当前位置:网站首页>Mobile heterogeneous computing technology GPU OpenCL programming (Advanced)
Mobile heterogeneous computing technology GPU OpenCL programming (Advanced)
2022-07-05 09:45:00 【Baidu geek said】

Reading guide : This article will explain OpenCL Some in-depth knowledge of , At the same time, it combines with the mainstream of the mobile terminal GPU Qualcomm, one of the manufacturers Adreno chip design , Explain the mobile terminal OpenCL Some general means of programming optimization . The full text 5201 word , Estimated reading time 14 minute .
One 、 Preface
stay 《 Mobile heterogeneous computing technology -GPU OpenCL Programming ( The basic chapter )》 in , The mobile terminal is introduced GPU Calculation status and OpenCL Basic concepts of programming . This article will further elaborate OpenCL Some in-depth knowledge of , At the same time, it combines with the mainstream of the mobile terminal GPU Qualcomm, one of the manufacturers Adreno chip design , Explain the mobile terminal OpenCL Some general means of programming optimization .
remarks : qualcomm GPU Outside the series , Huawei Kirin 、 The chips such as MediaTek Tianji adopt ARM Designed by the company Mali series GPU, Due to space limitations, this article will not be described separately .
Two 、 Basic concepts
丨 OpenCL
OpenCL By Khronos The organization develops and maintains an open 、 Free standard , Cross platform parallel programming for heterogeneous systems . This kind of design can help developers to use modern heterogeneous systems to play a powerful parallel computing power , At the same time, it is cross platform to some extent .
丨 OpenCL qualcomm
Qualcomm was the first to fully support mobile terminals OpenCL One of the chip manufacturers with computing power , And it has occupied a certain market share in the domestic and international markets .
3、 ... and 、OpenCL structure
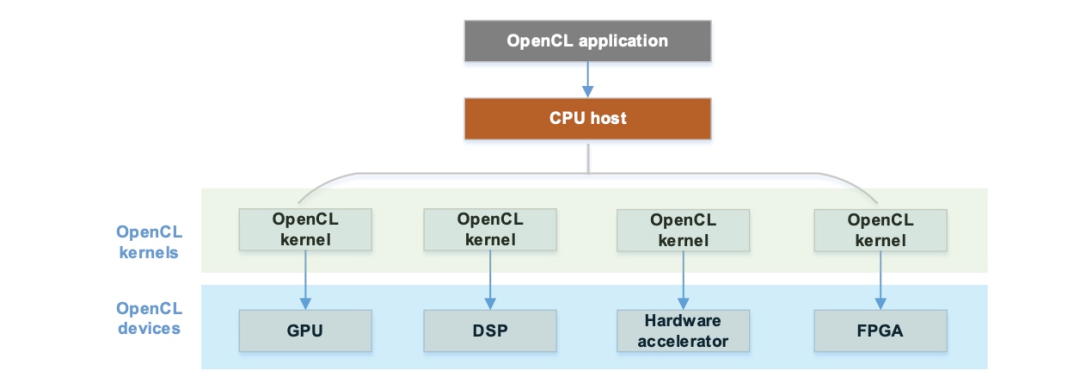
An abstract OpenCL application , It usually includes the following parts :
CPU Host: As a whole OpenCL Application management 、 Dispatcher , Control the whole OpenCL The implementation process of .
OpenCL Devices: Concrete OpenCL Hardware device , such as GPU、DSP、FPGA wait .
OpenCL Kernels: Undertaking the task of execution OpenCL Kernel code , Will be OpenCL Host Compile , And execute on the corresponding hardware .
丨 Mobile devices OpenCL
According to current experience ,Android Mobile devices in the camp ,OpenCL Usually use GPU As the hardware acceleration end . Qualcomm's suggestion is to select the mobile terminal GPU As OpenCL Acceleration equipment for ( notes : In fact, in most cases, there is no choice , You can only get one GPU Of device).
Four 、OpenCL Compatibility
丨 Program portability
OpenCL It provides good program compatibility , A set of OpenCL Code for , It can work normally on different devices . Of course , A small part is based on hardware expansion capability , Depends on current hardware support .
丨 Performance portability
Different from program compatibility ,OpenCL The performance portability of is usually poor . As an advanced computing standard ,OpenCL The implementation of the hardware part depends on the manufacturer , Each manufacturer has its own advantages and disadvantages . therefore , For different hardware platforms , Such as Qualcomm Adreno perhaps Arm Mali, The performance of the same code is different . Even the same manufacturer , As the hardware iterates , The corresponding drive will also have corresponding fine adjustment , To take full advantage of the full capabilities of the new generation of hardware . It is necessary to optimize for different devices or hardware . Of course this is a ROI( Return on investment ) problem .
丨 Backward compatibility
OpenCL Is designed to ensure backward compatibility as much as possible . If you want to use outdated capabilities , Just import a specific header file . It is worth noting that :OpenCL Is not completely backward compatible , These extensions are usually provided by hardware manufacturers in combination with hardware features , Therefore, it is necessary to consider the expansion compatibility between different hardware when applying .
5、 ... and 、 qualcomm Adreno OpenCL framework
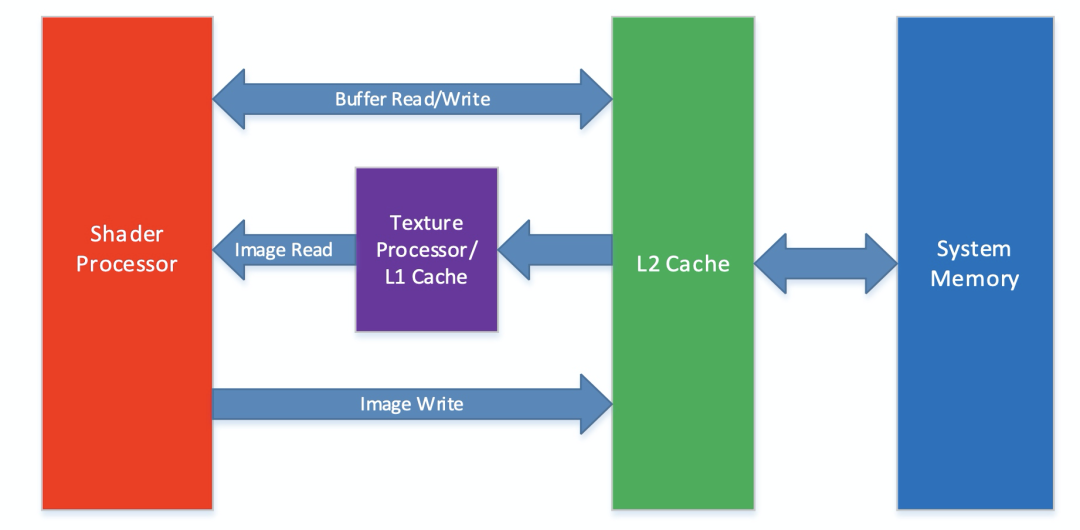
High pass is shown in the figure Adreno GPU OpenCL(Adreno A5x GPUS) The superstructure ,OpenCL Several key hardware modules are involved in the implementation process .
丨 Shader (or streaming) processor (SP) ( Shaders 、 Stream processors )
Adreno GPU Core module , Contains numerous hardware modules , Such as arithmetic logic unit 、 Load storage unit 、 Control flow unit 、 Register file, etc .
Run the shape shader ( Such as vertex shader 、 Chip shader 、 Calculate shaders, etc ), Run calculation load , Such as OpenCL Kernel, etc .
Every SP Corresponds to one or more OpenCL Operation unit of .
Adreno GPU It may contain one or more SP, It depends on the grade of the chip , The figure above shows a single SP The situation of .
SP Load and read Buffer Type or with __read_write Of the tag Image Type data object , You can use L2 cache .
SP Load read-only Image Data object of type , You can use L1 Cache or texture processor .
丨 Texture Processer (TP) ( Texture processor )
According to the scheduling of the kernel to carry out texture operations , Such as texture reading 、 Filtration, etc. .
TP and L1 Cache combination , Reduce from L2 The probability of cache loss when reading data from the cache .
丨 Unified L2 Cache (UCHE) ( Unified L2 cache )
- Respond to SP about Buffer Type read and load , as well as L1 about Image Type of data loading operation .
6、 ... and 、 How to write high performance OpenCL Code
丨 Performance compatibility
As mentioned above OpenCL Performance compatibility , Because the characteristics of different hardware are different , So after tuning on a chip OpenCL The performance of the code on another chip may not be optimal . You need to refer to the corresponding hardware documentation for specific optimization . For different chips , Targeted optimization is necessary .
丨 Means Overview
OpenCL Program optimization can generally be divided into the following three categories :
Program 、 Algorithm level optimization
API Level optimization
OpenCL Kernel optimization
Program algorithm and API The hierarchical optimization method is more general , Here we mainly expand OpenCL Kernel optimization means .
OpenCL The optimization problem of is essentially a problem of how to make use of kernel bandwidth and computing power . That is, reasonable use of global memory 、 Local memory 、 register 、 Multi level cache, etc , And rational use of logical operation units 、 Texture units and so on .
丨 Whether the procedure is applicable OpenCL
Developers need to determine whether the program is suitable for use OpenCL To write , It can be judged from the following aspects :
Whether there is a large data input
Whether the program itself is computationally intensive
Whether the program is compatible with parallel computing
There are relatively few control flow operations in the program
丨 take CPU Code changed to GPU Code time performance Tips
After clarifying the above key points , Developers can begin to CPU The code of is transformed into OpenCL Code for , To achieve an optimal performance , Attention should be paid to the following aspects :
In some cases , Will be multiple CPU Merge operations into one OpenCL You can get performance gains from the kernel . This method is usually used to reduce GPU And main memory .
In some cases , Will be a complex CPU The program is divided into several simple OpenCL kernel , You can get better program parallelism , To achieve global performance optimization .
Developers need to consider redesigning the overall data architecture , It is convenient to reduce the cost of data transmission .
These situations should be considered in combination with the actual situation , It is also the difficulty of high-performance heterogeneous programming .
丨 Parallelization CPU and GPU The workflow of the
Make full use of the computing performance of the chip , The task should be reasonably planned , stay GPU While performing some calculations ,CPU Can also undertake part of the work at the same time . Generally, it can be summarized as the following points :
send CPU To carry out CPU The part that is good at execution , Such as branch control logic , And some serial operations .
Try to avoid GPU Go idle , wait for CPU The situation of assigning further tasks .
CPU and GPU The cost of data transfer between is extremely high , To reduce this cost , Some can be adapted to CPU The tasks carried out are put into GPU Conduct .
7、 ... and 、 Performance analysis
丨 performance Profile
Can combine Profile Means to analyze program performance . because OpenCL Programs are divided into host CPU The scheduling logic of , as well as GPU Execution logic on hardware . Developers can choose from CPU Scheduling process and GPU Implement two levels of performance Profile. Usually CPU Profile It is used to measure the end-to-end performance of the whole process ,GPU Profile To measure OpenCL Kernel performance .
CPU Profile
You can use standard c++ programmatically , For example, through gettimeofday And so on. api Go ahead CPU Time statistics between processes .
Some sample code is listed in this article , detailed demo May refer to OpenCL Profile(https://github.com/xiebaiyuan/opencl_cook/tree/master/profile).
#include <time.h>
#include <sys/time.h>
void main() {
struct timeval start, end;
// get the start time
gettimeofday(&start, NULL);
// execute function of interest
{
. . .
clFinish(commandQ);
}
// get the end time
gettimeofday(&end, NULL);
// Print the total execution time
double elapsed_time = (end.tv_sec - start.tv_sec) * 1000. + \
(end.tv_usec - start.tv_usec) / 1000.;
printf("cpu all cost %f ms \n", elapsed_time);
GPU Profile
OpenCL Provide for the right to GPU Kernel Profile Of API, Get separately OpenCL Time node of each phase of the task , It is convenient for developers to optimize performance .
// opencl init codes
...
// cl gpu time profile
cl_event timing_event;
cl_ulong t_queued, t_submit, t_start, t_end;
// add event when clEnqueueNDRangeKernel
int status = clEnqueueNDRangeKernel(runtime.queue, runtime.kernel, 1, nullptr, &ARRAY_SIZE,
nullptr, 0, nullptr, &timing_event);
check_status(status, "clEnqueueNDRangeKernel failed");
clWaitForEvents(1, &timing_event);
clGetEventProfilingInfo(timing_event, CL_PROFILING_COMMAND_QUEUED,
sizeof(cl_ulong), &t_queued, nullptr);
clGetEventProfilingInfo(timing_event, CL_PROFILING_COMMAND_SUBMIT,
sizeof(cl_ulong), &t_submit, nullptr);
clGetEventProfilingInfo(timing_event, CL_PROFILING_COMMAND_START,
sizeof(cl_ulong), &t_start, nullptr);
clGetEventProfilingInfo(timing_event, CL_PROFILING_COMMAND_END,
sizeof(cl_ulong), &t_end, nullptr);
printf("t_queued at %llu \n"
"t_start at %llu \n"
"t_submit at %llu \n"
"t_end at %llu \n"
"kernel execute cost %f ns \n"
"", t_queued, t_start, t_submit, t_end, (t_end - t_start) * 1e-0);
Through the above api You can get OpenCL Kernel From entering the queue , Submit 、 Start 、 Each time point of the end , And you can calculate Kernel Operation duration :
t_queued at 683318895157
t_start at 683318906619
t_submit at 683318897475
t_end at 683318907168
kernel execute cost 549.000000 ns
Performance bottleneck
It is very important to identify and locate the performance bottleneck of the whole program , No performance bottlenecks were found , Even if the performance of other links is optimized , Nor can the performance of the entire application be improved .
Bottleneck positioning
about OpenCL kernel , Bottlenecks are usually memory bottlenecks and computing bottlenecks One of the two .
Here are two simple ways , You can verify by modifying the code a little :
Add extra computational logic , How not to affect performance , That should not be a computing bottleneck .
conversely , Add more data loading logic , How not to affect performance , That should not be a data bottleneck .
Solve performance bottlenecks
After successfully locating the performance bottleneck , There are a series of means to solve the problem :
If it is a computing bottleneck , Try some ways to reduce the computational complexity 、 A way to reduce the number of calculations , Or use OpenCL Provided fase relax math perhaps native math etc. . It can be used when the accuracy is not high fp16 replace fp32 Calculate .
If it is a memory bottleneck , You can try to optimize the memory access policy , Such as using vectorized memory loading and storage , Use local memory or texture memory, etc . Use shorter data types where possible , Can effectively reduce memory bandwidth .
8、 ... and 、 summary
In this article, Qualcomm Adreno GPU give an example , More in-depth exposition of OpenCL Design idea , At the same time OpenCL Some general methodologies for high-performance programming . Because the space is limited, more details are not fully developed , Small partners interested in this direction can continue to pay attention to **「 Baidu Geek say 」** official account .
Nine 、 reference
[1] OpenCL-Guide
https://github.com/KhronosGroup/OpenCL-Guide/blob/main/chapters/opencl_programming_model.md
[2]OpenCL-Examples
https://github.com/rsnemmen/OpenCL-examples
[3]Mali-GPU
https://zh.wikipedia.org/wiki/Mali_%28GPU%29
[4]Adreno-GPU
https://zh.wikipedia.org/wiki/Adreno
Recommended reading :
On a large scale C++ Compile performance optimization system OMAX Introduce
The evolution of Baidu intelligent applet patrol scheduling scheme
Mobile heterogeneous computing technology -GPU OpenCL Programming ( The basic chapter )
边栏推荐
- 观测云与 TDengine 达成深度合作,优化企业上云体验
- Nips2021 | new SOTA for node classification beyond graphcl, gnn+ comparative learning
- [ctfhub] Title cookie:hello guest only admin can get flag. (cookie spoofing, authentication, forgery)
- 测试老鸟浅谈unittest和pytest的区别
- 【el-table如何禁用】
- How to empty uploaded attachments with components encapsulated by El upload
- VS Code问题:长行的长度可通过 “editor.maxTokenizationLineLength“ 进行配置
- Viewpager pageradapter notifydatasetchanged invalid problem
- [Yugong series] go teaching course 003-ide installation and basic use in July 2022
- OpenGL - Model Loading
猜你喜欢

What should we pay attention to when developing B2C websites?

H.265编码原理入门
![[team PK competition] the task of this week has been opened | question answering challenge to consolidate the knowledge of commodity details](/img/d8/a367c26b51d9dbaf53bf4fe2a13917.png)
[team PK competition] the task of this week has been opened | question answering challenge to consolidate the knowledge of commodity details

Why does everyone want to do e-commerce? How much do you know about the advantages of online shopping malls?
观测云与 TDengine 达成深度合作,优化企业上云体验

Three-level distribution is becoming more and more popular. How should businesses choose the appropriate three-level distribution system?
TDengine ×英特尔边缘洞见软件包 加速传统行业的数字化转型
C语言-从键盘输入数组二维数组a,将a中3×5矩阵中第3列的元素左移到第0列,第3列以后的每列元素行依次左移,原来左边的各列依次绕到右边
Understanding of smt32h7 series DMA and DMAMUX

E-commerce apps are becoming more and more popular. What are the advantages of being an app?
随机推荐
An article takes you into the world of cookies, sessions, and tokens
Tdengine offline upgrade process
【愚公系列】2022年7月 Go教学课程 003-IDE的安装和基本使用
卷起来,突破35岁焦虑,动画演示CPU记录函数调用过程
测试老鸟浅谈unittest和pytest的区别
Tutorial on building a framework for middle office business system
百度交易中台之钱包系统架构浅析
How to choose the right chain management software?
A keepalived high availability accident made me learn it again
[Yugong series] go teaching course 003-ide installation and basic use in July 2022
MYSQL 对字符串类型排序不生效问题
mysql安装配置以及创建数据库和表
Kotlin introductory notes (V) classes and objects, inheritance, constructors
OpenGL - Coordinate Systems
VS Code问题:长行的长度可通过 “editor.maxTokenizationLineLength“ 进行配置
SQL learning alter add new field
From "chemist" to developer, from Oracle to tdengine, two important choices in my life
Unity skframework framework (24), avatar controller third person control
Community group buying exploded overnight. How should this new model of e-commerce operate?
What should we pay attention to when entering the community e-commerce business?