hadoop distcp工具做数据的跨云传输,走离线带宽不影响线上的读写业务
- RedKV集群的节点SiderCar作为对象存储的一个Client,RedKV节点加载本节点的SST并ingest

4.3. 数据批量导出
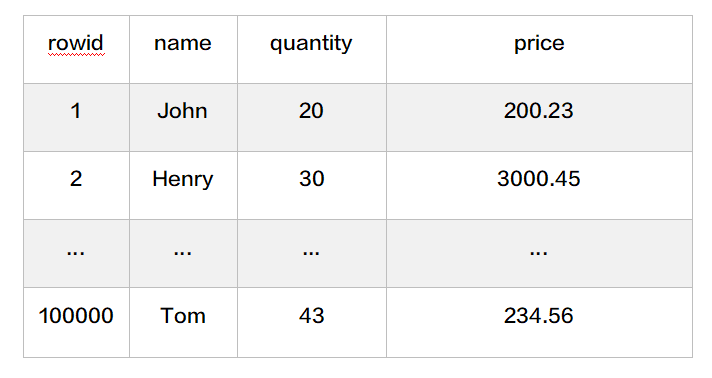
hmset {person}_1 name John quantity 20 price 200.23
hmset {person}_2 name Henry quantity 30 price 3000.45hmset {person:1}_1 name John quantity 20 price 200.23
hmset {person:1}_2 name Henry quantity 30 price 3000.45
...
hmset {person:16}_100000 name Tom quantity 43 price 234.564.4. 数据的备份和恢复
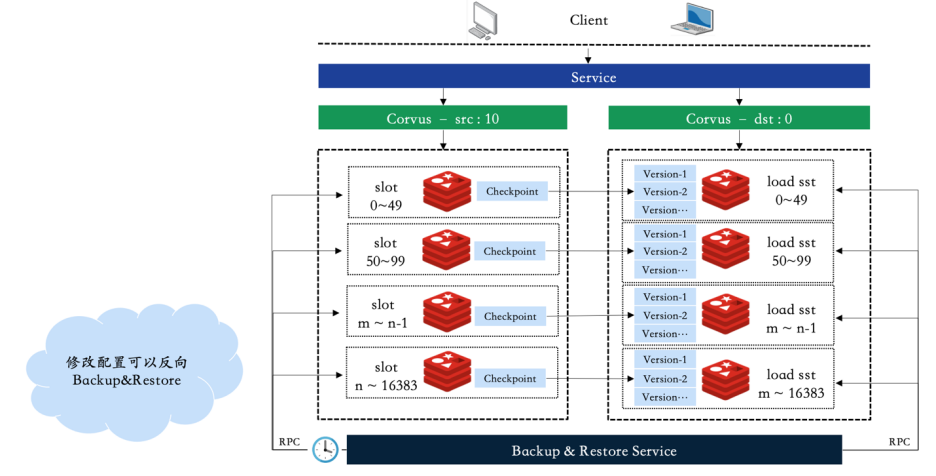
- 基于LSM结构的KV系统,数据compaction导致的空间放大会翻倍,数据量大后,数据备份需要大容量的磁盘
- 单集群故障后,集群恢复的时间不可控
- 备份数据依赖第三方系统
- 广告系统对数据的及时恢复能力有比较高的要求,通常要求在分钟级。为了解决上述几个问题,我们提出了一种中心管控的主备集群容灾策略,通过Proxy接入层的秒级切换能快速切流到一个特定的版本
- 先部署一个容灾集群,主集群对外提供读写服务,灾备集群保存特定数量的快照数据
- 低峰期,中心管控根据配置的版本数和任务时间会定时的向主集群发送打快照的服务
- 快照完成后通过发生远程rsync命令将快照目录传送到容灾集群,主集群低峰期数据压缩后数据量可控,这样灾备集群可以备份指定数量的版本信息
- 故障发生后,中心管控可以在灾备集群通过RPC指令指定恢复到一个特定的版本
- Proxy接入层通过服务注册与发现主键配置2组服务,通过动态的秒级切换可以将流量打向特定版本的集群,完成服务访问的秒级切换
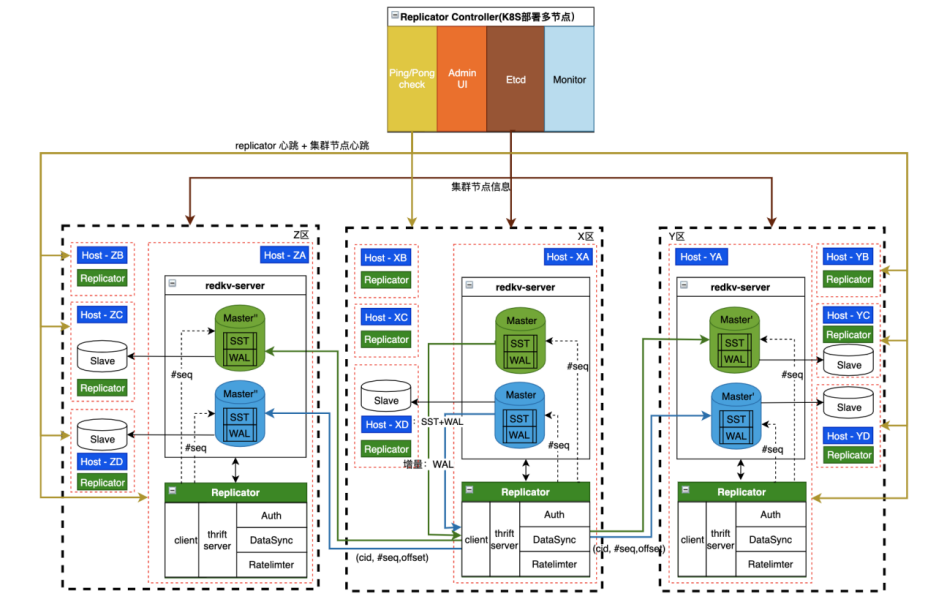
4.5. 跨云多活
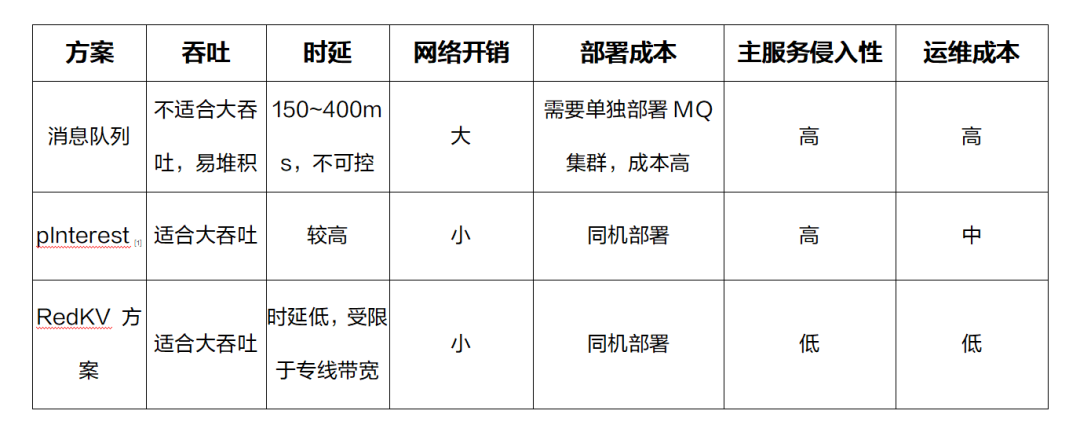
- 同机部署,网络开销小;
- Sidecar Service 对主服务侵入性小;
- 单独部署,易于升级

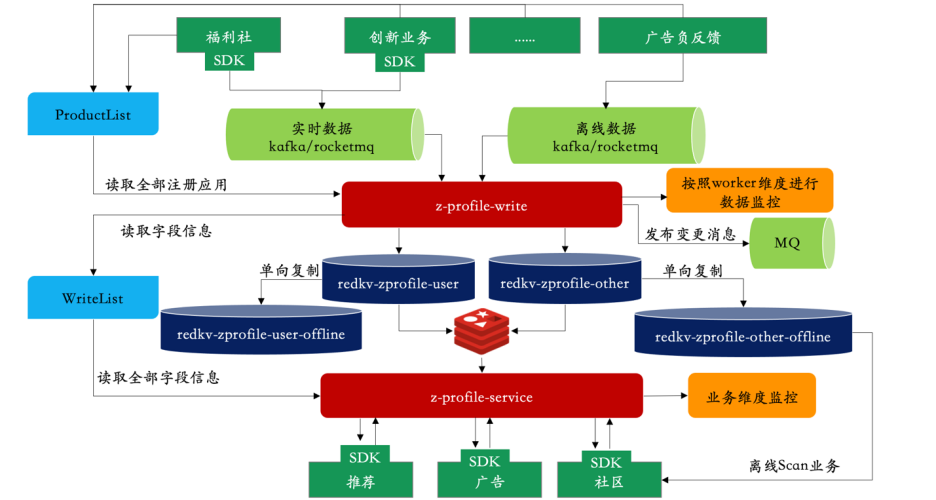
- zprofile-write service 对上游提供统一的数据写入接口服务,提供用户和比较的Meta管理,用户数据写入redkv-zprofile-user集群,笔记及其他数据写入redkv-zprofile-other集群。
- zprofile-service对下游提供统一的数据消费服务,对应时延要求不高的离线服务,RedKV本身支持单向数据复制的能力通过2个offline小集群提供数据scan业务。



- RedKV : 分布式高性能KV
- RedTao:满足一跳查询的高性能图存储数据库
- RedTable:提供Schema支持的表格存储
- RedGraph:提供两跳及以上的图语义查询数据库
边栏推荐
猜你喜欢
《天天数学》连载58:二月二十七日

pytorch输出tensor张量时有省略号的解决方案(将tensor完整输出)
5g NR system architecture
![[observation] with the rise of the](/img/9a/8bbf98e6aed80638f4340aacec2ea9.jpg)
[observation] with the rise of the "independent station" model of cross-border e-commerce, how to seize the next dividend explosion era?

2022鹏城杯web

爬虫(9) - Scrapy框架(1) | Scrapy 异步网络爬虫框架
5G NR系统架构
Learning II of workmanager

Idea create a new sprintboot project

2022年危险化学品生产单位安全生产管理人员特种作业证考试题库模拟考试平台操作
随机推荐
C#实现获取DevExpress中GridView表格进行过滤或排序后的数据
风控模型启用前的最后一道工序,80%的童鞋在这都踩坑
字符串、、
【JS】提取字符串中的分数,汇总后算出平均分,并与每个分数比较,输出
一个可以兼容各种数据库事务的使用范例
What is the most suitable book for programmers to engage in open source?
[observation] with the rise of the "independent station" model of cross-border e-commerce, how to seize the next dividend explosion era?
5G NR系统架构
Taro进阶
Activity jump encapsulation
微信核酸检测预约小程序系统毕业设计毕设(6)开题答辩PPT
SAP UI5 ObjectPageLayout 控件使用方法分享
The horizontally scrolling recycleview displays five and a half on one screen, lower than the average distribution of five
Learning note 4 -- Key Technologies of high-precision map (Part 2)
变量///
爬虫(9) - Scrapy框架(1) | Scrapy 异步网络爬虫框架
【JS】数组降维
C语言实现QQ聊天室小项目 [完整源码]
AtCoder Beginner Contest 258「ABCDEFG」
Universal double button or single button pop-up