当前位置:网站首页>[code practice] [stereo matching series] Classic ad census: (4) cross domain cost aggregation
[code practice] [stereo matching series] Classic ad census: (4) cross domain cost aggregation
2022-07-05 08:53:00 【Li Yingsong~】
Sorry to keep you waiting !
Download the complete source code , Click to enter : https://github.com/ethan-li-coding/AD-Census
Welcome to Github Discuss in the project !
Part 1 Cost calculation in , I've brought you an in-depth understanding ADCensusStereo Implementation code of cost calculation step , Experiments are done to show the results of the algorithm . Here is the experimental result of cost calculation :
 |  |  |
As mentioned at the end of the previous article ,AD-Census The cost calculation method of AD and Census Advantages of matching strategy , Is an excellent strategy .
And in any case , The result of cost calculation cannot be regarded as the final parallax result , The next optimization steps are right ADCensus Is an indispensable step . This article introduces the first optimization step : Cost aggregation based on cross domain Code implementation of .
List of articles
Algorithm
Please see the blog for the principle of Algorithm :
classic AD-Census: (2) Cross domain cost aggregation (Cross-based Cost Aggregation)
I won't repeat , So as not to make a fuss .
Code implementation
Class design
Member functions
I write the cross domain cost aggregation as a class CrossAggregator, Put it in the file cross_aggregator.h/cross_aggregator.cpp in .
/** * \brief Cross domain cost aggregator */
class CrossAggregator {
public:
CrossAggregator();
~CrossAggregator();
}
We need to CrossAggregator Class to design some public interfaces , Thus, they can be called to achieve the purpose of cost aggregation .
We use Cost calculator design The idea of .
The first interface is Initialization function Initialize , Do some preparatory work for cost aggregation , For example, a very important point is that I need to open up a memory to store the cross arm data of each pixel , For later aggregation .
The second type of interface is essential Set up the data SetData as well as Set parameters SetParam , Away from data and parameters , Algorithm is nothing .
The third is the key interface Aggregate 了 , Finally, we need to call it to complete the cost aggregation .
The last two additional interfaces are get_arms_ptr and get_cost_ptr, The former gets the array of cross arms , This is purely because the post-processing step requires ; The latter is to obtain the aggregated cost data pointer , It is very important , Because the following scan line optimization steps need it .
Let's take a look at the final class interface design :
/** * \brief Initialize the cost aggregator * \param width The image is wide * \param height Image height * \return true: Successful initialization */
bool Initialize(const sint32& width, const sint32& height, const sint32& min_disparity, const sint32& max_disparity);
/** * \brief Set the data of the cost aggregator * \param img_left // Left image data , Three channels * \param img_right // Right image data , Three channels * \param cost_init // Initial cost array */
void SetData(const uint8* img_left, const uint8* img_right, const float32* cost_init);
/** * \brief Set the parameters of the cost aggregator * \param cross_L1 // L1 * \param cross_L2 // L2 * \param cross_t1 // t1 * \param cross_t2 // t2 */
void SetParams(const sint32& cross_L1, const sint32& cross_L2, const sint32& cross_t1, const sint32& cross_t2);
/** \brief polymerization */
void Aggregate(const sint32& num_iters);
/** \brief Get the cross arm data pointer of all pixels */
CrossArm* get_arms_ptr();
/** \brief Get aggregate cost array pointer */
float32* get_cost_ptr();
The above interface is all public functions of the class , The caller can call . The parameter meaning of the specific interface , The notes are very clear , Just look at each other .
One thing to mention is ,get_arms_ptr Type of function scope CrossArm, It is my customized cross arm structure , Save the length of the upper, lower, left and right arms of the pixel . As shown below :
/** * \brief Cross arm structure * To limit memory usage , The arm length type is set to uint8, This means that the maximum arm length cannot exceed 255 */
struct CrossArm {
uint8 left, right, top, bottom;
CrossArm() : left(0), right(0), top(0), bottom(0) {
}
};
In order to complete the cost aggregation , We need some sub steps , They include :
- Build a cross arm
- Calculate the number of pixels in the support area of pixels
- The cost of aggregating all pixels at a fixed parallax
They are designed as private member functions of classes :
/** \brief Build a cross arm */
void BuildArms();
/** \brief Search the horizontal arm */
void FindHorizontalArm(const sint32& x, const sint32& y, uint8& left, uint8& right) const;
/** \brief Search for vertical arms */
void FindVerticalArm(const sint32& x, const sint32& y, uint8& top, uint8& bottom) const;
/** \brief Calculate the number of pixels in the support area of pixels */
void ComputeSupPixelCount();
/** \brief Aggregate a certain parallax */
void AggregateInArms(const sint32& disparity, const bool& horizontal_first);
In aggregate function Aggregate in , These private functions are called in turn to complete the cost aggregation .
Member variables
Finally, the indispensable member variables of the member function class , Such as image size 、 Cross arm data ( Left image )、 Image data 、 Cost data 、 Algorithm parameters, etc , It is they that always maintain the value required by the algorithm within the scope of the class , In order to achieve the final calculation purpose . You have to protect them with private types , For internal use of classes only , Let's see !
/** \brief Image size */
sint32 width_;
sint32 height_;
/** \brief Cross arms */
vector<CrossArm> vec_cross_arms_;
/** \brief Image data */
const uint8* img_left_;
const uint8* img_right_;
/** \brief Initial cost array pointer */
const float32* cost_init_;
/** \brief Aggregate cost array */
vector<float32> cost_aggr_;
/** \brief Temporary cost data */
vector<float32> vec_cost_tmp_[2];
/** \brief Support area pixel number array 0: Horizontal arm is preferred 1: Vertical arm is preferred */
vector<uint16> vec_sup_count_[2];
vector<uint16> vec_sup_count_tmp_;
sint32 cross_L1_; // Spatial domain parameters of cross window :L1
sint32 cross_L2_; // Spatial domain parameters of cross window :L2
sint32 cross_t1_; // Cross window color field parameters :t1
sint32 cross_t2_; // Cross window color field parameters :t2
sint32 min_disparity_; // Minimum parallax
sint32 max_disparity_; // Maximum parallax
/** \brief Flag indicating whether the initialization was successful */
bool is_initialized_;
Explain , In a member variable , Our initial cost data cost_init_ It is pointer type , Because it is the data returned by the cost calculator directly , And aggregate cost data cost_aggr_ yes vector Containers , It will open up memory in the initialization function of this class , And exist in the whole life cycle of the cost aggregator , Will be through the interface get_cost_ptr Output its address , Use for subsequent steps .
Class implementation
Let's first look at the cost aggregator class CrossAggregator Implementation of initialization function :
bool CrossAggregator::Initialize(const sint32& width, const sint32& height, const sint32& min_disparity, const sint32& max_disparity)
{
width_ = width;
height_ = height;
min_disparity_ = min_disparity;
max_disparity_ = max_disparity;
const sint32 img_size = width_ * height_;
const sint32 disp_range = max_disparity_ - min_disparity_;
if (img_size <= 0 || disp_range <= 0) {
is_initialized_ = false;
return is_initialized_;
}
// Allocate memory for the cross arm array
vec_cross_arms_.clear();
vec_cross_arms_.resize(img_size);
// Allocate memory for the temporary cost array
vec_cost_tmp_[0].clear();
vec_cost_tmp_[0].resize(img_size);
vec_cost_tmp_[1].clear();
vec_cost_tmp_[1].resize(img_size);
// Allocate memory for the array that stores the number of pixels in each pixel support area
vec_sup_count_[0].clear();
vec_sup_count_[0].resize(img_size);
vec_sup_count_[1].clear();
vec_sup_count_[1].resize(img_size);
vec_sup_count_tmp_.clear();
vec_sup_count_tmp_.resize(img_size);
// Allocate memory for the aggregate cost array
cost_aggr_.resize(img_size * disp_range);
is_initialized_ = !vec_cross_arms_.empty() && !vec_cost_tmp_[0].empty() && !vec_cost_tmp_[1].empty()
&& !vec_sup_count_[0].empty() && !vec_sup_count_[1].empty()
&& !vec_sup_count_tmp_.empty() && !cost_aggr_.empty();
return is_initialized_;
}
There is no need to say more about the previous variable assignment , The main task of initialization is to allocate memory for the cross arm array , Allocate memory for the temporary cost array , And allocate memory for the array storing the number of pixels in each pixel support area .( If you understand the algorithm theory , Then these operations should not be difficult to understand , All for the final calculation of the cost after aggregation ). Besides , The memory of the aggregate cost array is also opened here , And maintained by this class for life .( Maintain the results calculated by yourself , be perfectly logical and reasonable !)
After initialization ,SetData and SetParam Functions are easy to understand , I won't take up space .
When the above preparations are done , We begin to realize the function of cost aggregation .
We can see from the principle that , To complete the cost aggregation , We have to go through two steps :
- Build aggregation areas , That is to build a cross arm
- Perform aggregation
We know that for every pixel , Both have arms in two directions , A horizontal arm , A vertical arm , The constraints of the construction arm are exactly the same , It is divided into distance constraints and color constraints , Simply put, the distance cannot exceed the set threshold , The color difference cannot exceed the set threshold . This is done so that the pixels in the pixel aggregation area are close to their parallax .AD-Census Although it is not simple to calculate the distance and color difference between the pixel and the central pixel in the process of arm extension , But it's not complicated , Just calculate the distance and color difference from the previous pixel in one extension direction , Make the structure more robust . Specific implementation principle , Please read the blog :
I wrote two functions to construct horizontal arm and vertical arm respectively , In fact, except in different directions , The construction method and parameters are the same . Only pixels are posted here ( x , y ) (x,y) (x,y) Construction code of horizontal arm :
void CrossAggregator::FindHorizontalArm(const sint32& x, const sint32& y, uint8& left, uint8& right) const
{
// Pixel data address
const auto img0 = img_left_ + y * width_ * 3 + 3 * x;
// Pixel color value
const ADColor color0(img0[0], img0[1], img0[2]);
left = right = 0;
// Calculate the left and right arms , First left arm then right arm
sint32 dir = -1;
for (sint32 k = 0; k < 2; k++) {
// Extend the arm until the condition is not met
// The arm length shall not exceed cross_L1
auto img = img0 + dir * 3;
auto color_last = color0;
sint32 xn = x + dir;
for (sint32 n = 0; n < std::min(cross_L1_, MAX_ARM_LENGTH); n++) {
// Boundary treatment
if (k == 0) {
if (xn < 0) {
break;
}
}
else {
if (xn == width_) {
break;
}
}
// Get color value
const ADColor color(img[0], img[1], img[2]);
// Color distance 1( The color distance between the pixel on the arm and the calculated pixel )
const sint32 color_dist1 = ColorDist(color, color0);
if (color_dist1 >= cross_t1_) {
break;
}
// Color distance 2( The color distance between the pixel on the arm and the previous pixel )
if (n > 0) {
const sint32 color_dist2 = ColorDist(color, color_last);
if (color_dist2 >= cross_t1_) {
break;
}
}
// Arm length greater than L2 after , The color distance threshold is reduced to t2
if (n + 1 > cross_L2_) {
if (color_dist1 >= cross_t2_) {
break;
}
}
if (k == 0) {
left++;
}
else {
right++;
}
color_last = color;
xn += dir;
img += dir * 3;
}
dir = -dir;
}
}
Find out which two pixels are involved in the distance calculation, and you will almost understand . One is the distance between the new pixel and the central pixel in the process of arm extension ; The second is the distance between the new pixel and the previous pixel .
The construction method of the vertical arm is the same as that of the horizontal arm , It's just in different directions .
Next , We need to calculate the support area of each pixel ( The area covered by the cross arm ) The number of pixels . Why this step ? The reason is that we learned in the principle section , Cost aggregation is to accumulate the cost value of the support area , Divide by the number of pixels in the support area , That is, calculate the average cost of the support area , The generation value assigned to the central pixel .
meanwhile , What we must note is , Different aggregation directions , Support areas are not the same , That is, the aggregation direction of first horizontal and then vertical and the aggregation direction of first vertical and then horizontal , The support areas of the two are different . Therefore, you need to use arrays in two directions to save the number of pixels in the support area . So let's look at the code :
void CrossAggregator::ComputeSupPixelCount()
{
// Calculate the number of pixels in the support area of each pixel
// Be careful : Two different polymerization directions , The pixels in the support area of pixels are different , It needs to be calculated separately
bool horizontal_first = true;
for (sint32 n = 0; n < 2; n++) {
// n=0 : horizontal_first; n=1 : vertical_first
const sint32 id = horizontal_first ? 0 : 1;
for (sint32 k = 0; k < 2; k++) {
// k=0 : pass1; k=1 : pass2
for (sint32 y = 0; y < height_; y++) {
for (sint32 x = 0; x < width_; x++) {
// obtain arm The number
auto& arm = vec_cross_arms_[y*width_ + x];
sint32 count = 0;
if (horizontal_first) {
if (k == 0) {
// horizontal
for (sint32 t = -arm.left; t <= arm.right; t++) {
count++;
}
}
else {
// vertical
for (sint32 t = -arm.top; t <= arm.bottom; t++) {
count += vec_sup_count_tmp_[(y + t)*width_ + x];
}
}
}
else {
if (k == 0) {
// vertical
for (sint32 t = -arm.top; t <= arm.bottom; t++) {
count++;
}
}
else {
// horizontal
for (sint32 t = -arm.left; t <= arm.right; t++) {
count += vec_sup_count_tmp_[y*width_ + x + t];
}
}
}
if (k == 0) {
vec_sup_count_tmp_[y*width_ + x] = count;
}
else {
vec_sup_count_[id][y*width_ + x] = count;
}
}
}
}
horizontal_first = !horizontal_first;
}
}
In the process of calculation , We calculate the number of pixels in the support area by simulating the process of constructing the support area , That is, as stated in the original , First count the number of pixels in the support area in one direction , Stored in a temporary array , Then accumulate the stored values in the temporary array along the arm in the other direction . Because the support areas of the two tectonic directions are different , therefore vec_sup_count_ It's a capacity of 2 Array of , The number of each pixel support area in two construction directions is saved respectively .
Last , We can perform iterative aggregation , The number of iterations is passed in as a parameter , We use one for Loop to complete the iteration , Every iteration , We will convert the construction order of the support area ( Even iterations are constructed horizontally and then vertically , Odd times are constructed vertically and then horizontally ). Then, the algorithm will evaluate each parallax under the candidate parallax d d d Perform independent full graph aggregation ( parallax d 1 d_1 d1 And parallax d 2 d_2 d2 The cost aggregation between is completely independent , Can be highly parallel ).
Let's first look at single parallax d d d Aggregate code implementation under :
void CrossAggregator::AggregateInArms(const sint32& disparity, const bool& horizontal_first)
{
// This function aggregates all pixels when the parallax is disparity The price of
if (disparity < min_disparity_ || disparity >= max_disparity_) {
return;
}
const auto disp = disparity - min_disparity_;
const sint32 disp_range = max_disparity_ - min_disparity_;
if (disp_range <= 0) {
return;
}
// take disp The cost of layer is stored in the temporary array vec_cost_tmp_[0]
// This can avoid too many visits to larger cost_aggr_, Improve access efficiency
for (sint32 y = 0; y < height_; y++) {
for (sint32 x = 0; x < width_; x++) {
vec_cost_tmp_[0][y * width_ + x] = cost_aggr_[y * width_ * disp_range + x * disp_range + disp];
}
}
// Pixel by pixel aggregation
const sint32 ct_id = horizontal_first ? 0 : 1;
for (sint32 k = 0; k < 2; k++) {
// k==0: pass1
// k==1: pass2
for (sint32 y = 0; y < height_; y++) {
for (sint32 x = 0; x < width_; x++) {
// obtain arm The number
auto& arm = vec_cross_arms_[y*width_ + x];
// polymerization
float32 cost = 0.0f;
if (horizontal_first) {
if (k == 0) {
// horizontal
for (sint32 t = -arm.left; t <= arm.right; t++) {
cost += vec_cost_tmp_[0][y * width_ + x + t];
}
} else {
// vertical
for (sint32 t = -arm.top; t <= arm.bottom; t++) {
cost += vec_cost_tmp_[1][(y + t)*width_ + x];
}
}
}
else {
if (k == 0) {
// vertical
for (sint32 t = -arm.top; t <= arm.bottom; t++) {
cost += vec_cost_tmp_[0][(y + t) * width_ + x];
}
} else {
// horizontal
for (sint32 t = -arm.left; t <= arm.right; t++) {
cost += vec_cost_tmp_[1][y*width_ + x + t];
}
}
}
if (k == 0) {
vec_cost_tmp_[1][y*width_ + x] = cost;
}
else {
cost_aggr_[y*width_*disp_range + x*disp_range + disp] = cost / vec_sup_count_[ct_id][y*width_ + x];
}
}
}
}
}
The code follows the original idea , First for each pixel , Add the cost value in a certain direction to the temporary storage array ; Then accumulate the temporarily stored value of the arm spread of each pixel along the other direction , Finally, divide the cumulative value by the number of support areas , Get the final generation value .
In order to speed up , Before aggregation , We take parallax as d d d The initial cost of , Save to a temporary two-dimensional array , In this way, there is no need to frequently access the three-dimensional cost array in the aggregation process , Reduce access time .
Above, we will complete the sub steps of aggregation . The rest of the work is simple , In the public aggregation interface of the class Aggregate in , We only need to call the above sub steps once to complete the aggregation . The code is as follows :
void CrossAggregator::Aggregate(const sint32& num_iters)
{
if (!is_initialized_) {
return;
}
const sint32 disp_range = max_disparity_ - min_disparity_;
// Build a cross arm of pixels
BuildArms();
// Cost aggregation
// horizontal_first Represents the first horizontal convergence
bool horizontal_first = true;
// Calculate the number of pixels in each pixel support area in two aggregation directions
ComputeSupPixelCount();
// First initialize the aggregation cost as the initial cost
memcpy(&cost_aggr_[0], cost_init_, width_*height_*disp_range*sizeof(float32));
// Multi iteration aggregation
for (sint32 k = 0; k < num_iters; k++) {
for (sint32 d = min_disparity_; d < max_disparity_; d++) {
AggregateInArms(d, horizontal_first);
}
// Next iteration , Exchange order
horizontal_first = !horizontal_first;
}
}
The parameter of the function is the number of iterations of the aggregation , The original text is recommended as 4.
Finally, in the main class ADCensusStereo Cost aggregation function CostAggregation in , We call the cost aggregator CrossAggregator Public member functions of complete cost aggregation :
void ADCensusStereo::CostAggregation()
{
// Set aggregator data
aggregator_.SetData(img_left_, img_right_, cost_computer_.get_cost_ptr());
// Set aggregator parameters
aggregator_.SetParams(option_.cross_L1, option_.cross_L2, option_.cross_t1, option_.cross_t2);
// Cost aggregation
aggregator_.Aggregate(4);
}
From complex to simple , It's also C++ One of the characteristics of .
experiment
By convention , We will provide some experimental results .
And last chapter Cost calculation equally , We still use Cone data .
 |  |
The result of cost calculation , I have posted it at the beginning , The experimental results of cost aggregation are as follows :
|  |
One word , miao ! Through cost aggregation , The quality of parallax map has been significantly improved !
Well, that's all for today , The next one is Scan line optimization . Thank you for watching. , Bye-bye !
download AD-Census Complete source code , Click to enter : https://github.com/ethan-li-coding/AD-Census
Welcome to Github Discuss in the project , If you think the blogger's code quality is good , There is a star in the upper right corner ! thank !
About bloggers :
Ethan Li Li Yingsong ( You know : Li Yingsong )
Wuhan University Doctor of photogrammetry and remote sensing
Main direction Stereo matching 、 Three dimensional reconstruction
2019 Won the first prize of scientific and technological progress in surveying and mapping in ( Provincial and ministerial level )
Love 3D , Love sharing , Love open source
GitHub: https://github.com/ethan-li-coding ( welcome follow and star)
Personal wechat :
Welcome to exchange !
Pay attention to bloggers and don't get lost , thank !
Blog home page :https://ethanli.blog.csdn.net

边栏推荐
- An enterprise information integration system
- Business modeling | process of software model
- kubeadm系列-02-kubelet的配置和启动
- Install the CPU version of tensorflow+cuda+cudnn (ultra detailed)
- 资源变现小程序添加折扣充值和折扣影票插件
- Shift operation of complement
- 287. Looking for repeats - fast and slow pointer
- Digital analog 2: integer programming
- Guess riddles (4)
- 特征工程
猜你喜欢

Halcon color recognition_ fuses. hdev:classify fuses by color
![[daiy4] copy of JZ35 complex linked list](/img/bc/ce90bb3cb6f52605255f1d6d6894b0.png)
[daiy4] copy of JZ35 complex linked list
Ros-11 common visualization tools

Programming implementation of subscriber node of ROS learning 3 subscriber
Business modeling of software model | stakeholders

猜谜语啦(142)
The combination of deep learning model and wet experiment is expected to be used for metabolic flux analysis
Programming implementation of ROS learning 5-client node
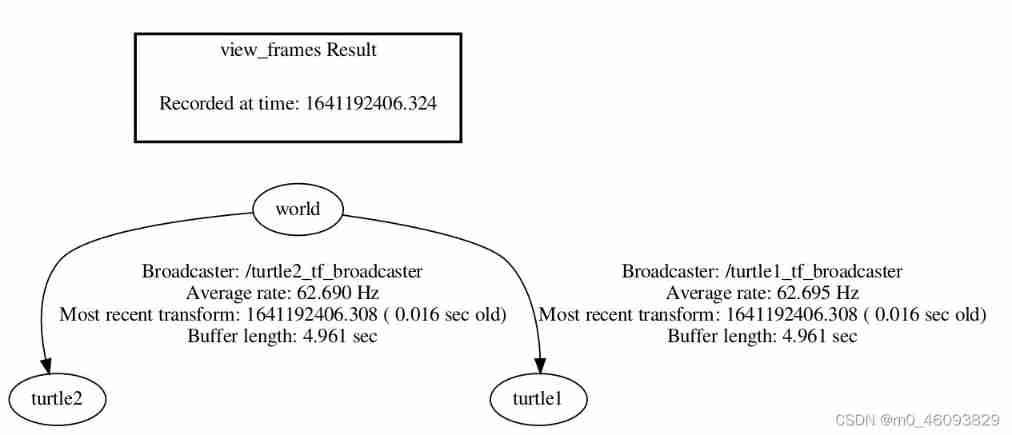
TF coordinate transformation of common components of ros-9 ROS
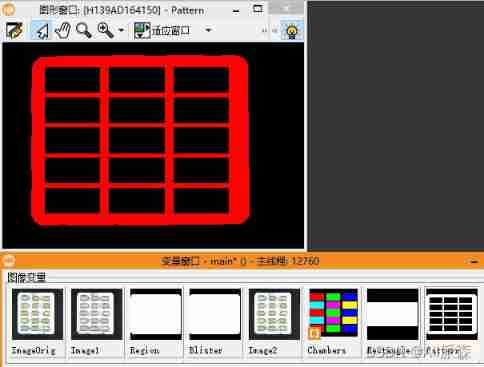
Halcon: check of blob analysis_ Blister capsule detection
随机推荐
C#绘制带控制点的Bezier曲线,用于点阵图像及矢量图形
Basic number theory -- Euler function
Wechat H5 official account to get openid climbing account
Ros-10 roslaunch summary
Infix expression evaluation
287. Looking for repeats - fast and slow pointer
asp.net(c#)的货币格式化
Run menu analysis
ORACLE进阶(三)数据字典详解
An enterprise information integration system
Programming implementation of subscriber node of ROS learning 3 subscriber
The location search property gets the login user name
Business modeling of software model | overview
Codeforces Round #648 (Div. 2) E.Maximum Subsequence Value
图解八道经典指针笔试题
Programming implementation of ROS learning 2 publisher node
Ecmascript6 introduction and environment construction
皮尔森相关系数
ROS learning 1- create workspaces and function packs
Pytorch entry record