当前位置:网站首页>Apache DolphinScheduler 系统架构设计
Apache DolphinScheduler 系统架构设计
2022-07-05 09:33:00 【杨林伟】
文章目录
01 引言
本文为
Apache DolphinScheduler官网的阅读笔记,原文地址:https://dolphinscheduler.apache.org/
在前面的博文《Apache DolphinScheduler 入门(一篇就够了)》大致讲了DolphinScheduler的一些概念,有了一个入门的概念。本文主要讲的是DolphinScheduler的系统架构设计。
本文开始讲解前,需要了解一些基础的概念:
- DAG: 全称Directed Acyclic Graph,简称DAG。工作流中的Task任务以有向无环图的形式组装起来,从入度为零的节点进行拓扑遍历,直到无后继节点为止。举例如下图:
- 流程定义:通过拖拽任务节点并建立任务节点的关联所形成的可视化DAG
- 流程实例:流程实例是流程定义的实例化,可以通过手动启动或定时调度生成,流程定义每运行一次,产生一个流程实例
- 任务实例:任务实例是流程定义中任务节点的实例化,标识着具体的任务执行状态
- 任务类型: 目前支持有SHELL、SQL、SUB_PROCESS(子流程)、PROCEDURE、MR、SPARK、PYTHON、DEPENDENT(依赖),同时计划支持动态插件扩展,注意:其中子 SUB_PROCESS 也是一个单独的流程定义,是可以单独启动执行的
- 调度方式: 系统支持基于cron表达式的定时调度和手动调度。命令类型支持:启动工作流、从当前节点开始执行、恢复被容错的工作流、恢复暂停流程、从失败节点开始执行、补数、定时、重跑、暂停、停止、恢复等待线程。其中 恢复被容错的工作流 和 恢复等待线程 两种命令类型是由调度内部控制使用,外部无法调用
- 定时调度:系统采用 quartz 分布式调度器,并同时支持cron表达式可视化的生成
- 依赖:系统不单单支持 DAG 简单的前驱和后继节点之间的依赖,同时还提供任务依赖节点,支持流程间的自定义任务依赖
- 优先级 :支持流程实例和任务实例的优先级,如果流程实例和任务实例的优先级不设置,则默认是先进先出
- 邮件告警:支持 SQL任务 查询结果邮件发送,流程实例运行结果邮件告警及容错告警通知
- 失败策略:对于并行运行的任务,如果有任务失败,提供两种失败策略处理方式,继续是指不管并行运行任务的状态,直到流程失败结束。结束是指一旦发现失败任务,则同时Kill掉正在运行的并行任务,流程失败结束
- 补数:补历史数据,支持区间并行和串行两种补数方式
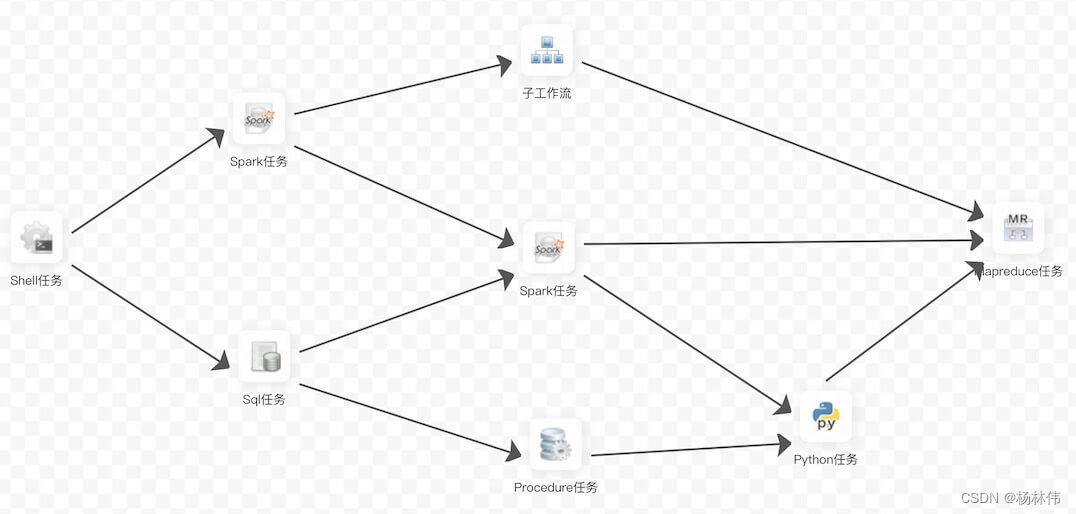
02 系统架构
2.1 MasterServer
MasterServer采用分布式无中心设计理念,MasterServer主要负责 DAG 任务切分、任务提交监控,并同时监听其它MasterServer和WorkerServer的健康状态。
MasterServer服务启动时向Zookeeper注册临时节点,通过监听Zookeeper临时节点变化来进行容错处理。
该服务内主要包含:
- Distributed Quartz分布式调度组件,主要负责定时任务的启停操作,当quartz调起任务后,Master内部会有线程池具体负责处理任务的后续操作
- MasterSchedulerThread是一个扫描线程,定时扫描数据库中的 command 表,根据不同的命令类型进行不同的业务操作
- MasterExecThread主要是负责DAG任务切分、任务提交监控、各种不同命令类型的逻辑处理
- MasterTaskExecThread主要负责任务的持久化
2.2 WorkerServer
WorkerServer也采用分布式无中心设计理念,WorkerServer主要负责任务的执行和提供日志服务。WorkerServer服务启动时向Zookeeper注册临时节点,并维持心跳。
该服务包含:
- FetchTaskThread主要负责不断从Task Queue中领取任务,并根据不同任务类型调用TaskScheduleThread对应执行器。
- LoggerServer是一个RPC服务,提供日志分片查看、刷新和下载等功能
2.3 ZooKeeper
ZooKeeper服务,系统中的MasterServer和WorkerServer节点都通过ZooKeeper来进行集群管理和容错。另外系统还基于ZooKeeper进行事件监听和分布式锁。 我们也曾经基于Redis实现过队列,不过我们希望EasyScheduler依赖到的组件尽量地少,所以最后还是去掉了Redis实现。
2.4 Task Queue
提供任务队列的操作,目前队列也是基于Zookeeper来实现。由于队列中存的信息较少,不必担心队列里数据过多的情况,实际上我们压测过百万级数据存队列,对系统稳定性和性能没影响。
2.5 Alert
提供告警相关接口,接口主要包括告警两种类型的告警数据的存储、查询和通知功能。其中通知功能又有邮件通知和 SNMP(暂未实现) 两种。
2.6 API
API接口层,主要负责处理前端UI层的请求。该服务统一提供RESTful api向外部提供请求服务。 接口包括工作流的创建、定义、查询、修改、发布、下线、手工启动、停止、暂停、恢复、从该节点开始执行等等。
2.7 UI
系统的前端页面,提供系统的各种可视化操作界面,详见 [功能介绍] 部分。
04 架构思想
4.1 中心化思想
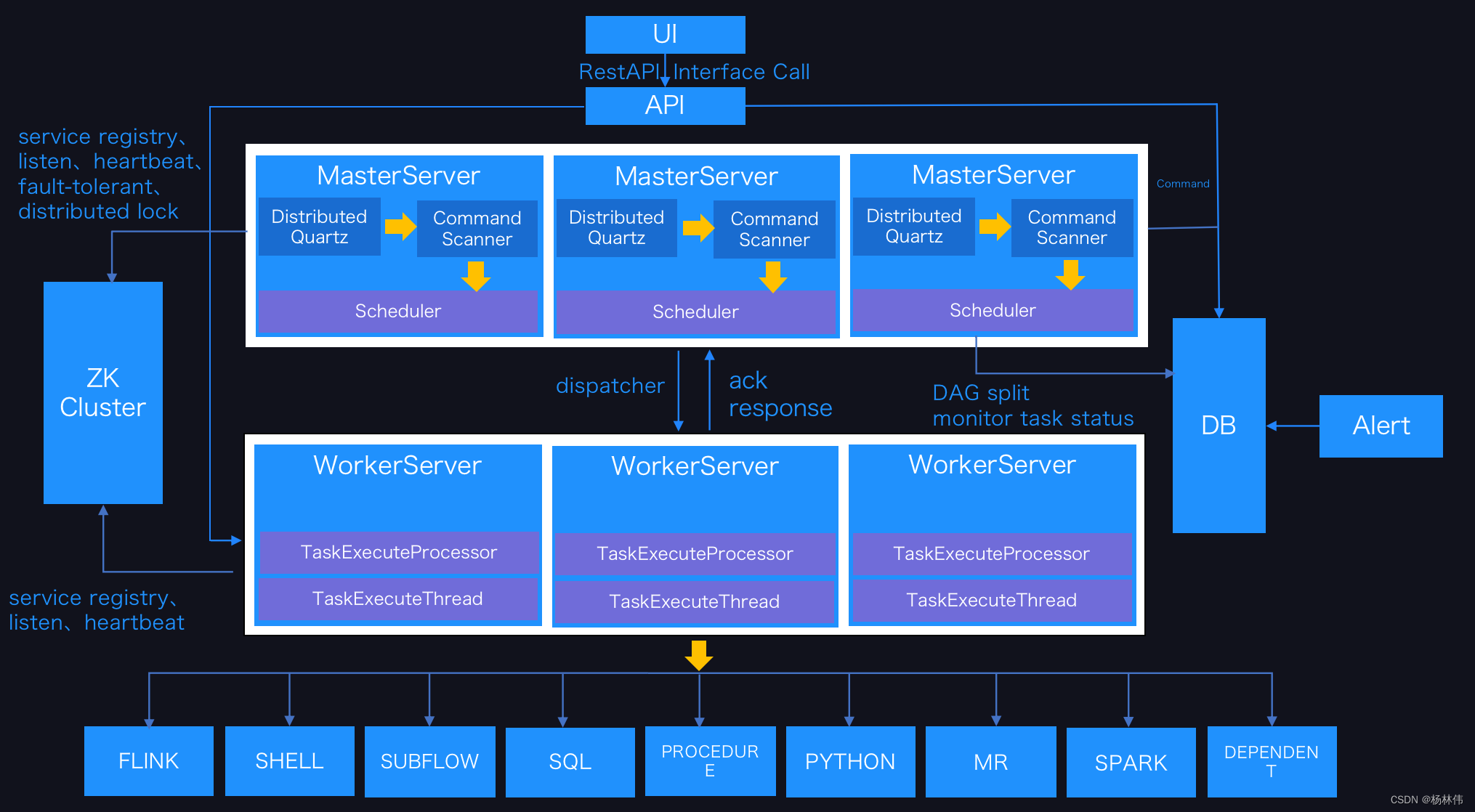
中心化的设计理念比较简单,分布式集群中的节点按照角色分工,大体上分为两种角色:
- Master的角色主要负责任务分发并监督Slave的健康状态,可以动态的将任务均衡到Slave上,以致Slave节点不至于“忙死”或”闲死”的状态。
- Worker的角色主要负责任务的执行工作并维护和Master的心跳,以便Master可以分配任务给Slave。
中心化思想设计存在的问题:
- 一旦Master出现了问题,则群龙无首,整个集群就会崩溃。为了解决这个问题,大多数Master/Slave架构模式都采用了主备Master的设计方案,可以是热备或者冷备,也可以是自动切换或手动切换,而且越来越多的新系统都开始具备自动选举切换Master的能力,以提升系统的可用性。
- 另外一个问题是如果Scheduler在Master上,虽然可以支持一个DAG中不同的任务运行在不同的机器上,但是会产生Master的过负载。如果Scheduler在Slave上,则一个DAG中所有的任务都只能在某一台机器上进行作业提交,则并行任务比较多的时候,Slave的压力可能会比较大。
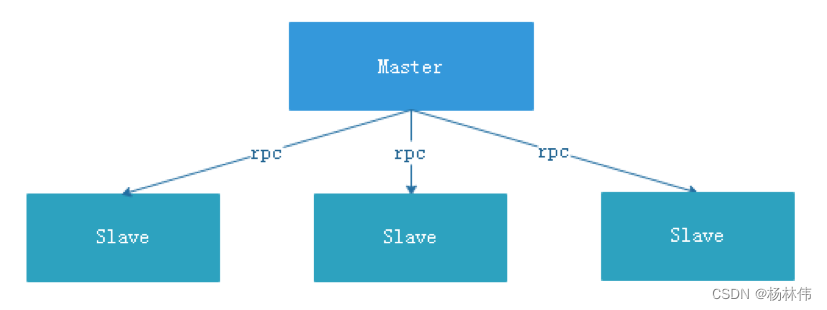
4.2 去中心化思想
在去中心化设计里,通常没有Master/Slave的概念,所有的角色都是一样的,地位是平等的,全球互联网就是一个典型的去中心化的分布式系统,联网的任意节点设备down机,都只会影响很小范围的功能。
去中心化设计的核心设计在于整个分布式系统中不存在一个区别于其他节点的”管理者”,因此不存在单点故障问题。但由于不存在” 管理者”节点所以每个节点都需要跟其他节点通信才得到必须要的机器信息,而分布式系统通信的不可靠行,则大大增加了上述功能的实现难度。
实际上,真正去中心化的分布式系统并不多见。反而动态中心化分布式系统正在不断涌出。在这种架构下,集群中的管理者是被动态选择出来的,而不是预置的,并且集群在发生故障的时候,集群的节点会自发的举行"会议"来选举新的"管理者"去主持工作。最典型的案例就是ZooKeeper及Go语言实现的Etcd。
EasyScheduler的去中心化是Master/Worker注册到Zookeeper中,实现Master集群和Worker集群无中心,并使用Zookeeper分布式锁来选举其中的一台Master或Worker为“管理者”来执行任务。
4.3 分布式锁实践
EasyScheduler使用ZooKeeper分布式锁来实现同一时刻只有一台Master执行Scheduler,或者只有一台Worker执行任务的提交。
获取分布式锁的核心流程算法如下: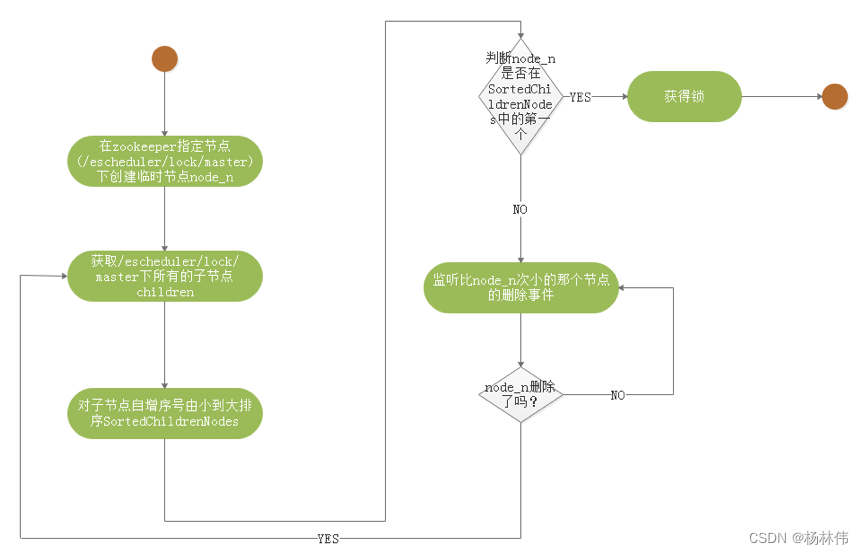
EasyScheduler中Scheduler线程分布式锁实现流程图: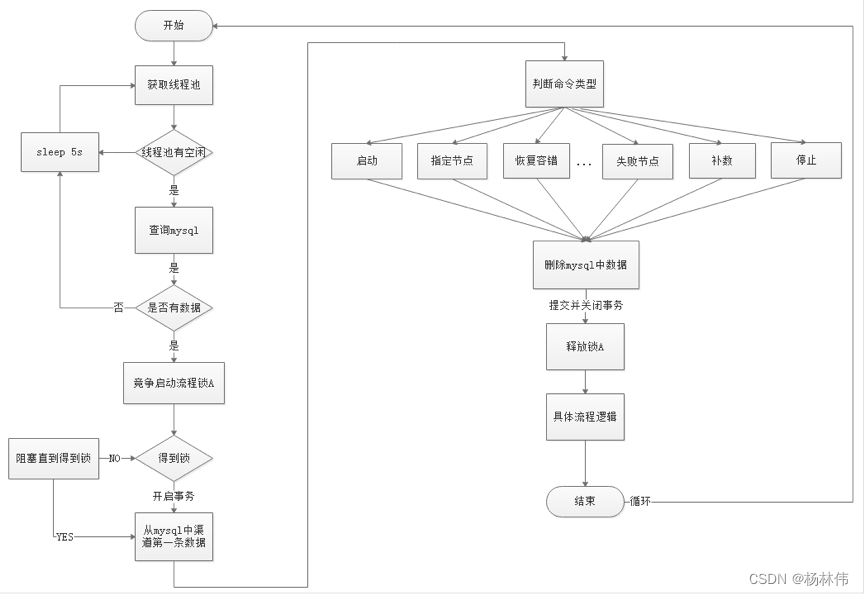
4.4 线程不足循环等待问题
如果一个DAG中没有子流程,则如果Command中的数据条数大于线程池设置的阈值,则直接流程等待或失败。
如果一个大的DAG中嵌套了很多子流程,如下图则会产生“死等”状态: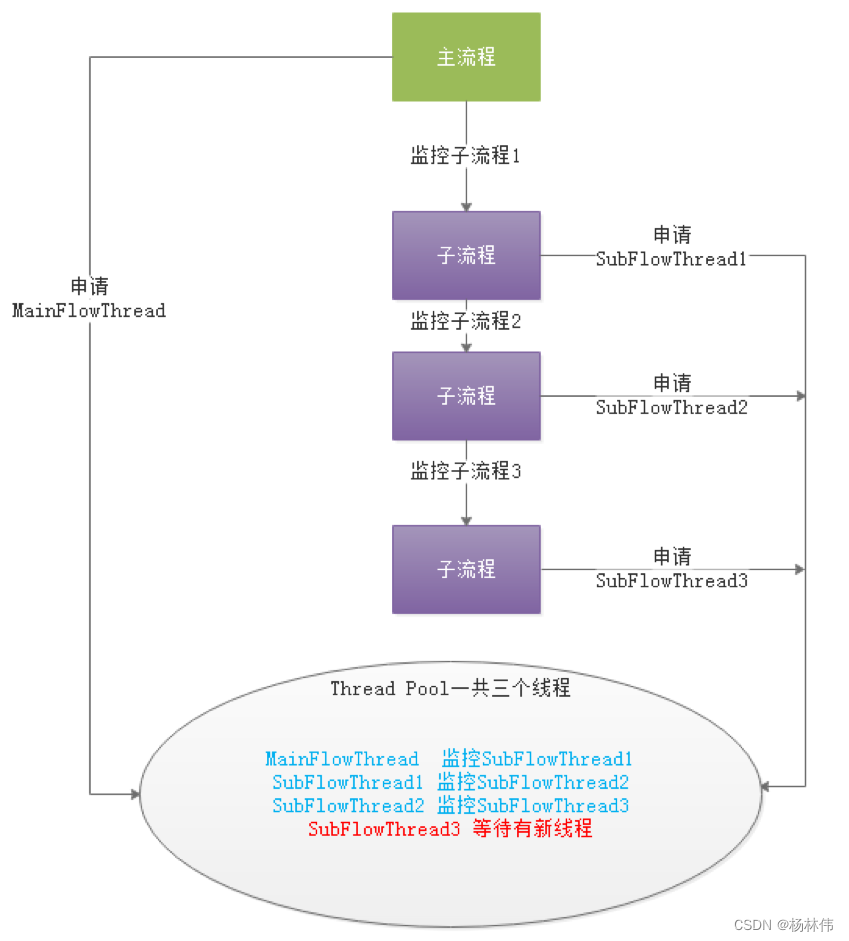
上图中MainFlowThread等待SubFlowThread1结束,SubFlowThread1等待SubFlowThread2结束, SubFlowThread2等待SubFlowThread3结束,而SubFlowThread3等待线程池有新线程,则整个DAG流程不能结束,从而其中的线程也不能释放。这样就形成的子父流程循环等待的状态。此时除非启动新的Master来增加线程来打破这样的”僵局”,否则调度集群将不能再使用。
对于启动新Master来打破僵局,似乎有点差强人意,于是我们提出了以下三种方案来降低这种风险:
- 计算所有Master的线程总和,然后对每一个DAG需要计算其需要的线程数,也就是在DAG流程执行之前做预计算。因为是多Master线程池,所以总线程数不太可能实时获取。
- 对单Master线程池进行判断,如果线程池已经满了,则让线程直接失败。
- 增加一种资源不足的Command类型,如果线程池不足,则将主流程挂起。这样线程池就有了新的线程,可以让资源不足挂起的流程重新唤醒执行。
注意:Master Scheduler线程在获取Command的时候是FIFO的方式执行的。
于是我们选择了第三种方式来解决线程不足的问题。
4.5 容错设计
容错分为服务宕机容错和任务重试,服务宕机容错又分为Master容错和Worker容错两种情况
4.5.1 宕机容错
服务容错设计依赖于ZooKeeper的Watcher机制,实现原理如图: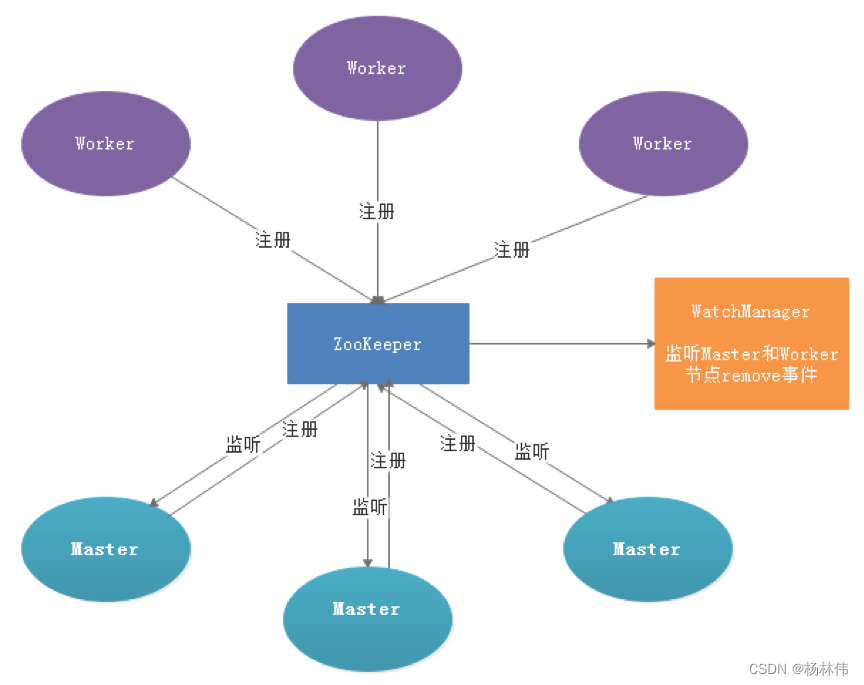
其中Master监控其他Master和Worker的目录,如果监听到remove事件,则会根据具体的业务逻辑进行流程实例容错或者任务实例容错。
Master容错流程图: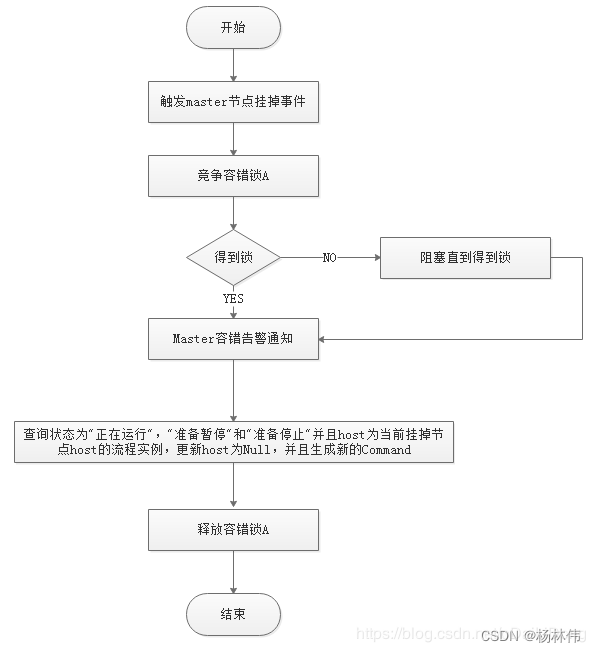
ZooKeeper Master容错完成之后则重新由EasyScheduler中Scheduler线程调度,遍历 DAG 找到”正在运行”和“提交成功”的任务,对”正在运行”的任务监控其任务实例的状态,对”提交成功”的任务需要判断Task Queue中是否已经存在,如果存在则同样监控任务实例的状态,如果不存在则重新提交任务实例。
Worker容错流程图: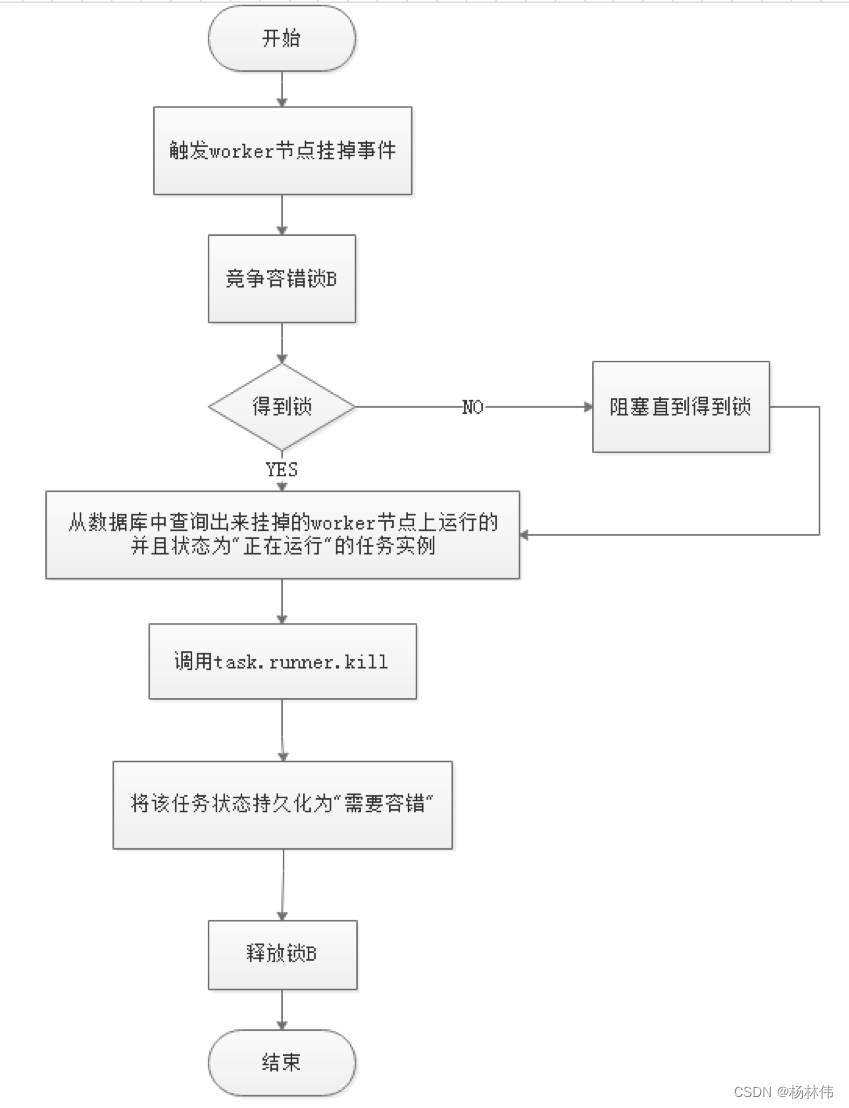
Master Scheduler线程一旦发现任务实例为” 需要容错”状态,则接管任务并进行重新提交。
注意:由于” 网络抖动”可能会使得节点短时间内失去和ZooKeeper的心跳,从而发生节点的remove事件。对于这种情况,我们使用最简单的方式,那就是节点一旦和ZooKeeper发生超时连接,则直接将Master或Worker服务停掉。
4.5.2 任务失败重试
这里首先要区分任务失败重试、流程失败恢复、流程失败重跑的概念:
- 任务失败重试是任务级别的,是调度系统自动进行的,比如一个Shell任务设置重试次数为3次,那么在Shell任务运行失败后会自己再最多尝试运行3次
- 流程失败恢复是流程级别的,是手动进行的,恢复是从只能从失败的节点开始执行或从当前节点开始执行
- 流程失败重跑也是流程级别的,是手动进行的,重跑是从开始节点进行
接下来说正题,我们将工作流中的任务节点分了两种类型。
- 一种是业务节点,这种节点都对应一个实际的脚本或者处理语句,比如Shell节点,MR节点、Spark节点、依赖节点等。
- 还有一种是逻辑节点,这种节点不做实际的脚本或语句处理,只是整个流程流转的逻辑处理,比如子流程节等。
每一个业务节点都可以配置失败重试的次数,当该任务节点失败,会自动重试,直到成功或者超过配置的重试次数。逻辑节点不支持失败重试。但是逻辑节点里的任务支持重试。
如果工作流中有任务失败达到最大重试次数,工作流就会失败停止,失败的工作流可以手动进行重跑操作或者流程恢复操作
5. 任务优先级设计
的任务同时完成的情况,而不能做到设置流程或者任务的优先级,因此我们对此进行了重新设计,目前我们设计如下:
按照不同流程实例优先级优先于同一个流程实例优先级优先于同一流程内任务优先级优先于同一流程内任务提交顺序依次从高到低进行任务处理。
具体实现是根据任务实例的json解析优先级,然后把流程实例优先级_流程实例id_任务优先级_任务id信息保存在ZooKeeper任务队列中,当从任务队列获取的时候,通过字符串比较即可得出最需要优先执行的任务
其中流程定义的优先级是考虑到有些流程需要先于其他流程进行处理,这个可以在流程启动或者定时启动时配置,共有5级,依次为HIGHEST、HIGH、MEDIUM、LOW、LOWEST。如下图

任务的优先级也分为5级,依次为HIGHEST、HIGH、MEDIUM、LOW、LOWEST。如下图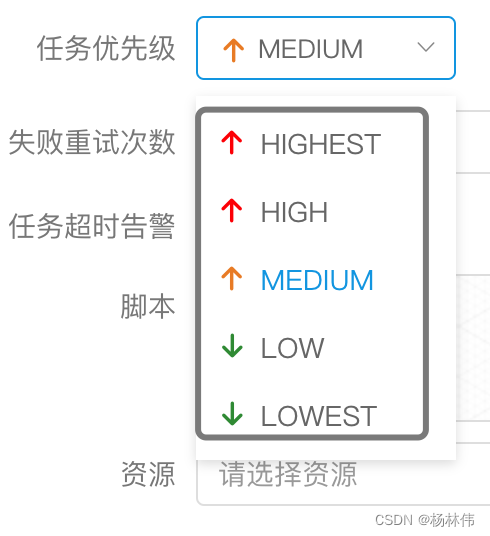
6. Logback和gRPC实现日志访问
由于Web(UI)和Worker不一定在同一台机器上,所以查看日志不能像查询本地文件那样。有两种方案:
将日志放到ES搜索引擎上
通过gRPC通信获取远程日志信息
介于考虑到尽可能的EasyScheduler的轻量级性,所以选择了gRPC实现远程访问日志信息。
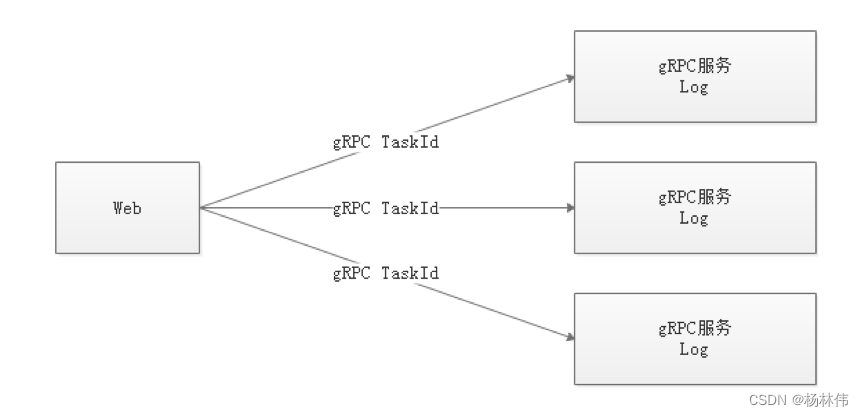
我们使用自定义Logback的FileAppender和Filter功能,实现每个任务实例生成一个日志文件。
FileAppender主要实现如下:
/** * task log appender */
public class TaskLogAppender extends FileAppender<ILoggingEvent> {
...
@Override
protected void append(ILoggingEvent event) {
if (currentlyActiveFile == null){
currentlyActiveFile = getFile();
}
String activeFile = currentlyActiveFile;
// thread name: taskThreadName-processDefineId_processInstanceId_taskInstanceId
String threadName = event.getThreadName();
String[] threadNameArr = threadName.split("-");
// logId = processDefineId_processInstanceId_taskInstanceId
String logId = threadNameArr[1];
...
super.subAppend(event);
}
}
以/流程定义id/流程实例id/任务实例id.log的形式生成日志
过滤匹配以TaskLogInfo开始的线程名称:
TaskLogFilter实现如下:
/** * task log filter */
public class TaskLogFilter extends Filter<ILoggingEvent> {
@Override
public FilterReply decide(ILoggingEvent event) {
if (event.getThreadName().startsWith("TaskLogInfo-")){
return FilterReply.ACCEPT;
}
return FilterReply.DENY;
}
}
边栏推荐
- Principle and performance analysis of lepton lossless compression
- Uncover the practice of Baidu intelligent testing in the field of automatic test execution
- MySQL installation configuration and creation of databases and tables
- Charm of code language
- Solve the problem of no all pattern found during Navicat activation and registration
- Small program startup performance optimization practice
- TDengine × Intel edge insight software package accelerates the digital transformation of traditional industries
- Tdengine can read and write through dataX, a data synchronization tool
- 【el-table如何禁用】
- 项目实战 | Excel导出功能
猜你喜欢

卷起来,突破35岁焦虑,动画演示CPU记录函数调用过程
Node の MongoDB Driver

What are the advantages of the live teaching system to improve learning quickly?
SQL learning - case when then else
植物大战僵尸Scratch
First understanding of structure

How to improve the operation efficiency of intra city distribution
Why don't you recommend using products like mongodb to replace time series databases?

mysql安装配置以及创建数据库和表
百度APP 基于Pipeline as Code的持续集成实践
随机推荐
测试老鸟浅谈unittest和pytest的区别
LeetCode 496. Next larger element I
uni-app---uni. Navigateto jump parameter use
OpenGL - Coordinate Systems
Understanding of smt32h7 series DMA and DMAMUX
如何正确的评测视频画质
Why don't you recommend using products like mongodb to replace time series databases?
Alibaba's ten-year test brings you into the world of APP testing
TDengine 离线升级流程
What about wechat mall? 5 tips to clear your mind
22-07-04 Xi'an Shanghao housing project experience summary (01)
分布式数据库下子查询和 Join 等复杂 SQL 如何实现?
The most comprehensive promotion strategy: online and offline promotion methods of E-commerce mall
MySQL does not take effect in sorting string types
Tdengine offline upgrade process
百度交易中台之钱包系统架构浅析
A keepalived high availability accident made me learn it again
百度APP 基于Pipeline as Code的持续集成实践
Online chain offline integrated chain store e-commerce solution
Node の MongoDB Driver