当前位置:网站首页>双向RNN与堆叠的双向RNN
双向RNN与堆叠的双向RNN
2022-07-05 10:20:00 【别团等shy哥发育】
双向RNN与堆叠的双向RNN
1、双向RNN
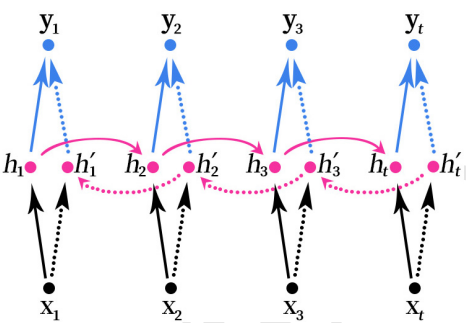
双向RNN(Bidirectional RNN)的结构如下图所示。
h t → = f ( W → x t + V → h t − 1 → + b → ) h t ← = f ( W ← x t + V ← h t − 1 ← + b ← ) y t = g ( U [ h t → ; h t ← ] + c ) \overrightarrow{h_t}=f(\overrightarrow{W}x_t+\overrightarrow{V}\overrightarrow{h_{t-1}}+\overrightarrow{b})\\ \overleftarrow{h_t}=f(\overleftarrow{W}x_t+\overleftarrow{V}\overleftarrow{h_{t-1}}+\overleftarrow{b})\\ y_t=g(U[\overrightarrow{h_t};\overleftarrow{h_t}]+c) ht=f(Wxt+Vht−1+b)ht=f(Wxt+Vht−1+b)yt=g(U[ht;ht]+c)
这里的 RNN 可以使用任意一种 RNN 结构 SimpleRNN,LSTM 或 GRU。这里箭头表示从左到右或从右到左传播,对于每个时刻的预测,都需要来自双向的特征向量,拼接 (Concatenate)后进行结果预测。箭头虽然不同,但参数还是同一套参数。有些模型中也 可以使用两套不同的参数。f,g表示激活函数, [ h t → ; h t ← ] [\overrightarrow{h_t};\overleftarrow{h_t}] [ht;ht]表示数据拼接(Concatenate)。
双向的 RNN 是同时考虑“过去”和“未来”的信息。上图是一个序列长度为 4 的双向RNN 结构。
比如输入 x 1 x_1 x1沿着实线箭头传输到隐层得到 h 1 h_1 h1,然后还需要再利用 x t x_t xt计算得到 h t ′ h_t' ht′,利用 x 3 x_3 x3和 h t ′ h_t' ht′计算得到 h 3 ′ h_3' h3′,利用 x 2 x_2 x2和 h 3 ′ h_3' h3′计算得到 h 2 ′ h_2' h2′,利用 x 1 x_1 x1和’h_2’计算得到 h 1 ′ h_1' h1′,最后再把 h 1 h_1 h1和 h 1 ′ h_1' h1′进行数据拼接(Concatenate),得到输出结果 y 1 y_1 y1。以此类推,同时利用前向传递和反向传递的数据进行结果的预测。
双向RNN就像是我们做阅读理解的时候从头向后读一遍文章,然后又从后往前读一遍文章,然后再做题。有可能从后往前再读一遍文章的时候会有新的不一样的理解,最后模型可能会得到更好的结果。
2、堆叠的双向RNN
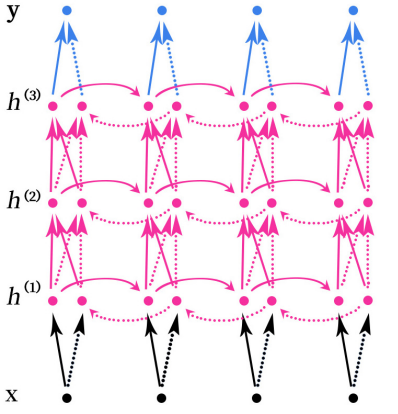
堆叠的双向RNN(Stacked Bidirectional RNN)的结构如上图所示。上图是一个堆叠了3个隐藏层的RNN网络。
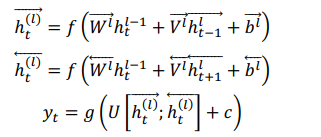
注意,这里的堆叠的双向RNN并不是只有双向的RNN才可以堆叠,其实任意的RNN都可以堆叠,如SimpleRNN、LSTM和GRU这些循环神经网络也可以进行堆叠。
堆叠指的是在RNN的结构中叠加多层,类似于BP神经网络中可以叠加多层,增加网络的非线性。
3、双向LSTM实现MNIST数据集分类
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import LSTM,Dropout,Bidirectional
from tensorflow.keras.optimizers import Adam
import matplotlib.pyplot as plt
# 载入数据集
mnist = tf.keras.datasets.mnist
# 载入数据,数据载入的时候就已经划分好训练集和测试集
# 训练集数据x_train的数据形状为(60000,28,28)
# 训练集标签y_train的数据形状为(60000)
# 测试集数据x_test的数据形状为(10000,28,28)
# 测试集标签y_test的数据形状为(10000)
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 对训练集和测试集的数据进行归一化处理,有助于提升模型训练速度
x_train, x_test = x_train / 255.0, x_test / 255.0
# 把训练集和测试集的标签转为独热编码
y_train = tf.keras.utils.to_categorical(y_train,num_classes=10)
y_test = tf.keras.utils.to_categorical(y_test,num_classes=10)
# 数据大小-一行有28个像素
input_size = 28
# 序列长度-一共有28行
time_steps = 28
# 隐藏层memory block个数
cell_size = 50
# 创建模型
# 循环神经网络的数据输入必须是3维数据
# 数据格式为(数据数量,序列长度,数据大小)
# 载入的mnist数据的格式刚好符合要求
# 注意这里的input_shape设置模型数据输入时不需要设置数据的数量
model = Sequential([
Bidirectional(LSTM(units=cell_size,input_shape=(time_steps,input_size),return_sequences=True)),
Dropout(0.2),
Bidirectional(LSTM(cell_size)),
Dropout(0.2),
# 50个memory block输出的50个值跟输出层10个神经元全连接
Dense(10,activation=tf.keras.activations.softmax)
])
# 循环神经网络的数据输入必须是3维数据
# 数据格式为(数据数量,序列长度,数据大小)
# 载入的mnist数据的格式刚好符合要求
# 注意这里的input_shape设置模型数据输入时不需要设置数据的数量
# model.add(LSTM(
# units = cell_size,
# input_shape = (time_steps,input_size),
# ))
# 50个memory block输出的50个值跟输出层10个神经元全连接
# model.add(Dense(10,activation='softmax'))
# 定义优化器
adam = Adam(lr=1e-3)
# 定义优化器,loss function,训练过程中计算准确率 使用交叉熵损失函数
model.compile(optimizer=adam,loss='categorical_crossentropy',metrics=['accuracy'])
# 训练模型
history=model.fit(x_train,y_train,batch_size=64,epochs=10,validation_data=(x_test,y_test))
#打印模型摘要
model.summary()
loss=history.history['loss']
val_loss=history.history['val_loss']
accuracy=history.history['accuracy']
val_accuracy=history.history['val_accuracy']
# 绘制loss曲线
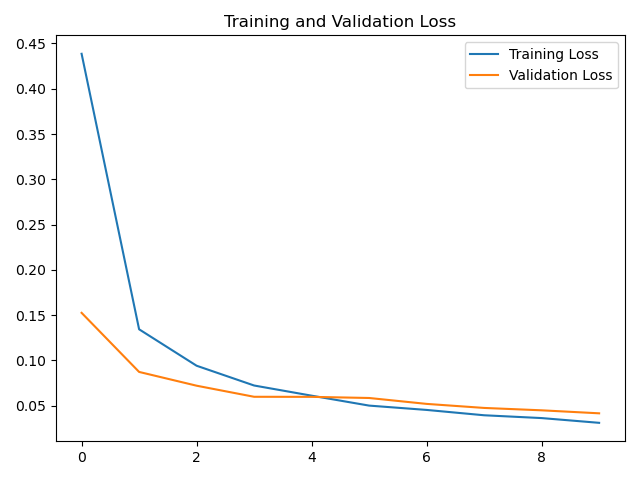
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
# 绘制acc曲线
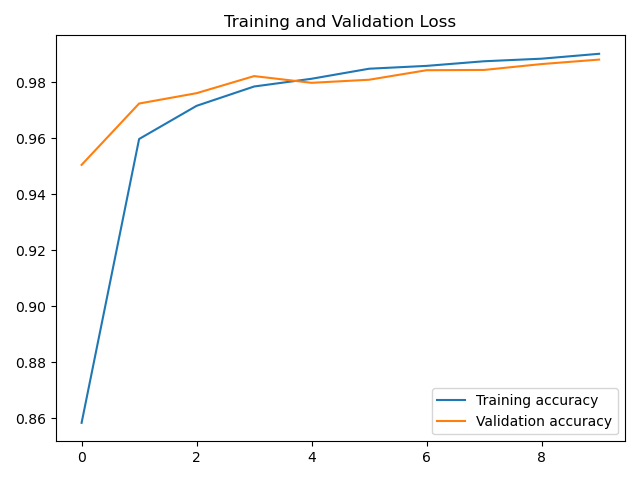
plt.plot(accuracy, label='Training accuracy')
plt.plot(val_accuracy, label='Validation accuracy')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
这个可能对文本数据比较容易处理,这里用这个模型有点勉强,只是简单测试下。
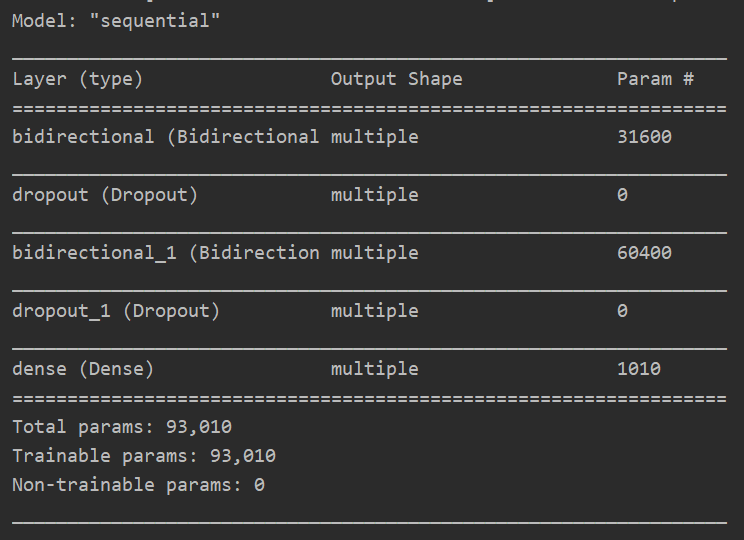
模型摘要:
acc曲线:
loss曲线:

边栏推荐
- AtCoder Beginner Contest 258「ABCDEFG」
- Ad20 make logo
- 官网给的这个依赖是不是应该为flink-sql-connector-mysql-cdc啊,加了依赖调
- Apple 5g chip research and development failure? It's too early to get rid of Qualcomm
- “军备竞赛”时期的对比学习
- vscode的快捷键
- Dedecms website building tutorial
- php解决redis的缓存雪崩,缓存穿透,缓存击穿的问题
- 横向滚动的RecycleView一屏显示五个半,低于五个平均分布
- Window下线程与线程同步总结
猜你喜欢
"Everyday Mathematics" serial 58: February 27

爬虫(9) - Scrapy框架(1) | Scrapy 异步网络爬虫框架
![[论文阅读] CKAN: Collaborative Knowledge-aware Atentive Network for Recommender Systems](/img/6c/5b14f47503033bc2c85a259a968d94.png)
[论文阅读] CKAN: Collaborative Knowledge-aware Atentive Network for Recommender Systems
AtCoder Beginner Contest 258「ABCDEFG」
WorkManager学习一
Learning note 4 -- Key Technologies of high-precision map (Part 2)

【观察】跨境电商“独立站”模式崛起,如何抓住下一个红利爆发时代?

Today in history: the first e-book came out; The inventor of magnetic stripe card was born; The pioneer of handheld computer was born

IDEA新建sprintboot项目

Have you learned to make money in Dingding, enterprise micro and Feishu?
随机推荐
【黑马早报】罗永浩回应调侃东方甄选;董卿丈夫密春雷被执行超7亿;吉利正式收购魅族;华为发布问界M7;豆瓣为周杰伦专辑提前开分道歉...
SqlServer定时备份数据库和定时杀死数据库死锁解决
请问大佬们 有遇到过flink cdc mongdb 执行flinksql 遇到这样的问题的么?
Events and bubbles in the applet of "wechat applet - Basics"
SQL Server 监控统计阻塞脚本信息
一个可以兼容各种数据库事务的使用范例
leetcode:1200. 最小绝对差
Detailed explanation of the use of staticlayout
Golang应用专题 - channel
到底谁才是“良心”国产品牌?
The horizontally scrolling recycleview displays five and a half on one screen, lower than the average distribution of five
学习笔记5--高精地图解决方案
Timed disappearance pop-up
重磅:国产IDE发布,由阿里研发,完全开源!
Personal website construction tutorial | local website environment construction | website production tutorial
WorkManager學習一
Atcoder beginer contest 254 "e BFS" f st table maintenance differential array GCD "
微信核酸检测预约小程序系统毕业设计毕设(7)中期检查报告
How can PostgreSQL CDC set a separate incremental mode, debezium snapshot. mo
Redis如何实现多可用区?