当前位置:网站首页>mongoDB副本集
mongoDB副本集
2022-07-05 09:43:00 【我要出家当道士】
目录
一、副本集架构
参考:Replica Set Members — MongoDB Manual
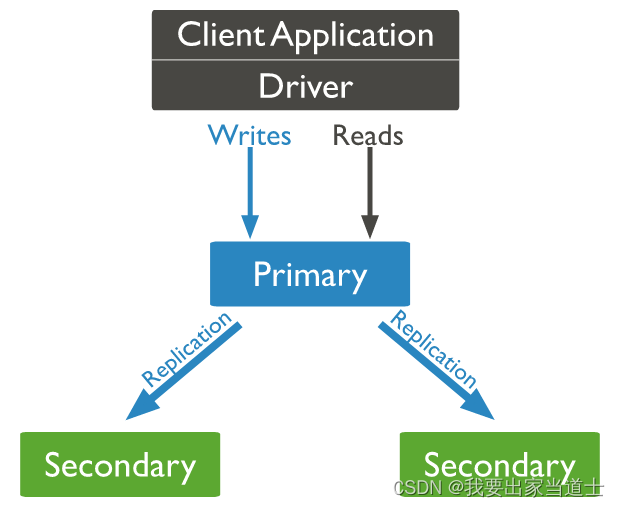
mongoDB 3 版本中副本集中最多支持 50 个节点,其中七个节点具备投票权。
1、primary
副本集中最多只能存在一个Primary节点。
面向用户,所有的数据写操作均作用于该节点。同时该节点也支持读操作,副本集中所有的节点都支持读操作,但用户读操作默认作用于Primary节点。
在该节点上左右的数据变动,均会产生 oplog(操作日志)。Secondary节点可以通过Primary的复制oplog同步数据。
2、secondary
维护与Primary相同的数据副本,支持提供读操作。同时还充当Primary候选节点,当Primary故障时可以根据身上状态自荐为Primary,之后各节点进行投票,选出Primary节点。注意,权重为 0 的节点无法被选举为Primary节点(权重为0的节点仍具备读与投票的功能)。
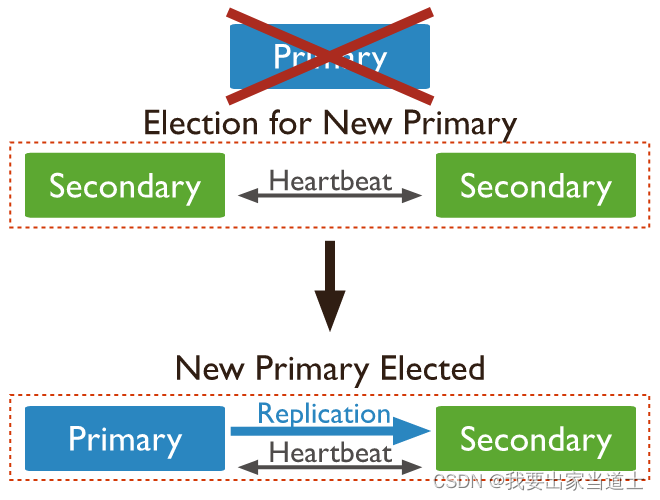
Secondary节点还可以进行隐藏设置。隐藏的Secondary,正常的同步Primary节点的数据,但其权重为 0,无法被选举为Primary节点(可以投票),而且对用户不可见(db.isMaster()不显示隐藏节点)。隐藏的Secondary节点可以用于执行一些专项任务(报告、备份等),除此之外不会存在其它通讯流量。

Secondary还可以设置延迟节点(delay node),延迟节点可以按设置的时间延迟备份Primary 的数据。如下如所示,延迟节点必须设置为隐藏的,且权重为 0。对于延迟节点的作用可能有点不好理解,为啥要延迟复制呢?其实延迟节点的数据相当于 Primary 节点过去某一个时间的数据快照。副本集中所有的 Secondary 节点都是于 Primary 数据同步的,但如果操作人员的一些失误使得整个集群中的数据都出错了,设置延迟节点可以将数据可以恢复到过去某一个时间。

3、Arbiter
仲裁节点,不存储数据,也无法成为Primary节点,主要用于选举从Seconary节点中选举Primary节点。
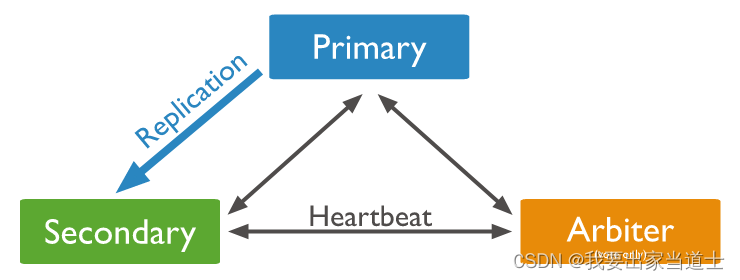
二、oplog
副本集中所有的 Secondary 与 Primary 都是数据同步的(延迟节点除外),他们之间通过oplog 实现数据同步。oplog 是 Primary 节点上的数据操作日志,是幂等的(多次执行,结果一致),Secondary 依据 oplog 即可复现 Primary 节点的所有数据操作,实现数据同步。副本集内所有的节点都会在本地维护一个 oplog(lcoal.oplog.rs),用于记录维护数据的状态。
oplog 大小约束如下。

1、oplog 结构
可以使用mongodump导出oplog数据,查看结构。
由于mongodump导出数据为bson格式的,你可以使用bsondump转换为json格式。
属性 | 描述 | 取值 |
ts | 时间戳。包含两个变量,前者表示操作发生的时间(单位:秒),后者表示相同时间内操作实现的顺序(默认从1开始) | (timestamp, count) |
h | 唯一标识操作的ID | |
t | ||
v | 版本 | |
op | i:insert,数据库插入操作 | |
d:delete,数据库删除操作 | ||
u:update,数据库更新操作 | ||
c:command,数据库执行命令,如建集合 | ||
n:none,空操作 | ||
ns | 写操作 | db_name.collection_name |
数据库命令执行操作 | db_name.$cmd | |
空操作 | blank | |
o | 初始化副本集 | {"msg":"initiate set"} |
选取主节点 | {"msg": "new primary"} | |
新增第一个从节点 | {"msg": "Reconfig Set", "version":2} | |
新增第二个从节点 | {"msg": "Reconfig Set", "version":3} | |
移除一个从节点 | {"msg": "Reconfig Set", "version":4} | |
创建集合 | {"create": "collection_name" } | |
删除集合 | {"drop": "collection_name"} | |
删除数据库 | { "dropDatabase" : 1 } | |
插入或删除文档 | {"_id":1, "Name":"ABC"} | |
更新文档 | { "$set":{ "Name":"MyTest" } } |
2、同步延迟
由于主节点执行所有的写操作,从节点可分担主节点读操作的负载压力。一般的业务场景下,也是写少读多,所以同步从节点和主节点的数据可以很好的减轻业务压力。而且当主节点发生故障后可以使用从节点的数据对主节点进行数据恢复。
当主节点发生数据写操作时,会生成一条或多条oplog日志。从主节点生成oplog日志,到从节点复制oplog到本地并复写oplog日志的这段时间就是同步延迟。这个延迟的影响因素有很多,网络,节点的工作负载都有可能影响。
3、oplog 的导入与导出
oplog的导入导出可以使用 mongodump 与 mongorestore 这两个工具。具体的参数解释可以参考官网的介绍。
有两点需要注意:
0、使用mongodump可以使用query参数执行json字符串进行数据过滤。
1、mongorestore 只支持插入,不支持覆盖操作。即在数据恢复的时候如果已经存在了相同ID的文档,则忽略掉。当然这个对oplog不起作用,因为oplog记录的时操作日志,你的每一个数据更新操作都会产生新的oplog记录。当使用mongorestore直接恢复mongodump导出的数据库数据时需要注意这点。
2、mongorestore 在进行数据恢复时也会产生 oplog日志。
mongodump — MongoDB Manual https://www.mongodb.com/docs/v3.4/reference/program/mongodump/mongorestore — MongoDB Manualhttps://www.mongodb.com/docs/v3.4/reference/program/mongorestore/
https://www.mongodb.com/docs/v3.4/reference/program/mongodump/mongorestore — MongoDB Manualhttps://www.mongodb.com/docs/v3.4/reference/program/mongorestore/
边栏推荐
- Flutter development: use safearea
- 如何判断线程池已经执行完所有任务了?
- Dedecms website building tutorial
- Evolution of Baidu intelligent applet patrol scheduling scheme
- Optimize database queries using the cursor object of SQLite
- Lepton 无损压缩原理及性能分析
- 历史上的今天:第一本电子书问世;磁条卡的发明者出生;掌上电脑先驱诞生...
- 卷起來,突破35歲焦慮,動畫演示CPU記錄函數調用過程
- Swift set pickerview to white on black background
- The essence of persuasion is to remove obstacles
猜你喜欢

基于单片机步进电机控制器设计(正转反转指示灯挡位)

Advanced opencv:bgr pixel intensity map
Pagoda panel MySQL cannot be started

How Windows bat script automatically executes sqlcipher command
能源势动:电力行业的碳中和该如何实现?
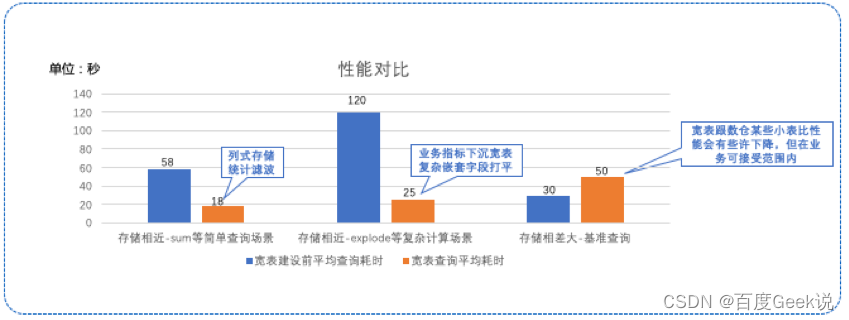
Application of data modeling based on wide table
Design and Simulation of fuzzy PID control system for liquid level of double tank (matlab/simulink)
Design and exploration of Baidu comment Center
Six simple cases of QT

Charm of code language
随机推荐
@SerializedName注解使用
Swift saves an array of class objects with userdefaults and nssecurecoding
双容水箱液位模糊PID控制系统设计与仿真(Matlab/Simulink)
ConstraintLayout官方提供圆角ImageFilterView
Single chip microcomputer principle and Interface Technology (esp8266/esp32) machine human draft
StaticLayout的使用详解
程序员搞开源,读什么书最合适?
90%的人都不懂的泛型,泛型的缺陷和应用场景
Cerebral Cortex:有向脑连接识别帕金森病中广泛存在的功能网络异常
Swift set pickerview to white on black background
【C语言】动态内存开辟的使用『malloc』
字节跳动面试官:一张图片占据的内存大小是如何计算
驱动制造业产业升级新思路的领域知识网络,什么来头?
LiveData 面试题库、解答---LiveData 面试 7 连问~
Apache DolphinScheduler 系统架构设计
基于单片机步进电机控制器设计(正转反转指示灯挡位)
Application of data modeling based on wide table
如何写出高质量的代码?
苹果 5G 芯片研发失败?想要摆脱高通为时过早
Mobile heterogeneous computing technology GPU OpenCL programming (Advanced)