当前位置:网站首页>Application of data modeling based on wide table
Application of data modeling based on wide table
2022-07-05 09:46:00 【Baidu geek said】

Reading guide : This paper introduces the trend of rapid iteration of Internet products , The technical scheme of replacing the classical data warehouse with the one-layer data warehouse wide table model , And from the Internet business change characteristics 、 The problems of classical data warehouse model 、 Principle, advantages and disadvantages of wide table model 、 The application effect of wide table is comprehensively analyzed , Finally, the wide table modeling is used to save data warehouse storage 、 The goal of improving query performance , Reduce the user's data use cost .
The full text 2995 word , Estimated reading time 8 minute
One 、 Business background
1.1 Current situation of data modeling :
Internet enterprises often have multiple product lines , A lot of data is produced every day , This data serves the data analysts 、 The product manager in the business 、 operating 、 Data developers and other roles . To meet the needs of these roles , The traditional data warehouse in the industry often adopts the data warehouse architecture of the classical layered model , from ODS>DWD>DWS>ADS Layer by layer modeling , Focus on support BI analysis , Here's the picture :
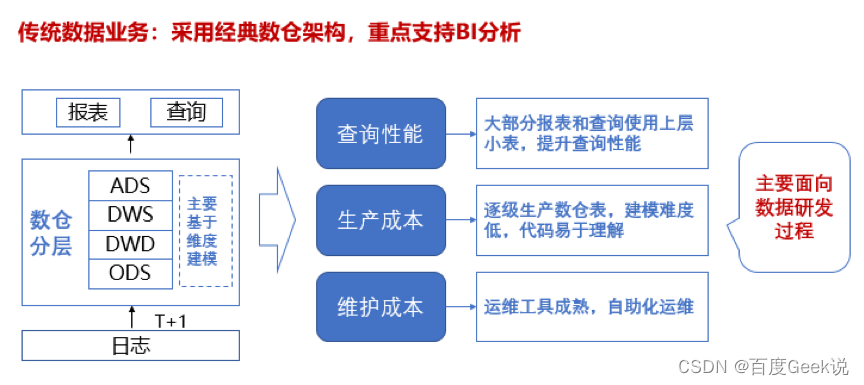
△ chart 1
1.2 Current business features and trends
Rapid iteration of Internet products , Business is growing faster and faster , More and more cross business analysis , Data driven business is becoming more and more important .
The main group of data services is shifting from data R & D to product personnel , The use threshold needs to be further reduced .
Two 、 Problems faced
2.1 Under the general trend that data-driven business is becoming more and more important , Problems faced
Faced with the following problems , Here's the picture :
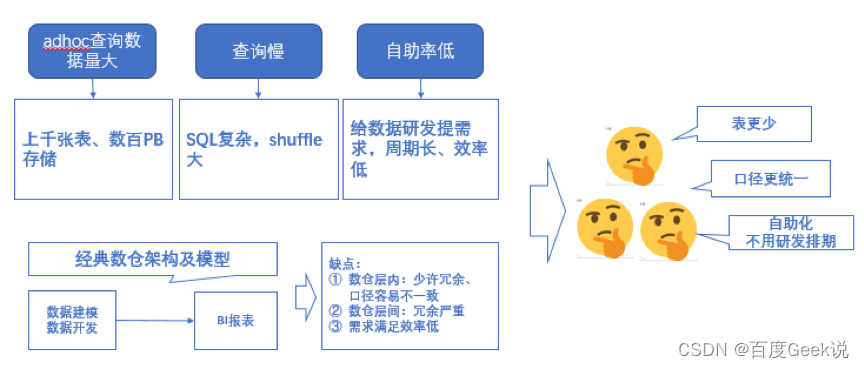
△ chart 2
2.2 reflection
So how to solve the above problems and pain points in production practice , After investigating the business line and interviewing specific users , According to the research and interview conclusion , Come up with the following ideas :
1) Save data warehouse for overall storage , The warehouse is not stratified , Meet business needs with fewer tables , For example, a topic has a wide table ;
2) Specify how to use the data sheet , Ensure clear and uniform caliber , Avoid the communication between the business lines , Reduce communication costs , Improve communication efficiency ;
3) Speed up data query , Meet business needs quickly , Help the data-driven business .
3、 ... and 、 Technical solution
According to the above idea , After feasibility analysis , This paper proposes a technical scheme that one-layer wide table model replaces the classical data warehouse dimension model , To solve the massive redundancy of data warehouse storage 、 There are many tables with unclear caliber and low query performance .
3.1 The wide table model replaces the classical data warehouse dimension model
3.1.1 Large and wide table model architecture
Replace the tables created using the dimension model in the data warehouse layer with a one-layer wide table , Replace the traditional... Between several storehouses ODS>DWD>DWS>ADS Layered architecture of layer by layer modeling , Final statement and adhoc Large and wide tables can be used directly in scenarios , Here's the picture :
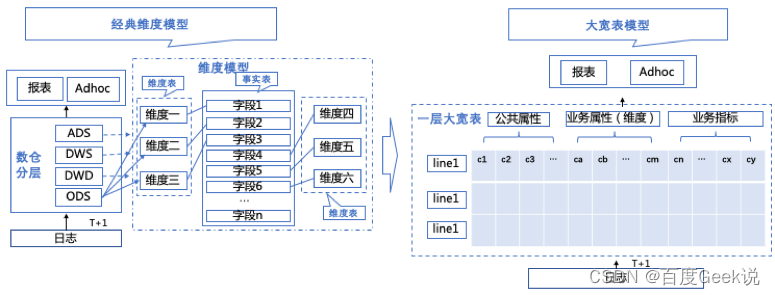
△ chart 3
3.1.2 Construction scheme of large and wide meters
According to different product functions and business scenarios , Divide the diary into different topics , In each subject, wide table construction is carried out according to the level of detail and business meaning of each business , Unified during construction ods Layer and dwd The table granularity of the layer , It covers all field requirements of downstream businesses , Include all fields of the schedule , It also covers the dimension fields and indicator columns of each layer , It is used to meet various needs of the upper layer, such as business indicator analysis , It mainly supports report analysis and adhoc Scene query , The details are as follows: :
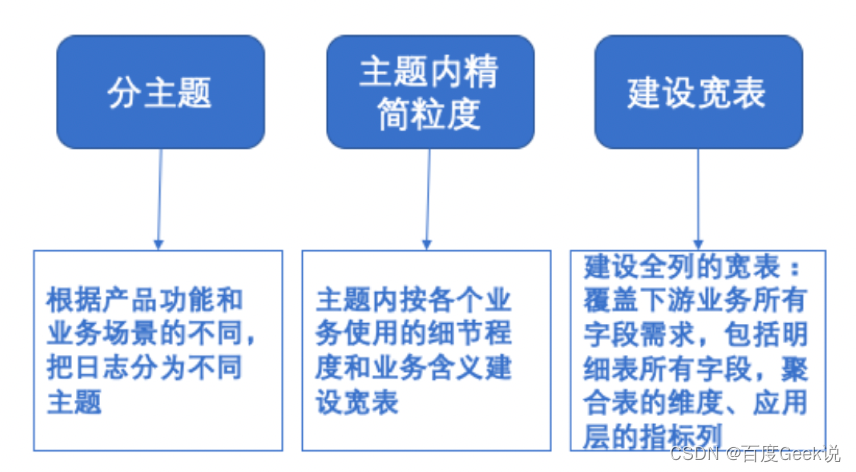
△ chart 4
3.1.3 Construction principle of large width meter
1) use Parquet The column type storage , It can support hundreds of columns in a wide table , Superfield , Then through the column by column efficient compression and coding technology , The overall storage space of the data warehouse is reduced , Improved IO efficiency , It has the effect of reducing the upper layer application delay
2) Flatten the complex nested fields of the fact table between each layer and the dimension tables 、 Indicators, etc join Generate wide table , The columns of the wide table are finally divided into common attributes 、 Business dimension attribute and indicator attribute
3.1.4 Advantages and performance of wide meter
1) A layer of large and wide tables replaces the dimension model , With minimal redundancy , Less tables are achieved , The caliber is clearer , At the same time, it is more convenient for business use , More fluent communication , More efficient
In the same subject , When building a wide table, the dimension table join To the fact table , More facts are listed , I thought it would add some storage , Results after column storage by column efficient compression and coding technology , Reduced storage space , In the production practice scenario , Found little storage increase .
After replacement, there is only one wide table in the data warehouse layer , And the table structure is clear , The communication efficiency is greatly improved , Here's the picture :

△ chart 5
2) There is a lot of redundancy between the classical data warehouse layer and the layer , One layer wide table replaces multi-layer data warehouse , The total storage of data warehouse decreases 30% about , Save a lot of storage
In the classic data warehouse architecture , There are a lot of redundant storage in the data warehouse for the same subject , For example, business often starts from ODS Layer extraction field generation DWD The layer data , There will be a lot of redundancy in the extracted fields between these two layers , Empathy , There is also a lot of redundancy between other layers within the topic . Within the same subject, it is used according to the level of detail and specific business meaning , The table granularity is reduced and unified into one granularity , At this granularity, it contains the fields required by downstream businesses , Generate wide table , It can avoid a large amount of redundancy between data warehouse layers . That is, the whole data warehouse does not need to be layered , There is only one layer of large width table , A topic has one or two wide tables . After the construction of large width meter in production practice , The total storage of data warehouse decreases 30% about , Greatly saves storage costs , Here's the picture :

△ chart 6
3) Performance comparison
There may be questions here , Since the amount of wide table data has increased , Will there be a performance loss on the query ?
There are three types of scenarios :
scene 1: When the storage of the classic data warehouse table and the one-layer wide table are similar , The wide table uses columnar storage and statistical filtering , Simple query , In particular, simple aggregate queries are faster
scene 2: This is still the case when the storage of the classic data warehouse table is similar to that of the one-layer wide table , The classic data warehouse needs to use explode And other functions , In the wide table, most of the requirements pass count、sum Can finish , Because the wide table will sink the business indicators , Split and level complex fields , Although the number of lines has increased , But avoid explode,get_json_object Wait for time-consuming operations , High query performance
scene 3: When there is a big difference between the storage of the classic data warehouse table and the one-layer wide table , There is a certain loss of wide meter performance , But within the scope of business acceptance , The impact is not big , Here's the picture :
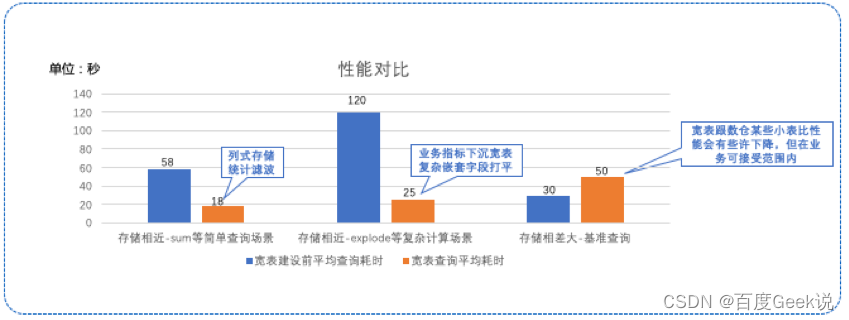
△ chart 7
3.1.5 The challenge of wide tables
Wide table modeling improves data usability and query performance , It also brings some challenges :
1) Development costs : In order to meet the business requirements as much as possible , It encapsulates a lot of ETL Processing logic and associated computation , This makes the wide table code more complex , Development iterations are more expensive to maintain .
2) Backtracking costs : In the business iteration process , It is often accompanied by the upgrading of the indicator caliber 、 Changes in log management , Wide table backtracking history data is required . The wide table itself has a large amount of data , Computational logic is complex , Backtracking will consume more computing resources , There is a high backtracking cost .
3) Output timeliness : Because the wide table itself has many upstream data sources 、 Large amount of data , When multiple upstream data readiness times are different , Barrel effect will appear in the output aging of wide tables .
In view of the above , Combined with practical application, we have explored some solutions :
Development costs increase , The main reason is that the wide table performs more ETL Operation and encapsulation of more index caliber calculations , This is essentially a trade-off between R & D costs and use costs , Encapsulate the recalculated cost of some downstream users into a wide table in advance . If the downstream users of the wide table are more , This increase in R & D costs actually reduces the overall business costs , That is to say, lowering the threshold of use 、 Improve self-service rate . Therefore, in the context of the current popularization of data analysis , The actual total cost is decreasing .
Backtracking cost increases , Reflected in the original only need to backtrack one dws or ads Small table of layers , Now you may have to go back to the whole wide table . Here in actual production , We can explore some optimization schemes technically , Include :
(1) Set the wide table to different service partitions , Only the corresponding partition data is updated during backtracking ;
(2) Based on the wide table as input , Fields required for backtracking , Avoid re executing complex calculation logic that generates wide tables ;
(3) Take advantage of the tide resources available online at night , Further reduce the backtracking resource cost .
The output timeliness of multiple upstream data sources is not synchronized , Here we can consider 2 Ways of planting :
(1) Through the upstream data flow batch integration transformation , Improve the timeliness of upstream data
(2) When the upstream data cannot be accelerated , You can consider batch production of data from different partitions , This way requires meta The system and dispatching system support synchronization , It will increase the complexity of the system .
More solutions , Welcome to further discuss ~
Four 、 Summary and planning
1) Wide table modeling is more suitable for fast iteration oriented data-driven business , Can improve business efficiency
2) Based on current business practices , Wide table is better than traditional data warehouse in storage and query performance
3) While improving business efficiency , The construction of wide tables will increase the cost of data production and maintenance , It also needs to be further optimized and explored in combination with practical applications
The future planning : It is more convenient to build a self-service analysis platform based on wide tables , Further improve the efficiency of business analysis .
Recommended reading :
Design and exploration of Baidu comment center
Data visualization platform based on template configuration
How to correctly evaluate the video quality
Small program startup performance optimization practice
How do we get through low code “⽆⼈ District ” Of :amis The key design of love speed
Mobile heterogeneous computing technology -GPU OpenCL Programming ( The basic chapter )
Cloud native enablement development test
be based on Saga Implementation of distributed transaction scheduling
边栏推荐
- Can't find the activitymainbinding class? The pit I stepped on when I just learned databinding
- The research trend of map based comparative learning (gnn+cl) in the top paper
- LeetCode 503. 下一个更大元素 II
- Why do offline stores need cashier software?
- What are the advantages of the live teaching system to improve learning quickly?
- 分布式数据库下子查询和 Join 等复杂 SQL 如何实现?
- uni-app---uni. Navigateto jump parameter use
- Unity SKFramework框架(二十三)、MiniMap 小地图工具
- 干货整理!ERP在制造业的发展趋势如何,看这一篇就够了
- [sourcetree configure SSH and use]
猜你喜欢

22-07-04 Xi'an Shanghao housing project experience summary (01)
oracle 多行数据合并成一行数据
一次 Keepalived 高可用的事故,让我重学了一遍它
Principle and performance analysis of lepton lossless compression
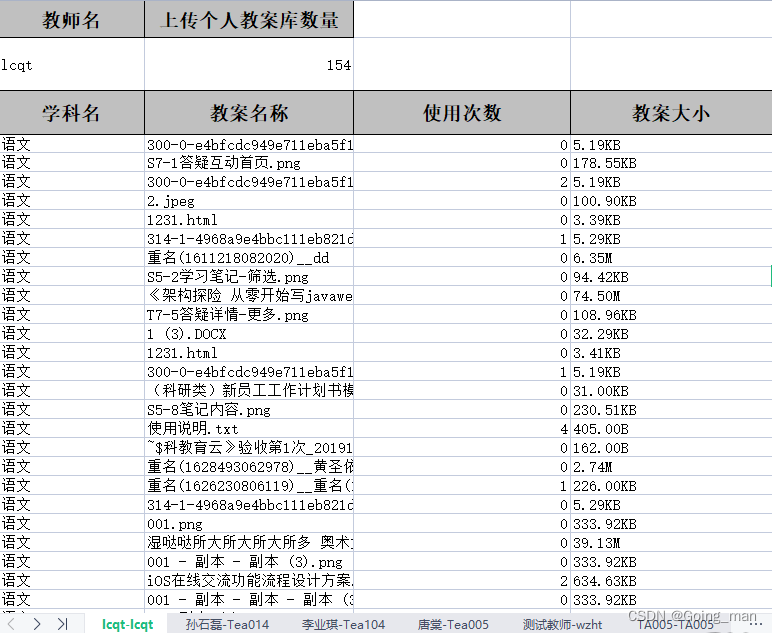
Project practice | excel export function
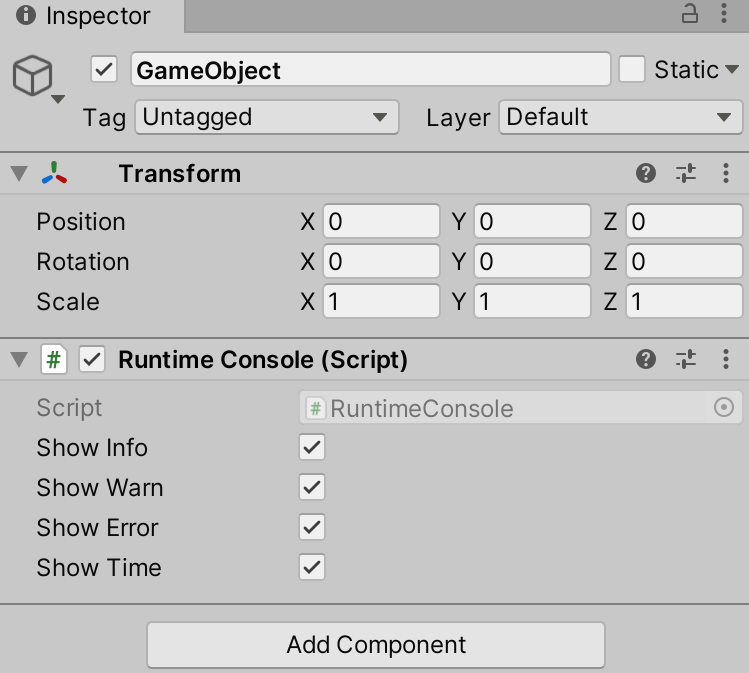
Unity skframework framework (XXII), runtime console runtime debugging tool

90%的人都不懂的泛型,泛型的缺陷和应用场景

Why do offline stores need cashier software?
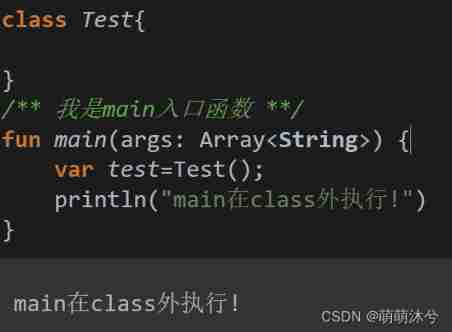
Kotlin introductory notes (II) a brief introduction to kotlin functions
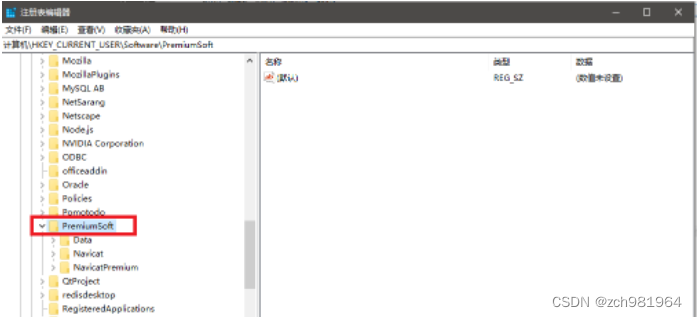
解决Navicat激活、注册时候出现No All Pattern Found的问题
随机推荐
MySQL does not take effect in sorting string types
Analysis of eventbus source code
What should we pay attention to when entering the community e-commerce business?
解决Navicat激活、注册时候出现No All Pattern Found的问题
Three-level distribution is becoming more and more popular. How should businesses choose the appropriate three-level distribution system?
Lepton 无损压缩原理及性能分析
Deep understanding of C language pointer
【组队 PK 赛】本周任务已开启 | 答题挑战,夯实商品详情知识
【对象数组a与对象数组b取出id不同元素赋值给新的数组】
The most comprehensive promotion strategy: online and offline promotion methods of E-commerce mall
Kotlin introductory notes (VIII) collection and traversal
mysql安装配置以及创建数据库和表
First understanding of structure
H.265编码原理入门
How to improve the operation efficiency of intra city distribution
Develop and implement movie recommendation applet based on wechat cloud
【两个对象合并成一个对象】
Officially launched! Tdengine plug-in enters the official website of grafana
On July 2, I invite you to TD Hero online press conference
一文读懂TDengine的窗口查询功能