当前位置:网站首页>Nips2021 | new SOTA for node classification beyond graphcl, gnn+ comparative learning
Nips2021 | new SOTA for node classification beyond graphcl, gnn+ comparative learning
2022-07-05 09:17:00 【Virgo programmer's friend】
Hello everyone , I'm a dialogue .
Today I will interpret an article NIPS2021 in GNN Papers combined with comparative learning , Later on Continuous updating NIPS2021 About comparative learning (Contrastive Learning) Interpretation of the thesis , Welcome to pay attention ~
This paper is from Purdue University , By introducing confrontation learning as a graph data enhancement method , So as to avoid the problem of poor effect of downstream tasks caused by capturing redundant information during training .

One 、 Abstract
Due to the real world map / Ubiquitous in network data Label scarcity , Therefore, graph neural network is very needed (GNN) Self supervised learning . Figure contrast learning (GCL) Through training GNN To maximize the correspondence between the representations of the same graph in different enhanced forms , Even without labels, it can produce robust and portable GNN. However , By tradition GCL Trained GNN Often take the risk of capturing redundant graph features , So it can be fragile , And the effect is very poor in downstream tasks . ad locum , We have come up with a new method , It is called antagonistic map contrast learning (AD-GCL), It makes GNN Can be optimized GCL To avoid capturing redundant information during training . We will AD-GCL Combined with theoretical explanation , A practical example is designed based on the trainable edge descent graph enhancement . By working with the most advanced GCL Methods compared , We have verified through experiments AD-GCL , stay 18 Among the tasks of different benchmark data sets , In unsupervised learning, up to 14%、 In transfer learning, as high as 6% And in semi supervised learning settings 3% Performance improvement of .

AD-GCL It consists of two components : The first component contains a GNN Encoder , It uses InfoMax To maximize the correspondence between the representation of the original graph and its enhanced graph / Mutual information . The second component contains a component based on GNN The intensifier of , It aims to optimize the enhancement strategy to minimize redundant information in the original diagram . AD-GCL Essentially, the encoder is allowed to capture at least enough information to distinguish the graphics in the data set . We further provide AD-GCL A theoretical explanation of . We show that , By regularizing the search space of the intensifier ,AD-GCL A lower bound guarantee that can generate information related to downstream tasks , At the same time, the upper limit of redundant information in the original graph is guaranteed , This is in line with the information bottleneck (IB) The goal of the principle .
Two 、AD-GCL Theoretical motivation and formulation

equation 3 Medium InfoMax For general representation learning, there may be problems in practice . Tschannen Others have shown that , For image classification , Capturing the representation of information completely unrelated to the image tag can also maximize mutual information , But this representation is absolutely useless for image classification . Similar problems can also be observed in graph representation learning , As shown in the figure below :

We consider data sets ogbg-molbace Binary graph classification of graphs in . Two with exactly the same architecture GNN The encoder is trained to maximize mutual information between the graph representation and the input graph , But at the same time GNN The encoder is further supervised by the random icon . Although supervised by random tags GNN The encoder is still in each input graph with its representation ( That is, maximize mutual information ) Maintain a one-to-one correspondence between , But we may be downstream ground-truth This... Was observed when the label was evaluated GNN Significant performance degradation of encoder .
This observation inspires us to rethink what is good graphic representation . lately , Information bottleneck (IB) It has been applied to learning graph representation . say concretely , Figure information bottleneck (GIB) Our goals are as follows :

InfoMax and GIB The difference between :InfoMax It is required to maximize the information in the original graph , and GIB It is required to minimize such information while maximizing information related to downstream tasks .
Unfortunately ,GIB Need class tags from downstream tasks Y Knowledge , Therefore, it is not applicable to those with little or no labels
GNN Self supervised training . then , The problem is how to learn robust and transferable in a self supervised way GNN.
To solve this problem , We will develop a GCL Method , The method Use adversarial learning to avoid capturing redundant information during presentation learning . Generally speaking ,GCL Methods use graph data to enhance (GDA) Process to disturb the original observed graphs and reduce the amount of information they encode . then , These methods will InfoMax Applied to perturbation graph pairs ( Use different GDA) To train the encoder f To capture the remaining information .
Definition 1: Figure data enhancement (GDA)

AD-GCL: We are GDA Optimize the following objectives

3、 ... and 、 experimental analysis
3.1 Unsupervised learning :

3.2 GDA Model regularization analysis :

3.3 The migration study :
Our assessment is made by AD-GCL Trained GNN Coder predicts chemical molecular properties and biological protein functions in transfer learning . We follow the design Merge Use the same data set :GNN Pre training on a data set using self supervised learning , Then fine tune on another dataset to test out of distribution performance . ad locum , Let's just think about AD-GCL-FIX, because AD-GCL-OPT It will only have better performance . The baseline we used included those without pre training GIN( namely , The first data set was not self supervised , Only fine tuning ),InfoGraph、GraphCL、 Three different pre training strategies include using edges 、 Edge prediction in the context of nodes and subgraphs 、 Node attribute masking and context prediction .

According to the table above , AD-GCL-FIX stay 9 Data sets 3 Data sets are significantly better than the baseline , And here 9 Data sets realize 2.4 The average ranking of , This is better than all baselines . Please note that , Even though AD-GCL On some datasets, only the 5 name , but AD-GCL Still significantly better than InfoGraph and GraphCL, Both are powerful GNN Self training baseline. And InfoGraph and GraphCL comparison , Based on domain knowledge and extensive assessment , AD-GCL It is closer to those baselines (EdgePred、AttrMasking and ContextPred). This is a It's quite important , Because our method only uses edge descent GDA, This shows again AD-GCL The validity of the principle .
3.4 Semi-supervised learning :
Last , We're on the benchmark TU Semi supervised learning evaluation of graph classification on data sets AD-GCL.
GNN Pre training on a data set using self supervised learning , Then based on 10% The label supervision is fine tuned . Again , Let's just think about AD-GCL-FIX And combine it with several baseline Compare :
1) No pre training GCN, It consists directly of 10% Start training from scratch ;
2) SS-GCN-A, A method of introducing more labeled data by creating random enhancement and then training from scratch baseline;
3) A prediction method GAE In the pre training phase, adjacency reconstruction and GCL Method ;
4) InfoGraph;
5) GraphCL;
Please note that , Here we must keep the encoder architecture the same , therefore AD-GCL-FIX use GCN As an encoder .

Four 、 summary
In this work , The author has developed a novel theoretically motivated principle : AD-GCL, It goes beyond the traditional InfoMax The goal is , be used for GNN Self supervised learning . The best that has nothing to do with downstream tasks GNN Encoders are those that capture at least enough information to identify each graph in the dataset . In order to achieve this goal ,AD-GCL It is suggested that graph contrast learning can be better carried out by optimizing graph enhancement in a confrontational way . Experimental results show that ,ADGCL be better than InfoGraph and GraphCL Such powerful GNN Self training baseline.
Finally, I welcome you to pay attention to my WeChat official account : Dialogue algorithm house (duibainotes), track NLP、 Machine learning frontiers such as recommendation system and comparative learning , I will also share my entrepreneurial experience and life sentiment every day . Students who want to further communicate can also add my wechat 「duibai996」 remarks You know +NLP, I'll pull you in 「NLP Frontier algorithm exchange group 」, The discussion atmosphere in the group is very good ~
recommend
Dialogue :R-Drop: The easiest way to improve the performance of supervised tasks
Dialogue : Comparative learning (Contrastive Learning) The latest review
边栏推荐
- 交通运输部、教育部:广泛开展水上交通安全宣传和防溺水安全提醒
- 3D reconstruction open source code summary [keep updated]
- Understanding rotation matrix R from the perspective of base transformation
- 一篇文章带你走进cookie,session,Token的世界
- AUTOSAR from getting started to mastering 100 lectures (103) -dbc file format and creation details
- Kotlin introductory notes (VI) interface and function visibility modifiers
- [beauty of algebra] singular value decomposition (SVD) and its application to linear least squares solution ax=b
- [code practice] [stereo matching series] Classic ad census: (4) cross domain cost aggregation
- 2020 "Lenovo Cup" National College programming online Invitational Competition and the third Shanghai University of technology programming competition
- Applet network data request
猜你喜欢
Shutter uses overlay to realize global pop-up
![C [essential skills] use of configurationmanager class (use of file app.config)](/img/8b/e56f87c2d0fbbb1251ec01b99204a1.png)
C [essential skills] use of configurationmanager class (use of file app.config)
The combination of deep learning model and wet experiment is expected to be used for metabolic flux analysis
C form click event did not respond
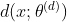
Generate confrontation network
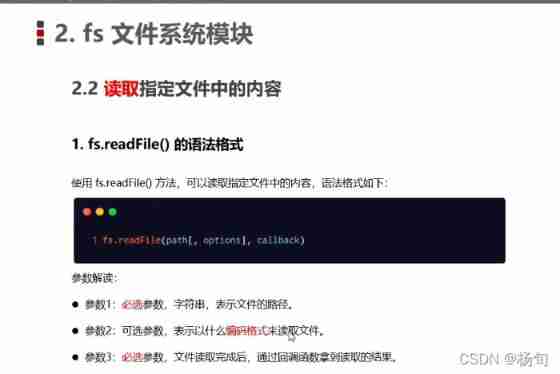
nodejs_ 01_ fs. readFile
![[code practice] [stereo matching series] Classic ad census: (5) scan line optimization](/img/54/cb1373fbe7b21c5383580e8b638a2c.jpg)
[code practice] [stereo matching series] Classic ad census: (5) scan line optimization
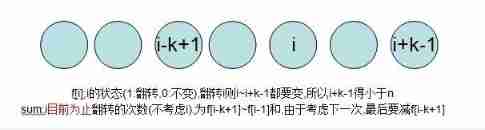
Summary of "reversal" problem in challenge Programming Competition
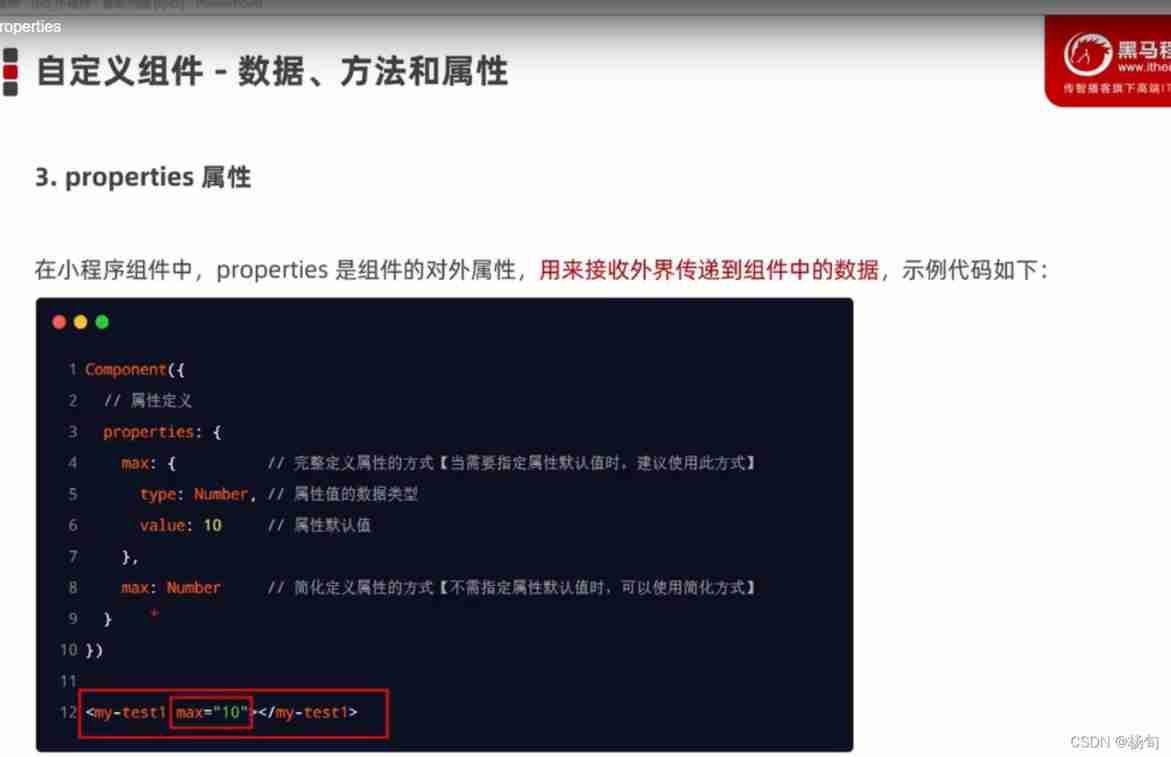
Applet data attribute method

Blogger article navigation (classified, real-time update, permanent top)
随机推荐
c语言指针深入理解
太不好用了,长文章加图文,今后只写小短文
Applet global style configuration window
阿里云发送短信验证码
Solution to the problems of the 17th Zhejiang University City College Program Design Competition (synchronized competition)
Progressive JPEG pictures and related
[code practice] [stereo matching series] Classic ad census: (4) cross domain cost aggregation
Ministry of transport and Ministry of Education: widely carry out water traffic safety publicity and drowning prevention safety reminders
Introduction Guide to stereo vision (7): stereo matching
生成对抗网络
520 diamond Championship 7-4 7-7 solution
Solution to the problem of the 10th Programming Competition (synchronized competition) of Harbin University of technology "Colin Minglun Cup"
Using request headers to develop multi terminal applications
Summary and Reflection on issues related to seq2seq, attention and transformer in hands-on deep learning
Transfer learning and domain adaptation
Mengxin summary of LCs (longest identical subsequence) topics
Codeforces Round #648 (Div. 2) E.Maximum Subsequence Value
C # compare the differences between the two images
12. Dynamic link library, DLL
混淆矩阵(Confusion Matrix)