当前位置:网站首页>百度交易中台之钱包系统架构浅析
百度交易中台之钱包系统架构浅析
2022-07-05 09:27:00 【百度Geek说】

导读:百度APP内含有现金、活动、虚拟等多类资产信息,分布于百度APP内各个业务线中,用户回访信息难度较高,且用户对百度资产认知度不高。我的钱包建立后,汇聚百度APP内所有用户资产信息,解决了用户回访难的问题,建立用户百度APP资产认知。本文主要介绍了钱包从0到1的搭建过程、遇到的各种问题以及相应的解决方案,旨在抛砖引玉,希望能给读者带来思考和帮助。
全文6082字,预计阅读时间16分钟
一、背景
百度APP坐拥日活2亿+、月活6亿+用户,在百度APP内每时每刻都产生了众多用户的资产信息。当前,百度APP内含有现金资产、活动资产、虚拟资产等多类资产信息,分布于百度APP内各个业务线中。每个业务线提供用户独立的资产信息,业务线间关联性较低,用户回访信息难度较高,不利于形成用户对百度APP资产信息的整体认知。亟需一个系统,能够汇聚百度APP内所有用户资产信息,支持用户资产信息统一汇总、展示,收拢用户回访入口,建立用户百度APP资产认知,提升百度APP用户体验,我的钱包应运而生。
二、业务介绍
百度APP个人中心里我的钱包,主要收拢了百度用户的资产信息,进行统一的管理、展示,同时收拢各个业务线资产查看、使用等能力的入口,便于用户快速回访、找到个人的资产信息。钱包在百度APP个人中心外露四个金刚位和钱包入口地址,四个金刚位支持配置,运营人员可根据不同时期的活动、营销等配置不同外露业务方,便于用户快捷回访。同时四个金刚位支持业务数据外露展示,使用户直观感知个人的资产信息。
在钱包入口点击后,可进入钱包首页。首页中主要外露用户的现金、提现活动、返现、卡券、虚拟币、快捷入口等信息,同时支持运营配置营销、活动。对于现金余额信息,我们需要用户授权,用户授权后查询用户在度小满、百度闪付的余额,进入明细页面后,可分别进行授权、查看明细。针对活动提现金额,钱包推动百度APP内所有涉及提现金额的业务接入钱包,统一进行管理,支持用户查看金额明细,其中金额明细中包含两个部分,一部分是明确返回用户余额信息的业务,支持用户点击跳转至具体业务方查看明细,另一部分是汇总百度提现中心全部业务,支持用户点击跳转,建立用户现金余额统一管理、访问的认知。对于虚拟币数据,可根据用户各个虚拟币余额数量进行动态展示,便于用户快速知晓自己的虚拟币信息,点击具体虚拟币时,支持跳转至业务方明细页面进行查看明细、充值等操作,也支持跳转至钱包统一虚拟币明细列表,查看用户明细、月度汇总等信息。对于业务方接入,钱包提供多种接入方式:API数据同步、实时查询、配置跳转,业务方可根据自己实际情况进行选择。
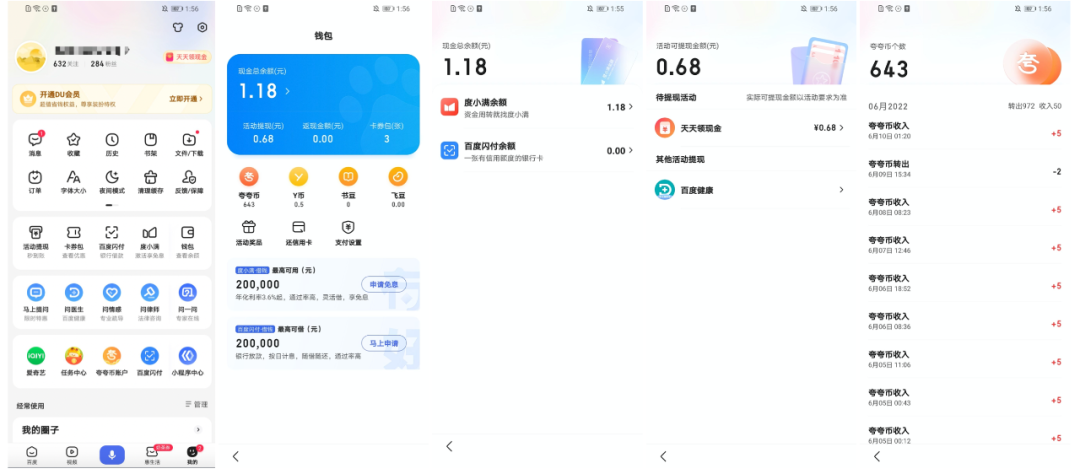
△图2-1 钱包展示
三、系统业务架构
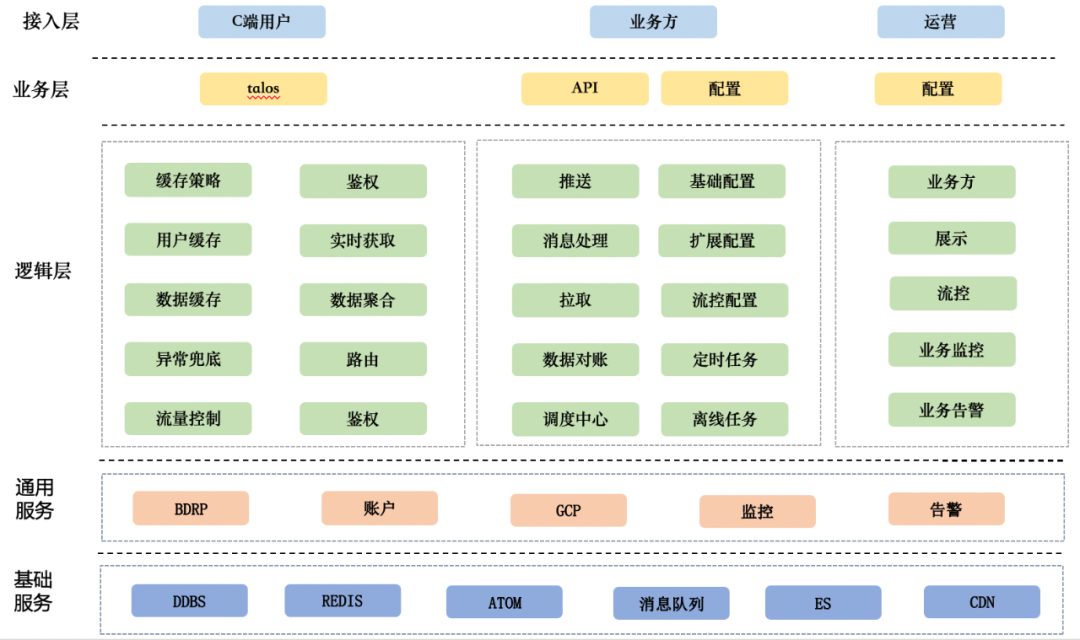
△图3-1 钱包业务架构图
钱包的整体系统业务架构如上图3-1所示,钱包服务主要面向C端用户、业务接入方、运营人员。针对C端用户,钱包提供百度APP个人中心一级入口和钱包首页两个核心入口,前端使用talos框架实现。用户通过个人中心入口访问到达逻辑层后,首先判断用户是否命中用户缓存,该缓存用来标识用户是否有资产,如果命中缓存且有资产,则读取数据缓存返回数据。用户通过钱包首页进入钱包,根据访问的模块,路由适配器根据配置规则,选择不同数据规则进行数据加载、获取,数据获取后按规则进行聚合返回。为了防止服务异常时影响页面渲染,提供异常兜底方案,业务方接口异常时使用缓存数据兜底,内部异常时统一返回兜底文案。
针对不同的业务方,我们提供多种接入方式,对一个人中心一级入口外露业务,我们提供推送、拉取机制,即业务方在用户数据变更时同步钱包,钱包准时拉取用户最新数据;对于钱包首页、列表页业务,我们提供实时查询方式,对于利用钱包给业务内导流的业务,我们支持H5、scheme、talos、端内等多种跳转能力。配置主要包括基础配置、扩展配置、流控配置, 实现不同的适配器供上游调用。
运营人员可使用B端运营工具,配置、修改接入的业务方信息,也可以管理钱包首页展示、运营活动、营销等,同时亦可配置相关的流控、监控等信息。底层服务,我们使用了百度内通用的数据库、Redis、消息队列、CDN等基础服务,该基础服务由统一的部门运维,稳定性比较可靠。
四、技术细节
1、资产数据同步
钱包搭建,面临着一个棘手的问题:百度APP内资产信息分布在不同业务线,信息间互相隔离,系统异构。如果推动业务方直接暴露API查询数据,则需要业务方接口达到钱包要求的高QPS、底平响、高稳定性,同时业务线内可能存在一些特殊情况,再加上节假日、活动等特殊时期流量突增,会严重影响钱包数据展示,进而影响用户体验。存在部分业务方用户量级较小,但必须得提供符合钱包需要的性能,这就对业务方带来额外压力。如果要求所有业务方将全量数据同步至钱包,又面临业务线数据推送、钱包海量数据存储、数据准确性对账等问题。
针对如上一系列问题,我们确定了接入钱包的原则:①在个人中心破壳展示位外露的业务方,必须将资产数据同步至钱包,钱包服务内部确保接口可用性和降级方案;②钱包首页展示数据,支持业务方选择是否将数据同步至钱包,如果不同步数据,需要提供满足QPS、平响等要求的API供钱包调用;③钱包二级页面、三级页面数据,需业务方提供查询API或者落地页,实时查询业务方数据进行展示,确保明细数据准确无误。
1.1 数据同步
对于业务方同步的用户资产数据,我们只存储用户的最新数据,考虑数据量级问题,钱包不存储历史快照。钱包定义业务方数据推送的接口规范,业务方在数据更新时,需及时通知钱包拉取最新数据。为了防止业务方推送数据时流量突增对钱包sever的影响以及提高钱包server的吞吐,引入消息队列进行削锋,即接到业务方资产数据变更请求时,放入消息队列后返回业务方通知成功,钱包server内消费队列消息,根据配置信息向业务方拉取最新数据进行更新。对于用户资产明细数据,钱包定义接口规范,业务方实现后将调用地址提供给钱包,钱包进行配置,用户访问时实时调用。
于是,我们设计了如下的数据同步方案:
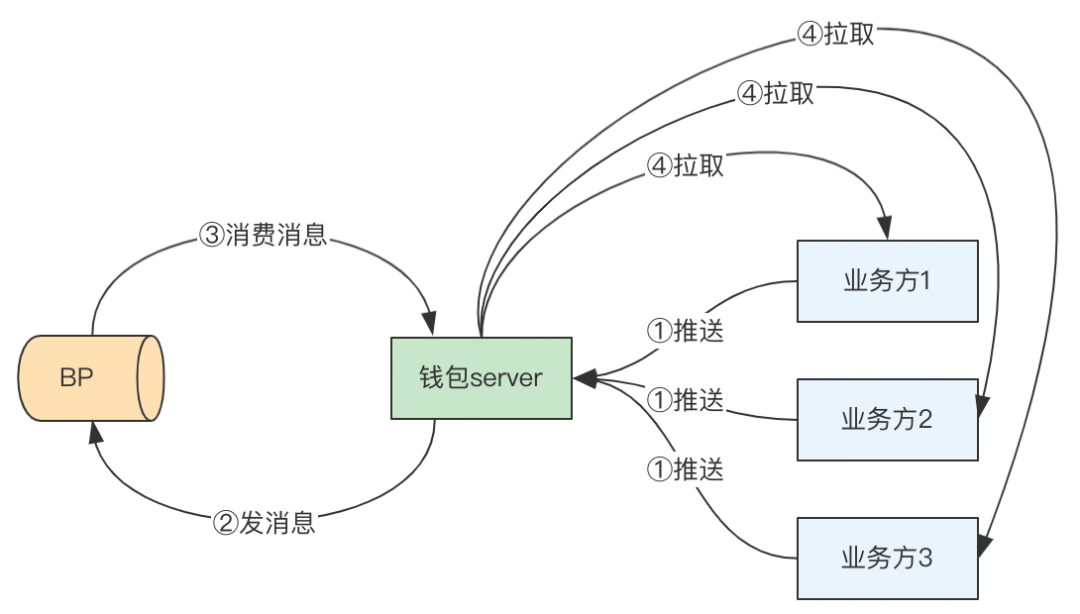
△图4-1 业务方数据同步
①用户资产变更时,业务方调用钱包接口通知信息变更;
②钱包接到通知后,放入消息队列;
③消费任务获取消息队列中消息进行消费处理;
④根据配置,拉取业务方最新信息,更新至钱包存储;
在消费消息时,钱包server进行批量处理,针对一定时间内同一业务方同一用户信息,只拉取一次数据,减少对业务方服务压力。遇到异常时,会进行3次重试拉取。钱包server控制是否拉取、流控,在下游业务方服务异常时,可及时停止拉取、降低拉取流量,减少或者去除下游系统对钱包的影响。
1.2 实时查询
针对部分业务方不推送数据,我们定义接口规范,业务方进行实现,实现后上报钱包配置调用方式。对于此类业务方,不允许配置到个人中心展示,防止业务方接口性能不达标拖累整体用户体验。实时查询接口主要分为余额、分页明细接口,钱包统一format后进行展示。余额接口查询返回后,异步写入Redis进行缓存,用于下次访问业务接口异常时进行兜底展示,如果后续访问业务接口正常,则使用最新数据更新Redis数据。
用户明细分页数据包含分页明细数据和月度汇总数据(月度总收入与总支出),钱包调用下游拆分成两个接口:分页明细接口和月度汇总接口,提供给前端展示页面封装成一个接口,降低前端交互复杂度。调用下游分页接口实时返回用户明细分页数据,月度汇总接口返回用户当前明细所属月份的汇总数据。钱包服务内部根据业务方明细分页接口数据进行汇总,为了减少请求业务方次数,钱包内部判断分页数据,如果返回数据都是同一月份,则只请求业务方一次月度汇总接口,后续分页不再请求,如果返回数据分散在两个月份,则请求业务方月度接口两次,如果返回数据分散在三个月份(含)以上,则只请求起止两个月份的月度数据,中间月份数据由钱包根据明细数据内部计算。
2、多级缓存
百度登录账号体系中,用户id已超过数十亿,存在资产的用户接近亿级,同时钱包会在百度APP个人中心破壳展示部分业务,即一级入口,预计会带来平均万级 QPS、峰值超过十万级 QPS流量,特殊时间点可能会更高。为了防止服务宕机对百度APP产生非预期影响,故需要对破壳展示的数据提供完整缓存方案和降级预案。为了提升系统的高吞吐,我们决定将一级入口数据全部缓存至Redis,访问流量只读Redis,如果遇到Redis异常时,则返回兜底数据,不查询DB(防止压垮DB)。DB数据用来Redis极端情况崩溃时恢复Redis数据时使用。
针对存在资产的用户量分析,进入个人中心的用户存在一个特点:大部分用户没有个人中心外露的资产数据,抽象成一个稀疏矩阵,这就使我们在设计的时候,可以考虑两层缓存:第一层判断用户是否拥有资产信息,第二层缓存存储用户资产数据。故我们设计了如下的两层缓存方案。
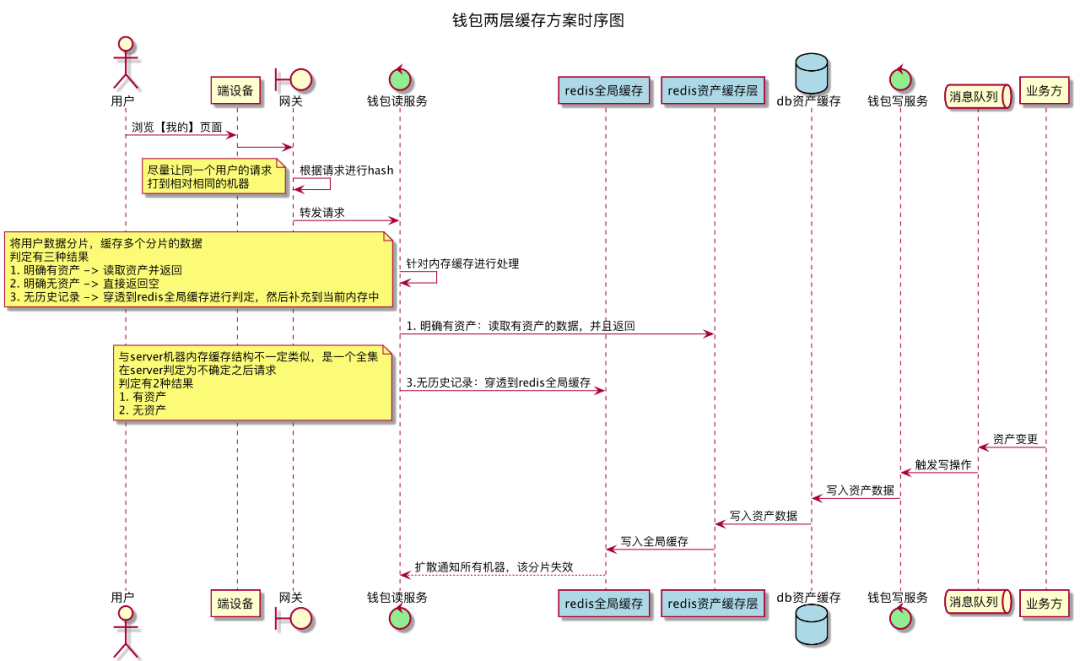
△图4-2 钱包两层缓存方案时序图
大部分用户流量会被第一层缓存拦截,设计合理的第一层缓存数据结构,成为了系统的一个关键。我们调研了hyperLogLog、布隆过滤器、roaringBitmap等方案,分析和实验后发现,hyperLogLog中pfadd操作本身可以满足性能要求,key的大小在12k也满足,但是由于pfadd本身针对于一个uid,只能操作一次,所以不适合这个场景hyperLogLog;布隆过滤器在试验20亿的数据量下,内存占用来量大约占比3G,内存占用比较大,基于redis的布隆过滤器没有分布式的数据能力,本质上还是对redis的强依赖,存在风险。
roaringBitmap在存储空间上满足要求,我们根据钱包的实际场景,改进了分桶与计算规则,根据用户id进行sharding分桶,桶内使用uid的hash值对应的bitmap位点标记状态。实验数据验证,3000分片,8个计算单元,1000W实验数据,存储空间占用500M+,误判率2.14%,即存在2.14%的用户没有资产信息会打到第二层缓存,整体对第二层缓存增加压力可控。
3、读写分离
钱包服务承接较大的读流量和写流量,为了防止互相影响,我们将读写流量分别拆到不同的服务。用户访问读服务异常时,不影响业务方推送写入,业务方推送写入服务异常时,不影响C端用户访问。读服务主要承接C端用户通过个人中心和钱包首页、二级页面访问的流量,将用户访问的相关数据进行缓存,提升系统平响。写服务主要承接业拉取业务方数据和C端用户授权信息,同时承接消息队列消费处理和与下游业务方交互。读写服务之间,通过RPC接口调用进行交互。
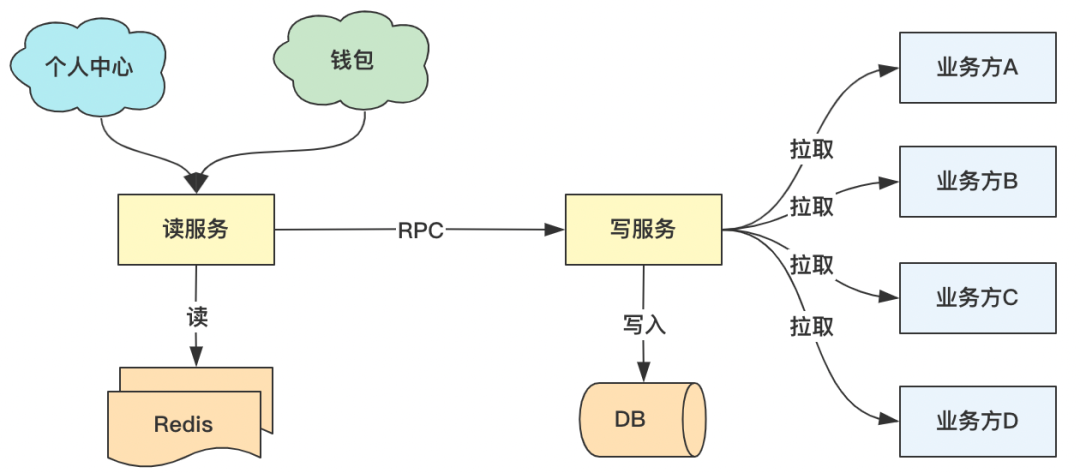
△图4-3 读写分离
4、数据一致
个人中心外露的业务数据,针对接入用户中心外露展示的业务方,我们需要业务方在用户资产发生变更时及时推送给钱包,以确保用户在钱包看到的数据与在业务方提供的入口查看的数据是相同的。但实际情况不一定如此,比如业务方推送服务异常、网络抖动,都有可能导致两方数据不一致。于是,我们提出了推拉结合的数据一致性解决方案。即业务方资产信息变更时,准时推送钱包,在用户进入个人中心时,触发拉取用户最新资产信息。当前,我们只对用户的资产信息已被推送至钱包的业务方,拉取用户最新资产信息,防止拉取全量业务方数据给用户量级小的业务方带来过多无效拉取流量导致服务压垮。针对系统内部,由于展示时只使用Redis中缓存数据,如果同步用户信息时因某些异常导致Redis与DB中数据不一致,我们采用定时任务,每天凌晨拉取DB中前一天(DB变更时间)有变更的用户信息,与Redis信息进行比对,数据不一致时,拉取业务方最新数据,更新Redis数据,做到T+1对账,解决系统内数据不一致问题。
对于钱包内展示的业务方,也会存在服务异常、网络抖动导致的无法获取用户最新信息的问题。我们采用的方案,对于正常请求业务方结果数据,将结果信息写入Redis,如果下次访问业务方接口异常时,使用Redis中数据作为兜底,优先确保数据正常展示。如果后续请求下游接口正常,则使用成功的数据更新Redis数据,确保Redis数据的准实时性。
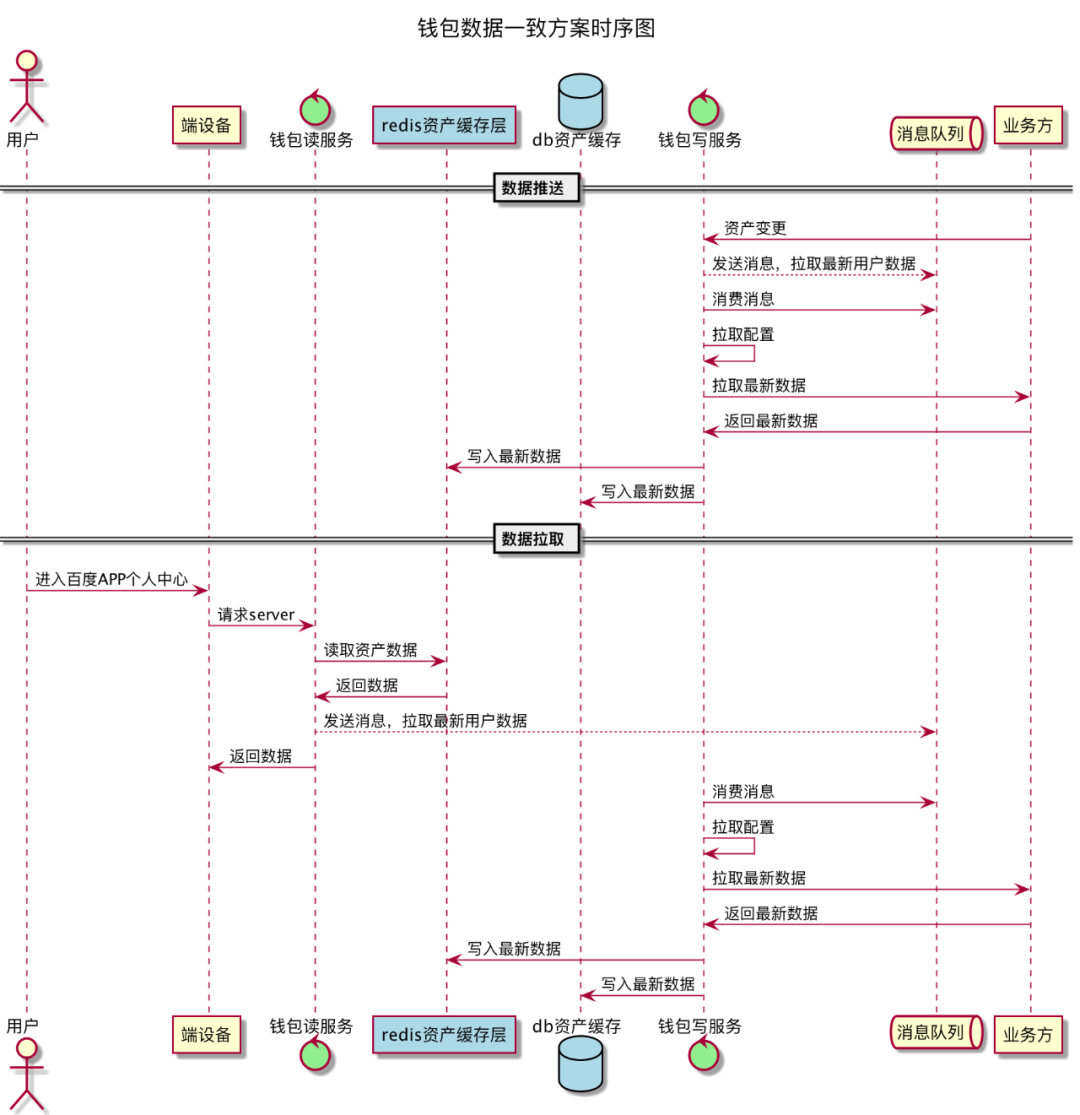
△图4-4 钱包数据一致方案时序图
5、配置化
钱包设计之初,就面临着如何支持业务方快速接入和支持运营人员快速配置用户展示界面、活动、营销等信息的问题。通用配置化能力,是解决此类问题的首选方案。
配置化主要分为两部分:接入配置化和展示配置化。通过分析发现,不同业务方的接入、展示需求不同,于是我们抽象共同的信息,生成通用基础信息,对于业务个性化信息,采用扩展模型记录业务特殊配置。汇总业务方基础配置+扩展配置后,放入Redis缓存中。对于钱包展示配置,底层设计展示通用配置,比如展示名称、文案、跳转链接、图片Url、背景图Url,对于特殊展示需求,可配置到扩展信息,比如外露Icon、展示金额,配置信息同样放入Redis缓存中。
项目上线初期,配置信息新增与更改的频次都很高,容易发生修改错误的风险,导致C端用户体验受损。于是我们设计版本号+白名单方案进行放量控制,新版本发布需与白名单用户相关联,配置生效后先使用白名单用户线上进行验证,验证通过后逐步全流量。修改配置时,保存历史更改全量数据,用于配置信息异常时回滚。
由于钱包对业务方配置信息依赖较强,如果Redis异常时会影响钱包的稳定性,所以我们将配置信息同步配置到百度云控平台GCP中,作为Redis异常时的兜底。缓存有效期可以设置永久有效,在变更配置时同步更新Redis,同时需要同步更新GCP配置,及时下发。
6、数据库设计
由于用户量较大,涉及用户资产信息到了数据库层面会同步放大,受限于MySQL数据库单机处理能力,故将数据进行拆分,不同的数据放置在不同的机器,便于机器扩容。在数据模型的设计上,数据库分表字段采用用户id作为分表字段(shardingKey),这样通过用户id定位到具体的库和表,因将整个资产信息库所有表按照统一规则进行切分,分表规则一致,保证按照同一用户都能在一个库,从而可以使用数据库事务。采用分库分表模式,后续遇到数据库存储瓶颈时,可以很方便的进行横向扩容。
五、总结
本文重点在介绍了百度APP个人钱包搭建的整个技术细节,在项目推动和落地的过程中,也遇到了诸多困难,主要的难点在系统高可用、高稳定、快速支持业务接入。梳理清楚难点与技术关键点,抓住关键问题,对系统合理做减法,降低系统复杂度,快速推进系统上线,后续不断迭代,打造极致用户体验。后续,在业务上会持续推进业务线快速接入,让用户在钱包内可以查看、管理百度系全量资产信息,在技术上继续推进稳定性、可靠性建设,为业务方带来更多用户流量,为用户提供更好的用户体验。
——————END——————
推荐阅读:
边栏推荐
- 2310. 个位数字为 K 的整数之和
- OpenGL - Lighting
- AUTOSAR from getting started to mastering 100 lectures (103) -dbc file format and creation details
- 浅谈Label Smoothing技术
- MySQL does not take effect in sorting string types
- Kotlin introductory notes (IV) circular statements (simple explanation of while, for)
- [sorting of object array]
- Unity skframework framework (XXII), runtime console runtime debugging tool
- Nips2021 | new SOTA for node classification beyond graphcl, gnn+ comparative learning
- 【ManageEngine】如何利用好OpManager的报表功能
猜你喜欢
nodejs_ fs. writeFile
高性能Spark_transformation性能
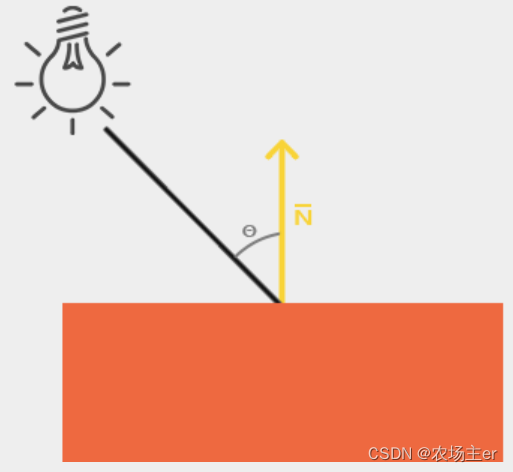
OpenGL - Lighting

The research trend of map based comparative learning (gnn+cl) in the top paper
![[ManageEngine] how to make good use of the report function of OpManager](/img/15/dc15e638ae86d6cf1d5b989fe56611.jpg)
[ManageEngine] how to make good use of the report function of OpManager

LeetCode 556. Next bigger element III
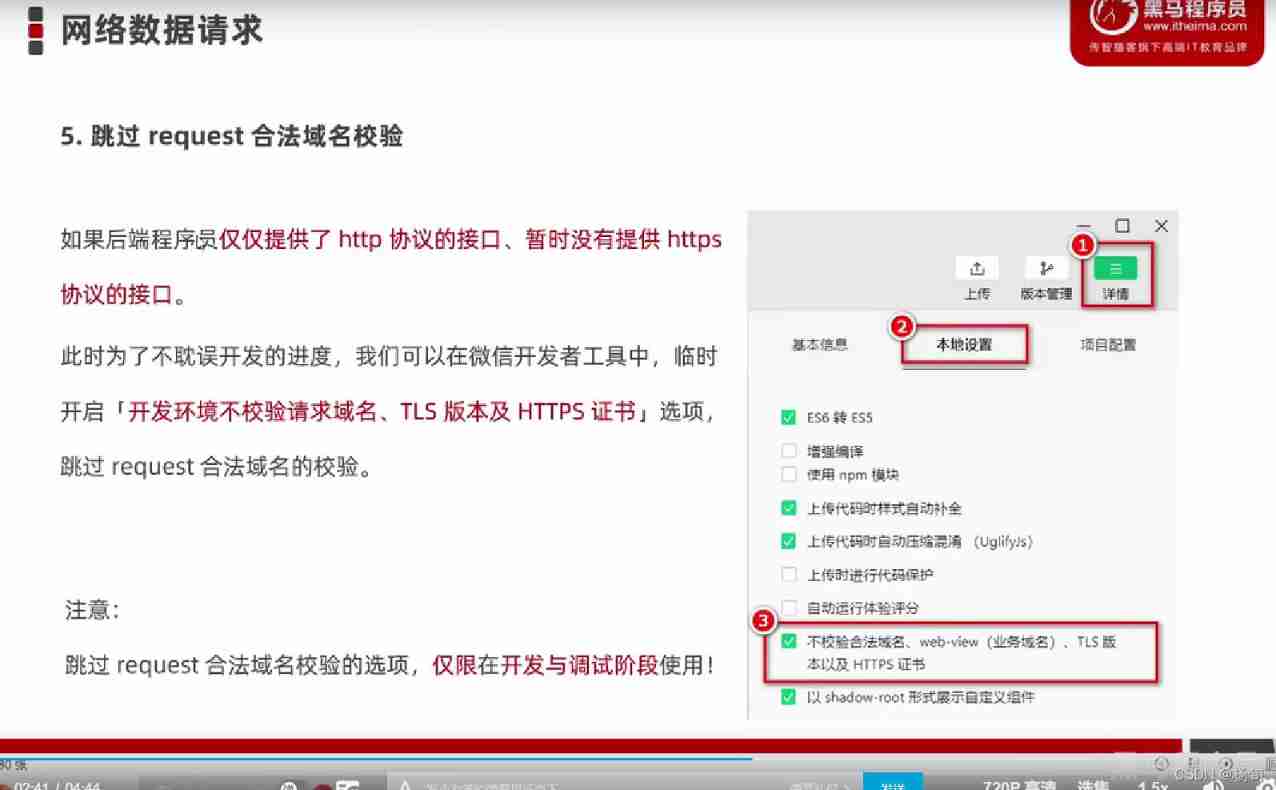
Applet network data request
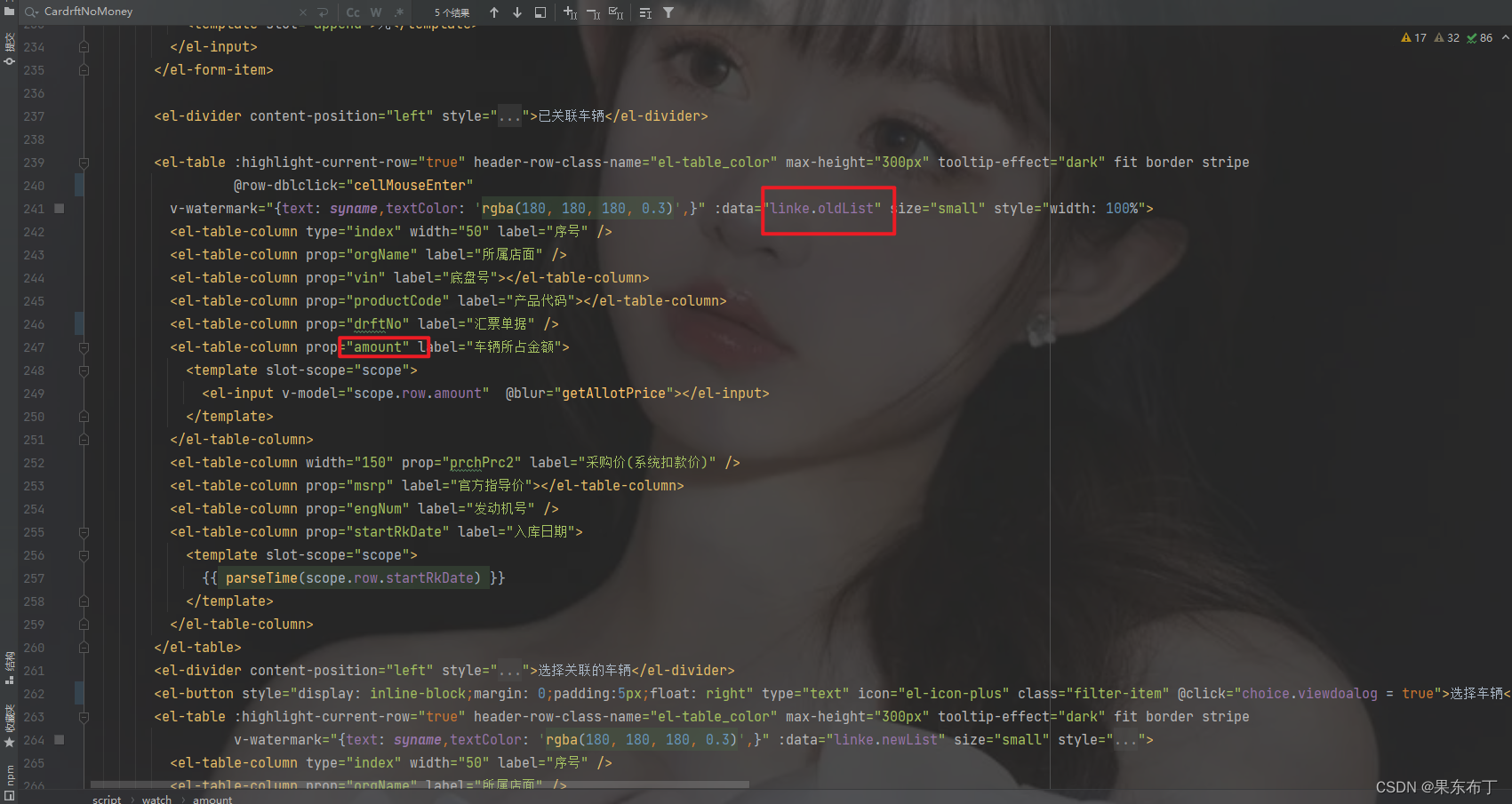
【数组的中的某个属性的监听】
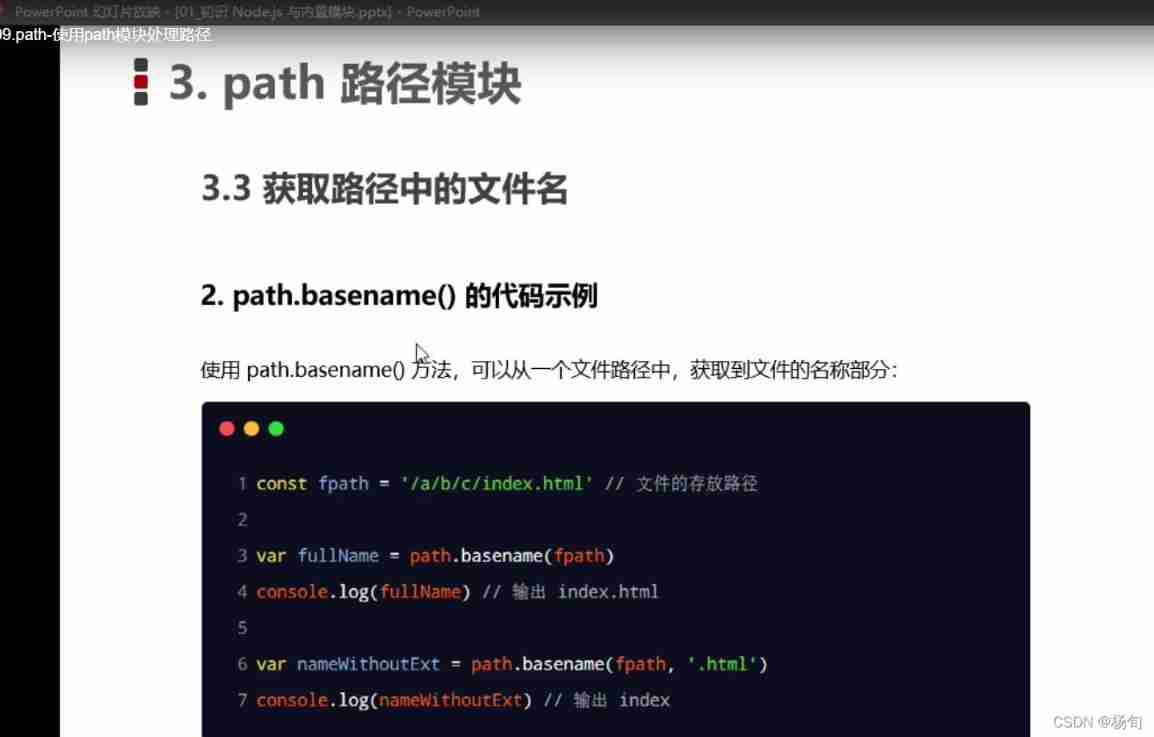
fs. Path module
Node collaboration and publishing
随机推荐
SQL learning alter add new field
Unity skframework framework (24), avatar controller third person control
Deep understanding of C language pointer
Unity SKFramework框架(二十三)、MiniMap 小地图工具
【PyTorch Bug】RuntimeError: Boolean value of Tensor with more than one value is ambiguous
C # image difference comparison: image subtraction (pointer method, high speed)
[reading notes] Figure comparative learning gnn+cl
OpenGL - Lighting
OpenGL - Model Loading
STM32 simple multi-level menu (array table lookup method)
C language - input array two-dimensional array a from the keyboard, and put 3 in a × 5. The elements in the third column of the matrix are moved to the left to the 0 column, and the element rows in ea
SQL learning - case when then else
Nodejs modularization
信息与熵,你想知道的都在这里了
C语言-从键盘输入数组二维数组a,将a中3×5矩阵中第3列的元素左移到第0列,第3列以后的每列元素行依次左移,原来左边的各列依次绕到右边
OpenGL - Coordinate Systems
2311. 小于等于 K 的最长二进制子序列
Understanding of smt32h7 series DMA and DMAMUX
Multiple solutions to one problem, asp Net core application startup initialization n schemes [Part 1]
The research trend of map based comparative learning (gnn+cl) in the top paper