当前位置:网站首页>High performance spark_ Transformation performance
High performance spark_ Transformation performance
2022-07-05 09:18:00 【sword_ csdn】
Catalog
wide (wide) Dependence and narrowness (narrow) rely on
(1) Narrow dependence (narrow dependencies). Father RDD The maximum number of quilts in each partition of RDD Referenced by a partition of .
(2) Wide dependence (wide dependencies). Father RDD Each partition of is divided into multiple sub RDD The referenced .
for example , Consider the following code code_A
val rdd2 = rdd1.map(x=>(x,1))
val rdd3 = rdd2.groupByKey()
from rdd1 To rdd3 The change of data is shown in the figure below :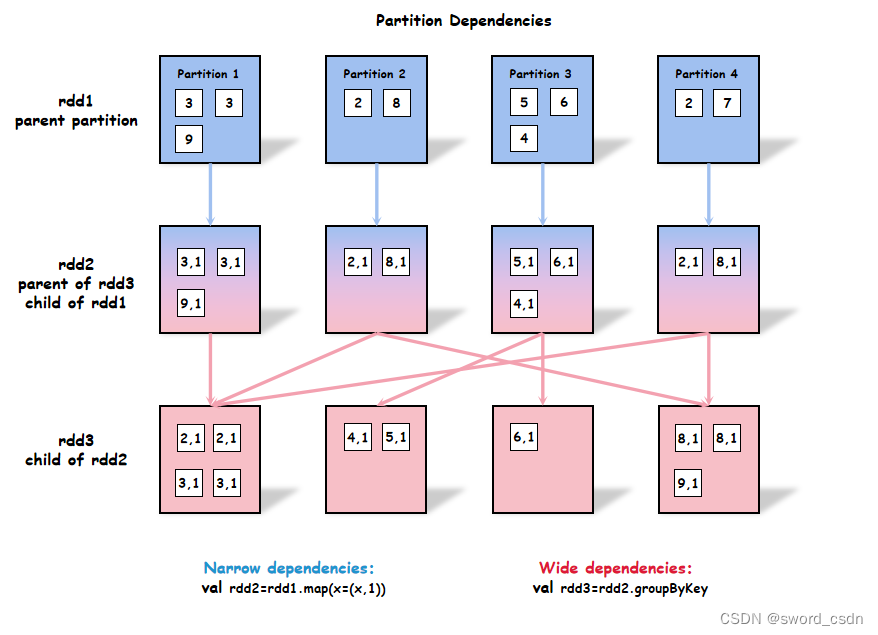
from rdd1 To rdd2 It belongs to narrow dependence (narrow dependencies), because rdd2 Each partition data in is only from rdd1 Get . from rdd2 To rdd3 It belongs to wide dependence (wide dependencies), because rdd3 There may be data from multiple partitions in rdd2 Multiple sections of .
narrow There is no data movement between partitions in the conversion process , There is no need to talk with driver node signal communication . When a series of narrow Encountered a wide After the transformation ,Spark Will take this. wide Transform and connect the... In front of it narrow Transformation is regarded as a stage Stage . And the transformation behind it will be counted in the next stage In phase .
One stage Medium narrow The transformation is parallel , and stage And stage Between them is serial . One stage How many partitions are there in ,narrow The parallel number of conversions is as much , The conversion is completed within the partition .wide Before implementing specific operations, the transformation will first realize the transmission of data between different partitions , This operation is called shuffle, The purpose is to put the relevant data into a partition to realize the data conversion within the partition .
(1)“narrow” and “wide” Impact on performance
narrow Conversion ratio wide The conversion runs faster , because narrow Conversion does not result in data transmission between partitions , also narrow The process of transformation does not need to be connected with driver node Interaction , This is the same as wide Conversion is the opposite .
(2)“narrow” and “wide” Impact on fault tolerance
When spark When an error occurs in the calculation of the cluster for the partition , about wide The conversion costs more to recover from this error . because wide Conversion may need to get data from multiple parent partitions when recalculating partitions . And it is easy to cause the problem of memory leakage .
(3) Use coalesce Precautions for
coalesce Methods are generally used to change rdd The number of divisions . When this method is used to reduce the number of partitions , Each parent partition has only one child partition corresponding to it , Because a child partition is a collection of parent partitions . So from that perspective , It belongs to narrow transformation . conversely , When coalesce Method is used to increase the number of partitions , Each parent partition will have multiple child partitions corresponding to it . At this point it wide transformation .
RDD The type of return
If one tuple Type of RDD Lost its schema Information ,Spark Will use “Any” Instead of , for example :RDD[Any] and RDD[(Any,Int)]. At this time, when some methods are executed , Compilation cannot pass , for example :sortByKey.sortByKey The method actually depends on key There are some hidden sortable possibilities for the value of , for example : Alphabetical order , Number sorting and so on . There are also many numerical methods, such as :max,min, and sum We also need to rely on RDD The data in is Long,Int Or is it double type .
DataFrame Medium Row It's a weak type , from DataFrame Turn into RDD, The type of some values will become “Any”, This is a sign of missing value type management information . So in this process, it's best to DataFrame Of schema Information is recorded with a variable .
Besides Dataset API It's a strong type , So it translates into RDD after , The value of each row will retain its type information .
Reduce the creation of objects
“ Garbage collection ” To create objects for recycling (object) Resources allocated when . So if Spark The more objects created in the job ,“ Garbage collection ” The higher the cost caused by the mechanism . So it is recommended that Spark Reduce the use of objects , Or multipoint reuse objects .
Use mapPartitions
rdd Of mapPartitions yes map A variation of , Both of them can process data in parallel . There are many differences between the two .
The first is the granularity of parallel processing data
(1)map Of input transformation Apply to every element .
(2)mapPartitions Of input transformation Apply to each partition .
Suppose a rdd Yes 10 Elements (1 2 3 4 5 6 7 8 9 10), Divide into 3 Zones , The test code is as follows
val a = sc.parallelize(1 to 10,3)
def handlePerElement(e:Int):Int={
println("element="+e)
}
def handlePerPartition(iter:Iterator[Int]:Iterator[Int]={
println("run in partition")
var res = for(e<-iter) yield e*2
res
}
val b = a.map(handlePerElement).collect
val c = a.mapPartitions(handlePerPartition).collect
Run the above code test and you can see , Based on element granularity handlePerElement Function output 10 Time , Based on partition granularity handlePerPartition Output 3 Time .
Input function to get data
be based on map call handlePerElement when , It's actually map Put the data PUSH To handlePerElement in , And when mapPartitions call handlePerPartition when , It is handlePerPartition Take the initiative PULL Take the data .
Dealing with big data sets
handlePerElement and handlePerPartition Initialize a time-consuming resource , And then use , For example, database connection .handlePerPartition Just initialize 3 A resource ( Every section 1 individual ),handlePerElement To initialize 10 Time ( Every element 1 individual ), In the case of big data , The number of elements in the data set is much larger than the number of partitions , therefore mapPartitions The cost is much smaller , Convenient for batch operation .
Sharing of variables
Spark There are two types of shared variables in : Accumulators and broadcast variables . Accumulators are used to aggregate information , Broadcast variables are used to efficiently distribute large objects .
Closure
Suppose there's a piece of code
var n = 1
val func = (i:Int)=>i+n
function func There are two variables ,n and i, among i Is the formal parameter of the function , That is to say Enter the reference , stay func When the function is called ,i Will be given a new value , be called Bound variable (bound variable), and n Is defined in the function func Outside , The function is not given any value , be called Free variable (free variable).
image func Function like this , The result of a function that depends on one or more external variables , Capture these free variables and form a closed function , be called “ Closure ”.
Suppose there is an example of cumulative summation , The code is as follows :
var sum = 0
val arr = Array(1,2,3,4,5)
sc.parallelize(arr).foreach(x=>sum+=x)
println(sum)
This code will not achieve sum=15 The effect of . It is sum=0. The reason for this result is the existence of closures .
In the cluster ,Spark Actually, Hui is right RDD The operation processing of is decomposed into Tasks, Every Task from Executor perform . Before execution ,Spark Calculation task The closure of ( That is, in the above code foreach()). The closure will be serialized and sent to each Executor, But only copies are sent .
( Only now do I understand what a closure is , It is a method, even if it uses external variables , The calculation only uses a copy of this variable , Close the door and count )
Principle of accumulator
Accumulator can break through the limitation of closure , Update the change in the value of the work node to Driver in . First Driver call SparkContext.accumulator(initialValue) Method ,Spark The executor code in the closure will +1. That is, put the following code
var sum = 0
Change to
val sum = sc.accumulator(0)
The principle of broadcast variables
The principle of broadcast variable is similar to that of accumulator , The difference lies in , Broadcasting variables does not mean sending copies of variables to all Task, But just distribute it to all work nodes , Then all in the work node Task Share a copy of the data .
val broadcastVar = sc.broadcast(Array(1,2,3))
broadcastVar.val
RDD Reuse of
Spark Provides persist,cache,checkpoint There are three ways to achieve RDD Reuse of .cache and persist Is to cache data in memory by default ( rdd.persist(StorageLevel.DISK_ONLY) It can be cached on disk ),checkpoint It's physical storage .
(1)cache The underlying call is persist.
(2)cache The default persistence level is memory and cannot be modified ,persist You can modify the persistence level .
(3) When a certain step takes special time , It is recommended to use cache and checkpoint
(4) When the calculated chain is very long , It is recommended to use cache and checkpoint
In general, it is recommended to use cache and persist Pattern , Because there is no need to create a storage location , It is stored in memory by default, and the calculation speed is fast , and checkpoint You need to manually create storage locations and manually delete .
边栏推荐
- C#图像差异对比:图像相减(指针法、高速)
- Codeworks round 638 (Div. 2) cute new problem solution
- 生成对抗网络
- Solution to the problems of the 17th Zhejiang University City College Program Design Competition (synchronized competition)
- [beauty of algebra] solution method of linear equations ax=0
- Talking about label smoothing technology
- Multiple solutions to one problem, asp Net core application startup initialization n schemes [Part 1]
- It's too difficult to use. Long articles plus pictures and texts will only be written in short articles in the future
- Causes and appropriate analysis of possible errors in seq2seq code of "hands on learning in depth"
- 牛顿迭代法(解非线性方程)
猜你喜欢

The research trend of map based comparative learning (gnn+cl) in the top paper
编辑器-vi、vim的使用
Applet network data request

Blogger article navigation (classified, real-time update, permanent top)
OpenGL - Coordinate Systems
什么是防火墙?防火墙基础知识讲解
![[technical school] spatial accuracy of binocular stereo vision system: accurate quantitative analysis](/img/59/823b587566f812c76e0e4dee486674.jpg)
[technical school] spatial accuracy of binocular stereo vision system: accurate quantitative analysis

RT thread kernel quick start, kernel implementation and application development learning with notes
![[code practice] [stereo matching series] Classic ad census: (5) scan line optimization](/img/54/cb1373fbe7b21c5383580e8b638a2c.jpg)
[code practice] [stereo matching series] Classic ad census: (5) scan line optimization
![Introduction Guide to stereo vision (5): dual camera calibration [no more collection, I charge ~]](/img/68/6bfa390b0bedcdbc4afba2f9bd9c0f.jpg)
Introduction Guide to stereo vision (5): dual camera calibration [no more collection, I charge ~]
随机推荐
Introduction Guide to stereo vision (4): DLT direct linear transformation of camera calibration [recommended collection]
Summary of "reversal" problem in challenge Programming Competition
Kotlin introductory notes (V) classes and objects, inheritance, constructors
AUTOSAR从入门到精通100讲(103)-dbc文件的格式以及创建详解
Editor use of VI and VIM
编辑器-vi、vim的使用
迁移学习和域自适应
Kotlin introductory notes (III) kotlin program logic control (if, when)
深入浅出PyTorch中的nn.CrossEntropyLoss
.NET服务治理之限流中间件-FireflySoft.RateLimit
生成对抗网络
Codeforces Round #648 (Div. 2) E.Maximum Subsequence Value
Using request headers to develop multi terminal applications
C # image difference comparison: image subtraction (pointer method, high speed)
【PyTorch Bug】RuntimeError: Boolean value of Tensor with more than one value is ambiguous
Rebuild my 3D world [open source] [serialization-3] [comparison between colmap and openmvg]
[beauty of algebra] solution method of linear equations ax=0
Applet (global data sharing)
Kotlin introductory notes (II) a brief introduction to kotlin functions
什么是防火墙?防火墙基础知识讲解